Przegląd
Oracle Data Mining (ODM) jest składnikiem Opcji bazy danych Oracle Advanced Analytics. ODM zawiera zestaw zaawansowanych algorytmów eksploracji danych, które są osadzone w bazie danych, co pozwala na przeprowadzanie zaawansowanych analiz danych.
Oracle Data Miner to rozszerzenie Oracle SQL Developer, graficznego środowiska programistycznego dla Oracle SQL. Oracle Data Miner wykorzystuje technologię eksploracji danych wbudowaną w Oracle Database do tworzenia, wykonywania i zarządzania przepływami pracy, które zawierają operacje eksploracji danych. Architekturę ODM przedstawiono na rysunku 1.
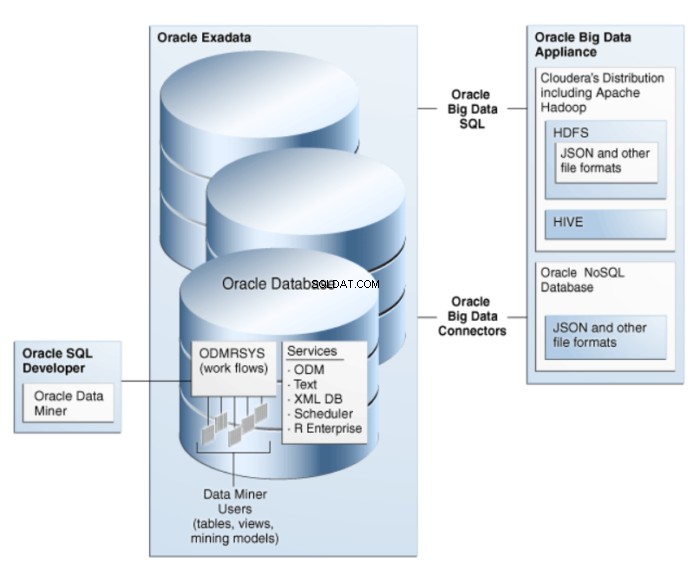
Rysunek 1:Architektura Oracle Data Mining dla Big Data
Algorytmy są implementowane jako funkcje SQL i wykorzystują mocne strony Oracle Database. Funkcje eksploracji danych SQL mogą wydobywać dane transakcyjne, agregacje, dane nieustrukturyzowane, tj. typ danych CLOB (przy użyciu Oracle Text) i dane przestrzenne.
Każda funkcja eksploracji danych określa klasę problemów, które można modelować i rozwiązywać. Funkcje eksploracji danych dzielą się zasadniczo na dwie kategorie:nadzorowane i nienadzorowane.
Pojęcia nadzorowanego i nienadzorowanego uczenia się wywodzą się z nauki o uczeniu maszynowym, które zostało nazwane podobszarem sztucznej inteligencji.
Uczenie nadzorowane jest również znane jako uczenie ukierunkowane. Proces uczenia jest kierowany przez znany wcześniej zależny atrybut lub cel. Ukierunkowana eksploracja danych próbuje wyjaśnić zachowanie celu jako funkcji zestawu niezależnych atrybutów lub predyktorów.
Uczenie się nienadzorowane jest niekierowane. Nie ma rozróżnienia między atrybutami zależnymi i niezależnymi. Nie jest znany wcześniej wynik, który kierowałby algorytmem podczas budowania modelu. Nauka nienadzorowana może być wykorzystywana do celów opisowych.
Nadzorowane algorytmy Oracle Data Mining
| Technika | Zastosowanie | Algorytmy (krótki opis) |
|---|---|---|
Klasyfikacja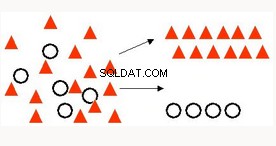 | Najczęściej stosowana technika przewidywania konkretnego wyniku, na przykład identyfikacja komórek nowotworowych, analiza sentymentu, klasyfikacja leków, wykrywanie spamu. | Uogólnione modele liniowe Regresja logistyczna — klasyczna technika statystyczna dostępna w bazie danych Oracle w wysoce wydajnej, skalowalnej, parallowanej implementacji (dotyczy wszystkich algorytmów OAA ML). Obsługuje dane tekstowe i transakcyjne (dotyczy prawie wszystkich algorytmów OAA ML) Naive Bayes — szybki, prosty, powszechnie stosowany. Obsługa maszyny wektorowej — algorytm uczenia maszynowego, obsługuje tekst i szerokie dane. Drzewo decyzyjne - Popularny algorytm ML do interpretacji. Zapewnia czytelne dla człowieka „zasady”. |
Regresja | Technika przewidywania ciągłego wyniku liczbowego, takiego jak analiza danych astronomicznych, generowanie wglądu w zachowanie konsumentów, rentowność i inne czynniki biznesowe, obliczanie związków przyczynowych między parametrami w systemach biologicznych. | Uogólnione modele liniowe Regresja wielokrotna — klasyczna technika statystyczna, ale teraz dostępna w bazie danych Oracle jako wysoce wydajna, skalowalna, sparaliżowana implementacja. Obsługuje regresję grzbietu, tworzenie i wybór funkcji. Obsługuje dane tekstowe i transakcyjne. Obsługa maszyny wektorowej - algorytm uczenia maszynowego, obsługuje tekst i szerokie dane. |
Ważność atrybutu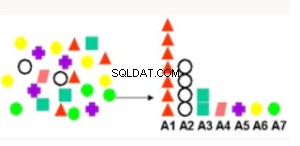 | Rankinguje atrybuty według siły związku z atrybutem docelowym. Przypadki użycia obejmują znalezienie czynników najbardziej związanych z klientami, którzy odpowiadają na ofertę, czynników najbardziej związanych ze zdrowymi pacjentami. | Minimalna długość opisu — traktuje każdy atrybut jako prosty model predykcyjny klasy docelowej i zapewnia względny wpływ. |
Nienadzorowane algorytmy Oracle Data Mining
| Technika | Zastosowanie | Algorytmy |
|---|---|---|
Klastrowanie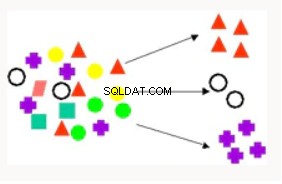 | Klastrowanie służy do dzielenia rekordów bazy danych na podzbiory lub klastry, w których elementy w klastrze mają zestaw wspólnych właściwości. Przykłady obejmują znajdowanie nowych segmentów klientów i rekomendacje filmów. | K-Means — obsługuje eksplorację tekstu, klastrowanie hierarchiczne, oparte na odległości. Klastrowanie partycjonowania ortogonalnego — klastrowanie hierarchiczne, oparte na gęstości. Maksymalizacja oczekiwań — technika klastrowania, która sprawdza się dobrze w problemach eksploracji danych mieszanych (gęstych i rzadkich). |
Wykrywanie anomalii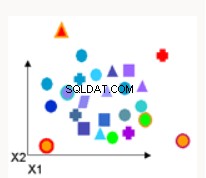 | Wykrywanie anomalii identyfikuje punkty danych, zdarzenia i/lub obserwacje, które odbiegają od normalnego zachowania zbioru danych. Typowe przykłady to oszustwo bankowe, wada strukturalna, problemy medyczne lub błędy w tekście | Jednoklasowa maszyna wektorów wsparcia - trenuje nieoznakowane dane i próbuje określić, czy punkt testowy należy do dystrybucji danych treningowych. |
Wybór i wyodrębnianie funkcji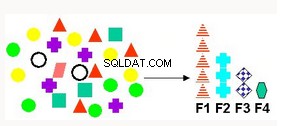 | Produkuje nowe atrybuty jako liniową kombinację istniejących atrybutów. Ma zastosowanie do danych tekstowych, ukrytej analizy semantycznej (LSA), kompresji danych, dekompozycji i projekcji danych oraz rozpoznawania wzorców. | Nieujemna faktoryzacja macierzy — mapuje oryginalne dane do nowego zestawu atrybutów Analiza głównych składników (PCA) — tworzy mniej nowych atrybutów złożonych, które reprezentują wszystkie atrybuty. Singular Vector Decomposition - uznana metoda wyodrębniania cech, która ma szeroki zakres zastosowań. |
Powiązanie | Znajduje reguły związane z często współwystępującymi pozycjami, wykorzystywane do analizy koszyka rynkowego, sprzedaży krzyżowej, analizy przyczyn źródłowych. Przydatne do łączenia produktów i analizy defektów. | Apriori — Zahaszuj drzewo w celu zebrania informacji w bazie danych |
Włączanie opcji eksploracji danych Oracle
Od 12c Release 2 Oracle Advanced Analytics Opcja obejmuje funkcję Data Mining i Oracle R.
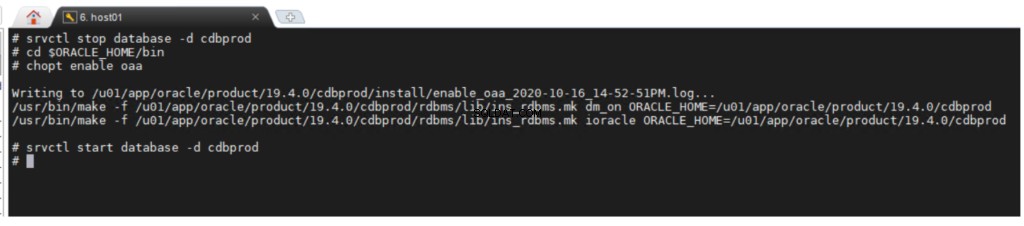
Opcja Oracle Advanced Analytics jest domyślnie włączona podczas instalacji Oracle Database Enterprise Edition. Jeśli chcesz włączyć lub wyłączyć opcję bazy danych, możesz użyć narzędzia wiersza poleceń chopt .
chopt [ enable | disable ] oaa
Aby włączyć opcję Oracle Advanced Analytics:
Tworzenie przestrzeni tabel i schematu ODM
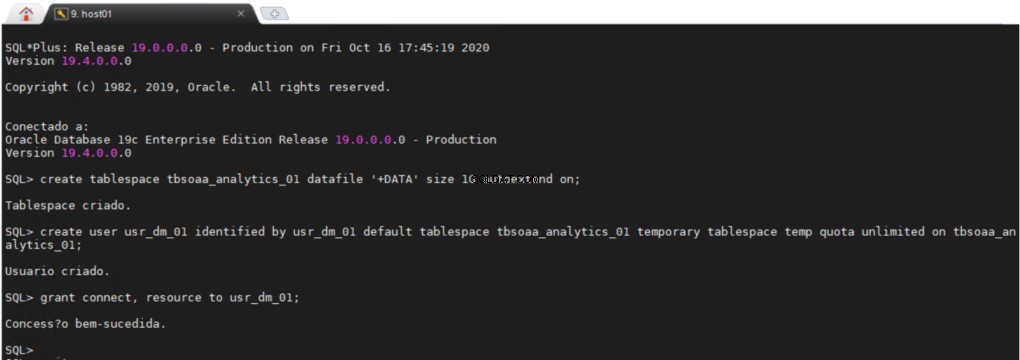
Wszyscy użytkownicy potrzebują stałego obszaru tabel i tymczasowego obszaru tabel, w którym mogą wykonywać swoją pracę, bardzo przydatne może być posiadanie oddzielnego obszaru w bazie danych, w którym można tworzyć wszystkie obiekty eksploracji danych.
usr_dm_01 schemat będzie zawierał wszystkie prace związane z eksploracją danych.
Tworzenie repozytorium ODM
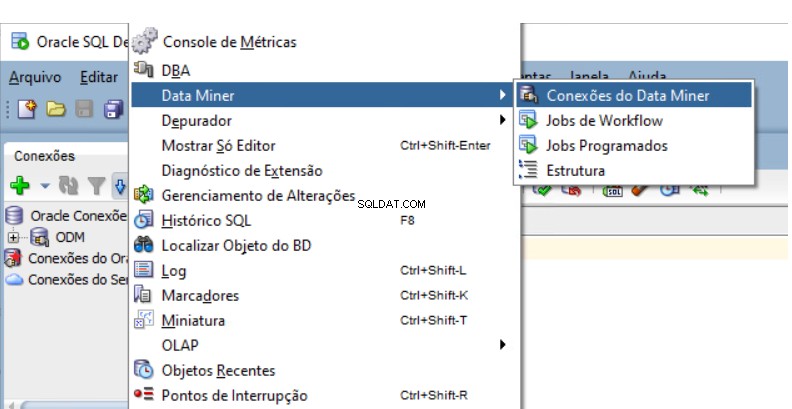
Musisz utworzyć Repozytorium Oracle Data Mining w bazie danych. Przejdź do Data Miner Navigator w programie SQL Developer.
Wybierz Widok -> Data Miner -> Połączenia Data Miner:
Nowa karta otworzy się obok istniejącej karty Połączenia:
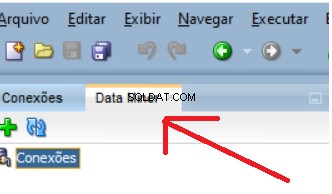
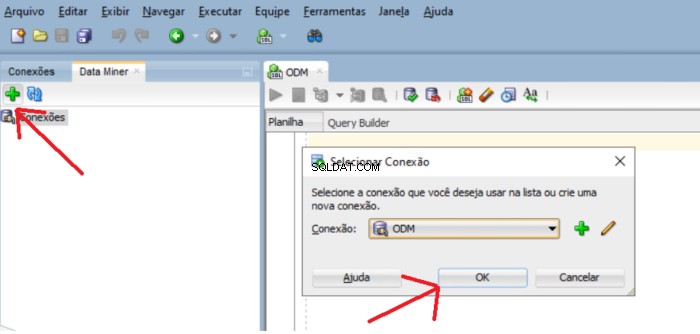
Aby dodać usr_dm_01 schemat do tej listy, kliknij zielony plus okna i OK
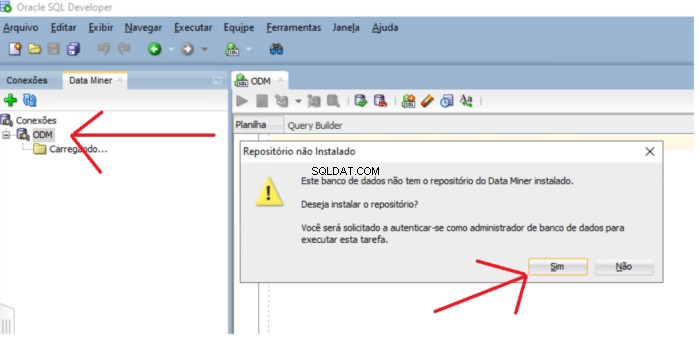
Jeśli repozytorium nie istnieje, zostanie wyświetlony komunikat z pytaniem, czy chcesz zainstalować repozytorium. Kliknij Tak przycisk, aby kontynuować instalację.
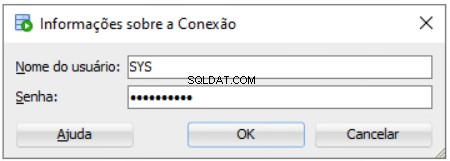
Musisz wprowadzić hasło SYS
Ustawienia instalacji repozytorium
Okno postępu instalacji Data Miner Repository
Zadanie zakończone pomyślnie
Plik dziennika
Komponenty Oracle Data Mining
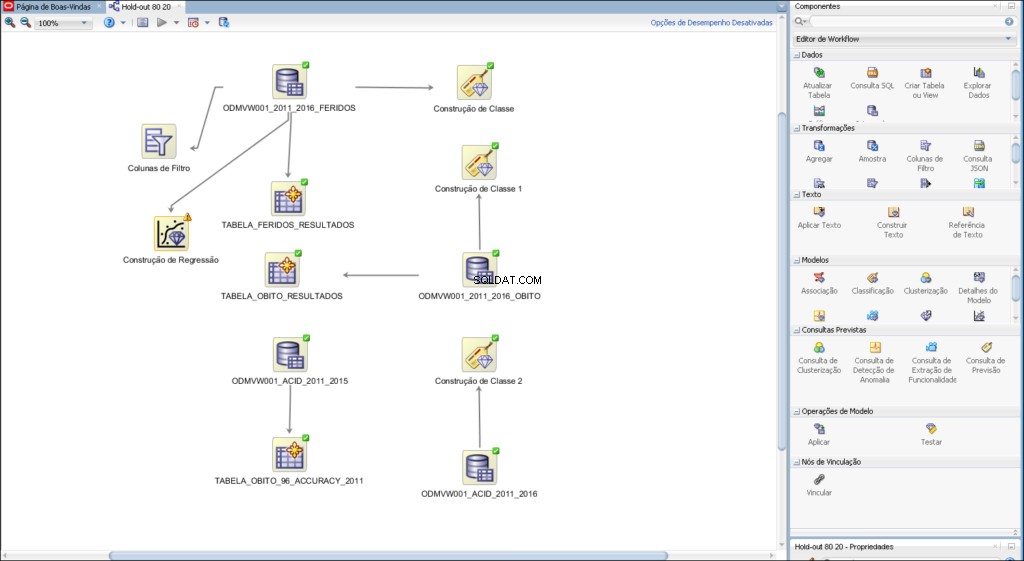
Przepływ pracy pozwala zbudować serię węzłów, które wykonują wszystkie wymagane przetwarzanie danych.
Przykład przepływu pracy opracowanego dla analityki predykcyjnej
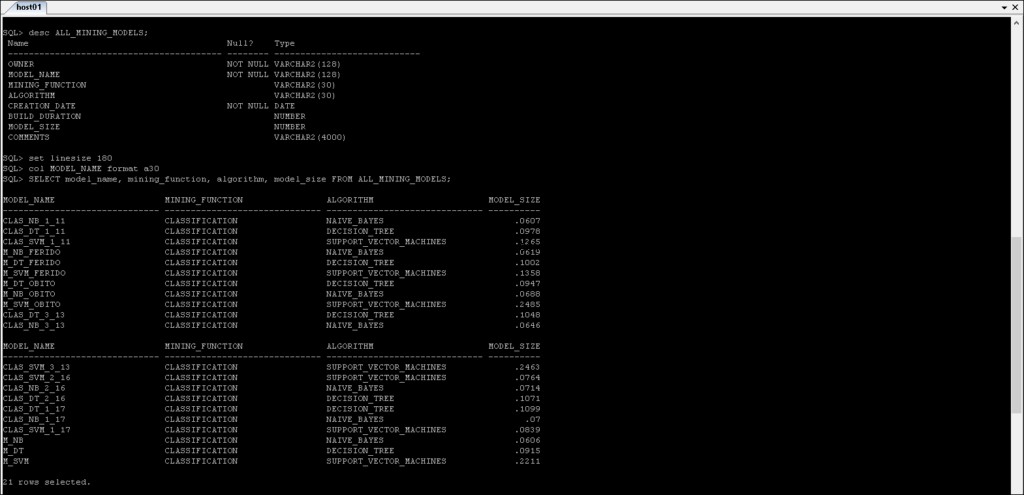
Widoki słownika danych ODM
Możesz uzyskać informacje o modelach wyszukiwania ze słownika danych.
Widoki słownika danych Data Mining są podsumowane w następujący sposób:
Uwaga:* można zastąpić przez ALL_, USER_, DBA_ i CDB_
*_MINING_MODELS :Informacje o stworzonych modelach wyszukiwania.
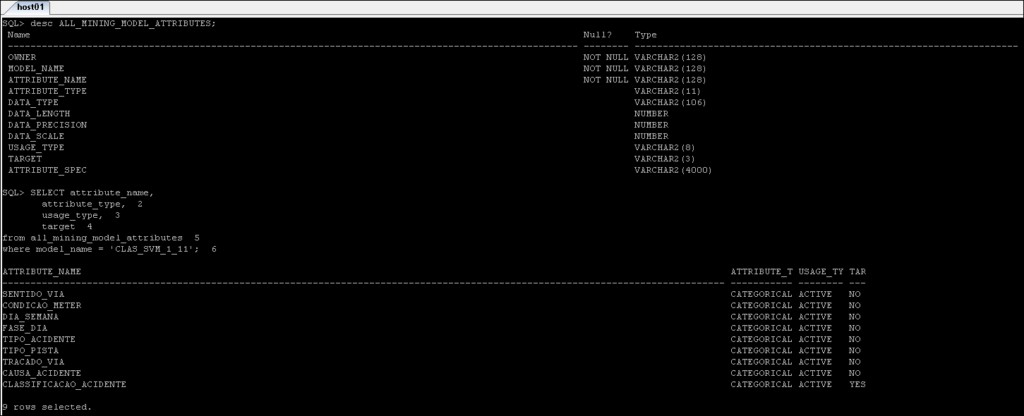
*_MINING_MODEL_ATTRIBUTES :Zawiera szczegóły atrybutów, które zostały użyte do stworzenia modelu Oracle Data Mining.
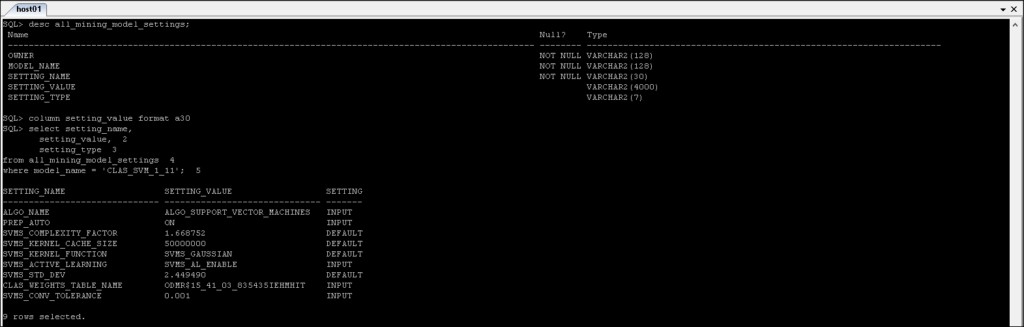
*_MINING_MODEL_SETTINGS :Zwraca informacje o ustawieniach modeli wyszukiwania, do których masz dostęp.
Referencje
Przewodnik użytkownika Oracle Data Mining. Dostępne pod adresem:https://docs.oracle.com/en/database/oracle/oracle-database/19/dmprg/lot.html
Oracle Data Mining — skalowalna analiza predykcyjna w bazie danych. Dostępne pod adresem:https://www.oracle.com/database/technologies/advanced-analytics/odm.html
Przegląd systemu Oracle Data Miner. Dostępne pod adresem:https://docs.oracle.com/database/sql-developer-17.4/DMRIG/oracle-data-miner-overview.htm#DMRIG124