Koncepcyjnie rozwiązanie będzie wyglądało jak wykonanie zapytania źródłowego w celu wygenerowania zestawu wyników. Zapisz to w zmiennej, a następnie będziesz musiał wykonać iterację przez te wyniki, a dla każdego wiersza będziesz chciał wywołać swoją procedurę składowaną z wartością tego wiersza i wysłać wyniki do nowego pliku Excel.
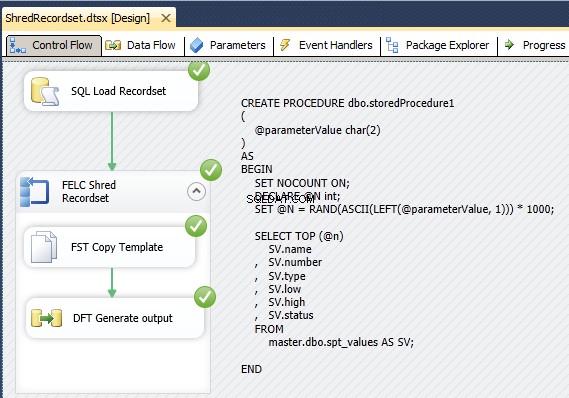
Wyobrażam sobie twój pakiet wyglądający mniej więcej tak
Wykonanie zadania SQL o nazwie „Zestaw rekordów ładowania SQL” dołączone do kontenera pętli Foreach o nazwie „Zestaw rekordów Shred FELC”. Zagnieżdżone tam mam zadanie systemu plików o nazwie „Szablon kopiowania FST”, które jest priorytetem dla zadania przepływu danych o nazwie „Wygeneruj dane wyjściowe DFT”.
Konfiguruj
Ponieważ jesteś początkującym, postaram się wyjaśnić szczegółowo. Aby zaoszczędzić sobie trochę kłopotów, pobierz kopię BIDSHelper. Jest to bezpłatne narzędzie typu open source, które poprawia komfort projektowania w BIDS/SSDT.
Zmienne
Kliknij tło swojego przepływu sterowania. Gdy nic nie jest zaznaczone, kliknij prawym przyciskiem myszy i wybierz Zmienne. W nowym oknie, które się pojawi, kliknij przycisk, który tworzy nową zmienną 4 razy. Powodem nie klikania na nic jest to, że do SQL Server 2012 domyślnym zachowaniem tworzenia zmiennych jest tworzenie ich w zakresie bieżącego obiektu. Spowodowało to utratę wielu włosów zarówno dla nowych, jak i doświadczonych programistów. W nazwach zmiennych rozróżniana jest wielkość liter, więc miej tego świadomość.
- Zmień nazwę zmiennej na RecordSet. Zmień typ danych z Int32 na Object
- Zmień nazwę zmiennej 1 na wartość parametru. Zmień typ danych z Int32 na String
- Zmień nazwę zmiennej 2 na plik szablonu. Zmień typ danych z Int32 na String. Ustaw wartość na ścieżkę wyjściowego pliku Excel. Użyłem C:\ssisdata\ShredRecordset.xlsx
- Zmień nazwę zmiennej 4 na OutputFileName. Zmień typ danych z Int32 na String. Tutaj zrobimy coś nieco zaawansowanego. Kliknij zmienną i naciśnij F4, aby wyświetlić okno Właściwości. Zmień wartość EvaluateAsExpression na True. W Wyrażeniu ustaw go na
"C:\\ssisdata\\ShredRecordset." + @[User::ParameterValue] + ".xlsx"(lub cokolwiek to jest twój plik i ścieżka). To, co robi, to konfiguruje zmienną, aby zmieniała się wraz ze zmianą wartości ParameterValue. Pomaga to zapewnić, że otrzymamy unikalną nazwę pliku. W razie potrzeby możesz zmienić konwencję nazewnictwa. Pamiętaj, że musisz zmienić znaczenie\za każdym razem, gdy jesteś w wyrażeniu.
Menedżerowie połączeń
Założyłem, że używasz menedżera połączeń OLE DB. Mój nazywa się FOO. Jeśli używasz ADO.NET, koncepcje będą podobne, ale pojawią się niuanse dotyczące parametrów i tym podobnych.
Do obsługi programu Excel potrzebny będzie również drugi menedżer połączeń. Jeśli SSIS ma temperament w stosunku do typów danych, Excel jest całkowicie psychotyczny, jeśli chodzi o typy danych. Zaczekamy i pozwolimy, aby przepływ danych faktycznie utworzył tego menedżera połączeń, aby upewnić się, że nasze typy są dobre.
Zapytanie źródłowe do zestawu wyników
SQL Load Recordset jest instancją wykonania zadania SQL. Tutaj mam proste zapytanie, które naśladuje twoje źródło.
SELECT 'aq' AS parameterValue
UNION ALL SELECT 'dr'
UNION ALL SELECT 'tb'
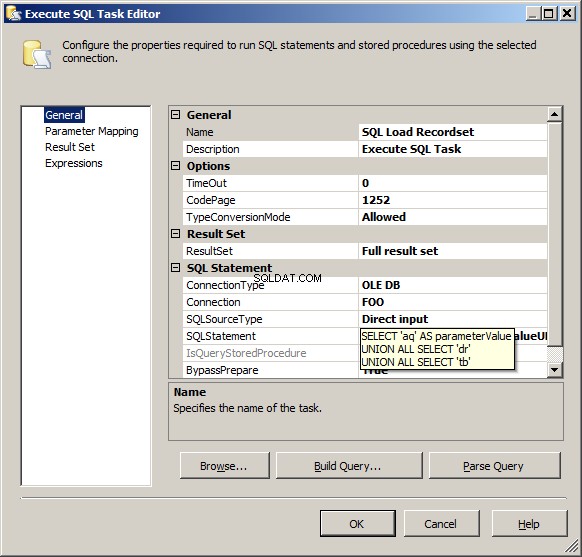
Należy zauważyć, że na karcie Ogólne zmieniłem zestaw wyników z None do Full result set . Spowoduje to, że karta Zestaw wyników zmieni się z wyszarzonej na użyteczną.
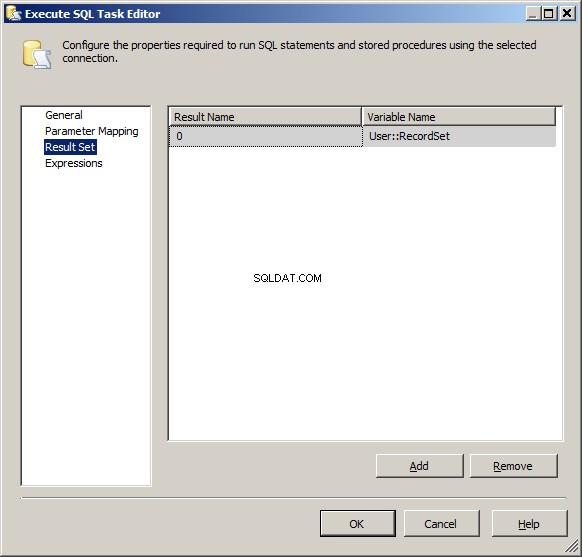 Można zauważyć, że przypisałem nazwę zmiennej do utworzonej powyżej zmiennej (User::RecordSet) i I nazwa wyniku to
Można zauważyć, że przypisałem nazwę zmiennej do utworzonej powyżej zmiennej (User::RecordSet) i I nazwa wyniku to 0 . Jest to ważne, ponieważ wartość domyślna NewResultName nie działa.
Zestaw nagrań niszczących FELC
Chwyć kontener pętli Foreach, a użyjemy go do „zniszczenia” wyników, które zostały wygenerowane w poprzednim kroku.
Skonfiguruj moduł wyliczający jako Foreach ADO Enumerator Użyj User::RecordSet jako zmienną źródłową obiektu ADO. Wybierz rows in the first table jako tryb wyliczania
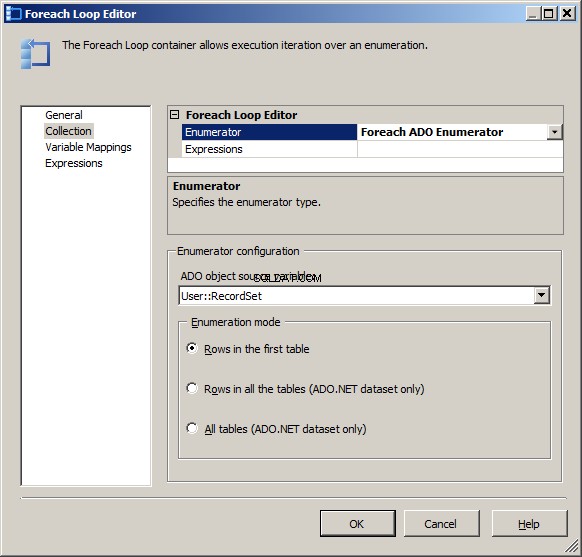
Na karcie Mapowania zmiennych musisz wybrać zmienną User::ParameterValue i przypisz mu Index równy 0. Spowoduje to przypisanie zerowego elementu w obiekcie zestawu rekordów do zmiennej ParameterValue. Ważne jest, aby mieć umowę typu danych, ponieważ usługi SSIS nie będą tutaj wykonywać niejawnych konwersji.
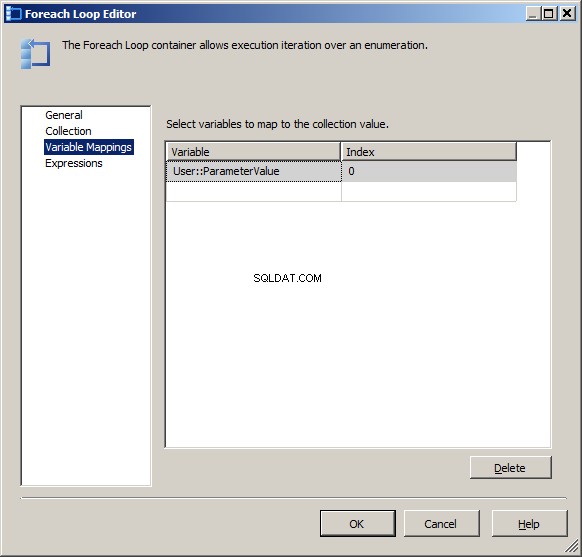
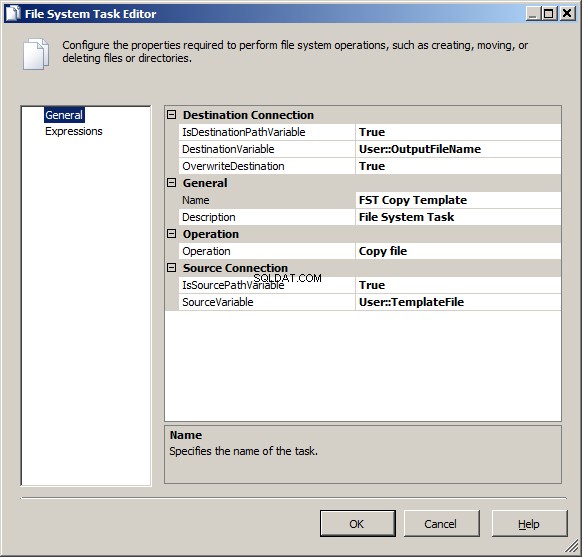
Szablon kopiowania FST
To zadanie systemu plików. Zamierzamy skopiować nasz szablon pliku Excel, aby mieć dobrze nazwany plik wyjściowy (zawiera nazwę parametru). Skonfiguruj jako
- IsDestinationPathVariable:prawda
- Zmienna docelowa:Użytkownik::OutputFileName
- Zastąp miejsce docelowe:prawda
- Operacja:Kopiuj plik
- IsSourcePathVariable:prawda
- ZmiennaŹródłowa:Użytkownik::Plik Szablonu
Generuj dane wyjściowe DFT
To jest zadanie przepływu danych. Zakładam, że po prostu zrzucasz wyniki bezpośrednio do pliku, więc będziemy potrzebować tylko źródła OLE DB i miejsca docelowego programu Excel
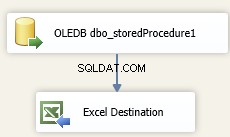
OLEDB dbo_storedProcedure1
W tym miejscu Twoje dane są pobierane z systemu źródłowego z parametrem, który zniszczyliśmy w Przepływie sterowania. Zamierzam napisać tutaj moje zapytanie i użyć ? aby wskazać, że ma parametr.
Zmień tryb dostępu do danych na „Polecenie SQL” i w dostępnym tekście polecenia SQL wpisz zapytanie
EXECUTE dbo.storedProcedure1 ?
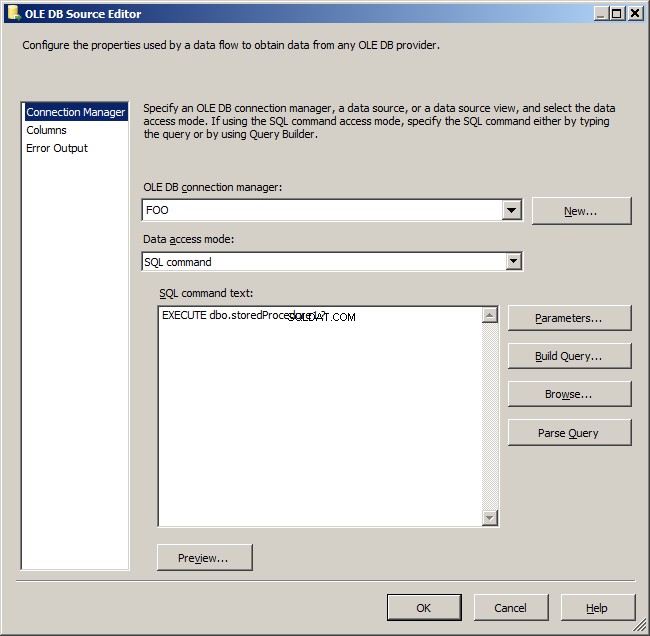
Klikam przycisk Parametry... i wypełniam go, jak pokazano
- Parametry:@parameterValue
- Zmienne:Użytkownik::ParameterValue
- Kierunek parametrów:wejście
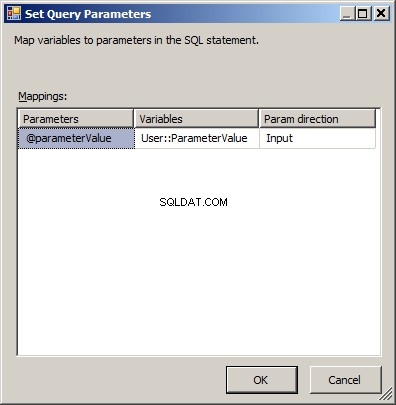
Połącz miejsce docelowe programu Excel ze źródłem OLE DB. Kliknij dwukrotnie i w sekcji Menedżer połączeń programu Excel kliknij Nowy... Określ, czy potrzebujesz formatu 2003 lub 2007 (xls vs. xlsx) i czy chcesz, aby plik miał wiersze nagłówka. W przypadku ścieżki pliku wpisz tę samą wartość, co w zmiennej @User::TemplatePath i kliknij przycisk OK.
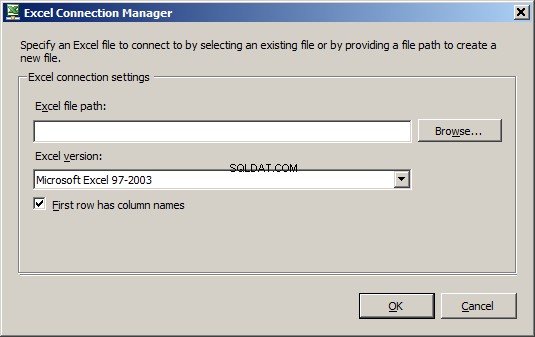
Musimy teraz wypełnić nazwę arkusza Excel. Kliknij ten przycisk Nowy... i może szczekać, że nie ma wystarczających informacji o mapowaniu typów danych. Nie martw się, to półstandard. Następnie pojawi się definicja tabeli, podobna do
CREATE TABLE `Excel Destination` (
`name` NVARCHAR(35),
`number` INT,
`type` NVARCHAR(3),
`low` INT,
`high` INT,
`status` INT
)
Nazwa „tabeli” będzie nazwą arkusza, a dokładnie nazwanym zestawem danych w arkuszu. Zrobiłem arkusz Sheet1 i kliknąłem OK. Teraz, gdy arkusz istnieje, wybierz go z listy rozwijanej. Wybrałem Sheet1$ jako nazwę arkusza docelowego. Nie jestem pewien, czy to robi różnicę.
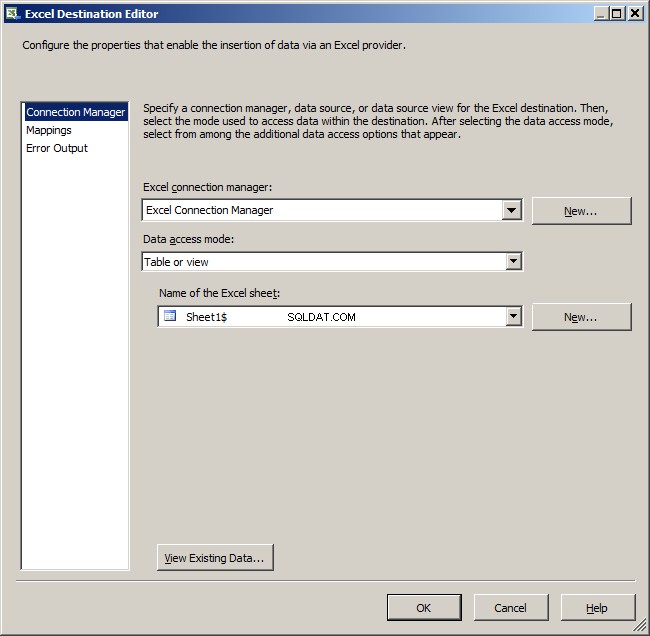
Kliknij kartę Mapowania, a wszystko powinno być automatycznie mapowane, więc kliknij OK.
Wreszcie
W tym momencie, gdybyśmy uruchomili pakiet, za każdym razem nadpisywałby plik szablonu. Sekret polega na tym, że musimy powiedzieć, że Excel Connection Manager właśnie sprawiliśmy, że nie musi mieć zakodowanej nazwy.
Kliknij raz na Menedżera połączeń programu Excel na karcie Menedżery połączeń. W oknie Właściwości znajdź Expressions sekcji i kliknij wielokropek ... Tutaj skonfigurujemy właściwość ExcelFilePath a wyrażenie, którego użyjemy to@[User::OutputFileName]
Jeśli twoje ikony i takie wyglądają inaczej, można się tego spodziewać. Zostało to udokumentowane za pomocą SSIS 2012. Przepływ pracy będzie taki sam w latach 2005 i 2008/2008 R2 tylko skóra jest inna.
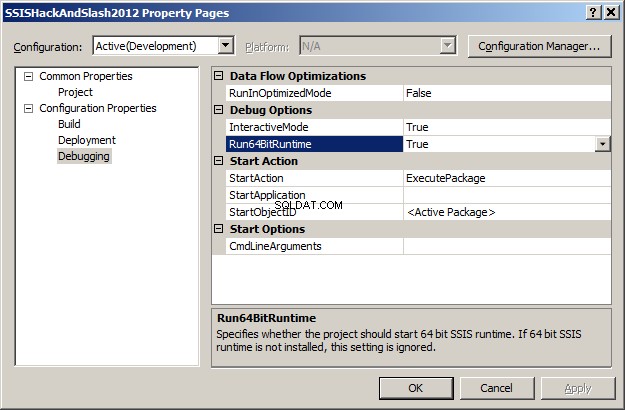
Jeśli uruchomisz ten pakiet i nawet się nie uruchomi, a pojawi się błąd dotyczący ACE 12 lub Jet 4.0, coś jest niedostępne, to jesteś na maszynie 64-bitowej i musisz powiedzieć BIDS/SSDT, że chcesz uruchomić w wersji 32-bitowej tryb.
Upewnij się, że wartość Run64BitRuntime to False . To ustawienie projektu można znaleźć, klikając prawym przyciskiem myszy projekt, rozwiń Właściwości konfiguracji i będzie to opcja w obszarze Debugowanie.
Dalsze czytanie
Inny przykład niszczenia obiektu zestawu rekordów można znaleźć w artykule Jak zautomatyzować wykonywanie procedury składowanej za pomocą pakietu SSIS?