W świecie baz danych jest kilka rzeczy, które są powszechnie akceptowane. Zwiększona pamięć RAM jest w dużej mierze korzystna dla systemów DMBS. Rozpowszechnianie danych i plików dziennika w macierzy RAID poprawia wydajność.
Konwencje nazewnictwa nie są jedną z tych rzeczy.
Jest to zaskakująco polaryzujący temat, w którym zwolennicy różnych metodologii są mocno zakorzenieni na swoich stanowiskach. I bardzo głośni i pełni pasji w ich obronie.
W tym artykule zagłębimy się w niektóre specyficzne konwencje i argumenty po obu stronach, próbując jednocześnie przedstawić rozsądne wnioski dla każdego punktu.
Wielka debata na temat pluralizacji
W istocie jest to prosty temat. Na przykład, jak prawidłowo nazwać tabelę zawierającą informacje o klientach w schemacie relacyjnej bazy danych? Czy to Customer lub Customers ?
Wiele argumentów po obu stronach.
Na pierwszy rzut oka , naturalne jest myślenie o zbiorze obiektów w liczbie mnogiej. Grupa kilku osób lub firm to Klienci . Dlatego tabela (będąca zbiorem obiektów) powinna być nazywana w liczbie mnogiej. Pojedynczy wiersz w tej tabeli to pojedynczy klient .
Zasady nazewnictwa ISO/IEC, chociaż są przestarzałe, zalecają nazwy tabel w liczbie mnogiej i nazwy kolumn w liczbie pojedynczej.
Większość tabel systemowych SQL Server używa nazw w liczbie mnogiej (sysnotifications , operatorzy systemowi ), ale jest to niespójne. Dlaczego sysproxylogin a nie sysproxylogins ?
W argumentach dotyczących nazw tabel w liczbie mnogiej wiersze w tabeli są również określane jako „instancje” całości – podobnie jak elementy w kolekcji. Klienci definiuje cały zestaw; jednego klienta jest instancją Klientów .
I odwrotnie, istnieje wiele powodów, dla których warto używać pojedynczych nazw obiektów.
Chociaż może być wiele pozycji (lub klientów ) w tabeli, samą tabelę można uznać za pojedynczą jednostkę. pudełko klientów nie jest „pudełkiem klientów”, nawet jeśli zawiera dużą liczbę klientów. Ponadto w tabeli może znajdować się tylko jedna pozycja – lub żaden – co czyni „klientów” mylącą nazwą.
Jeśli zdecydujesz się zmienić nazwę tabeli na podstawie wariantów słów, szybko mogą pojawić się niespójności. Wiele słów będzie prostych (Klient zostaje Klientami , Produkt staje się Produktami ), inne słowa mogą nie być. W tym przypadku Osoba może zostać ludźmi lub Osoby; pojedynczy łoś wyglądałaby tak samo, jak liczba mnoga, łoś . (Chociaż po co ci stół z łosiem?) Konwencja, taka jak People.FirstName zaczyna być myląco niejasne.
Jeśli w grę wchodzi wiele języków, sytuacja staje się jeszcze gorsza. Ponieważ liczba mnogości słów może różnić się na wiele sposobów (klienci, myszy, łosie, dzieci, kryzysy, programy nauczania, samoloty), osoby nie będące rodzimymi użytkownikami mają dodatkowe wyzwania. Trzymanie się pojedynczych nazw obiektów całkowicie eliminuje ten problem.
Pytanie dotyczące konwencji sprawy
W konwencjach przypadków nie ma takiego samego zapału jak w przypadku liczby mnogiej, ale argumenty są przemawiające za kilkoma różnymi opcjami. Należą do nich:
- Sprawa Pascala :Pierwsza litera każdego połączonego słowa jest pisana wielkimi literami, jak w:
CustomerOrder -
Wielbłąd :Pierwsza litera pierwszego słowa jest mała; wszystkie kolejne połączone słowa mają pierwszą literę wielką, jak w:
customerOrderPascal Case jest czasami uważany za podtyp Camel Case, ale Microsoft generalnie rozróżnia między nimi.
W przypadku słów krótszych niż trzy znaki zaleca się używanie tylko wielkich liter, jak w
UIlubIO. - Podkreślenie [przypadek „C”] :Słowa są oddzielone podkreśleniami, tak jak w przypadku
Customer_Orderlubcustomer_Order– jeszcze więcej decyzji!
Naukowcy z Uniwersytetu Johnsa Hopkinsa przeprowadzili badanie skuteczności używania podkreśleń w programowaniu nazw obiektów. Odkryli, że użycie Camel Case (lub Pascal Case) poprawiło dokładność pisania i rozpoznawanie. Podkreślenia były szeroko stosowane w programowaniu w C, ale trend zmierza w kierunku Camel/Pascal Case, z ostatnim naciskiem na języki Microsoft i Java.
Podobnie jak w przypadku innych tematów, obserwuj ustalona konwencja jest ważniejsza niż wybór samej konwencji.
Dodatkową kwestią jest rozróżnianie wielkości liter w bazie danych. Sortowanie SQL Server określa tę wrażliwość za pomocą „CS” (z uwzględnieniem wielkości liter) lub „CI” (bez uwzględniania wielkości liter) w nazwie sortowania. Na przykład:
SQL_Latin1_General_Cp437_CS_AS_KI_WI: Case Sensitive SQL_Latin1_General_Cp437_CI_AS_KI_WI: Case Insensitive
W sortowaniu uwzględniającym wielkość liter Select * from myTable nie powiedzie się w stosunku do obiektu MyTable . Może to sprawić, że podkreślenia będą nieco lepsze, aby uniknąć nieporozumień, ale Intellisense pomaga również wyeliminować błędy w pisaniu w większości nowoczesnych środowisk programistycznych.
Inne kwestie dotyczące konwencji nazewnictwa
Debata pojedyncza kontra mnoga i pytanie o wielką sprawę mogą być miejscem, w którym walka jest najbardziej zacięta, ale są jeszcze co najmniej trzy obszary, o których należy pamiętać, rozważając konwencję nazewnictwa.
Unikaj używania jakichkolwiek słów zastrzeżonych SQL Server jako nazw obiektów. Obejmuje to zarówno tabele, jak i kolumny. Na przykład – Użytkownik , Czas i data są zastrzeżone. Zarezerwowane słowa kluczowe mogą wymagać dodatkowej uwagi (np. użycie nawiasów kwadratowych) w zależności od aplikacji wywołującej. Dotyczy to również przestrzeni. Spacje w nazwach obiektów wymagają cudzysłowów jako odniesienia.
Wiąże się to również z innym zaleceniem – precyzją. System.CreateDate jest znacznie wyraźniejszy niż System.Date . Dobrze zaprojektowany model umożliwia widzowi natychmiastowe zrozumienie przeznaczenia obiektów leżących pod spodem. Gdy jakiekolwiek identyfikatory mają być określane jako klucze obce, zachowaj swobodę w nazwie – Customer.CustomerID zamiast ID.Klienta .
Unikaj przedrostków i przyrostków w tabelach i widokach , na przykład tblTable . Notacja węgierska (która zawsze miała na celu identyfikowanie użycia zmiennych) wpadła w powszechne konwencje nazewnictwa SQL Server, ale jest szeroko wyszydzana. Identyfikatory obiektów powinny opisywać zawartość, a nie sam obiekt.
Jednak prefiksy są przydatne w obiektach obsługujących SQL Server , ponieważ opisują funkcjonalną naturę obiektu.
Poniżej znajdują się powszechnie akceptowane przedrostki dla obiektów SQL Server:
- IX:Indeks
- PK:klucz podstawowy
- FK:klucz obcy
- CK:Sprawdź ograniczenie
- DF:domyślny
- UQ jest czasami używane również dla unikalnych indeksów.
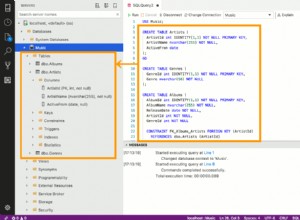
Model ten ilustruje punkty określone powyżej. Nie wymaga wyjaśnienia charakteru danych; stosowane są pojedyncze konwencje nazewnictwa i istnieją jasne identyfikatory.
W końcu po każdej stronie debaty na temat nazewnictwa konwencji są zalety i wady. Jest jednak jeden kluczowy punkt, co do którego obie strony mogą się zgodzić:niezależnie od podjętych decyzji należy zachować zgodność z wybraną konwencją.
Jakich konwencji nazewnictwa SQL używasz i dlaczego?