TimescaleDB to baza danych typu open source wymyślona w celu skalowania SQL dla danych szeregów czasowych. To stosunkowo nowy system baz danych. TimescaleDB został wprowadzony na rynek dwa lata temu i osiągnął wersję 1.0 we wrześniu 2018 roku. Niemniej jednak jest zaprojektowany na bazie dojrzałego systemu RDBMS.
TimescaleDB jest spakowany jako rozszerzenie PostgreSQL. Cały kod jest objęty licencją open-source Apache-2, z wyjątkiem niektórych kodów źródłowych związanych z funkcjami korporacyjnymi serii czasowych licencjonowanymi na podstawie licencji Timescale (TSL).
Jako baza danych szeregów czasowych zapewnia automatyczne partycjonowanie według daty i wartości kluczy. Natywna obsługa SQL TimescaleDB sprawia, że jest to dobra opcja dla tych, którzy planują przechowywanie danych szeregów czasowych i mają już solidną znajomość języka SQL.
Jeśli szukasz bazy danych szeregów czasowych, która może korzystać z bogatego SQL, HA, solidnego rozwiązania do tworzenia kopii zapasowych, replikacji i innych funkcji dla przedsiębiorstw, ten blog może skierować Cię na właściwą ścieżkę.
Kiedy używać TimescaleDB
Zanim zaczniemy od funkcji TimescaleDB, zobaczmy, gdzie może się zmieścić. TimescaleDB został zaprojektowany tak, aby oferować to, co najlepsze zarówno z relacyjnych, jak i NoSQL, z naciskiem na szeregi czasowe. Ale czym są dane szeregów czasowych?
Dane szeregów czasowych leżą u podstaw Internetu Rzeczy, systemów monitoringu i wielu innych rozwiązań skoncentrowanych na częstych zmianach danych. Jak sugeruje nazwa „seria czasowa”, mówimy o danych, które zmieniają się w czasie. Możliwości tego typu DBMS są nieograniczone. Można go używać w różnych przemysłowych zastosowaniach IoT w sektorach produkcji, górnictwa, ropy i gazu, handlu detalicznego, opieki zdrowotnej, monitorowania deweloperów lub informacji finansowych. Może również doskonale pasować do potoków uczenia maszynowego lub jako źródło operacji biznesowych i inteligencji.
Nie ma wątpliwości, że zapotrzebowanie na IoT i podobne rozwiązania będzie rosło. Mając to na uwadze, możemy również spodziewać się konieczności analizowania i przetwarzania danych na wiele różnych sposobów. Dane szeregów czasowych są zazwyczaj tylko dołączane — jest mało prawdopodobne, że będziesz aktualizować stare dane. Zazwyczaj nie usuwasz poszczególnych wierszy, z drugiej strony możesz chcieć pewnego rodzaju agregacji danych w czasie. Chcemy nie tylko przechowywać zmiany naszych danych w czasie, ale także analizować je i uczyć się na ich podstawie.
Problem z nowymi typami systemów baz danych polega na tym, że zazwyczaj używają one własnego języka zapytań. Nauczenie się nowego języka wymaga czasu. Największą różnicą między TimescaleDB a innymi popularnymi bazami danych szeregów czasowych jest obsługa SQL. TimescaleDB obsługuje pełny zakres funkcji SQL, w tym agregacje oparte na czasie, sprzężenia, podzapytania, funkcje okien i indeksy pomocnicze. Co więcej, jeśli Twoja aplikacja korzysta już z PostgreSQL, nie są potrzebne żadne zmiany w kodzie klienta.
Podstawy architektury
TimescaleDB jest zaimplementowana jako rozszerzenie PostgreSQL, co oznacza, że baza danych w skali czasu działa w ramach ogólnej instancji PostgreSQL. Model rozszerzenia umożliwia bazie danych korzystanie z wielu atrybutów PostgreSQL, takich jak niezawodność, bezpieczeństwo i łączność z szeroką gamą narzędzi innych firm. Jednocześnie TimescaleDB wykorzystuje wysoki stopień dostosowania dostępny dla rozszerzeń, dodając hooki głęboko do planowania zapytań, modelu danych i silnika wykonawczego PostgreSQL.
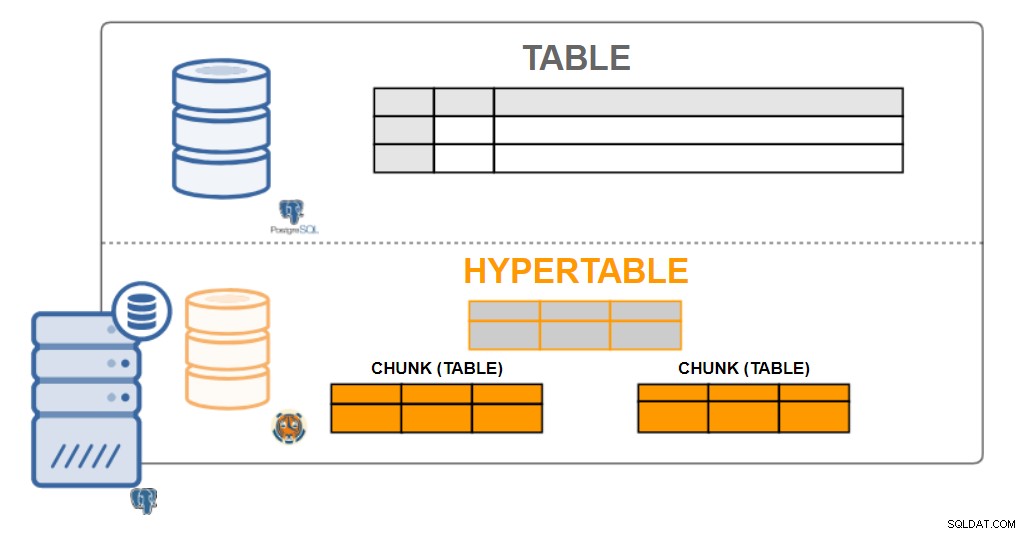 Architektura TimescaleDB
Architektura TimescaleDB Hipertabele
Z perspektywy użytkownika dane TimescaleDB wyglądają jak pojedyncze tabele, zwane hipertabelami. Hipertabele to koncepcja lub niejawny widok wielu pojedynczych tabel zawierających dane zwane fragmentami. Dane hipertabeli mogą mieć jeden lub dwa wymiary. Może być agregowany według przedziału czasu i (opcjonalnej) wartości „klucza partycji”.
Praktycznie wszystkie interakcje użytkownika z TimescaleDB dotyczą hipertabel. Tworzenie tabel, indeksów, zmienianie tabel, wybieranie danych, wstawianie danych... wszystko powinno być wykonywane na hipertabeli.
TimescaleDB wykonuje to rozbudowane partycjonowanie zarówno w przypadku wdrożeń jednowęzłowych, jak i wdrożeń klastrowych (w fazie rozwoju). Chociaż partycjonowanie jest tradycyjnie używane tylko do skalowania na wielu maszynach, pozwala nam również na skalowanie do wysokich szybkości zapisu (i ulepszonych zapytań równoległych) nawet na pojedynczych maszynach.
Obsługa danych relacyjnych
Jako relacyjna baza danych posiada pełne wsparcie dla SQL. TimescaleDB obsługuje elastyczne modele danych, które można zoptymalizować pod kątem różnych przypadków użycia. To sprawia, że skala czasu nieco różni się od większości innych baz danych szeregów czasowych. DBMS jest zoptymalizowany pod kątem szybkiego pozyskiwania i złożonych zapytań, opartych na PostgreSQL, a w razie potrzeby mamy dostęp do solidnego przetwarzania szeregów czasowych.
Instalacja
TimescaleDB podobnie jak PostgreSQL obsługuje wiele różnych sposobów instalacji, w tym instalację na platformach Ubuntu, Debian, RHEL/Centos, Windows lub w chmurze.
Jednym z najwygodniejszych sposobów na zabawę z TimescaleDB jest obraz dokowany.
Poniższe polecenie pobierze obraz Dockera z Docker Hub, jeśli nie został jeszcze zainstalowany, a następnie go uruchomi.
docker run -d --name timescaledb -p 5432:5432 -e POSTGRES_PASSWORD=severalnines timescale/timescaledbPierwsze użycie
Ponieważ nasza instancja jest już uruchomiona, nadszedł czas, aby utworzyć naszą pierwszą bazę danych ze skalą czasową. Jak widać poniżej, łączymy się przez standardową konsolę PostgreSQL, więc jeśli masz zainstalowane lokalnie narzędzia klienta PostgreSQL (np. psql), możesz ich użyć, aby uzyskać dostęp do instancji dockera TimescaleDB.
psql -U postgres -h localhost
CREATE DATABASE severalnines;
\c severalnines
CREATE EXTENSION IF NOT EXISTS timescaledb CASCADE;Codzienne operacje
Z perspektywy użytkowania i zarządzania, TimescaleDB po prostu wygląda i działa jak PostgreSQL i może być zarządzany i odpytywany jako taki.
Główne punkty dotyczące codziennych operacji to:
- Współistnieje z innymi bazami danych TimescaleDB i PostgreSQL na serwerze PostgreSQL.
- Używa SQL jako języka interfejsu.
- Wykorzystuje popularne złącza PostgreSQL do narzędzi innych firm do tworzenia kopii zapasowych, konsoli itp.
Ustawienia bazy czasowej
Gotowe ustawienia PostgreSQL są zazwyczaj zbyt konserwatywne dla nowoczesnych serwerów i TimescaleDB. Powinieneś upewnić się, że ustawienia postgresql.conf są dostrojone, używając timescaledb-tune lub robiąc to ręcznie.
$ timescaledb-tuneSkrypt poprosi o potwierdzenie zmian. Te zmiany są następnie zapisywane w pliku postgresql.conf i zaczną obowiązywać po ponownym uruchomieniu.
Teraz rzućmy okiem na kilka podstawowych operacji z samouczka TimescaleDB, który może dać ci wyobrażenie o tym, jak pracować z nowym systemem bazy danych.
Aby utworzyć hipertabelę, zaczynasz od zwykłej tabeli SQL, a następnie przekształcasz ją w hipertabelę za pomocą funkcji create_hypertable.
-- Create extension timescaledb
CREATE EXTENSION timescaledb;
Create a regular table
CREATE TABLE conditions (
time TIMESTAMPTZ NOT NULL,
location TEXT NOT NULL,
temperature DOUBLE PRECISION NULL,
humidity DOUBLE PRECISION NULL
);Konwersja do hipertabeli jest prosta, ponieważ:
SELECT create_hypertable('conditions', 'time');Wstawianie danych do hipertabeli odbywa się za pomocą zwykłych poleceń SQL:
INSERT INTO conditions(time, location, temperature, humidity)
VALUES (NOW(), 'office', 70.0, 50.0);Wybieranie danych to stary dobry SQL.
SELECT * FROM conditions ORDER BY time DESC LIMIT 10;Jak widać poniżej, możemy pogrupować według, uporządkować według i funkcje. Ponadto TimescaleDB zawiera funkcje do analizy szeregów czasowych, które nie są obecne w waniliowym PostgreSQL.
SELECT time_bucket('15 minutes', time) AS fifteen_min,
location, COUNT(*),
MAX(temperature) AS max_temp,
MAX(humidity) AS max_hum
FROM conditions
WHERE time > NOW() - interval '3 hours'
GROUP BY fifteen_min, location
ORDER BY fifteen_min DESC, max_temp DESC;