W pierwszej części tej serii przedstawiłem podstawową terminologię związaną z logowaniem, więc polecam to przeczytać przed kontynuowaniem tego postu. Wszystko, co omówię w tej serii, wymaga znajomości architektury dziennika transakcji, więc o tym tym razem omówię. Nawet jeśli nie zamierzasz śledzić serii, niektóre z koncepcji, które wyjaśnię poniżej, są warte poznania w codziennych zadaniach, którymi zajmują się administratorzy baz danych w produkcji.
Hierarchia strukturalna
Dziennik transakcji jest wewnętrznie zorganizowany przy użyciu trzypoziomowej hierarchii, jak pokazano na rysunku 1 poniżej.
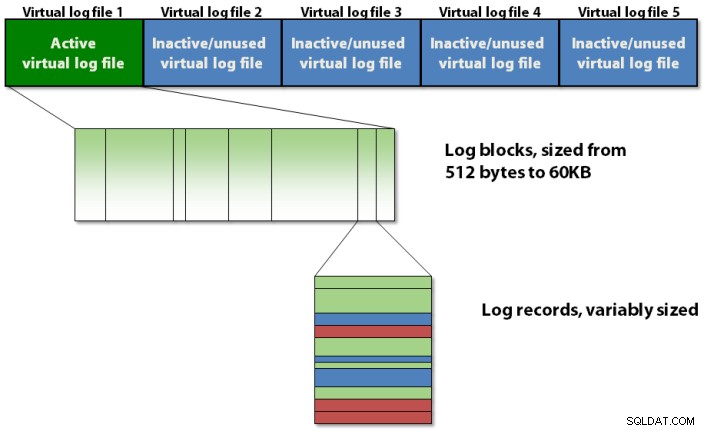 Rysunek 1:Trzypoziomowa hierarchia strukturalna dziennika transakcji
Rysunek 1:Trzypoziomowa hierarchia strukturalna dziennika transakcji
Dziennik transakcji zawiera wirtualne pliki dziennika, które zawierają bloki dziennika, w których przechowywane są rzeczywiste zapisy dziennika.
Wirtualne pliki dziennika
Dziennik transakcji jest podzielony na sekcje zwane wirtualnymi plikami dziennika , powszechnie nazywane po prostu VLF . Ma to na celu ułatwienie zarządzania operacjami w dzienniku transakcji dla menedżera dziennika w SQL Server. Nie możesz określić, ile plików VLF jest tworzonych przez SQL Server, gdy baza danych jest tworzona po raz pierwszy lub plik dziennika automatycznie się powiększa, ale możesz na to wpłynąć. Algorytm określający liczbę tworzonych plików VLF jest następujący:
- Rozmiar pliku dziennika mniejszy niż 64 MB:utwórz 4 pliki VLF, każdy o rozmiarze około 16 MB
- Rozmiar pliku dziennika od 64 MB do 1 GB:utwórz 8 plików VLF, każdy w przybliżeniu 1/8 całkowitego rozmiaru
- Rozmiar pliku dziennika większy niż 1 GB:utwórz 16 plików VLF, każdy z grubsza 1/16 całkowitego rozmiaru
Przed SQL Server 2014, gdy plik dziennika automatycznie rośnie, liczba nowych plików VLF dodawanych na końcu pliku dziennika jest określana przez powyższy algorytm, na podstawie rozmiaru automatycznego wzrostu. Jednak przy użyciu tego algorytmu, jeśli rozmiar automatycznego przyrostu jest mały, a plik dziennika podlega wielu automatycznym przyrostom, może to prowadzić do bardzo dużej liczby małych plików VLF (nazywanej fragmentacją VLF ), co może stanowić duży problem z wydajnością niektórych operacji (patrz tutaj).
Z powodu tego problemu w SQL Server 2014 zmieniono algorytm na automatyczny wzrost pliku dziennika. Jeśli rozmiar automatycznego wzrostu jest mniejszy niż 1/8 całkowitego rozmiaru pliku dziennika, tworzony jest tylko jeden nowy VLF, w przeciwnym razie używany jest stary algorytm. To drastycznie zmniejsza liczbę VLF dla pliku dziennika, który przeszedł duży automatyczny wzrost. Wyjaśniłem przykład różnicy w tym poście na blogu.
Każdy VLF ma numer kolejny który jednoznacznie go identyfikuje i jest używany w różnych miejscach, co wyjaśnię poniżej oraz w przyszłych postach. Można by pomyśleć, że numery sekwencyjne zaczynają się od 1 dla zupełnie nowej bazy danych, ale tak nie jest.
Na instancji SQL Server 2019 utworzyłem nową bazę danych bez określania rozmiarów plików, a następnie sprawdziłem VLF za pomocą poniższego kodu:
CREATE DATABASE NewDB;
GO
SELECT
[file_id],
[vlf_begin_offset],
[vlf_size_mb],
[vlf_sequence_number]
FROM
sys.dm_db_log_info (DB_ID (N'NewDB'));
Zwróć uwagę na sys.dm_db_log_info DMV został dodany w dodatku SP2 dla programu SQL Server 2016. Wcześniej (i dzisiaj, ponieważ nadal istnieje) możesz użyć nieudokumentowanego DBCC LOGINFO polecenie, ale nie możesz dać mu listy wyboru — po prostu wykonaj DBCC LOGINFO(N'NewDB'); a numery sekwencyjne VLF znajdują się w FSeqNo kolumna zestawu wyników.
W każdym razie wyniki zapytania sys.dm_db_log_info były:
file_id vlf_begin_offset vlf_size_mb vlf_sequence_number ------- ---------------- ----------- ------------------- 2 8192 1.93 37 2 2039808 1.93 0 2 4071424 1.93 0 2 6103040 2.17 0
Zauważ, że pierwszy VLF zaczyna się od przesunięcia 8192 bajtów w pliku dziennika. Dzieje się tak, ponieważ wszystkie pliki bazy danych, w tym dziennik transakcji, mają stronę nagłówka pliku, która zajmuje pierwsze 8 KB i przechowuje różne metadane dotyczące pliku.
Dlaczego więc SQL Server wybiera 37, a nie 1 jako pierwszy numer sekwencyjny VLF? Znajduje najwyższy numer sekwencyjny VLF w modelu bazy danych, a następnie, dla każdej nowej bazy danych, pierwszy plik VLF dziennika transakcji używa tego numeru plus 1 jako numeru sekwencyjnego. Nie wiem, dlaczego ten algorytm został wybrany w mgnieniu oka, ale tak było przynajmniej od SQL Server 7.0.
Aby to udowodnić, uruchomiłem ten kod:
SELECT
MAX ([vlf_sequence_number]) AS [Max_VLF_SeqNo]
FROM
sys.dm_db_log_info (DB_ID (N'model')); A wyniki były następujące:
Max_VLF_SeqNo -------------------- 36
Więc masz to.
Jest więcej do omówienia na temat VLF i sposobu ich użycia, ale na razie wystarczy wiedzieć, że każdy VLF ma numer sekwencyjny, który zwiększa się o jeden dla każdego VLF.
Bloki dziennika
Każdy plik VLF zawiera mały nagłówek metadanych, a resztę miejsca wypełniają bloki dziennika. Każdy blok dziennika zaczyna się od 512 bajtów i rośnie w 512-bajtowych przyrostach do maksymalnego rozmiaru 60 KB, po czym musi zostać zapisany na dysku. Blok dziennika może zostać zapisany na dysku, zanim osiągnie swój maksymalny rozmiar, jeśli wystąpi jedna z następujących sytuacji:
- Transakcja zostaje zatwierdzona, a opóźniona trwałość nie jest używana dla tej transakcji, więc blok dziennika musi zostać zapisany na dysku, aby transakcja była trwała
- W użyciu jest opóźniona trwałość, a w tle uruchamiane jest zadanie „przerzucania bieżącego bloku dziennika na dysk” na 1 ms
- Strona pliku danych jest zapisywana na dysku przez punkt kontrolny lub leniwy zapis, a w bieżącym bloku dziennika znajduje się co najmniej jeden rekord dziennika, który ma wpływ na stronę, która ma zostać zapisana (pamiętaj, że rejestrowanie z wyprzedzeniem musi być gwarantowane)
Blok dziennika można uznać za coś w rodzaju strony o zmiennym rozmiarze, która przechowuje rekordy dziennika w kolejności, w jakiej są tworzone przez transakcje zmieniające bazę danych. Nie ma bloku dziennika dla każdej transakcji; zapisy dziennika dla wielu jednoczesnych transakcji mogą być przemieszane w bloku dziennika. Można by pomyśleć, że może to stwarzać trudności w przypadku operacji, które muszą znaleźć wszystkie rekordy dziennika dla pojedynczej transakcji, ale tak się nie dzieje, ponieważ wyjaśnię, jak działa wycofywanie transakcji w późniejszym poście.
Co więcej, gdy blok dziennika jest zapisywany na dysku, jest całkowicie możliwe, że zawiera zapisy dziennika z niezatwierdzonych transakcji. Nie stanowi to również problemu ze względu na sposób, w jaki działa przywracanie po awarii — co jest kilkoma dobrymi postami w przyszłości.
Numery sekwencji dziennika
Bloki dziennika mają identyfikator w VLF, zaczynając od 1 i wzrastając o 1 dla każdego nowego bloku dziennika w VLF. Rekordy dziennika mają również identyfikator w bloku dziennika, zaczynając od 1 i wzrastając o 1 dla każdego nowego rekordu dziennika w bloku dziennika. Tak więc wszystkie trzy elementy w hierarchii strukturalnej dziennika transakcji mają identyfikator i są zebrane razem w trzyczęściowy identyfikator zwany numerem sekwencyjnym dziennika , częściej nazywany po prostu LSN .
LSN jest zdefiniowany jako
Wykonano prace ziemne!
Chociaż ważne jest, aby wiedzieć o VLF, moim zdaniem LSN jest najważniejszą koncepcją, którą należy zrozumieć wokół implementacji rejestrowania SQL Server, ponieważ LSN są podstawą, na której budowane są przywracanie transakcji i odzyskiwanie po awarii, a LSN będą pojawiać się raz za razem, gdy Przechodzę przez serię. W następnym poście omówię obcinanie dziennika i cykliczną naturę dziennika transakcji, co ma związek z plikami VLF i sposobami ich ponownego wykorzystania.