Prowadzenie warsztatu samochodowego/samochodowego to bardzo złożona działalność. Musisz umówić się na spotkanie, podczas gdy niektórzy klienci przyjadą, a nie chcesz, aby czekali godzinami. Będziesz także musiał organizować pracowników, śledzić naprawy, materiały, obciążać klientów itp. Na pewno będziesz potrzebować rozwiązania informatycznego i oczywiście modelu danych w tle. Dzisiaj porozmawiamy o jednym takim modelu.
Pomysł
Wspomniałem już, że ten model biznesowy jest naprawdę złożony. Dlatego nie będę starał się opisywać wszystkiego. Celowo pominąłem materiały do śledzenia i części zamienne, a także uprościłem niektóre części modelu. Powód tego jest dość prosty. Gdybym zamieściła naprawdę wszystko, model byłby po prostu za duży na artykuł o rozsądnych rozmiarach. Więc zacznijmy.
Model danych
Model składa się z 5 obszarów tematycznych:
Repair shops & employeesCustomers & contactsVehiclesServices & offersiVisits
Opiszemy każdy z tych 5 obszarów tematycznych w kolejności, w jakiej zostały wymienione.
Sekcja 1:Warsztaty i pracownicy
Pierwszym obszarem tematycznym, od którego zaczniemy, jest Repair shops & employees Tematyka. To całkiem oczywiste, że musimy wiedzieć, co mamy do dyspozycji, zanim będziemy mogli składać oferty klientom.
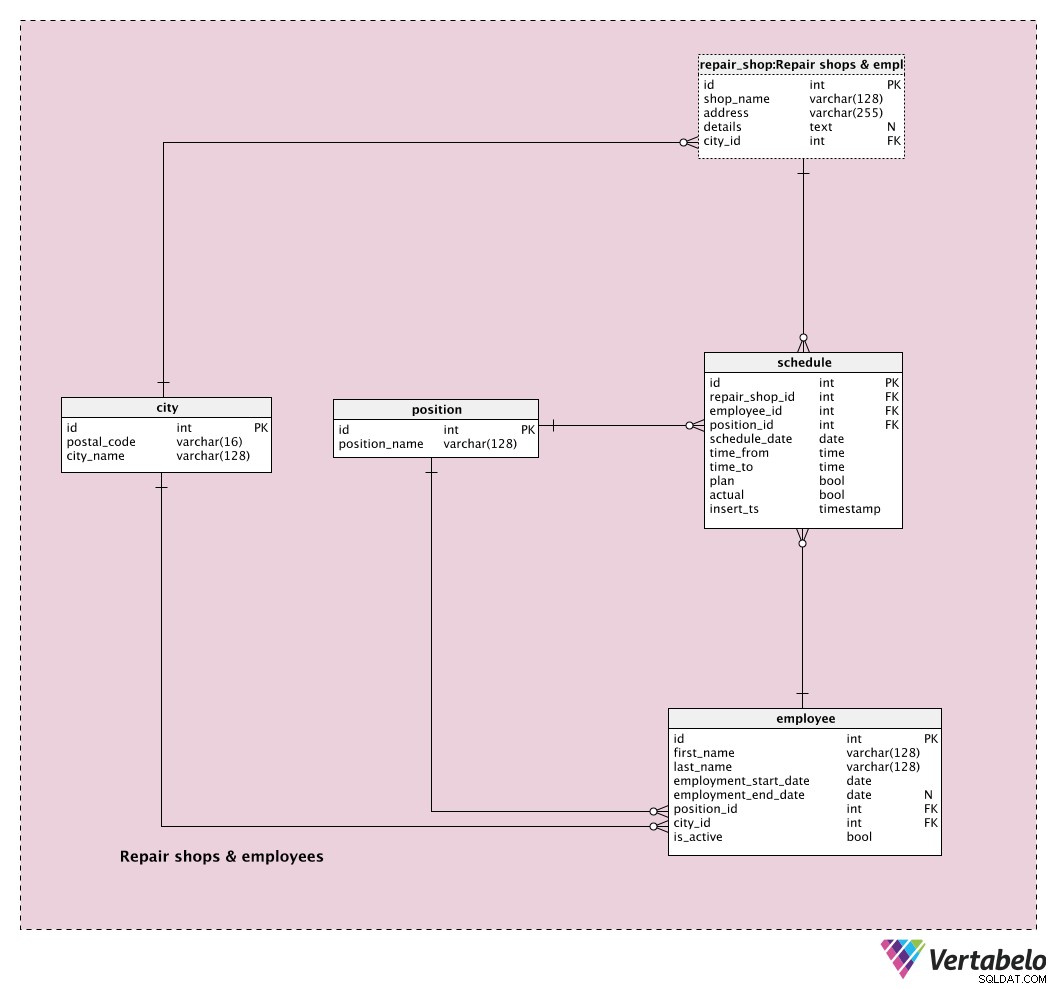
city Słownik służy do przechowywania wszystkich odrębnych miast, z których mamy warsztaty lub z których pochodzą nasi klienci. Każde miasto jest jednoznacznie zdefiniowane przez parę postal_code – city_name . Moglibyśmy zdecydować się na tylko jeden wpis na każde miasto, nawet jeśli to miasto ma wiele kodów pocztowych. W takim przypadku użylibyśmy tylko „głównego” kodu pocztowego dla tego miasta. Mimo to mamy możliwość posiadania wielu wpisów dla tego samego miasta i różnych kodów pocztowych – na wypadek, gdybyśmy tego chcieli.
repair_shop tabela to miejsce, w którym będziemy przechowywać listę wszystkich naszych warsztatów naprawczych. Możemy się spodziewać, że w pewnym momencie będziemy działać więcej niż jeden. Każdy sklep jest jednoznacznie zdefiniowany przez jego shop_name oraz identyfikator miasta, do którego należy (city_id ). Przechowamy również adres sklepu i dodatkowe details w formacie tekstowym, jeśli taki istnieje.
position słownik służy do przechowywania unikalnych position_names które mogą być przypisane naszym pracownikom. Chociaż większość stanowisk będzie związana z naszą podstawową działalnością, będziemy mieć również takie, które nie są częścią podstawowej działalności (role / stanowiska techniczne), ale są również niezbędne (administracja, sprzedaż itp.).
Lista wszystkich naszych pracowników jest przechowywana w employee stół. Dla każdego pracownika przechowamy jego:
first_name&last_name– Imię i nazwisko pracownika.employment_start_date&employment_end_date– Data rozpoczęcia i zakończenia pracownika w firmie. Data zakończenia powinna zawierać wartość NULL, dopóki nie będziemy mogli jej zdefiniować.position_id– Odniesienie do aktualnego stanowiska w firmie.city_id– Odniesienie do miasta, w którym aktualnie mieszka pracownik.is_active– Flaga informująca, czy pracownik jest aktualnie aktywny, czy nie.
Ostatnia tabela w tym obszarze tematycznym to schedule stół. W tej tabeli będziemy przechowywać dokładne harmonogramy dla wszystkich naszych pracowników na poziomie dziennym. Będziemy mieli również możliwość przechowywania wielu interwałów dla tego samego pracownika w ciągu tego samego dnia. Aby to osiągnąć, użyjemy następujących atrybutów:
repair_shop_id– Odniesienie do odpowiedniego warsztatu naprawczego.employee_id– Odniesienie do powiązanego pracownika.position_id– Odniesienie do powiązanego stanowiska, które pracownik miałby w określonym czasie. W większości przypadków byłaby to jego aktualna pozycja, ale mamy możliwość przypisania tutaj innej pozycji.schedule_date– Data, z którą związany jest ten wpis.time_from&time_to– Ta para określa okres czasu, z którym związany jest ten wpis.plan– Flaga informująca, czy był to planowany wpis. Wejście nie powinno być planowane tylko wtedy, gdy wstawiliśmy je ad hoc.actual– Ta flaga wskazuje, czy ten wpis został zrealizowany. Zauważ, że w większości przypadków obie flagi, plan i rzeczywista, byłyby ustawione na True. To wskazywałoby, że zaplanowaliśmy i faktycznie zrealizowaliśmy ten plan.insert_ts– Znacznik czasu oznaczający moment, w którym ten rekord został wstawiony do tabeli.
Kombinacja repair_shop_id - employee_id - schedule_date - time_from tworzy UNIKALNY/alternatywny klucz tej tabeli. Przed wstawieniem nowego rekordu powinniśmy również sprawdzić nowy interwał time_from – time_to nie pokrywa się z żadnym istniejącym przedziałem dla tego samego pracownika i daty.
Sekcja 2:Klienci i kontakty
Teraz jesteśmy gotowi do przejścia do części modelu związanej z klientem.
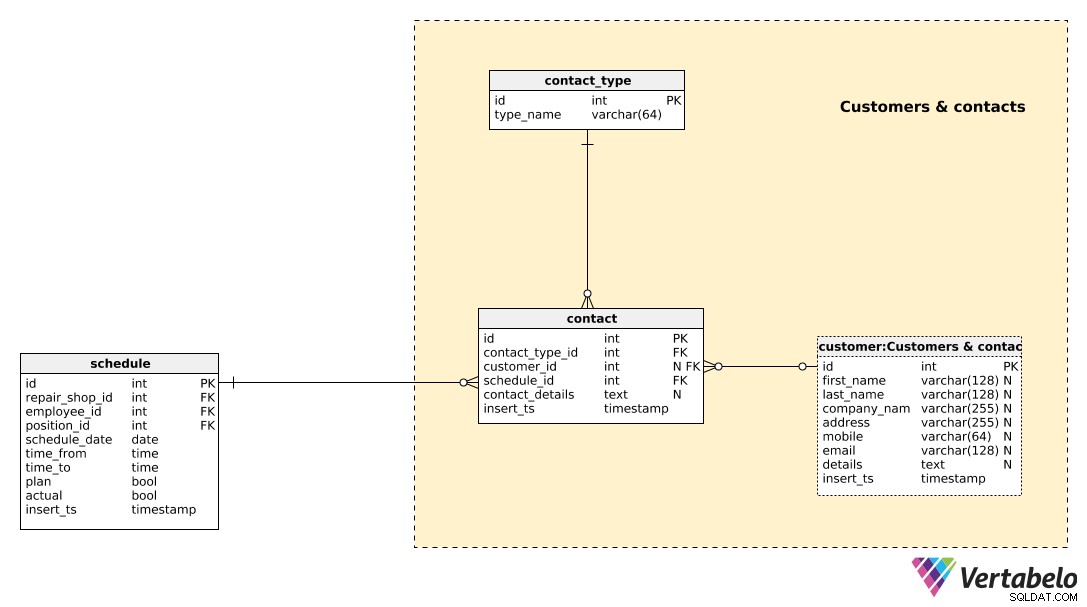
Wszystkich klientów, z którymi współpracowaliśmy lub z którymi mieliśmy kontakt, będziemy przechowywać w customer stół. Dla każdego klienta przechowujemy:
first_name&last_name– Imię i nazwisko klienta, w przypadku gdy nasz klient jest osobą prywatną.company_name– Nazwa firmy, w przypadku gdy klient to firma, a nie osoba prywatna.address– Adres klienta.mobile– Numer telefonu komórkowego klienta.email– E-mail klientadetails– Wszystkie dodatkowe dane klienta, jeśli takie istnieją, w formacie tekstowym.insert_ts– Znacznik czasu oznaczający moment, w którym ten rekord został wstawiony do tabeli.
Większość atrybutów w tej tabeli ma wartość null, ponieważ prawdopodobnie nie będziemy mieć niektórych z nich, a niektórych (first_name &last_name a company_name ) wyklucz inne.
Będziemy musieli śledzić wszystkie kontakty, które nawiązaliśmy z każdym klientem. W tym celu użyjemy dwóch tabel. Pierwszy, contact_type table, jest prostym słownikiem zawierającym tylko UNIKALNE type_name wartość.
Prawdziwe dane kontaktowe są przechowywane w contact stół. Będziemy przechowywać odniesienia do typu tego kontaktu (contact_type_id ), klient, z którym mieliśmy kontakt (customer_id ), pracownik, który nawiązał kontakt (schedule_id ), a także przechowywać dane kontaktowe i czas wstawienia tego rekordu do tabeli (insert_ts ).
Sekcja 3:Pojazdy
Po poznaniu naszych zasobów i klientów musimy przechowywać pojazdy, z którymi będziemy współpracować. Oprócz śledzenia danych i tworzenia raportów wewnętrznych, w większości krajów musimy również tworzyć raporty dla agencji regulacyjnych, firm ubezpieczeniowych, policji.
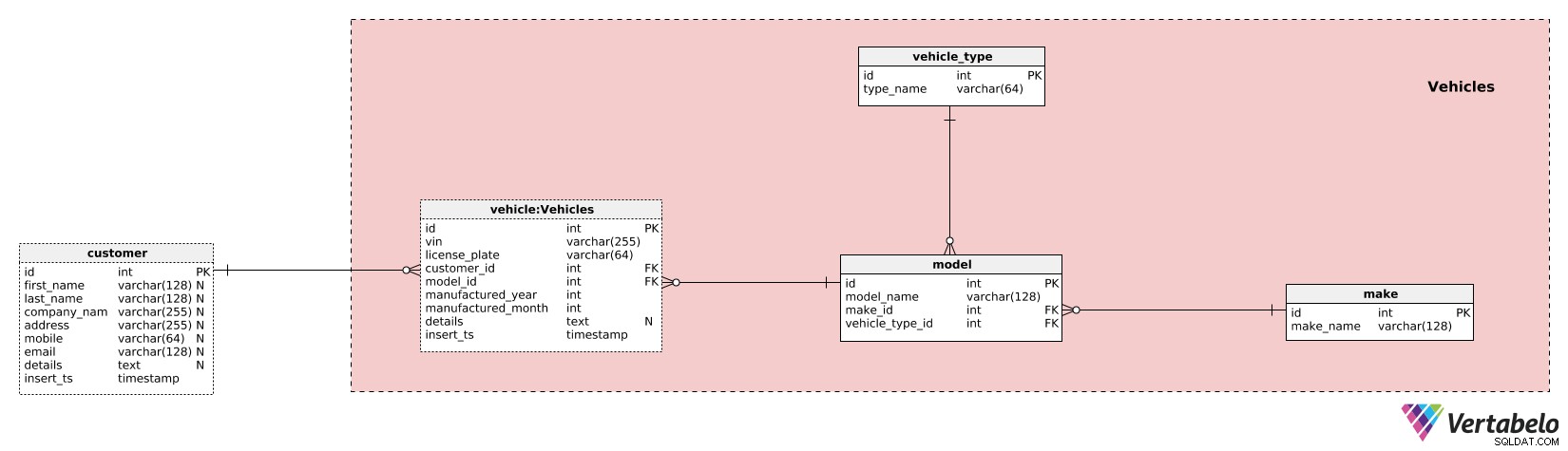
Najpierw zdefiniujemy modele naszych pojazdów. Aby to osiągnąć, użyjemy 3 tabel. W make słowniku, wymienimy unikalne make_names dla wszystkich producentów/marek samochodów/pojazdów. Poza tym musimy znać typy pojazdów, więc użyjemy jeszcze jednego słownika z tylko jednym unikalnym atrybutem wartości — type_name . 3 używany słownik to model słownik. Ten powinien zawierać listę wszystkich modeli, które przeszły przez nasze drzwi. Dla każdego modelu zdefiniujemy unikalną kombinację model_name – make_id – vechicle_type_id .
Skończymy opisywać ten obszar tematyczny za pomocą vehicle stół. To jedyna tabela w tej dziedzinie zawierająca „prawdziwe” dane. Użyjemy tej tabeli do przechowywania następujących informacji:
vin– Numer identyfikacyjny pojazdu, jednoznacznie określający ten pojazd.license_plate– Aktualny numer tablicy rejestracyjnej.customer_id– Odniesienie do klienta, do którego należy ten pojazd. Jeśli pojazd zmieni właściciela, wstawimy go jako nowy rekord, ale będziemy wiedzieć, że to ten sam pojazd na podstawie numeru seryjnego.model_id– Odniesienie do słownika modeli.manufactured_year&manufactured_month– Wskaż rok i miesiąc, w którym ten pojazd został wyprodukowany.details– Wszystkie dodatkowe szczegóły w formacie tekstowym.insert_ts– Znacznik czasu oznaczający moment, w którym ten rekord został wstawiony do tabeli.
Sekcja 4:Usługi i oferty
Jesteśmy gotowi na kolejny duży krok. Musimy określić, co oferujemy naszym (potencjalnym) klientom. Mogą to być pojedyncze zadania lub zestaw zadań – usług.
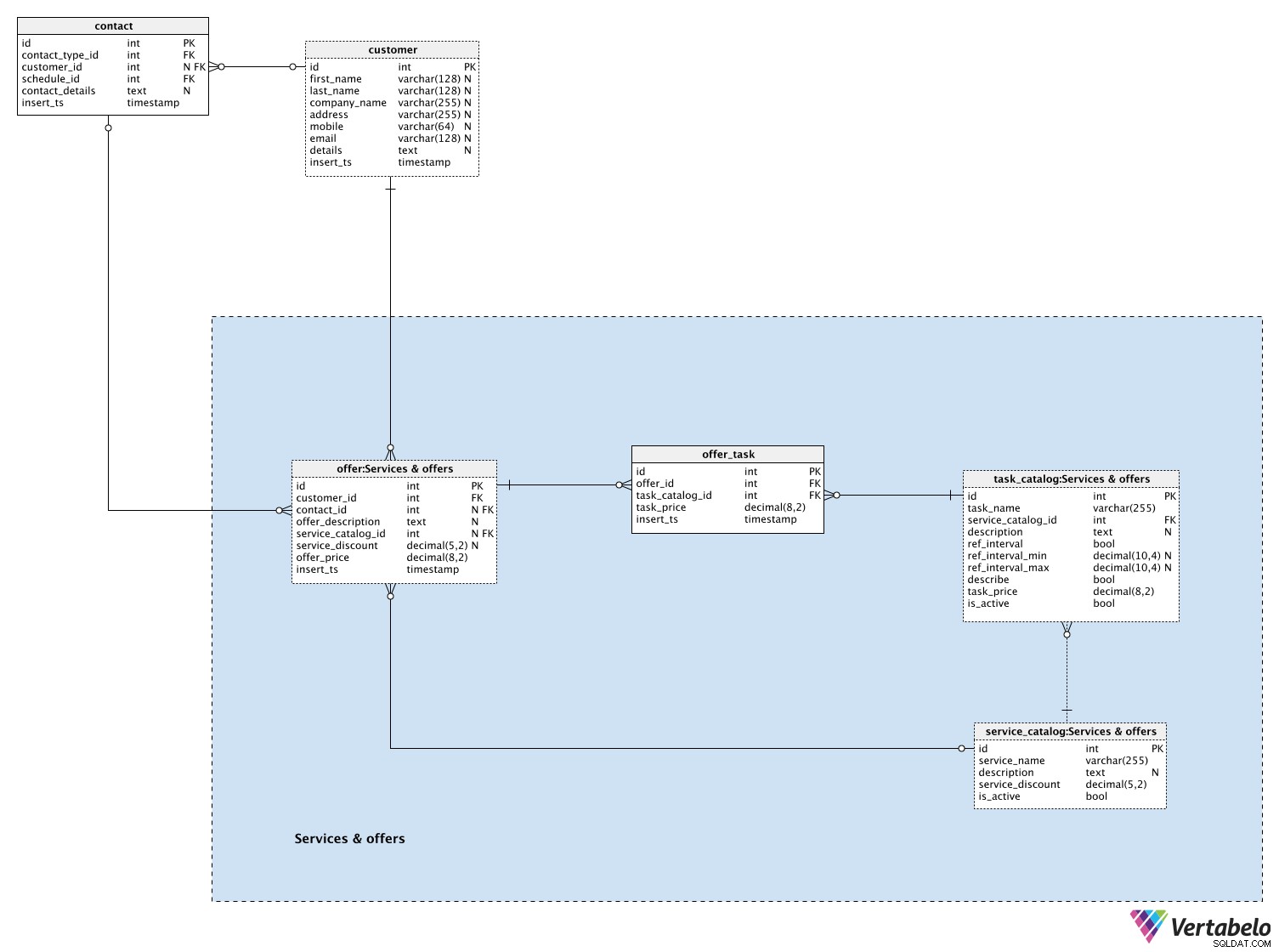
Lista wszystkich usług jest przechowywana w service_catalog słownik. Każda usługa składa się z kilku zadań i jest jednoznacznie zdefiniowana przez swoją service_name . Oprócz nazwy przechowamy również opis, jeśli taki mamy, procent service_discount i is_active flaga. Zniżka na usługę zostanie wykorzystana na wszystkie zadania objęte tą usługą.
Następnie zdefiniujemy zadania. Zadania są częścią naszych usług. Są to podstawowe działania, które można wykonać samodzielnie. Każde zadanie jest zdefiniowane przez te wartości w task_catalog tabela:
task_name&service_catalog_id– Nazwa, której będziemy używać do opisania tego zadania i usługi, do której należy. Ta para atrybutów tworzy unikalny klucz tabeli.description– Dodatkowy opis tekstowy, jeśli taki istnieje, użyty do opisania tego zadania.ref_interval– Flaga oznaczająca, czy będziemy mierzyć interwał dla tego zadania.ref_interval_min&ref_interval_max– Minimalna i maksymalna granica zakresu odniesienia.description– Flaga informująca, czy powinniśmy dodać komentarz tekstowy do tego zadania.task_price– Aktualna cena, bez rabatów serwisowych, za to zadanie.is_active– Flaga informująca, czy zadanie jest aktualnie aktywne (w naszej ofercie), czy nie.
Po kontakcie z klientami złożymy im oferty. Oferta może być kompletną usługą ze wszystkimi jej zadaniami lub zestawem zadań. Wszystkie oferty są przechowywane w offer stół. Dla każdej oferty przechowujemy:
customer_id– Identyfikator powiązanego klienta.contact_id– Identyfikator powiązanego kontaktu, jeśli taki był. Może to być ważna informacja, aby określić, ile ofert pojawiło się w wyniku poprzednich kontaktów.offer_description– Dodatkowy opis tekstowy tej oferty.service_catalog_id– Identyfikator usługi, którą zaoferowaliśmy klientowi. Ten identyfikator może być NULL w przypadku, gdy nie zaoferowaliśmy mu pełnej usługi, ale jedno lub więcej zadań, które nie są częścią usługi.service_discount– Zniżka na usługę w momencie tworzenia oferty. Ta wartość powinna zawierać NULL w przypadku, gdy oferta nie była związana z usługą.offer_price– Ostateczna cena tej oferty. Można to obliczyć jako sumę wszystkich zadań minus zniżka na usługę.insert_ts– Znacznik czasu oznaczający moment, w którym ten rekord został wstawiony do tabeli.
Ostatnia tabela w tym obszarze tematycznym to offer_task stół. Dla każdej oferty, bez względu na to, czy oferowaliśmy pełną usługę, czy nie, przechowujemy zestaw wszystkich zadań. Musimy przechowywać następujące dane:
offer_id– Identyfikator powiązanej oferty.task_catalog_id– identyfikator powiązanego zadania. Wraz zoffer_id, tworzy unikalny/alternatywny klucz tej tabelitask_price– Aktualna cena tego zadania w momencie wstawienia tego rekordu.insert_ts- Znacznik czasu wskazujący moment, w którym ten rekord został wstawiony do tabeli.
Sekcja 5:Odwiedziny
Ostatni obszar tematyczny w naszym modelu służy do przechowywania rzeczywistych wizyt klientów w naszym warsztacie. Chociaż wygląda to na skomplikowane, mamy tu tylko 2 nowe tabele, visit i visit_task .
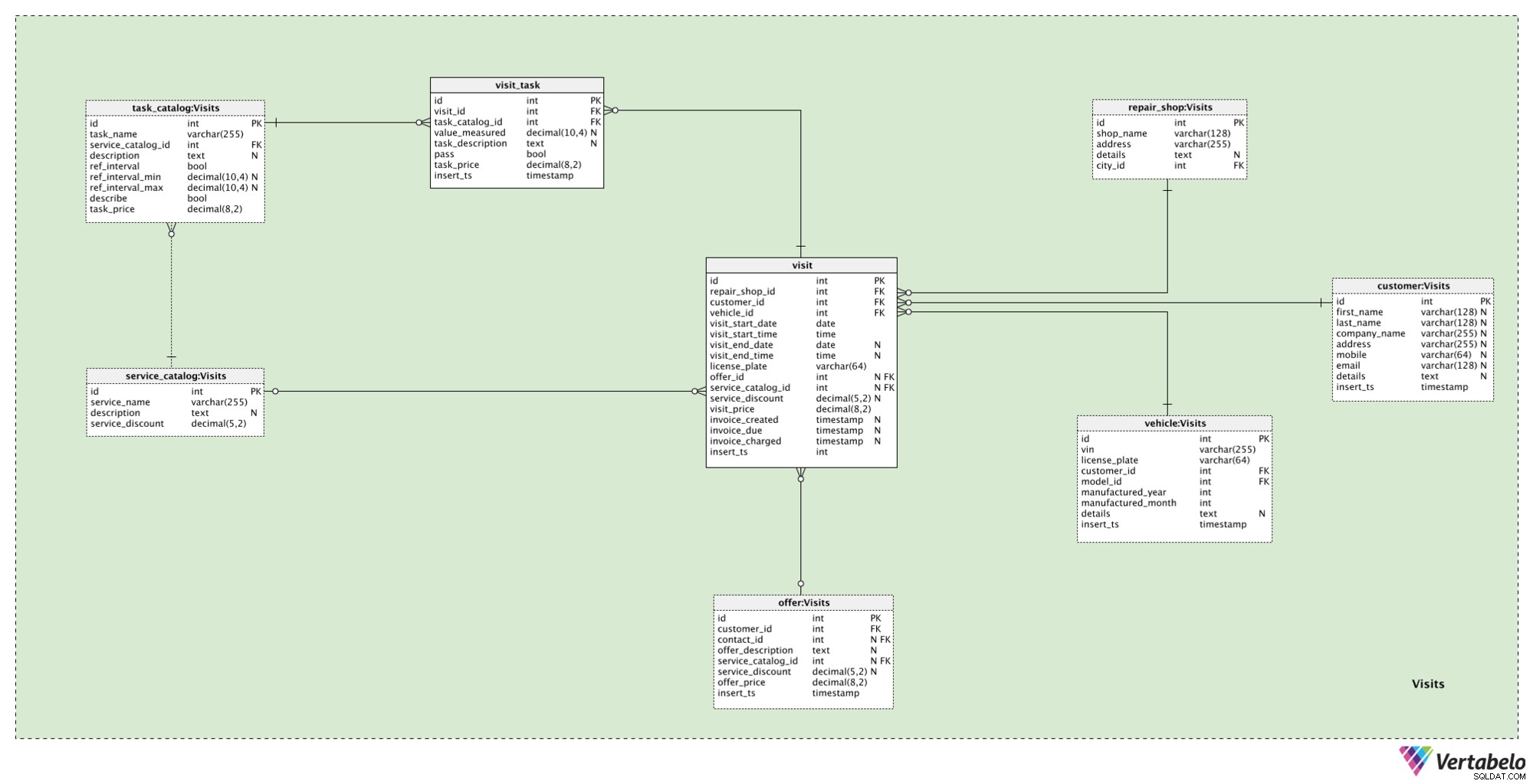
Gdy klient wyrazi zgodę na naszą ofertę lub po prostu wejdzie do naszego sklepu, potraktujemy to jako visit . Dla każdego takiego wydarzenia będziemy przechowywać następujące dane:
repair_shop_id– Odniesienie do odpowiedniego warsztatu naprawczego.customer_id– Odniesienie do klienta, z którym ta wizyta jest związana.vehicle_id– Odniesienie do pojazdu, którego dotyczy ta wizyta.visit_start_date– Data rozpoczęcia wizyty (planowana).visit_start_time– Godzina rozpoczęcia wizyty (planowana).visit_end_date– Data rozpoczęcia wizyty (rzeczywista). Tę wartość należy ustawić po faktycznym zakończeniu wizyty.visit_end_time– Godzina rozpoczęcia wizyty (rzeczywista). Tę wartość należy ustawić po faktycznym zakończeniu wizyty.license_plate– Numer rejestracyjny w momencie wizyty. Zauważ, że tablice rejestracyjne zmieniają się w czasie.offer_id– Identyfikator powiązanej oferty, jeśli taki istnieje.service_catalog_id– Identyfikator powiązanej usługi, jeśli taki istnieje.service_discount– Procentowa kwota rabatu w momencie dodania tego rekordu i w przypadku, gdy oferujemy pełną usługę.visit_price– Całkowita cena, jaką klient powinien zapłacić za tę wizytę.invoice_created– Znacznik czasu wygenerowania faktury.invoice_due– Znacznik czasu, kiedy faktura stała się wymagalna.invoice_charged– Znacznik czasu obciążenia faktury.insert_ts– Znacznik czasu oznaczający moment, w którym ten rekord został wstawiony do tabeli.
Ostatnia tabela w naszym modelu to visit_task stół. Jest to miejsce do przechowywania wszystkich zadań, które faktycznie były częścią tej wizyty. Dla każdego rekordu tutaj będziemy przechowywać następujące wartości:
visit_id– Nawiązanie do tej wizyty.task_catalog_id– Odniesienie do powiązanego zadaniavalue_measured– Wartość, która została zmierzona podczas tego zadania, jeśli zadanie wymagało pomiaru.task_description– Opis związany z tym zadaniem, jeśli zadanie wymaga opisu.pass– Flaga wskazująca, czy to zadanie było w oczekiwanym przedziale, czy nie.task_price– Rzeczywista cena tego zadania w tej chwili wstawiona do tej tabeli.insert_ts– Znacznik czasu oznaczający moment, w którym ten rekord został wstawiony do tabeli.
Chociaż ten model jest dość uproszczony, zawiera wszystkie niezbędne elementy, których będziesz potrzebować, aby zbudować wokół niego kompletny model. Części, które wymagają ulepszeń to na pewno wykorzystane materiały oraz obsługa płatności. Czy dodałbyś coś więcej do tego modelu?