Aby odpowiedzieć na Twoje pytanie, dlaczego SQL Server to robi, odpowiedź jest taka, że zapytanie nie jest kompilowane w logicznej kolejności, każda instrukcja jest kompilowana na własną korzyść, więc gdy generowany jest plan zapytania dla instrukcji select, optymalizator nie wie, że @val1 i @Val2 staną się odpowiednio „val1” i „val2”.
Gdy SQL Server nie zna wartości, musi jak najlepiej zgadywać, ile razy ta zmienna pojawi się w tabeli, co czasami może prowadzić do nieoptymalnych planów. Moim głównym celem jest to, że to samo zapytanie z różnymi wartościami może generować różne plany. Wyobraź sobie ten prosty przykład:
IF OBJECT_ID(N'tempdb..#T', 'U') IS NOT NULL
DROP TABLE #T;
CREATE TABLE #T (ID INT IDENTITY PRIMARY KEY, Val INT NOT NULL, Filler CHAR(1000) NULL);
INSERT #T (Val)
SELECT TOP 991 1
FROM sys.all_objects a
UNION ALL
SELECT TOP 9 ROW_NUMBER() OVER(ORDER BY a.object_id) + 1
FROM sys.all_objects a;
CREATE NONCLUSTERED INDEX IX_T__Val ON #T (Val);
Wszystko, co zrobiłem tutaj, to utworzenie prostej tabeli i dodanie 1000 wierszy z wartościami 1-10 dla kolumny val , jednak 1 pojawia się 991 razy, a pozostałe 9 pojawia się tylko raz. Założeniem jest to zapytanie:
SELECT COUNT(Filler)
FROM #T
WHERE Val = 1;
Bardziej efektywne byłoby po prostu przeskanować całą tabelę, niż użyć indeksu do wyszukiwania, a następnie wykonać 991 wyszukiwania zakładek, aby uzyskać wartość Filler , jednak z tylko 1 wierszem następujące zapytanie:
SELECT COUNT(Filler)
FROM #T
WHERE Val = 2;
będzie bardziej wydajne przy wyszukiwaniu indeksu i pojedynczym wyszukiwaniu zakładek w celu uzyskania wartości dla Filler (a uruchomienie tych dwóch zapytań zatwierdzi to)
Jestem prawie pewien, że odcięcie wyszukiwania i wyszukiwania zakładek różni się w zależności od sytuacji, ale jest dość niskie. Korzystając z przykładowej tabeli, z odrobiną prób i błędów, stwierdziłem, że potrzebuję Val kolumna, aby mieć 38 wierszy z wartością 2, zanim optymalizator przejdzie do pełnego skanowania tabeli poprzez wyszukiwanie indeksu i wyszukiwanie zakładek:
IF OBJECT_ID(N'tempdb..#T', 'U') IS NOT NULL
DROP TABLE #T;
DECLARE @I INT = 38;
CREATE TABLE #T (ID INT IDENTITY PRIMARY KEY, Val INT NOT NULL, Filler CHAR(1000) NULL);
INSERT #T (Val)
SELECT TOP (991 - @i) 1
FROM sys.all_objects a
UNION ALL
SELECT TOP (@i) 2
FROM sys.all_objects a
UNION ALL
SELECT TOP 8 ROW_NUMBER() OVER(ORDER BY a.object_id) + 2
FROM sys.all_objects a;
CREATE NONCLUSTERED INDEX IX_T__Val ON #T (Val);
SELECT COUNT(Filler), COUNT(*)
FROM #T
WHERE Val = 2;
W tym przykładzie limit wynosi 3,7% pasujących wierszy.
Ponieważ zapytanie nie wie, ile wierszy będzie pasować, gdy używasz zmiennej, musi zgadywać, a najprostszym sposobem jest znalezienie łącznej liczby wierszy i podzielenie jej przez całkowitą liczbę odrębnych wartości w kolumnie, więc w tym przykładzie szacowana liczba wierszy dla WHERE val = @Val wynosi 1000 / 10 =100, Rzeczywisty algorytm jest bardziej złożony niż ten, ale na przykład to wystarczy. Więc kiedy spojrzymy na plan wykonania dla:
DECLARE @i INT = 2;
SELECT COUNT(Filler)
FROM #T
WHERE Val = @i;
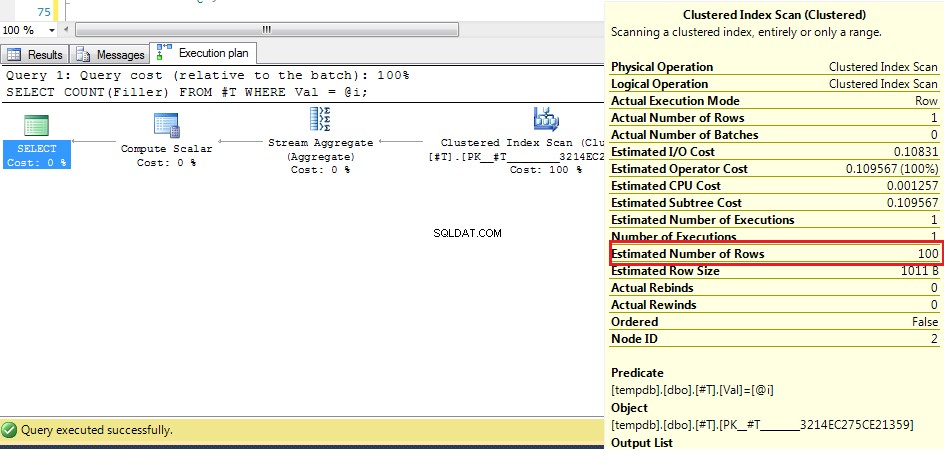
Widzimy tutaj (z oryginalnymi danymi), że szacowana liczba wierszy to 100, ale rzeczywista liczba wierszy to 1. Z poprzednich kroków wiemy, że przy więcej niż 38 wierszach optymalizator wybierze klastrowe skanowanie indeksu na indeksie seek, więc ponieważ najlepsze przypuszczenie dla liczby wierszy jest wyższe niż ta, plan dla nieznanej zmiennej to skanowanie indeksu klastrowego.
Aby jeszcze bardziej udowodnić teorię, jeśli utworzymy tabelę z 1000 rzędów liczb 1-27 równomiernie rozłożonych (więc szacowana liczba rzędów będzie wynosić około 1000 / 27 =37,037)
IF OBJECT_ID(N'tempdb..#T', 'U') IS NOT NULL
DROP TABLE #T;
CREATE TABLE #T (ID INT IDENTITY PRIMARY KEY, Val INT NOT NULL, Filler CHAR(1000) NULL);
INSERT #T (Val)
SELECT TOP 27 ROW_NUMBER() OVER(ORDER BY a.object_id)
FROM sys.all_objects a;
INSERT #T (val)
SELECT TOP 973 t1.Val
FROM #T AS t1
CROSS JOIN #T AS t2
CROSS JOIN #T AS t3
ORDER BY t2.Val, t3.Val;
CREATE NONCLUSTERED INDEX IX_T__Val ON #T (Val);
Następnie uruchom zapytanie ponownie, otrzymujemy plan z wyszukiwaniem indeksu:
DECLARE @i INT = 2;
SELECT COUNT(Filler)
FROM #T
WHERE Val = @i;
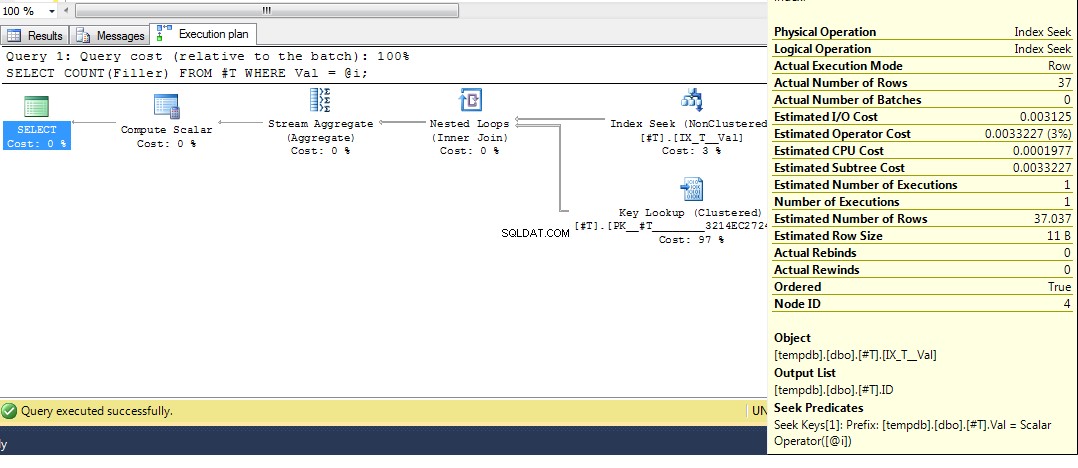
Miejmy więc nadzieję, że to dość wyczerpująco wyjaśnia, dlaczego otrzymujesz ten plan. Teraz przypuszczam, że następnym pytaniem jest, jak wymusić inny plan, a odpowiedzią jest użycie podpowiedzi do zapytania OPTION (RECOMPILE) , aby wymusić kompilację zapytania w czasie wykonywania, gdy wartość parametru jest znana. Powrót do oryginalnych danych, gdzie najlepszy plan dla Val = 2 to wyszukiwanie, ale użycie zmiennej daje plan ze skanowaniem indeksu, możemy uruchomić:
DECLARE @i INT = 2;
SELECT COUNT(Filler)
FROM #T
WHERE Val = @i;
GO
DECLARE @i INT = 2;
SELECT COUNT(Filler)
FROM #T
WHERE Val = @i
OPTION (RECOMPILE);
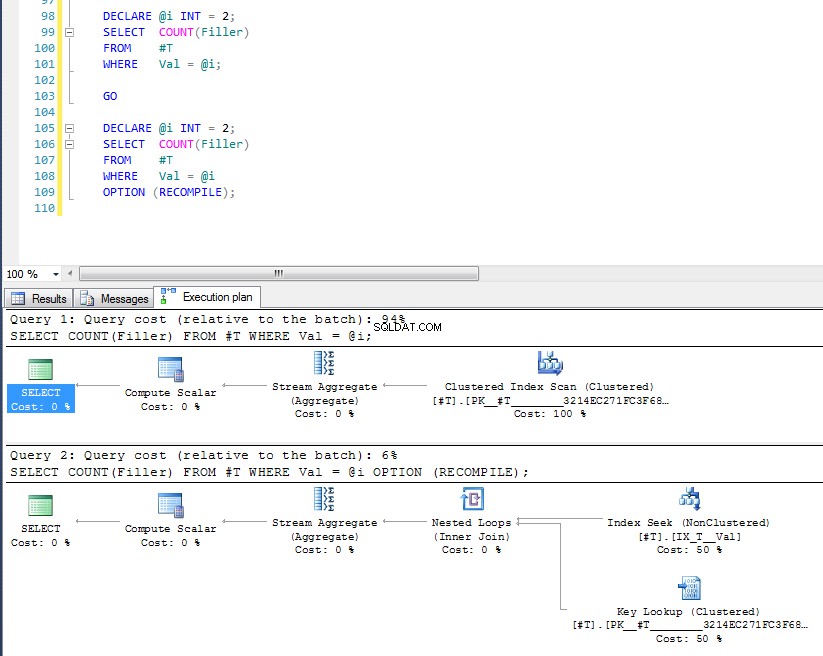
Widzimy, że ten ostatni używa wyszukiwania indeksu i wyszukiwania klucza, ponieważ sprawdzał wartość zmiennej w czasie wykonania i wybierany jest najbardziej odpowiedni plan dla tej konkretnej wartości. Problem z OPTION (RECOMPILE) oznacza to, że nie możesz korzystać z planów zapytań zapisanych w pamięci podręcznej, więc za każdym razem istnieje dodatkowy koszt kompilacji zapytania.