SQL Server istnieje od ponad 30 lat, a ja pracuję z SQL Server prawie tak długo. Widziałem wiele zmian na przestrzeni lat (i dziesięcioleci!) i wersji tego niesamowitego produktu. W tych postach podzielę się z Wami tym, jak patrzę na niektóre funkcje lub aspekty SQL Server, czasami wraz z odrobiną perspektywy historycznej.
Sprawdź najnowsze blogi Kalena na temat operatorów problematycznych tutaj.
Tworzenie planów diagnostyki serwera SQL może być kosztowne, ponieważ optymalizator zapytań musi być w stanie znaleźć dobry plan dla każdego przesłanego zapytania prawnego. Optymalizator ocenia kolejność łączenia wielokrotnych, wiele indeksów. oraz różne typy algorytmów łączenia i grupowania, w zależności od zapytania i zaangażowanych tabel. Jeśli ta sama kwerenda zostanie ponownie uruchomiona, SQL Server może zaoszczędzić wiele zasobów, ponownie wykorzystując istniejący plan. Ale nie zawsze jest możliwe ponowne wykorzystanie istniejącego planu i nie zawsze jest to dobre. W następnych dwóch artykułach przyjrzymy się, kiedy plan jest ponownie wykorzystywany, a kiedy ponownie kompilowany.
Najpierw przyjrzymy się różnym odmianom planów i widokowi metadanych, którego najczęściej używam, aby sprawdzić, co znajduje się w pamięci podręcznej moich planów. Napisałem własny pogląd, który zawiera informacje, które są dla mnie najbardziej przydatne. SQL Server buforuje sześć różnych typów planów zapytań, ale tylko dwa są zwykle używane do strojenia pamięci podręcznej planów. Są to PLAN SKOMPILOWANY i STABILIZOWANY PLAN. Mój widok odfiltrowuje wszystkie oprócz tych dwóch typów obiektów pamięci podręcznej. SKOMPILOWANE PLANY występują w trzech odmianach:AD HOC, PREPARED i PROC. Skomentuję wszystkie trzy rodzaje.
Nawet jeśli patrzymy tylko na SKOMPILOWANE PLANY, wciąż jest wiele planów w pamięci podręcznej, które zwykle należy zignorować, ponieważ są one generowane przez sam SQL Server. Obejmują one plany wyszukiwania strumieni plików lub indeksów wyszukiwania pełnotekstowego lub zapytań wewnętrznych pracujących z OLTP w pamięci. Tak więc mój widok dodaje filtry, aby spróbować odstawić większość planów, którymi nie jestem zainteresowany. Możesz pobrać skrypt, aby zbudować ten widok, o nazwie sp_cacheobjects , stąd.
Nawet przy wszystkich filtrach, których używa mój widok, w pamięci podręcznej nadal znajdują się niektóre wewnętrzne zapytania SQL Server; Zazwyczaj często usuwam pamięć podręczną planu podczas testowania w tym obszarze. Najprostszym sposobem na wyczyszczenie WSZYSTKICH planów z pamięci podręcznej jest polecenie:DBCC FREEPROCCACHE.
Plany skompilowane adhoc
Najprostszym rodzajem planu jest Adhoc. Służy do podstawowych zapytań, które nie pasują do innej kategorii. Jeśli pobrałeś mój skrypt i utworzyłeś mój widok sp_cacheobjects, możesz uruchomić następujące. Każda wersja bazy danych AdventureWorks powinna działać. Ten skrypt tworzy kopię tabeli i buduje na niej kilka unikalnych indeksów. Masuje również sumę częściową, aby usunąć wszelkie cyfry dziesiętne.
USE AdventureWorks2016;
PRZEJDŹ DROP TABLE IF EXISTS newsales;
PRZEJDŹ-- Zrób kopię tabeli Sales.SalesOrderHeader
WYBIERZ * DO dbo.newsales
Z Sales.SalesOrderHeader;
IŚĆ
AKTUALIZUJ dbo.newsales
SET SubTotal =cast(cast(SubTotal as int) as money);
PRZEJDŹUTWÓRZ UNIKALNY indeks newsales_ident
W aktualnościach (IDZamówieniaSprzedaży);
PRZEJDŹUTWÓRZ INDEKS IX_Sales_SubTotal W przypadku newsales(SubTotal);
IŚĆ
-- Ponowne użycie planu zapytań Adhoc
DBCC FREEPROCCACHE;
PRZEJDŹ-- zapytanie adhoc
WYBIERZ * Z dbo.newsales
GDZIE suma częściowa =4;
PRZEJDŹSELECT * FROM sp_cacheobjects;
PRZEJDŹ

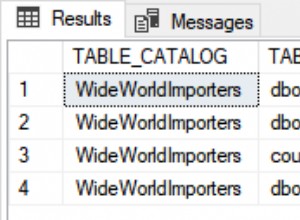
W moich wynikach widzisz dwa plany Adhoc. Jedna dotyczy instrukcji SELECT z newsale tabeli, a druga jest dla SELECT z moich sp_cacheobjects pogląd. Ponieważ plan jest buforowany, jeśli DOKŁADNIE to samo zapytanie zostanie uruchomione ponownie, ten sam plan może zostać ponownie użyty i zobaczysz liczniki użycia wzrost wartości. Jest jednak pewien haczyk. Aby plan Adhoc mógł zostać ponownie wykorzystany, ciąg SQL musi być dokładnie taki sam. Jeśli zmienisz jakiekolwiek znaki w SQL, zapytanie nie zostanie rozpoznane jako to samo zapytanie i zostanie wygenerowany nowy plan. Jeśli nawet dodam spację, dodam komentarz lub nowy podział wiersza, to nie jest to ten sam ciąg. Jeśli zmienię wielkość liter, oznacza to, że istnieją różne wartości kodu ASCII, a więc nie ten sam ciąg.
Możesz to wypróbować samodzielnie, uruchamiając różne odmiany mojej pierwszej instrukcji SELECT z newsale stół. Zobaczysz inny wiersz w pamięci podręcznej dla każdego z nich. Po uruchomieniu kilku wariacji – zmiana szukanego numeru, zmiana wielkości liter, dodanie komentarza i nowej linii, w pamięci podręcznej widzę następujące. SELECT z mojego widoku jest ponownie używany, ale wszystko inne ma liczniki użycia wartość 1.
 Dodatkowym wymogiem ponownego użycia planu zapytań Adhoc jest to, że w sesji, na której uruchomione jest zapytanie, obowiązują te same opcje SET . W danych wyjściowych znajduje się kolejna kolumna, którą można zobaczyć po prawej stronie tekstu zapytania, o nazwie SETOPTS. Jest to ciąg bitów z bitem dla każdej odpowiedniej opcji SET. Jeśli zmienisz jedną z opcji, na przykład SET ANSI_NULLS OFF, ciąg bitów ulegnie zmianie i ten sam plan z oryginalnym ciągiem bitów nie będzie mógł zostać ponownie użyty.
Dodatkowym wymogiem ponownego użycia planu zapytań Adhoc jest to, że w sesji, na której uruchomione jest zapytanie, obowiązują te same opcje SET . W danych wyjściowych znajduje się kolejna kolumna, którą można zobaczyć po prawej stronie tekstu zapytania, o nazwie SETOPTS. Jest to ciąg bitów z bitem dla każdej odpowiedniej opcji SET. Jeśli zmienisz jedną z opcji, na przykład SET ANSI_NULLS OFF, ciąg bitów ulegnie zmianie i ten sam plan z oryginalnym ciągiem bitów nie będzie mógł zostać ponownie użyty.
Przygotowane skompilowane plany
Drugim typem skompilowanego planu w pamięci podręcznej jest plan PREPARED. Jeśli Twoje zapytanie spełnia określony zestaw wymagań. W rzeczywistości można go automatycznie sparametryzować. Pojawia się w metadanych jako PREPARED, a ciąg SQL zawiera znacznik parametru. Oto przykład:

Plan PREPARED pokazuje znacznik parametru jako @1 i nie zawiera rzeczywistej wartości. Zauważ, że istnieje wiersz dla zapytania ADHOC z rzeczywistą wartością 5555, ale w rzeczywistości jest to tylko „powłoka” prawdziwego zapytania. Nie buforuje całego planu, ale tylko zapytanie i kilka szczegółów identyfikujących, aby pomóc procesorowi zapytań znaleźć sparametryzowany plan w pamięci podręcznej. Zwróć uwagę na rozmiar (używane strony ) jest znacznie mniejszy niż plan PREPARED.
Domyślny tryb parametryzacji, zwany parametryzacją PROSTA, bardzo ściśle określa, jakie plany można sparametryzować. Tak naprawdę są to tak naprawdę tylko najprostsze zapytania, które można domyślnie sparametryzować. Kwerendy zawierające JOIN, GROUP BY, OR i wiele innych stosunkowo typowych konstrukcji zapytań uniemożliwiają sparametryzowanie zapytania. Oprócz braku żadnej z tych konstrukcji, najważniejszą rzeczą dla PROSTEJ parametryzacji jest to, że zapytanie jest BEZPIECZNE. Oznacza to, że istnieje tylko jeden możliwy plan bez względu na to, jakie wartości są przekazywane dla dowolnych parametrów. (Oczywiście zapytanie bez parametrów może być również BEZPIECZNE). Moje zapytanie szuka dokładnego dopasowania w kolumnie SalesOrderID , który ma unikalny indeks. Tak więc istniejący indeks nieklastrowy może zostać użyty do znalezienia dowolnego pasującego wiersza. Bez względu na to, jakiej wartości użyję, 55555 lub coś innego, nigdy nie będzie więcej niż jednego wiersza, co oznacza, że plan nadal będzie dobry.
W moim przykładzie planu zapytań Adhoc szukałem pasujących wartości dla Podsuma . Niektóre Podsumy wartości występują kilka razy lub wcale, więc indeks nieklastrowy byłby dobry. Ale inne wartości mogą wystąpić wiele razy, więc indeks NIE byłby przydatny. W związku z tym plan zapytania nie jest BEZPIECZNY i nie można sparametryzować zapytania. Dlatego widzieliśmy plan Adhoc dla mojego pierwszego przykładu.
JEŚLI masz zapytania z JOIN lub innymi niedozwolonymi konstrukcjami, możesz nakazać SQL Serverowi bardziej agresywne parametryzowanie, zmieniając opcję bazy danych:
ALTER DATABASE Parametryzacja AdventureWorks2016 SET FORCED;
IŚĆ
Ustawienie w bazie danych parametryzacji WYMUSZONE oznacza, że SQL Server będzie parametryzować znacznie więcej zapytań, w tym z opcją JOIN, GROUP BY, OR itp. Ale oznacza to również, że SQL Server może sparametryzować zapytanie, które nie jest BEZPIECZNE. Może wymyślić plan, który jest dobry, gdy zwracanych jest tylko kilka wierszy, a następnie ponownie korzystać z planu, gdy zwracanych jest wiele wierszy. Może to skończyć się bardzo nieoptymalną wydajnością.
Ostatnią opcją dla przygotowanego planu jest wyraźne przygotowanie planu. To zachowanie jest zwykle wywoływane przez aplikację z SQLPrepare i SQLExecute Pszczoła. Określasz, czym jest zapytanie za pomocą oznaczeń parametrów, określasz typy danych i określasz konkretne wartości do użycia. To samo zapytanie można następnie uruchomić ponownie z różnymi określonymi wartościami i zostanie użyty istniejący plan. Chociaż użycie jawnie przygotowanych planów może być możliwe w przypadkach, w których SQL Server nie parametryzuje, a Ty sobie tego życzysz, nie uniemożliwia to SQL Serverowi korzystania z planu, który NIE jest dobry dla kolejnych parametrów. Musisz przetestować swoje zapytania z wieloma różnymi wartościami wejściowymi i upewnić się, że uzyskasz oczekiwaną wydajność, jeśli i kiedy plan zostanie ponownie wykorzystany.
Metadane (np. moje sp_cacheobjects widok) pokazuje tylko PRZYGOTOWANE dla wszystkich trzech rodzajów planów:WYMUSZONA i PROSTA autoparametryzacja oraz WYRAŹNA parametryzacja.
Plany skompilowane przez proces
Ostatni objtype wartość Plany skompilowane dotyczy procedury składowanej, która jest wyświetlana jako Proc. Jeśli to możliwe, procedury składowane są najlepszym wyborem w przypadku kodu wielokrotnego użytku ze względu na łatwość zarządzania z samego serwera, ale nie oznacza to, że zawsze zapewniają najlepszą wydajność. Podobnie jak przy użyciu opcji parametryzacji WYMUSZONE (a także parametryzacji jawnej), procedury składowane wykorzystują „podsłuchiwanie parametrów”. Oznacza to, że pierwsza przekazana wartość parametru określa plan. Jeśli kolejne wykonania działają dobrze z tym samym planem, podsłuchiwanie parametrów nie stanowi problemu i może w rzeczywistości być korzystne, ponieważ pozwala zaoszczędzić na kosztach ponownej kompilacji i ponownej optymalizacji. Jeśli jednak kolejne egzekucje z różnymi wartościami nie powinny korzystać z pierwotnego planu, to mamy problem. Pokażę Ci przykład podsłuchiwania parametrów powodującego problem
Stworzę procedurę składowaną na podstawie newsale stół, którego używaliśmy wcześniej. Procedura będzie miała jedno zapytanie, które filtruje na podstawie SalesOrderID kolumna, na której zbudowaliśmy indeks nieklastrowy. Zapytanie będzie oparte na nierówności, więc dla niektórych wartości zapytanie może zwrócić tylko kilka wierszy i użyć indeksu, a dla innych wartości zapytanie może zwrócić DUŻO wierszy. Innymi słowy, zapytanie nie jest BEZPIECZNE.
USE AdventureWorks2016;
IŚĆ
DROP PROC IF EXISTS get_sales_range;
IŚĆ
UTWÓRZ PROC get_sales_range
@numer int
JAK
WYBIERZ * Z dbo.newsales
GDZIE IDZamówieniaSprzedaży <@num;
PRZEJDŹ
Użyję opcji SET STATISTICS IO ON, aby zobaczyć, ile pracy jest wykonywanej podczas wykonywania procedury. Najpierw wykonam go z parametrem, który zwraca tylko kilka wierszy:
WŁĄCZ IO STATYSTYK
IŚĆ
EXEC pobierz_zakres_sprzedaży 43700;
PRZEJDŹ
Wartość STATISTICS IO informuje, że zwrócenie 41 wierszy wymagało 43 odczytów logicznych. Jest to normalne w przypadku indeksu nieklastrowanego. Teraz wykonujemy procedurę ponownie ze znacznie większą wartością.
EXEC get_sales_range 66666;
IŚĆ
WYBIERZ * Z sp_cacheobjects;
IŚĆ
Tym razem widzimy, że SQL Server wykorzystał znacznie więcej odczytów:
 W rzeczywistości skan tabeli w newsale table zajmuje tylko 843 odczytów, więc jest to znacznie gorsza wydajność niż skanowanie tabeli. obiekty sp_cache widok pokazuje nam, że plan PROC został ponownie użyty do tego drugiego wykonania. To jest przykład, kiedy wąchanie parametrów NIE jest dobrą rzeczą.
W rzeczywistości skan tabeli w newsale table zajmuje tylko 843 odczytów, więc jest to znacznie gorsza wydajność niż skanowanie tabeli. obiekty sp_cache widok pokazuje nam, że plan PROC został ponownie użyty do tego drugiego wykonania. To jest przykład, kiedy wąchanie parametrów NIE jest dobrą rzeczą.
Co więc możemy zrobić, gdy podsłuchiwanie parametrów jest problemem? W następnym poście powiem Ci, kiedy SQL Server wymyśli nowy plan i nie wykorzysta starych. Przyjrzymy się, jak możesz wymusić (lub zachęcić) do ponownej kompilacji, a także zobaczymy, kiedy SQL Server automatycznie ponownie kompiluje Twoje zapytania.
Spotlight Cloud może zrewolucjonizować monitorowanie wydajności i diagnostykę serwera SQL. Rozpocznij bezpłatny okres próbny, korzystając z poniższego linku: