Wprowadzenie
Kilka lat temu otrzymaliśmy zadanie biznesowego wymagania danych kartowych w określonym formacie w celu czegoś, co nazywa się „uzgadnianiem”. Pomysł polegał na przedstawieniu danych w tabeli do aplikacji, która konsumowałaby i przetwarzała dane, które miałyby okres przechowywania 6 miesięcy. Musieliśmy utworzyć nową bazę danych dla tej potrzeby biznesowej, a następnie utworzyć tabelę podstawową jako tabelę partycjonowaną. Opisany tutaj proces to proces, którego używamy, aby zapewnić, że dane starsze niż sześć miesięcy zostaną usunięte z tabeli w czysty sposób.
Trochę o partycjonowaniu
Partycjonowanie tabel to technologia bazy danych, która umożliwia przechowywanie danych należących do jednej jednostki logicznej (tabeli) jako zestawu partycji, które będą znajdować się na oddzielnej strukturze fizycznej – plikach danych – poprzez warstwę abstrakcji zwaną File Groups w SQL Server. Proces tworzenia tej tabeli partycjonowanej obejmuje dwa kluczowe obiekty:
Funkcja partycji :Funkcja partycji definiuje sposób mapowania wierszy tabeli partycjonowanej na podstawie wartości określonej kolumny (kolumny partycji). Tabela podzielona na partycje może być oparta na liście lub zakres. Na potrzeby naszego przypadku użycia (zachowując dane tylko z sześciu miesięcy), użyliśmy Range Partition . Funkcję partycji można zdefiniować jako ZAKRES W PRAWO lub ZAKRES W LEWO. Użyliśmy RANGE RIGHT, jak pokazano w kodzie na Listingu 1, co oznacza, że wartość graniczna będzie należeć do prawej strony przedziału wartości granicznej, gdy wartości są sortowane w kolejności rosnącej od lewej do prawej.
-- Listing 1:Utwórz funkcję partycji USE [post_office_history]GOCREATE PARTITION FUNCTIONPostTranPartFunc (datetime) JAKO ZAKRES WŁAŚCIWY DLA WARTOŚCI ('20190201','20190301','20190401','20190501','20190601','20190701', „20190801”, „20190901”, „20191001”, „20191101”, „20191201”) PRZEJDŹ Schemat partycji :Schemat partycji opiera się na funkcji partycji i określa, na których strukturach fizycznych zostaną umieszczone wiersze należące do każdej partycji. Osiąga się to poprzez mapowanie takich wierszy na grupy plików. Listing 2 przedstawia kod do tworzenia schematu partycji. Przed utworzeniem schematu partycji muszą istnieć grupy plików, do których będzie się on odnosić.
-- Listing 2:Tworzenie schematu partycji ---- Krok 1:Tworzenie grup plików --USE [master]GOALTER DATABASE [post_office_history] ADD FILEGROUP [JAN]ALTER DATABASE [post_office_history] ADD FILEGROUP [LUTY]ALTER DATABASE [post_office_history ] ADD FILEGROUP [MAR]ALTER DATABASE [post_office_history] ADD FILEGROUP [APR]ALTER DATABASE [post_office_history] ADD FILEGROUP [MAY]ALTER DATABASE [post_office_history] ADD FILEGROUP [JUN]ALTER DATABASE [post_office_ALGROUP_history_BASE] ADD FI ] ADD FILEGROUP [AUG]ALTER DATABASE [post_office_history] ADD FILEGROUP [SEP]ALTER DATABASE [post_office_history] ADD FILEGROUP [OCT]ALTER DATABASE [post_office_history] ADD FILEGROUP [NOV]ALTER DATABASE [post_office_GROUP]- [Step] ADD FILE 2:Dodaj pliki danych do każdej grupy plików --USE [master]GOALTER DATABASE [post_office_history] ADD FILE (NAZWA =N'post_office_history_part_01', FILENAME =N'E:\MSSQL\DATA\post_office_history_part_01.ndf', SIZE =2097152KB, FILEGROWTH=1048576KB) DO FILEGROUP [JAN]ZMIEŃ BAZĘ DANYCH [post_office_history] ADD FILE (NAZWA =N'post_office_history_part_02', FILENAME =N'E:\MSSQL\DATA\post_office_history_part_02.ndf', SIZE =2097152KB, FILEGROWTH) FEB]ALTER DATABASE [post_office_history] ADD FILE (NAZWA =N'post_office_history_part_03', FILENAME =N'E:\MSSQL\DATA\post_office_history_part_03.ndf', SIZE =2097152KB, FILEGROWTH =1048576KB) DO FILEGROWTH_ALGROUP_DANYCH [history_ALGROUPICE] ] DODAJ PLIK (NAZWA =N'post_office_history_part_04', FILENAME =N'E:\MSSQL\DATA\post_office_history_part_04.ndf', SIZE =2097152KB, FILEGROWTH =1048576KB) DO FILEGROUP [APR]ZMIEŃ BAZA DANYCH [NAZWA_AD FI_HISLE] N'post_office_history_part_05', NAZWA PLIKU =N'E:\MSSQL\DANE\post_office_history_part_05.ndf', ROZMIAR =2097152KB, FILEGROWTH =1048576KB) DO GRUPY PLIKÓW [MAY]ZMIANA BAZY DANYCH [post_office_history] ADD', FILE_PART_NAME (NAZWA_PLIKÓW) =N'G:\MSSQL\DANE\post_office_history_part_06. ndf', SIZE =2097152KB, FILEGROWTH =1048576KB) DO FILEGROUP [JUN] ZMIEŃ BAZĘ DANYCH [post_office_history] DODAJ PLIK (NAZWA =N'post_office_history_part_07', FILENAME =N'G:\MSSQL\DATA\post_office_ndf97_part_07, S , FILEGROWTH =1048576KB) DO FILEGROUP [JUL] ALTER DATABASE [post_office_history] DODAJ PLIK (NAZWA =N'post_office_history_part_08', FILENAME =N'G:\MSSQL\DATA\post_office_history_part_08.ndf', ROZMIAR) =10485LEGROW2K) FILEGROUP [SIEŃ] ALTER DATABASE [post_office_history] ADD FILE (NAZWA =N'post_office_history_part_09', FILENAME =N'G:\MSSQL\DATA\post_office_history_part_09.ndf', SIZE =2097152KB, FILEGROWTH =10485LE76KB DANYCH [SEP] [post_office_history] DODAJ PLIK (NAZWA =N'post_office_history_part_10', NAZWA PLIKU =N'G:\MSSQL\DATA\post_office_history_part_10.ndf', SIZE =2097152KB, FILEGROWTH =1048576KB) DO FILEGROUP [OCT_history]_GOALTER ADRES NAZWA =N'post_office_history_part_09', NAZWA PLIKU =N'G:\MS SQL\DANE\post_office_history_part_11.ndf', ROZMIAR =2097152KB, FILEGROWTH =1048576KB) DO FILEGROUP [listopad] ZMIEŃ BAZĘ DANYCH [post_office_history] DODAJ PLIK (NAZWA =N'post_office_history_part_10', FILENAME_off_D_12.\MSATA ndf', SIZE =2097152KB, FILEGROWTH =1048576KB) DO FILEGROUP [DEC]GO-- Krok 3:Utwórz schemat partycji --PRINT 'tworzenie schematu partycji...'GOUSE [post_office_history]GOCREATE SCHEMAT PARTYCJI PostTranPartSch AS PARTITION PostTranPartFunc TO(JAN ,LUTY, MARCA, KWIECIEŃ, MAJ, CZERWIEC, LIPIEC, SIERPIEŃ, WRZESIEŃ, PAŹDZIERNIK, LISTOPAD, GRUDZIEŃ) START
Zauważ, że dla N partycje, zawsze będzie N-1 Granic. Należy zachować ostrożność podczas definiowania pierwszej grupy plików w schemacie partycji. Pierwsza granica wymieniona w funkcji partycji będzie leżeć między pierwszą a drugą grupą plików, dlatego ta wartość graniczna (20190201) będzie znajdować się w drugiej partycji (luty). Ponadto w rzeczywistości możliwe jest umieszczenie wszystkich partycji w jednej grupie plików, ale w tym przypadku wybraliśmy oddzielne grupy plików.
Zabrudzenie rąk
Zajmijmy się więc przełączaniem partycji!
Pierwszą rzeczą, którą musimy zrobić, to dokładnie określić, w jaki sposób nasze dane są rozmieszczone na partycjach, abyśmy mogli wiedzieć, którą partycję chcemy wyłączyć. Zazwyczaj wyłączamy najstarszą partycję.
-- Listing 3:Sprawdzanie dystrybucji danych w partycjach --USE POST_OFFICE_HISTORYGOSELECT $PARTITION.POSTTRANPARTFUNC(DATETIME_TRAN_LOCAL) AS [NUMER PARTYCJI] , MIN(DATETIME_TRAN_LOCAL) AS [MIN DATE] , MAX(DATETIME_TRAN_LOCAL) AS [MAX DATE] , COUNT(*) JAKO [ROWS IN PARTITION]FROM DBO.POST_TRAN_TAB -- PARTYCOWANA GRUPA TABEL WEDŁUG $PARTITION.POSTTRANPARTFUNC(DATETIME_TRAN_LOCAL)ORDER BY [NUMER PARTYCJI]GO
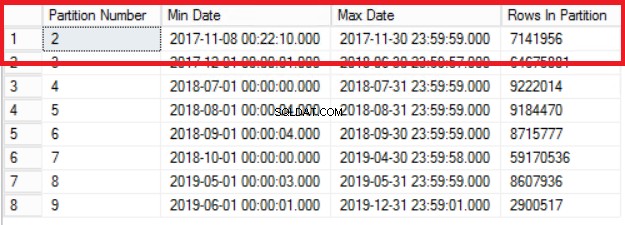
Rys. 1 Dane wyjściowe z Listingu 3
Rys. 1 pokazuje nam wynik zapytania z Listingu 3. Najstarszą partycją jest partycja 2, która zawiera wiersze z roku 2017. Weryfikujemy to za pomocą zapytania z Listingu 4. Listing 4 pokazuje nam również, która grupa plików przechowuje dane w partycji 2.
-- Listing 4:Sprawdź grupę plików skojarzoną z partycją --USE POST_OFFICE_HISTORYGOSELECT PS.NAME AS PSNAME, DDS.DESTINATION_ID AS PARTITIONNUMBER, FG.NAME AS FILEGROUPNAMEFROM (((SYS.TABLES AS T INNER JOIN SYS.INDEXES AS I ON) (T.OBJECT_ID =I.OBJECT_ID)) ZŁĄCZENIE WEWNĘTRZNE SYS.PARTITION_SCHEMES JAKO PS ON (I.DATA_SPACE_ID =PS.DATA_SPACE_ID)) ZŁĄCZENIE WEWNĘTRZNE SYS.DESTINATION_DATA_SPACES JAKO DDS ON (PS.DATA_SPACE_ID =DDS.PARTITION)_SCHEME FILEGROUPS AS FG ON DDS.DATA_SPACE_ID =FG.DATA_SPACE_IDWHERE (T.NAME ='POST_TRAN_TAB') AND (I.INDEX_ID IN (0,1)) AND DDS.DESTINATION_ID =$PARTITION.POSTTRANPARTFUNC('20171108'); Rys. 1 Dane wyjściowe z Listingu 3
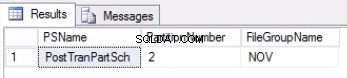
Rys. 2 Dane wyjściowe z Listingu 4
Listing 4 pokazuje nam, że grupa plików skojarzona z partycją 2 to NOV . Aby wyłączyć partycję 2, potrzebujemy tabeli historii, która jest repliką tabeli aktywnej, ale znajduje się w tej samej grupie plików, co partycja, którą zamierzamy wyłączyć. Ponieważ mamy już tę tabelę, wszystko, czego potrzebujemy, jest odtwarzane w żądanej grupie plików. Musisz również odtworzyć indeks klastrowy. Zwróć uwagę, że ten indeks klastrowy ma taką samą definicję, jak indeks klastrowy w tabeli post_tran_tab a także znajduje się w tej samej grupie plików co post_tran_tab_hist tabela.
-- Listing 5:Odtwórz Tablicę Historii -- Odtwórz Tablicę Historii --USE [post_office_history]GOSET ANSI_NULLS ONGOSET QUOTED_IDENTIFIER ONGOSET ANSI_PADDING ONGODROP TABLE [dbo].[post_tran_tab_hist]GOCREATE TABLE [dbo].[ post_tran_tab_hist]( [tran_nr] [bigint] NOT NULL, [tran_type] [char](2) NULL, [tran_reversed] [char](2) NULL, [batch_nr] [int] NULL, [message_type] [znak](4 ) NULL, [nazwa_węzła źródłowego] [varchar](12) NULL, [system_trace_audit_nr] [char](6) NULL, [settle_currency_code] [char](3) NULL, [sink_node_name] [varchar](30) NULL, [sink_node_currency_code] [char](3) NULL, [to_account_id] [varchar](30) NULL, [pan] [varchar](19) NOT NULL, [pan_encrypted] [char](18) NULL, [pan_reference] [char](70 ) NULL, [datetime_tran_local] [datetime] NOT NULL, [tran_amount_req] [float] NOT NULL, [tran_amount_rsp] [float] NOT NULL, [tran_cash_req] [float] NOT NULL, [tran_cash_rsp] [float] NOT NULL, [datetime_tran_g ] [znak](10) NULL, [merchant_type] [znak](4) NULL, [pos_entry_mode] [znak] (3) NULL, [pos_condition_code] [znak](2) NULL, [acquiring_inst_id_code] [varchar](11) NULL, [retrieval_reference_nr] [znak](12) NULL, [auth_id_rsp] [znak](6) NULL, [ rsp_code_rsp] [znak](2) NULL, [service_restriction_code] [znak](3) NULL, [terminal_id] [znak](8) NULL, [terminal_owner] [varchar](25) NULL, [card_acceptor_id_code] [znak]( 15) NULL, [card_acceptor_name_loc] [znak](40) NULL, [from_account_id] [varchar](28) NULL, [auth_reason] [char](1) NULL, [auth_type] [char](1) NULL, [message_reason_code ] [znak](4) NULL, [datetime_req] [datetime] NULL, [datetime_rsp] [datetime] NULL, [from_account_type] [znak](2) NULL, [to_account_type] [znak](2) NULL, [insert_date] [datetime] NOT NULL, [tran_postilion_originated] [int] NOT NULL, [card_product] [varchar](20) NULL, [card_seq_nr] [char](3) NULL, [data_wygaśnięcia] [char](4) NULL, [srcnode_cash_approved ] [float] NOT NULL, [tran_completed] [char](2) NULL) ON [NOV] GOSET ANSI_PADDING OFFGO-- Odtwórz indeks klastrowy --USE [post_office_history]GO UTWÓRZ SKLASTROWANY INDEKS [IX_Datetime_Local] ON [dbo].[post_tran_tab_hist] ( [datetime_tran_local] ASC, [tran_nr] ASC ) Z (PAD_INDEX =OFF, STATISTICS_NORECOMPUTE =OFF, SORT_IN_TEMPDB =OFF, ON_EXISTING_DUP =OFF, ON_EXISTING_DUP =, ALLOW_ROW_LOCKS =WŁ., ALLOW_PAGE_LOCKS =WŁ.) [NOV]GO
Wyłączenie ostatniej partycji jest teraz poleceniem jednowierszowym. Liczenie obu tabel przed i po wykonaniu tego jednowierszowego polecenia daje pewność, że mamy wszystkie pożądane dane.
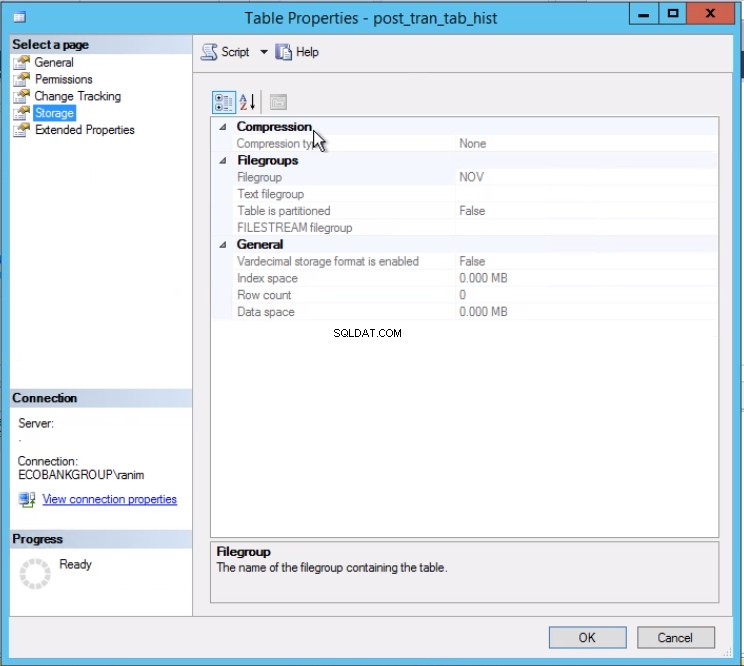
Rys. 3 Tabela post_tran_tab_hist znajduje się w grupie plików NOV
Ponieważ wyłączyliśmy ostatnią partycję, nie potrzebujemy już granicy. Łączymy dwa zakresy wcześniej podzielone przez tę granicę za pomocą polecenia z Listingu 7. Dalej przycinamy tabelę historii, jak pokazano na Listingu 8. Robimy to, ponieważ o to chodzi:usuwanie starych danych, których już nie potrzebujemy.
-- Listing 7:Scalanie zakresów partycji-- Scal zakresUSE [POST_OFFICE_HISTORY]GOALTER PARTITION FUNCTION POSTTRANPARTFUNC() MERGE RANGE ('20171101');-- Potwierdź, że zakres jest scalonyUSE [POST_OFFICE_HISTORY]GOSELECT * FROM SYS.PARTITION_GO
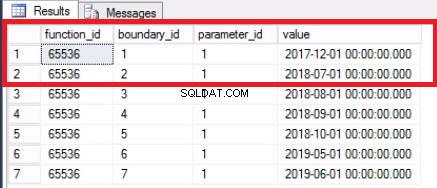
Rys. 4 Scalona granica
-- Listing 8:Obcinanie tabeli historiiUSE [post_office_history]GOTRUNCATE TABLE post_tran_tab_hist;GO
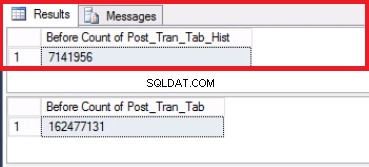
Rys. 5 Liczba wierszy dla obu tabel przed przycięciem
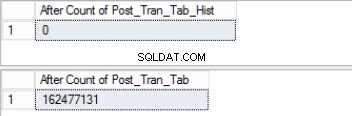
Zwróć uwagę, że liczba wierszy w tabeli historii jest dokładnie taka sama, jak liczba wierszy poprzednio w partycji 2, jak pokazano na rys. 1. Możesz również pójść o krok dalej, odzyskując puste miejsce w grupie plików należącej do ostatniego przegroda. Będzie to przydatne, jeśli potrzebujesz tego miejsca na nowe dane, które będą znajdować się na wcześniejszej partycji. Ten krok może nie być konieczny, jeśli uważasz, że masz wystarczająco dużo miejsca w swoim otoczeniu.
-- Listing 9:Odzyskiwanie miejsca w systemie operacyjnym-- Sprawdź, czy plik został opróżniony USE [post_office_history]GOSELECT DF.FILE_ID, DF.NAME, DF.PHYSICAL_NAME, DS.NAME, DS.TYPE, DF.STATE_DESC FROM SYS .DATABASE_FILES DFJOIN SYS.DATA_SPACES DS ON DF.DATA_SPACE_ID =DS.DATA_SPACE_ID;
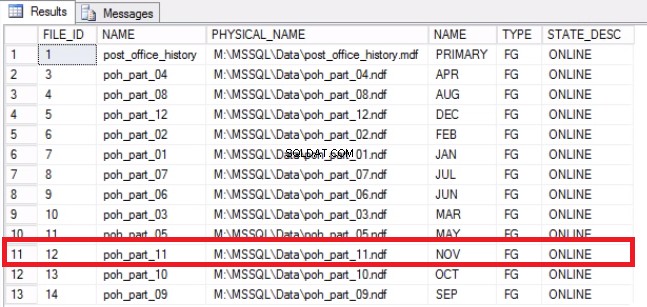
Rys. 7 Mapowania plików do grup plików
-- Zmniejsz plik do 2GBUSE [post_office_history]GODBCC SHRINKFILE (N'post_office_history_part_11', 2048)GO-- W systemie operacyjnym potwierdź wolne miejsce na dyskachSELECT DISTINCT DB_NAME (S.DATABASE_ID) AS DATABASE_NAME,S.DATABASE_ID, S. VOLUME_MOUNT_POINT--, S.VOLUME_ID, S.LOGICAL_VOLUME_NAME, S.FILE_SYSTEM_TYPE, S.TOTAL_BYTES/1024/1024/1024 AS [TOTAL_SIZE (GB)], S.AVAILABLE_BYTES/1024/1024/1024 AS [FREE_SPACE (GB)], LEWY ((OKRĄGŁY (((S.AVAILABLE_BYTES*1.0)/S.TOTAL_BYTES), 4)*100),4) JAKO PROCENT_WOLNY OD SYS.MASTER_FILES JAKO FCROSS ZASTOSUJ SYS.DM_OS_VOLUME_STATS (F.DATABASE_ID, F.FILE_ID) JAKO SWHERE DB_NAME (S.DATABASE_ID) ='POST_OFFICE_HISTORY';

Rys. 8 Wolne miejsce w systemie operacyjnym
Wniosek
W tym artykule omówiliśmy proces przełączania partycji z tabeli partycjonowanej. Jest to bardzo wydajny sposób zarządzania przyrostem danych natywnie w SQL Server. Bardziej zaawansowane technologie, takie jak Stretch Database, są dostępne w aktualnych wersjach SQL Server.
Referencje
Isakow, V. (2018). Egzamin nr 70-764 Administrowanie infrastrukturą bazy danych SQL. Edukacja Pearson
Tabele partycjonowane i indeksy w SQL Server