Jeśli kiedykolwiek tworzyłeś UDF powiązany ze schematem, wiesz, że powiązanie schematu to tylko kwestia dodania WITH SCHEMABINDING do twojej definicji. To samo dotyczy tworzenia widoku powiązanego ze schematem.
Procedury składowane są nieco inne.
Tylko natywnie skompilowane procedury składowane mogą być powiązane ze schematem. W rzeczywistości natywnie skompilowane procedury składowane muszą być powiązany ze schematem. Nie można utworzyć natywnie skompilowanej procedury składowanej bez powiązania jej ze schematem.
Ale jeśli spróbujesz schematycznie powiązać zwykłą (nie skompilowaną natywnie) procedurę, otrzymasz błąd.
Przykład procedury składowanej związanej ze schematem
Oto przykład tworzenia powiązanej ze schematem (skompilowanej natywnie) procedury składowanej.
CREATE PROCEDURE dbo.usp_GetCowsByName @cowname varchar(70)Z ŁĄCZENIEM SCHEMATÓW, NATIVE_COMPILATIONASBEGIN ATOMIC WITH ( TRANSACTION ISOLATION LEVEL =SNAPSHOT, LANGUAGE =N'us_english' ) SELECT CowE. PhoneFwname =CowROM /pre>Dołączyłem
WITH SCHEMABINDINGargument, ale dodałem teżNATIVE_COMPILATION, co oznacza, że procedura jest kompilowana natywnie.Zwróć także uwagę na
ATOMIC WITHblok. Jest to wymagane w przypadku natywnie kompilowanych procedur składowanych.Ten kod utworzył procedurę składowaną związaną ze schematem.
Błąd? Sprawdź te wymagania wstępne
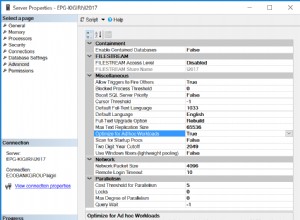
Natywnie skompilowane procedury składowane wymagają, aby wszystkie tabele bazowe były tabelami zoptymalizowanymi pod kątem pamięci.
Aby utworzyć tabele zoptymalizowane pod kątem pamięci, należy najpierw utworzyć grupę plików zoptymalizowaną pod kątem pamięci.
Oto kod, którego użyłem do utworzenia grupy plików zoptymalizowanej pod kątem pamięci, skojarzonego z nią pliku i tabeli zoptymalizowanej pod kątem pamięci, do której odwołuję się w procedurze składowanej:
ALTER DATABASE Test ADD FILEGROUP imoltp_test ZAWIERA MEMORY_OPTIMIZED_DATA; GOALTER DATABASE Test ADD FILE (name='imoltp_test1', filename='/var/opt/mssql/data/imoltp_test1.mdf') TOBOCtRELEtest1.mdf') TO .[Krowy]( [CowId] [int] IDENTITY (1,1) NOT NULL PODSTAWOWY KLUCZ NIECLUSTROWANY, [CowName] [varchar](70) NULL, [Phone] [varchar](10) NULL) WITH (MEMORY_OPTIMIZED =ON , TRWAŁOŚĆ =SCHEMAT_I_DANE)GOWięc jeśli chcesz skopiować i wkleić mój kod, musisz najpierw uruchomić ten kod, a następnie powyższy kod procedury składowanej.
Zauważ też, że używam SQL Server dla systemu Linux, więc ścieżki plików używają konwencji linuksowych. Jeśli tworzysz plik bazy danych w systemie Windows, musisz go zmienić, aby używał konwencji ścieżki plików systemu Windows (i pamiętaj, aby użyć ścieżki pliku, która istnieje w twoim systemie).