Zrzut ekranu nr 1 pokazuje kilka punktów do rozróżnienia między Merge Join transformation i Lookup transformation .
Jeśli chodzi o wyszukiwanie:
Jeśli chcesz znaleźć wiersze pasujące w źródle 2 na podstawie danych wejściowych ze źródła 1 i jeśli wiesz, że dla każdego wiersza wejściowego będzie tylko jedno dopasowanie, sugerowałbym użycie operacji Lookup. Przykładem może być OrderDetails tabeli i chcesz znaleźć pasujący Order Id i Customer Number , wtedy Lookup jest lepszą opcją.
Jeśli chodzi o połączenie scalające:
Jeśli chcesz wykonać połączenia, takie jak pobieranie wszystkich adresów (dom, praca, inne) z Address tabela dla danego Klienta w zakładce Customer tabeli, musisz przejść do opcji Merge Join, ponieważ klient może mieć przypisany 1 lub więcej adresów.
Przykład do porównania:
Oto scenariusz demonstrujący różnice w wydajności między Merge Join i Lookup . Użyte tutaj dane to sprzężenie jeden do jednego, co jest jedynym wspólnym scenariuszem do porównania.
-
Mam trzy tabele o nazwie
dbo.ItemPriceInfo,dbo.ItemDiscountInfoidbo.ItemAmount. Tworzenie skryptów dla tych tabel znajduje się w sekcji Skrypty SQL. -
Tabele
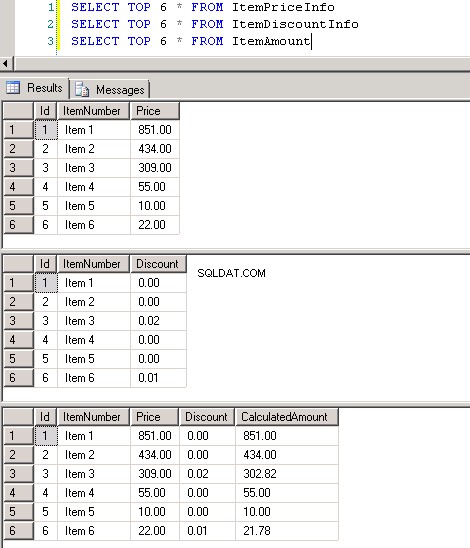
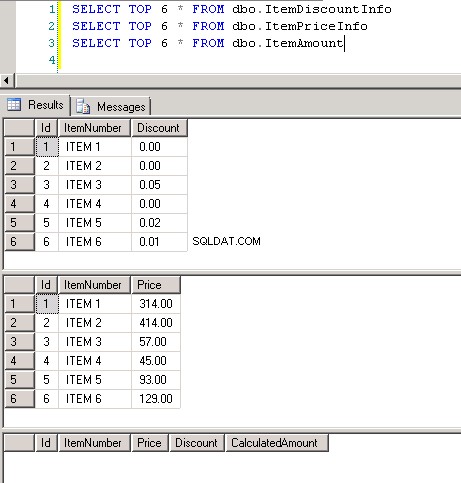
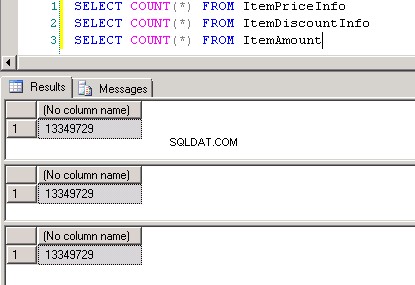
dbo.ItemPriceInfoidbo.ItemDiscountInfooba mają 13 349 729 wierszy. Obie tabele mają jako wspólną kolumnę ItemNumber. ItemPriceInfo ma informacje o cenie, a ItemDiscountInfo ma informacje o rabacie. Zrzut ekranu #2 pokazuje liczbę wierszy w każdej z tych tabel. Zrzut ekranu #3 pokazuje 6 górnych wierszy, aby dać wyobrażenie o danych obecnych w tabelach. -
Utworzyłem dwa pakiety SSIS, aby porównać wydajność przekształceń Merge Join i Lookup. Oba pakiety muszą pobierać informacje z tabel
dbo.ItemPriceInfoidbo.ItemDiscountInfo, oblicz łączną kwotę i zapisz ją w tabelidbo.ItemAmount. -
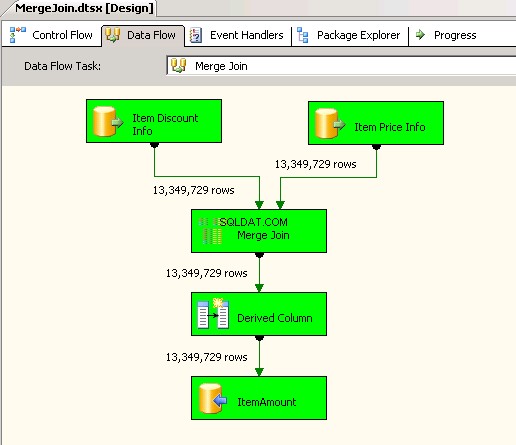
Pierwszy pakiet użyty
Merge Jointransformacji i wewnątrz, że używał INNER JOIN do łączenia danych. Zrzuty ekranu #4 i #5 pokaż przykładowe wykonanie pakietu i czas realizacji. Zajęło to05minuty14sekundy719milisekundy na wykonanie pakietu opartego na transformacji Merge Join. -
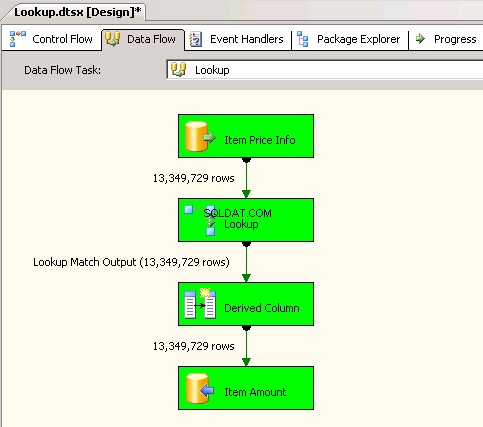
Drugi pakiet używany
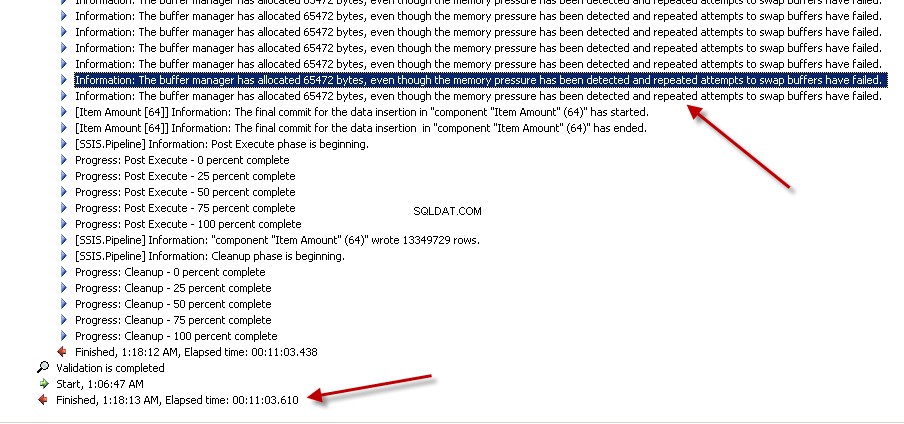
Lookuptransformacja z pełną pamięcią podręczną (co jest ustawieniem domyślnym). zrzuty ekranu #6 i #7 pokaż przykładowe wykonanie pakietu i czas realizacji. Zajęło to11minuty03sekund610milisekundy na wykonanie pakietu opartego na transformacji wyszukiwania. Możesz napotkać komunikat ostrzegawczy Informacja:The buffer manager has allocated nnnnn bytes, even though the memory pressure has been detected and repeated attempts to swap buffers have failed.Oto link mówi o tym, jak obliczyć rozmiar pamięci podręcznej wyszukiwania. Podczas wykonywania tego pakietu, mimo że zadanie przepływu danych zostało ukończone szybciej, czyszczenie potoku zajęło dużo czasu. -
To nie oznacza, że transformacja wyszukiwania jest zła. Tyle tylko, że trzeba go mądrze używać. Używam tego dość często w moich projektach, ale znowu nie mam do czynienia z ponad 10 milionami wierszy do wyszukiwania każdego dnia. Zwykle moje prace obejmują od 2 do 3 milionów wierszy, a do tego wydajność jest naprawdę dobra. Do 10 milionów wierszy, oba działały równie dobrze. Przez większość czasu zauważyłem, że wąskie gardło okazuje się raczej komponentem docelowym niż transformacjami. Możesz to przezwyciężyć, mając wiele miejsc docelowych. Tu to przykład pokazujący implementację wielu miejsc docelowych.
-
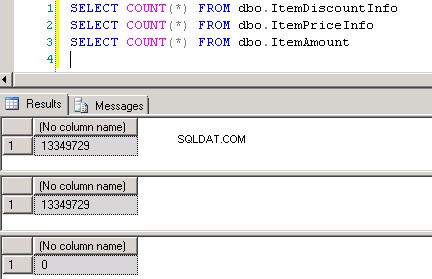
Zrzut ekranu nr 8 pokazuje liczbę rekordów we wszystkich trzech tabelach. Zrzut ekranu nr 9 pokazuje 6 najlepszych rekordów w każdej tabeli.
Mam nadzieję, że to pomoże.
Skrypty SQL:
CREATE TABLE [dbo].[ItemAmount](
[Id] [int] IDENTITY(1,1) NOT NULL,
[ItemNumber] [nvarchar](30) NOT NULL,
[Price] [numeric](18, 2) NOT NULL,
[Discount] [numeric](18, 2) NOT NULL,
[CalculatedAmount] [numeric](18, 2) NOT NULL,
CONSTRAINT [PK_ItemAmount] PRIMARY KEY CLUSTERED ([Id] ASC)) ON [PRIMARY]
GO
CREATE TABLE [dbo].[ItemDiscountInfo](
[Id] [int] IDENTITY(1,1) NOT NULL,
[ItemNumber] [nvarchar](30) NOT NULL,
[Discount] [numeric](18, 2) NOT NULL,
CONSTRAINT [PK_ItemDiscountInfo] PRIMARY KEY CLUSTERED ([Id] ASC)) ON [PRIMARY]
GO
CREATE TABLE [dbo].[ItemPriceInfo](
[Id] [int] IDENTITY(1,1) NOT NULL,
[ItemNumber] [nvarchar](30) NOT NULL,
[Price] [numeric](18, 2) NOT NULL,
CONSTRAINT [PK_ItemPriceInfo] PRIMARY KEY CLUSTERED ([Id] ASC)) ON [PRIMARY]
GO
Zrzut ekranu nr 1:

Zrzut ekranu nr 2:
Zrzut ekranu nr 3:
Zrzut ekranu nr 4:
Zrzut ekranu nr 5:

Zrzut ekranu nr 6:
Zrzut ekranu nr 7:
Zrzut ekranu nr 8:
Zrzut ekranu nr 9: