Co sprawia, że zapytanie z zastosowaniem krzyżowym działa tak słabo na tym prostym dokumencie XML i działa wykładniczo wolniej wraz ze wzrostem zestawu danych?
Jest to użycie osi nadrzędnej do uzyskania identyfikatora atrybutu z węzła elementu.
To ta część planu zapytań jest problematyczna.

Zwróć uwagę na 423 wiersze wychodzące z niższej funkcji o wartościach w tabeli.
Dodanie jeszcze jednego węzła pozycji z trzema węzłami pól daje to.
Zwrócono 732 wierszy.
Co się stanie, jeśli podwoimy węzły z pierwszego zapytania do łącznie 6 węzłów pozycji?
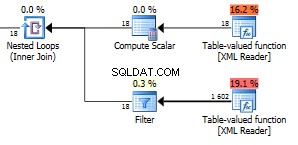
Zwróciliśmy aż 1602 wierszy.
Cyfra 18 w górnej funkcji to wszystkie węzły pól w Twoim XML. Mamy tutaj 6 pozycji z trzema polami w każdej pozycji. Tych 18 węzłów jest używanych w zagnieżdżonych pętlach sprzężonych z inną funkcją, więc 18 wykonań zwracających 1602 wiersze oznacza, że zwraca 89 wierszy na iterację. Tak się składa, że jest to dokładna liczba węzłów w całym XML. Cóż, w rzeczywistości jest to jeden więcej niż wszystkie widoczne węzły. Nie wiem dlaczego. Możesz użyć tego zapytania, aby sprawdzić całkowitą liczbę węzłów w swoim pliku XML.
select count(*)
from @XML.nodes('//*, //@*, //*/text()') as T(X)
Tak więc algorytm używany przez SQL Server do pobierania wartości, gdy używasz osi nadrzędnej .. w funkcji wartości jest to, że najpierw znajduje wszystkie węzły, na których niszczysz, 18 w ostatnim przypadku. Dla każdego z tych węzłów niszczy i zwraca cały dokument XML i sprawdza operator filtru dla węzła, którego faktycznie potrzebujesz. Tutaj masz swój wykładniczy wzrost. Zamiast korzystać z osi rodzicielskiej, powinieneś zastosować jeden dodatkowy krzyżyk. Najpierw niszcz przedmiot, a potem pole.
select I.X.value('@name', 'varchar(5)') as item_name,
F.X.value('@id', 'uniqueidentifier') as field_id,
F.X.value('@type', 'int') as field_type,
F.X.value('text()[1]', 'nvarchar(15)') as field_value
from #temp as T
cross apply T.x.nodes('/data/item') as I(X)
cross apply I.X.nodes('field') as F(X)
Zmieniłem również sposób dostępu do wartości tekstowej pola. Używając . sprawi, że SQL Server będzie szukał węzłów podrzędnych w field i połącz te wartości w wyniku. Nie masz wartości podrzędnych, więc wynik jest taki sam, ale dobrze jest unikać umieszczania tej części w planie zapytania (operator UDX).
Plan zapytania nie ma problemu z osią nadrzędną, jeśli używasz indeksu XML, ale nadal będziesz korzystać ze zmiany sposobu pobierania wartości pola.



