W zeszłym roku opublikowałem wskazówkę zatytułowaną Popraw wydajność serwera SQL, przełączając się na wyzwalacze ZAMIAST.
Głównym powodem, dla którego preferuję wyzwalacz ZAMIAST, szczególnie w przypadkach, w których spodziewam się wielu naruszeń logiki biznesowej, jest to, że wydaje się intuicyjne, że taniej byłoby całkowicie zapobiec działaniu, niż kontynuować i wykonać je (i zarejestruj to!), tylko po to, aby użyć wyzwalacza PO, aby usunąć nieprawidłowe wiersze (lub wycofać całą operację). Wyniki pokazane w tej wskazówce pokazały, że tak było w rzeczywistości – i podejrzewam, że byłyby jeszcze bardziej widoczne w przypadku większej liczby nieklastrowanych indeksów dotkniętych operacją.
Było to jednak na wolnym dysku i na wczesnym CTP SQL Server 2014. Przygotowując slajd do nowej prezentacji, którą będę robił w tym roku na temat wyzwalaczy, odkryłem, że w nowszej wersji SQL Server 2014 – w połączeniu ze zaktualizowanym sprzętem – trochę trudniej było zademonstrować tę samą różnicę wydajności między wyzwalaczem AFTER i INSTEAD OF. Więc postanowiłem odkryć dlaczego, chociaż od razu wiedziałem, że będzie to więcej pracy, niż kiedykolwiek zrobiłem dla jednego slajdu.
Jedną rzeczą, o której chcę wspomnieć, jest to, że wyzwalacze mogą używać tempdb na różne sposoby, a to może wyjaśniać niektóre z tych różnic. Wyzwalacz AFTER używa magazynu wersji dla wstawionych i usuniętych pseudotabel, podczas gdy wyzwalacz INSTEAD OF tworzy kopię tych danych w wewnętrznej tabeli roboczej. Różnica jest subtelna, ale warta podkreślenia.
Zmienne
Zamierzam przetestować różne scenariusze, w tym:
- Trzy różne wyzwalacze:
- Wyzwalacz AFTER, który usuwa określone wiersze, które nie powiodły się
- Wyzwalacz AFTER, który wycofuje całą transakcję w przypadku niepowodzenia dowolnego wiersza
- Wyzwalacz ZAMIAST OF, który wstawia tylko wiersze, które przechodzą
- Różne modele odzyskiwania i ustawienia izolacji migawki:
- FULL z włączoną funkcją SNAPSHOT
- FULL z wyłączonym SNAPSHOT
- PROSTY z włączoną funkcją SNAPSHOT
- SIMPLE z wyłączonym SNAPSHOT
- Różne układy dysków*:
- Dane na dysku SSD, zaloguj się na dysk twardy 7200 obr./min
- Dane na SSD, zaloguj się na SSD
- Dane na 7200 obr./min HDD, zaloguj się na SSD
- Dane na dysku 7200 obr/min, logowanie na dysku 7200 obr/min
- Różne wskaźniki niepowodzeń:
- 10%, 25% i 50% wskaźnik niepowodzeń w całym:
- Wstawianie pojedynczej partii 20 000 wierszy
- 10 partii po 2000 wierszy
- 100 partii po 200 rzędów
- 1000 partii po 20 rzędów
- 20 000 wkładek singletonowych
*
tempdbto pojedynczy plik danych na wolnym dysku o prędkości 7200 obr./min. Jest to celowe i ma na celu wzmocnienie wszelkich wąskich gardeł spowodowanych różnymi zastosowaniamitempdb. Planuję wrócić do tego testu w pewnym momencie, gdytempdbjest na szybszym dysku SSD. - 10%, 25% i 50% wskaźnik niepowodzeń w całym:
OK, TL; DR już!
Jeśli chcesz tylko poznać wyniki, przejdź w dół. Wszystko w środku to tylko tło i wyjaśnienie, jak skonfigurowałem i przeprowadziłem testy. Nie mam złamanego serca, że nie wszyscy będą zainteresowani wszystkimi drobiazgami.
Scenariusz
W przypadku tego konkretnego zestawu testów rzeczywisty scenariusz to taki, w którym użytkownik wybiera nazwę ekranową, a wyzwalacz jest przeznaczony do wychwytywania przypadków, w których wybrana nazwa narusza pewne zasady. Na przykład nie może to być żadna odmiana „Ninny-Muggins” (z pewnością możesz użyć tutaj swojej wyobraźni).
Utworzyłem tabelę z 20 000 unikalnych nazw użytkowników:
USE model; GO -- 20,000 distinct, good Names ;WITH distinct_Names AS ( SELECT Name FROM sys.all_columns UNION SELECT Name FROM sys.all_objects ) SELECT TOP (20000) Name INTO dbo.GoodNamesSource FROM ( SELECT Name FROM distinct_Names UNION SELECT Name + 'x' FROM distinct_Names UNION SELECT Name + 'y' FROM distinct_Names UNION SELECT Name + 'z' FROM distinct_Names ) AS x; CREATE UNIQUE CLUSTERED INDEX x ON dbo.GoodNamesSource(Name);
Następnie stworzyłem tabelę, która byłaby źródłem moich „niegrzecznych imion” do sprawdzenia. W tym przypadku jest to po prostu ninny-muggins-00001 przez ninny-muggins-10000 :
USE model;
GO
CREATE TABLE dbo.NaughtyUserNames
(
Name NVARCHAR(255) PRIMARY KEY
);
GO
-- 10,000 "bad" names
INSERT dbo.NaughtyUserNames(Name)
SELECT N'ninny-muggins-' + RIGHT(N'0000' + RTRIM(n),5)
FROM
(
SELECT TOP (10000) n = ROW_NUMBER() OVER (ORDER BY Name)
FROM dbo.GoodNamesSource
) AS x;
Stworzyłem te tabele w model bazy danych, aby za każdym razem, gdy tworzę bazę danych, istniała ona lokalnie, i planuję utworzyć wiele baz danych, aby przetestować macierz scenariuszy wymienioną powyżej (zamiast zmieniać ustawienia bazy danych, czyścić dziennik itp.). Pamiętaj, że jeśli tworzysz obiekty w modelu do celów testowych, upewnij się, że usuniesz te obiekty, gdy skończysz.
Nawiasem mówiąc, zamierzam celowo pominąć naruszenia kluczy i inne obsługę błędów, przyjmując naiwne założenie, że wybrana nazwa jest sprawdzana pod kątem unikalności na długo przed próbą wstawienia, ale w ramach tej samej transakcji (tak jak w przypadku sprawdź z tabelą niegrzecznych imion, które można było zrobić wcześniej).
Aby to wesprzeć, stworzyłem również następujące trzy prawie identyczne tabele w model , do celów izolacji testowej:
USE model; GO -- AFTER (rollback) CREATE TABLE dbo.UserNames_After_Rollback ( UserID INT IDENTITY(1,1) PRIMARY KEY, Name NVARCHAR(255) NOT NULL UNIQUE, DateCreated DATE NOT NULL DEFAULT SYSDATETIME() ); CREATE INDEX x ON dbo.UserNames_After_Rollback(DateCreated) INCLUDE(Name); -- AFTER (delete) CREATE TABLE dbo.UserNames_After_Delete ( UserID INT IDENTITY(1,1) PRIMARY KEY, Name NVARCHAR(255) NOT NULL UNIQUE, DateCreated DATE NOT NULL DEFAULT SYSDATETIME() ); CREATE INDEX x ON dbo.UserNames_After_Delete(DateCreated) INCLUDE(Name); -- INSTEAD CREATE TABLE dbo.UserNames_Instead ( UserID INT IDENTITY(1,1) PRIMARY KEY, Name NVARCHAR(255) NOT NULL UNIQUE, DateCreated DATE NOT NULL DEFAULT SYSDATETIME() ); CREATE INDEX x ON dbo.UserNames_Instead(DateCreated) INCLUDE(Name); GO
Oraz następujące trzy wyzwalacze, po jednym dla każdej tabeli:
USE model;
GO
-- AFTER (rollback)
CREATE TRIGGER dbo.trUserNames_After_Rollback
ON dbo.UserNames_After_Rollback
AFTER INSERT
AS
BEGIN
SET NOCOUNT ON;
IF EXISTS
(
SELECT 1 FROM inserted AS i
WHERE EXISTS
(
SELECT 1 FROM dbo.NaughtyUserNames
WHERE Name = i.Name
)
)
BEGIN
ROLLBACK TRANSACTION;
END
END
GO
-- AFTER (delete)
CREATE TRIGGER dbo.trUserNames_After_Delete
ON dbo.UserNames_After_Delete
AFTER INSERT
AS
BEGIN
SET NOCOUNT ON;
DELETE d
FROM inserted AS i
INNER JOIN dbo.NaughtyUserNames AS n
ON i.Name = n.Name
INNER JOIN dbo.UserNames_After_Delete AS d
ON i.UserID = d.UserID;
END
GO
-- INSTEAD
CREATE TRIGGER dbo.trUserNames_Instead
ON dbo.UserNames_Instead
INSTEAD OF INSERT
AS
BEGIN
SET NOCOUNT ON;
INSERT dbo.UserNames_Instead(Name)
SELECT i.Name
FROM inserted AS i
WHERE NOT EXISTS
(
SELECT 1 FROM dbo.NaughtyUserNames
WHERE Name = i.Name
);
END
GO Prawdopodobnie chciałbyś rozważyć dodatkową obsługę, aby powiadomić użytkownika, że jego wybór został wycofany lub zignorowany – ale to również jest pominięte dla uproszczenia.
Konfiguracja testu
Stworzyłem przykładowe dane reprezentujące trzy wskaźniki awarii, które chciałem przetestować, zmieniając 10 procent na 25, a następnie 50 i dodając te tabele również do model :
USE model;
GO
DECLARE @pct INT = 10, @cap INT = 20000;
-- change this ----^^ to 25 and 50
DECLARE @good INT = @cap - (@cap*(@pct/100.0));
SELECT Name, rn = ROW_NUMBER() OVER (ORDER BY NEWID())
INTO dbo.Source10Percent FROM
-- change this ^^ to 25 and 50
(
SELECT Name FROM
(
SELECT TOP (@good) Name FROM dbo.GoodNamesSource ORDER BY NEWID()
) AS g
UNION ALL
SELECT Name FROM
(
SELECT TOP (@cap-@good) Name FROM dbo.NaughtyUserNames ORDER BY NEWID()
) AS b
) AS x;
CREATE UNIQUE CLUSTERED INDEX x ON dbo.Source10Percent(rn);
-- and here as well -------------------------^^ Każda tabela ma 20 000 wierszy, z inną mieszanką nazw, które zakończą się powodzeniem i niepowodzeniem, a kolumna numeru wiersza ułatwia podział danych na różne wielkości partii dla różnych testów, ale z powtarzalnymi wskaźnikami niepowodzeń dla wszystkich testów.
Oczywiście potrzebujemy miejsca na uchwycenie wyników. Zdecydowałem się użyć do tego oddzielnej bazy danych, uruchamiając każdy test wiele razy, po prostu przechwytując czas trwania.
CREATE DATABASE ControlDB; GO USE ControlDB; GO CREATE TABLE dbo.Tests ( TestID INT, DiskLayout VARCHAR(15), RecoveryModel VARCHAR(6), TriggerType VARCHAR(14), [snapshot] VARCHAR(3), FailureRate INT, [sql] NVARCHAR(MAX) ); CREATE TABLE dbo.TestResults ( TestID INT, BatchDescription VARCHAR(15), Duration INT );
Wypełniłem dbo.Tests tabeli z następującym skryptem, abym mógł wykonać różne części, aby ustawić cztery bazy danych tak, aby odpowiadały bieżącym parametrom testu. Zwróć uwagę, że D:\ to dysk SSD, a G:\ to dysk o prędkości 7200 obr./min:
TRUNCATE TABLE dbo.Tests;
TRUNCATE TABLE dbo.TestResults;
;WITH d AS
(
SELECT DiskLayout FROM (VALUES
('DataSSD_LogHDD'),
('DataSSD_LogSSD'),
('DataHDD_LogHDD'),
('DataHDD_LogSSD')) AS d(DiskLayout)
),
t AS
(
SELECT TriggerType FROM (VALUES
('After_Delete'),
('After_Rollback'),
('Instead')) AS t(TriggerType)
),
m AS
(
SELECT RecoveryModel = 'FULL'
UNION ALL SELECT 'SIMPLE'
),
s AS
(
SELECT IsSnapshot = 0
UNION ALL SELECT 1
),
p AS
(
SELECT FailureRate = 10
UNION ALL SELECT 25
UNION ALL SELECT 50
)
INSERT ControlDB.dbo.Tests
(
TestID,
DiskLayout,
RecoveryModel,
TriggerType,
IsSnapshot,
FailureRate,
Command
)
SELECT
TestID = ROW_NUMBER() OVER
(
ORDER BY d.DiskLayout, t.TriggerType, m.RecoveryModel, s.IsSnapshot, p.FailureRate
),
d.DiskLayout,
m.RecoveryModel,
t.TriggerType,
s.IsSnapshot,
p.FailureRate,
[sql]= N'SET NOCOUNT ON;
CREATE DATABASE ' + QUOTENAME(d.DiskLayout)
+ N' ON (name = N''data'', filename = N''' + CASE d.DiskLayout
WHEN 'DataSSD_LogHDD' THEN N'D:\data\data1.mdf'')
LOG ON (name = N''log'', filename = N''G:\log\data1.ldf'');'
WHEN 'DataSSD_LogSSD' THEN N'D:\data\data2.mdf'')
LOG ON (name = N''log'', filename = N''D:\log\data2.ldf'');'
WHEN 'DataHDD_LogHDD' THEN N'G:\data\data3.mdf'')
LOG ON (name = N''log'', filename = N''G:\log\data3.ldf'');'
WHEN 'DataHDD_LogSSD' THEN N'G:\data\data4.mdf'')
LOG ON (name = N''log'', filename = N''D:\log\data4.ldf'');' END
+ '
EXEC sp_executesql N''ALTER DATABASE ' + QUOTENAME(d.DiskLayout)
+ ' SET RECOVERY ' + m.RecoveryModel + ';'';'
+ CASE WHEN s.IsSnapshot = 1 THEN
'
EXEC sp_executesql N''ALTER DATABASE ' + QUOTENAME(d.DiskLayout)
+ ' SET ALLOW_SNAPSHOT_ISOLATION ON;'';
EXEC sp_executesql N''ALTER DATABASE ' + QUOTENAME(d.DiskLayout)
+ ' SET READ_COMMITTED_SNAPSHOT ON;'';'
ELSE '' END
+ '
DECLARE @d DATETIME2(7), @i INT, @LoopID INT, @loops INT, @perloop INT;
DECLARE c CURSOR LOCAL FAST_FORWARD FOR
SELECT LoopID, loops, perloop FROM dbo.Loops;
OPEN c;
FETCH c INTO @LoopID, @loops, @perloop;
WHILE @@FETCH_STATUS <> -1
BEGIN
EXEC sp_executesql N''TRUNCATE TABLE '
+ QUOTENAME(d.DiskLayout) + '.dbo.UserNames_' + t.TriggerType + ';'';
SELECT @d = SYSDATETIME(), @i = 1;
WHILE @i <= @loops
BEGIN
BEGIN TRY
INSERT ' + QUOTENAME(d.DiskLayout) + '.dbo.UserNames_' + t.TriggerType + '(Name)
SELECT Name FROM ' + QUOTENAME(d.DiskLayout) + '.dbo.Source' + RTRIM(p.FailureRate) + 'Percent
WHERE rn > (@i-1)*@perloop AND rn <= @i*@perloop;
END TRY
BEGIN CATCH
SET @TestID = @TestID;
END CATCH
SET @i += 1;
END
INSERT ControlDB.dbo.TestResults(TestID, LoopID, Duration)
SELECT @TestID, @LoopID, DATEDIFF(MILLISECOND, @d, SYSDATETIME());
FETCH c INTO @LoopID, @loops, @perloop;
END
CLOSE c;
DEALLOCATE c;
DROP DATABASE ' + QUOTENAME(d.DiskLayout) + ';'
FROM d, t, m, s, p; -- implicit CROSS JOIN! Do as I say, not as I do! :-) Następnie można było łatwo przeprowadzić wszystkie testy wielokrotnie:
USE ControlDB;
GO
SET NOCOUNT ON;
DECLARE @TestID INT, @Command NVARCHAR(MAX), @msg VARCHAR(32);
DECLARE d CURSOR LOCAL FAST_FORWARD FOR
SELECT TestID, Command
FROM ControlDB.dbo.Tests ORDER BY TestID;
OPEN d;
FETCH d INTO @TestID, @Command;
WHILE @@FETCH_STATUS <> -1
BEGIN
SET @msg = 'Starting ' + RTRIM(@TestID);
RAISERROR(@msg, 0, 1) WITH NOWAIT;
EXEC sp_executesql @Command, N'@TestID INT', @TestID;
SET @msg = 'Finished ' + RTRIM(@TestID);
RAISERROR(@msg, 0, 1) WITH NOWAIT;
FETCH d INTO @TestID, @Command;
END
CLOSE d;
DEALLOCATE d;
GO 10
W moim systemie zajęło to prawie 6 godzin, więc przygotuj się na nieprzerwane działanie. Upewnij się również, że nie masz żadnych aktywnych połączeń ani otwartych okien zapytań względem model bazy danych, w przeciwnym razie możesz otrzymać ten błąd, gdy skrypt próbuje utworzyć bazę danych:
Nie można uzyskać blokady na wyłączność „modelu” bazy danych. Ponów operację później.
Wyniki
Istnieje wiele punktów danych, którym należy się przyjrzeć (a wszystkie zapytania używane do uzyskania danych znajdują się w Dodatku). Pamiętaj, że każdy podany tutaj średni czas trwania to ponad 10 testów i wstawia łącznie 100 000 wierszy do tabeli docelowej.
Wykres 1 – Ogólne agregaty
Pierwszy wykres pokazuje ogólne agregaty (średni czas trwania) dla różnych zmiennych w izolacji (czyli *wszystkie* testy używające wyzwalacza AFTER, który usuwa, *wszystkie* testy używające wyzwalacza AFTER, który cofa się itd.).
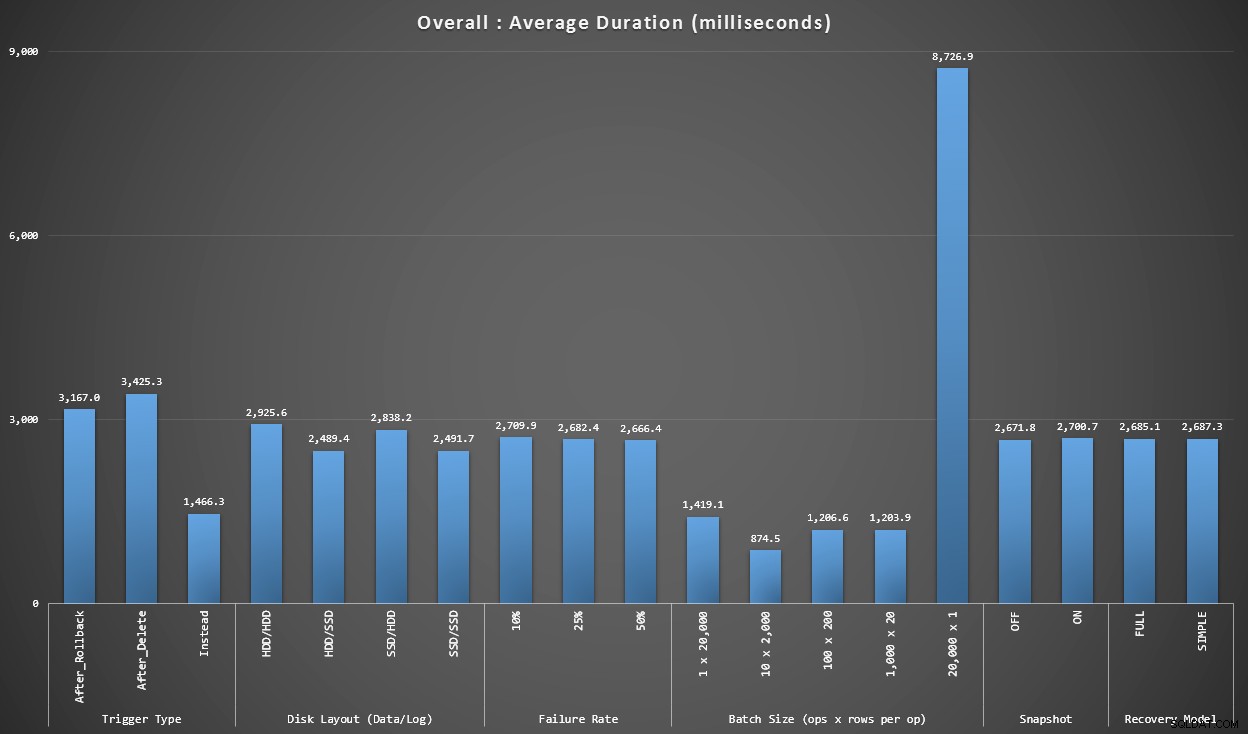
Średni czas trwania w milisekundach dla każdej izolowanej zmiennej
Kilka rzeczy wyskakuje nam od razu:
- Tutaj wyzwalacz INSTEAD OF jest dwa razy szybszy niż oba wyzwalacze AFTER.
- Dziennik transakcji na dysku SSD zrobił pewną różnicę. Znacznie mniej lokalizacji pliku danych.
- Partia 20 000 pojedynczych wkładek była 7-8 razy wolniejsza niż jakakolwiek inna dystrybucja partii.
- Wstawianie pojedynczej partii z 20 000 wierszy było wolniejsze niż którakolwiek z dystrybucji innych niż pojedyncze.
- Wskaźnik awarii, izolacja migawek i model odzyskiwania miały niewielki, jeśli w ogóle, wpływ na wydajność.
Wykres 2 – Najlepsze 10 ogółem
Ten wykres pokazuje 10 najszybszych wyników, gdy uwzględni się każdą zmienną. Są to wszystkie wyzwalacze INSTEAD OF, w których największy procent wierszy kończy się niepowodzeniem (50%). Co zaskakujące, najszybszy (choć nie za dużo) miał zarówno dane, jak i logowanie na tym samym dysku twardym (nie SSD). Istnieje tutaj mieszanka układów dysków i modeli odzyskiwania, ale wszystkie 10 miały włączoną izolację migawek, a wszystkie 7 najlepszych wyników obejmowało rozmiar partii 10 x 2000 wierszy.
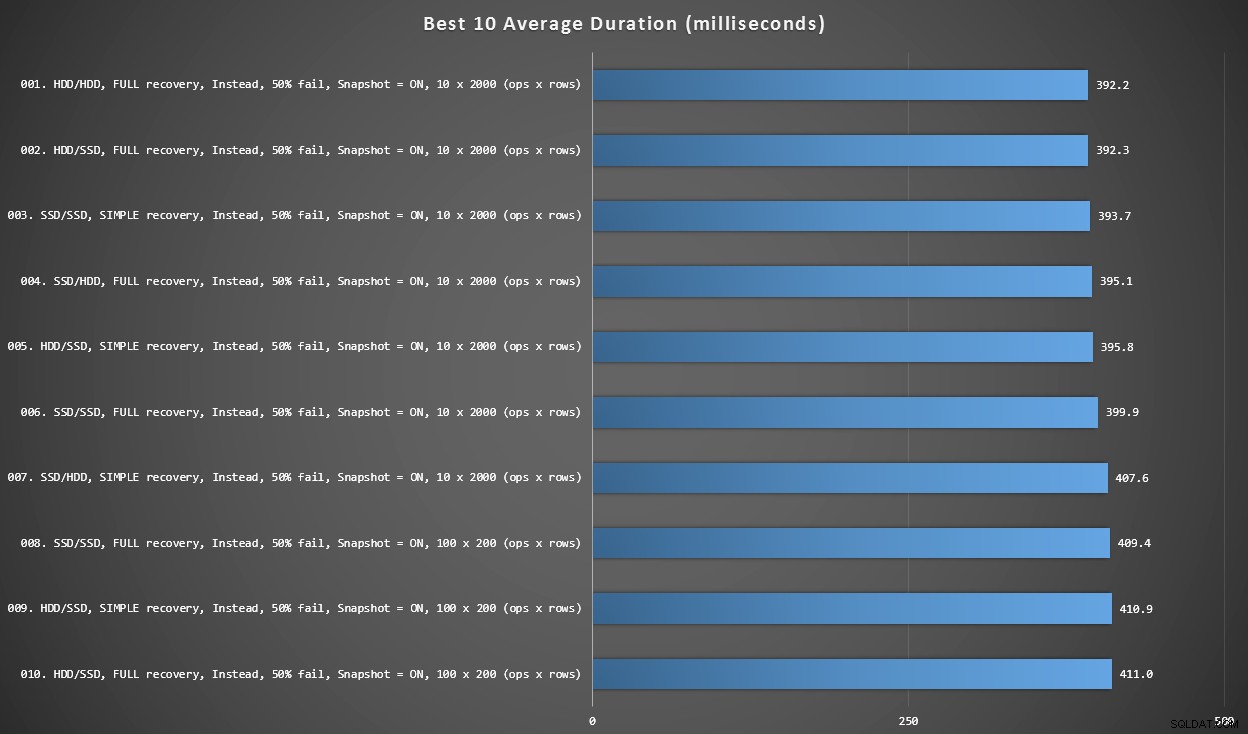
10 najlepszych czasów trwania w milisekundach, biorąc pod uwagę każdą zmienną
Najszybszy wyzwalacz AFTER – wariant ROLLBACK z 10% współczynnikiem awaryjności w wielkości partii rzędu 100 x 200 – znalazł się na pozycji #144 (806 ms).
Wykres 3 – Najgorsze 10 ogólnie
Ten wykres pokazuje najwolniejsze 10 wyników, gdy weźmie się pod uwagę każdą zmienną; wszystkie są wariantami PO, wszystkie obejmują 20 000 pojedynczych wkładek i wszystkie mają dane i logują się na tym samym wolnym dysku twardym.
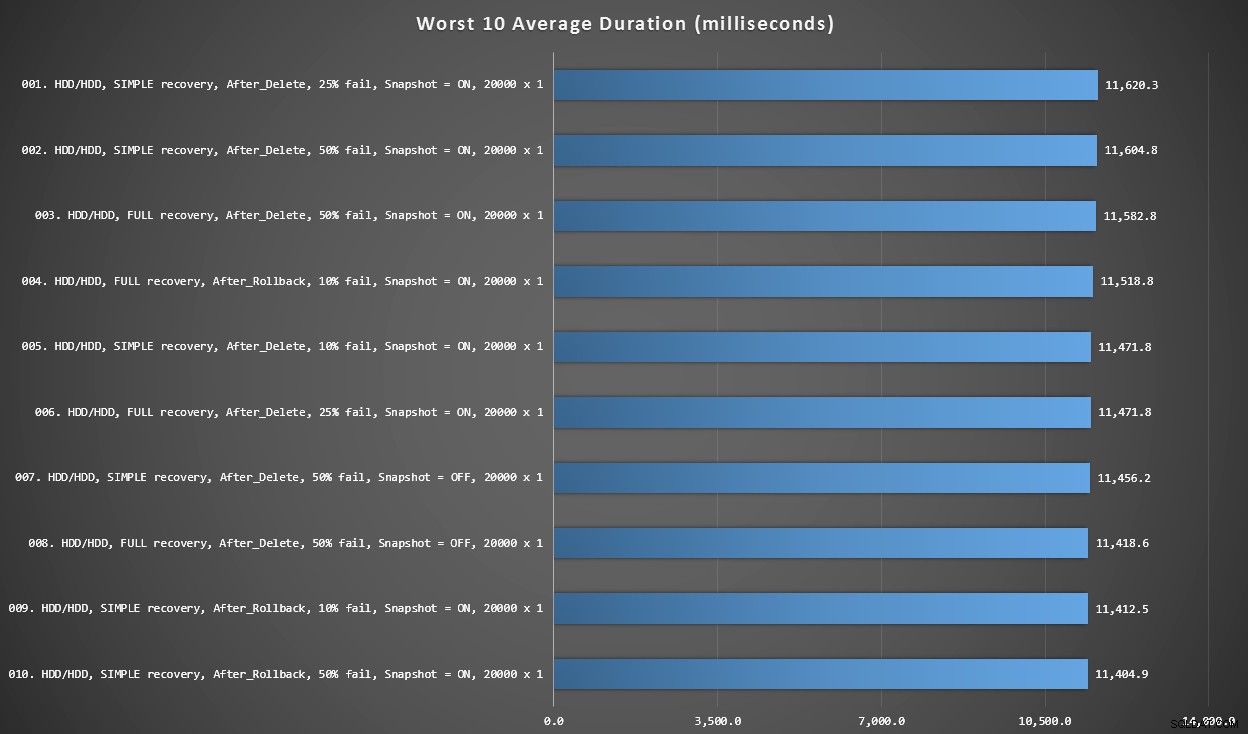
10 najgorszych czasów trwania w milisekundach, biorąc pod uwagę każdą zmienną
Najwolniejszy test INSTEAD OF znajdował się na pozycji 97, przy 5680 ms – 20 000 testach z pojedynczą wkładką, w którym 10% zakończyło się niepowodzeniem. Interesujące jest również to, że ani jeden wyzwalacz AFTER przy użyciu wielkości partii 20 000 pojedynczych wkładek nie wypadł lepiej – w rzeczywistości 96. najgorszy wynik to test PO (usuwanie), który pojawił się po 10 219 ms – prawie dwukrotność kolejnego najwolniejszego wyniku.
Wykres 4 – Typ dysku dziennika, wstawki singletonowe
Powyższe wykresy dają nam z grubsza wyobrażenie o największych problemach, ale są one albo zbyt powiększone, albo niewystarczająco powiększone. Ten wykres filtruje dane oparte na rzeczywistości:w większości przypadków tego typu operacja będzie wstawką singletonową. Pomyślałem, że podzielę to według wskaźnika awaryjności i typu dysku, na którym znajduje się dziennik, ale spójrz tylko na wiersze, w których partia składa się z 20 000 pojedynczych wstawek.
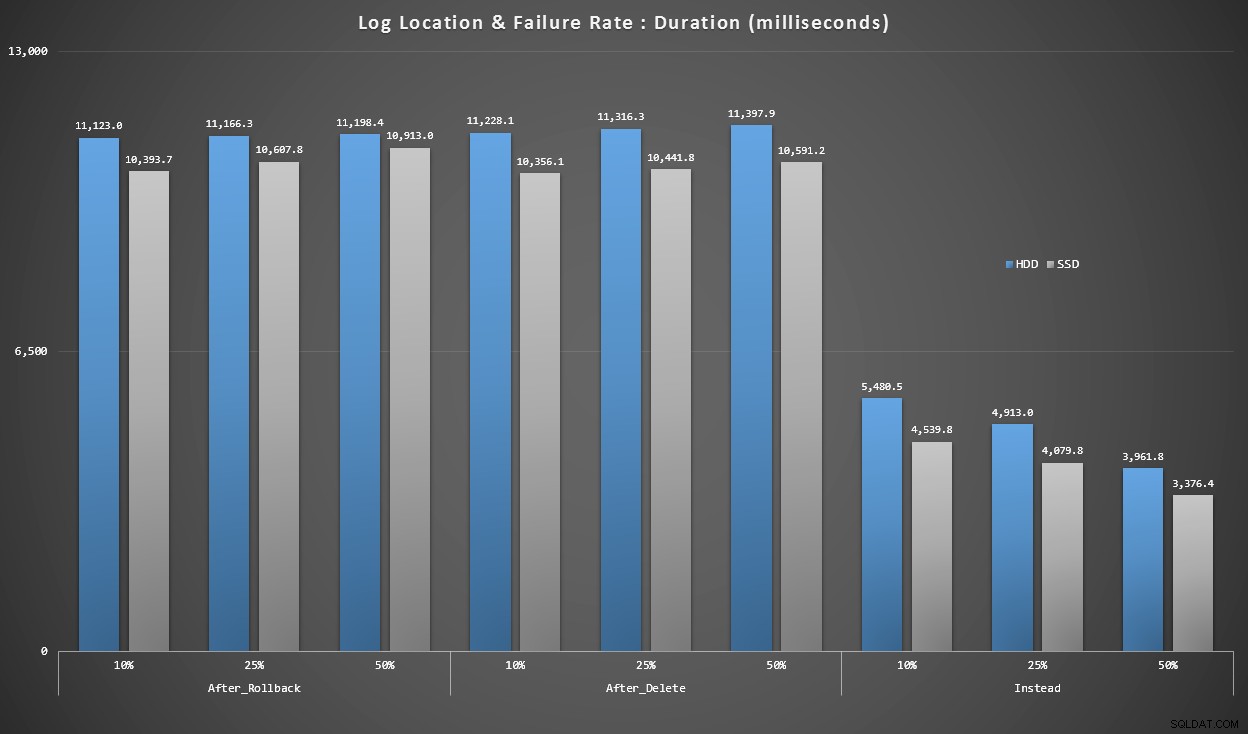
Czas trwania w milisekundach, pogrupowany według wskaźnika awarii i lokalizacji dziennika, na 20 000 pojedynczych wkładek
Widzimy tutaj, że wszystkie wyzwalacze AFTER są średnio w zakresie 10-11 sekund (w zależności od lokalizacji dziennika), podczas gdy wszystkie wyzwalacze INSTEAD OF są znacznie poniżej znaku 6 sekund.
Wniosek
Jak dotąd wydaje mi się jasne, że wyzwalacz INSTEAD OF jest zwycięzcą w większości przypadków – w niektórych przypadkach bardziej niż w innych (na przykład, gdy wskaźnik niepowodzeń rośnie). Inne czynniki, takie jak model odzyskiwania, wydają się mieć znacznie mniejszy wpływ na ogólną wydajność.
Jeśli masz inne pomysły na rozbicie danych lub chcesz otrzymać kopię danych do samodzielnego krojenia i kostkowania, daj mi znać. Jeśli potrzebujesz pomocy w skonfigurowaniu tego środowiska, aby móc przeprowadzać własne testy, mogę również w tym pomóc.
Chociaż ten test pokazuje, że wyzwalacze INSTEAD OF są zdecydowanie warte rozważenia, nie jest to cała historia. Dosłownie połączyłem te wyzwalacze, używając logiki, która moim zdaniem była najbardziej sensowna dla każdego scenariusza, ale kod wyzwalacza – jak każde polecenie T-SQL – można dostroić w celu uzyskania optymalnych planów. W kolejnym poście przyjrzę się potencjalnej optymalizacji, która może sprawić, że element AFTER będzie bardziej konkurencyjny.
Załącznik
Zapytania użyte w sekcji Wyniki:
Wykres 1 – Ogólne agregaty
SELECT RTRIM(l.loops) + ' x ' + RTRIM(l.perloop), AVG(r.Duration*1.0) FROM dbo.TestResults AS r INNER JOIN dbo.Loops AS l ON r.LoopID = l.LoopID GROUP BY RTRIM(l.loops) + ' x ' + RTRIM(l.perloop); SELECT t.IsSnapshot, AVG(Duration*1.0) FROM dbo.TestResults AS tr INNER JOIN dbo.Tests AS t ON tr.TestID = t.TestID GROUP BY t.IsSnapshot; SELECT t.RecoveryModel, AVG(Duration*1.0) FROM dbo.TestResults AS tr INNER JOIN dbo.Tests AS t ON tr.TestID = t.TestID GROUP BY t.RecoveryModel; SELECT t.DiskLayout, AVG(Duration*1.0) FROM dbo.TestResults AS tr INNER JOIN dbo.Tests AS t ON tr.TestID = t.TestID GROUP BY t.DiskLayout; SELECT t.TriggerType, AVG(Duration*1.0) FROM dbo.TestResults AS tr INNER JOIN dbo.Tests AS t ON tr.TestID = t.TestID GROUP BY t.TriggerType; SELECT t.FailureRate, AVG(Duration*1.0) FROM dbo.TestResults AS tr INNER JOIN dbo.Tests AS t ON tr.TestID = t.TestID GROUP BY t.FailureRate;
Wykres 2 i 3 – Najlepsze i najgorsze 10
;WITH src AS
(
SELECT DiskLayout, RecoveryModel, TriggerType, FailureRate, IsSnapshot,
Batch = RTRIM(l.loops) + ' x ' + RTRIM(l.perloop),
Duration = AVG(Duration*1.0)
FROM dbo.Tests AS t
INNER JOIN dbo.TestResults AS tr
ON tr.TestID = t.TestID
INNER JOIN dbo.Loops AS l
ON tr.LoopID = l.LoopID
GROUP BY DiskLayout, RecoveryModel, TriggerType, FailureRate, IsSnapshot,
RTRIM(l.loops) + ' x ' + RTRIM(l.perloop)
),
agg AS
(
SELECT label = REPLACE(REPLACE(DiskLayout,'Data',''),'_Log','/')
+ ', ' + RecoveryModel + ' recovery, ' + TriggerType
+ ', ' + RTRIM(FailureRate) + '% fail'
+ ', Snapshot = ' + CASE IsSnapshot WHEN 1 THEN 'ON' ELSE 'OFF' END
+ ', ' + Batch + ' (ops x rows)',
best10 = ROW_NUMBER() OVER (ORDER BY Duration),
worst10 = ROW_NUMBER() OVER (ORDER BY Duration DESC),
Duration
FROM src
)
SELECT grp, label, Duration FROM
(
SELECT TOP (20) grp = 'best', label = RIGHT('0' + RTRIM(best10),2) + '. ' + label, Duration
FROM agg WHERE best10 <= 10
ORDER BY best10 DESC
UNION ALL
SELECT TOP (20) grp = 'worst', label = RIGHT('0' + RTRIM(worst10),2) + '. ' + label, Duration
FROM agg WHERE worst10 <= 10
ORDER BY worst10 DESC
) AS b
ORDER BY grp; Wykres 4 – Typ dysku dziennika, wstawki singletonowe
;WITH x AS
(
SELECT
TriggerType,FailureRate,
LogLocation = RIGHT(DiskLayout,3),
Duration = AVG(Duration*1.0)
FROM dbo.TestResults AS tr
INNER JOIN dbo.Tests AS t
ON tr.TestID = t.TestID
INNER JOIN dbo.Loops AS l
ON l.LoopID = tr.LoopID
WHERE l.loops = 20000
GROUP BY RIGHT(DiskLayout,3), FailureRate, TriggerType
)
SELECT TriggerType, FailureRate,
HDDDuration = MAX(CASE WHEN LogLocation = 'HDD' THEN Duration END),
SSDDuration = MAX(CASE WHEN LogLocation = 'SSD' THEN Duration END)
FROM x
GROUP BY TriggerType, FailureRate
ORDER BY TriggerType, FailureRate;