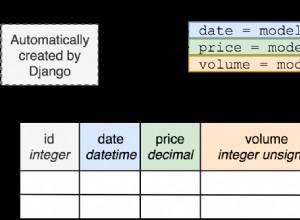
SELECT a, b, c
FROM (
SELECT *, ROW_NUMBER() OVER (PARTITION BY a ORDER BY b, c) rn
FROM mytable
) q
WHERE rn = 1
ORDER BY
a
lub
SELECT mi.*
FROM (
SELECT DISTINCT a
FROM mytable
) md
CROSS APPLY
(
SELECT TOP 1 *
FROM mytable mi
WHERE mi.a = md.a
ORDER BY
b, c
) mi
ORDER BY
a
Utwórz indeks złożony na (a, b, c) aby zapytania działały szybciej.
Który z nich jest bardziej wydajny, zależy od dystrybucji danych.
Jeśli masz kilka odrębnych wartości a ale wiele rekordów w każdym a , drugie zapytanie byłoby lepsze.
Możesz to poprawić jeszcze bardziej, tworząc widok indeksowany:
CREATE VIEW v_mytable_da
WITH SCHEMABINDING
AS
SELECT a, COUNT_BIG(*) cnt
FROM dbo.mytable
GROUP BY
a
GO
CREATE UNIQUE CLUSTERED INDEX
pk_vmytableda_a
ON v_mytable_da (a)
GO
SELECT mi.*
FROM v_mytable_da md
CROSS APPLY
(
SELECT TOP 1 *
FROM mytable mi
WHERE mi.a = md.a
ORDER BY
b, c
) mi
ORDER BY
a