Benjamin Nevarez jest niezależnym konsultantem z Los Angeles w Kalifornii, który specjalizuje się w dostrajaniu i optymalizacji zapytań SQL Server. Jest autorem „SQL Server 2014 Query Tuning &Optimization” i „Inside the SQL Server Query Optimizer” oraz współautorem „SQL Server 2012 Internals”. Mając ponad 20-letnie doświadczenie w relacyjnych bazach danych, Benjamin był również prelegentem na wielu konferencjach poświęconych SQL Server, w tym PASS Summit, SQL Server Connections i SQLBits. Blog Benjamina można znaleźć na https://www.benjaminnevarez.com i można się z nim również skontaktować przez e-mail na adres admin na benjaminnevarez dot com i na Twitterze na @BenjaminNevarez.
Podczas gdy większość informacji, blogów i dokumentacji na temat SQL Server 2014 skupiała się na Hekatonie i innych nowych funkcjach, nie podano wielu szczegółów dotyczących nowego estymatora kardynalności. Obecnie BOL tylko pośrednio mówi o tym w sekcji Co nowego (aparat bazy danych), mówiąc, że SQL Server 2014 „zawiera znaczne ulepszenia w komponencie, który tworzy i optymalizuje plany zapytań” oraz ALTER DATABASE oświadczenie pokazuje, jak włączyć lub wyłączyć jego zachowanie. Na szczęście możemy uzyskać dodatkowe informacje, czytając artykuł badawczy Testing Cardinality Estimation Models in SQL Server autorstwa Campbell Fraser et al. Chociaż głównym tematem artykułu jest proces zapewniania jakości nowego modelu estymacji, przedstawia on również podstawowe wprowadzenie do nowego estymatora kardynalności oraz motywację jego przeprojektowania.
Czym więc jest estymator kardynalności? Estymator liczności jest elementem procesora zapytań, którego zadaniem jest oszacowanie liczby wierszy zwracanych przez operacje relacyjne w zapytaniu. Te informacje, wraz z kilkoma innymi danymi, są używane przez optymalizator zapytań w celu wybrania wydajnego planu wykonania. Szacowanie kardynalności jest z natury niedokładne, ponieważ jest to model matematyczny, który opiera się na informacjach statystycznych. Opiera się również na kilku założeniach, które, choć nieudokumentowane, były znane na przestrzeni lat – niektóre z nich obejmują założenia jednolitości, niezależności, ograniczania i włączania. Poniżej znajduje się krótki opis tych założeń.
- Jednorodność . Używane, gdy rozkład dla atrybutu jest nieznany, na przykład wewnątrz wierszy zakresu w kroku histogramu lub gdy histogram nie jest dostępny.
- Niezależność . Używane, gdy atrybuty w relacji są niezależne, chyba że znana jest korelacja między nimi.
- Zamknięcie . Używane, gdy dwa atrybuty mogą być takie same, zakłada się, że są takie same.
- Włączenie . Używane podczas porównywania atrybutu ze stałą, zakłada się, że zawsze jest dopasowanie.
Interesujące jest to, że niedawno mówiłem o niektórych ograniczeniach tych założeń podczas mojego ostatniego wykładu na PASS Summit, zatytułowanego Pokonywanie ograniczeń optymalizatora zapytań. Ze zdziwieniem przeczytałem jednak w artykule, że autorzy przyznają, że zgodnie z ich doświadczeniem w praktyce te założenia są „często błędne”.
Obecny estymator kardynalności został napisany wraz z całym procesorem zapytań dla SQL Server 7.0, który został wydany w grudniu 1998 roku. Oczywiście ten składnik przeszedł wiele zmian w ciągu kilku lat i wiele wydań SQL Server, w tym poprawki, dostosowania i rozszerzenia uwzględnić szacowanie kardynalności dla nowych funkcji T-SQL. Być może zastanawiasz się, po co wymieniać komponent, który był z powodzeniem używany przez około 15 lat?
Dlaczego nowy estymator liczności
Artykuł wyjaśnia niektóre powody przeprojektowania, w tym:
- Aby dostosować estymator kardynalności do nowych wzorców obciążenia.
- Zmiany wprowadzone w estymatorze liczności na przestrzeni lat sprawiły, że komponent był trudny do „debugowania, przewidywania i zrozumienia”.
- Próba ulepszenia obecnego modelu przy obecnej architekturze była trudna, więc stworzono nowy projekt, skupiający się na rozdzieleniu zadań (a) decydowania o sposobie obliczenia konkretnego oszacowania i (b) faktycznego wykonywania obliczeń .
Nie jestem pewien, czy więcej szczegółów na temat nowego estymatora kardynalności opublikuje Microsoft. W końcu w ciągu 15 lat nie opublikowano tak wielu szczegółów na temat starego estymatora kardynalności; na przykład, w jaki sposób obliczane jest określone oszacowanie kardynalności. Z drugiej strony pojawiły się nowe rozszerzone zdarzenia, które możemy wykorzystać do rozwiązywania problemów z szacowaniem kardynalności lub po prostu do zbadania, jak to działa. Te zdarzenia obejmują query_optimizer_estimate_cardinality , inaccurate_cardinality_estimate , query_optimizer_force_both_cardinality_estimation_behaviors i query_rpc_set_cardinality .
Regresje planu
Głównym problemem, który przychodzi na myśl przy tak dużej zmianie w optymalizatorze zapytań, są regresje planu. Strach przed regresją planu został uznany za największą przeszkodę w ulepszeniu optymalizatora zapytań. Regresje to problemy pojawiające się po zastosowaniu poprawki w optymalizatorze zapytań i czasami określane jako klasyczne „dwa zło naprawiają”. Może się tak zdarzyć, gdy dwie złe oceny, na przykład jedna zawyżająca wartość, a druga ją niedoszacowująca, znoszą się wzajemnie, dając na szczęście dobre oszacowanie. Korekta tylko jednej z tych wartości może teraz prowadzić do złego oszacowania, co może negatywnie wpłynąć na wybór planu, powodując regresję.
Aby uniknąć regresji związanych z nowym estymatorem kardynalności, SQL Server zapewnia sposób włączania lub wyłączania go, ponieważ zależy to od poziomu zgodności bazy danych. Można to zmienić za pomocą ALTER DATABASE oświadczenie, jak wskazano wcześniej. Ustawienie bazy danych na poziom zgodności 120 będzie wykorzystywał nowy estymator kardynalności, podczas gdy poziom zgodności mniejszy niż 120 będzie wykorzystywał stary estymator kardynalności. Ponadto po użyciu określonego estymatora kardynalności istnieją dwie flagi śledzenia, których można użyć do zmiany na drugą. Chociaż w tej chwili nie widzę nigdzie udokumentowanych flag śledzenia, są one wymienione jako część opisu query_optimizer_force_both_cardinality_estimation_behaviors rozszerzone wydarzenie. Flagi śledzenia 2312 można użyć do włączenia nowego estymatora liczności, a flagi śledzenia 9481 do jej wyłączenia. Możesz nawet użyć flag śledzenia dla określonego zapytania za pomocą QUERYTRACEON wskazówka (chociaż nie jest jeszcze udokumentowane, czy ta będzie obsługiwana).
Przykłady
Na koniec w artykule wspomniano również o niektórych przetestowanych scenariuszach, takich jak przepełniony klucz podstawowy, proste łączenie lub problem z kluczem rosnącym. Pokazuje również, w jaki sposób autorzy eksperymentowali z wieloma scenariuszami (lub wariantami modelu), a w niektórych przypadkach „złagodzili” niektóre założenia przyjęte przez estymator kardynalności, na przykład w przypadku założenia niezależności, przechodząc od całkowitej niezależności do pełnej korelacji i coś pomiędzy, dopóki nie znaleziono dobrych wyników.
Chociaż w artykule nie podano żadnych szczegółów, postanawiam rozpocząć testowanie niektórych z tych scenariuszy, aby spróbować zrozumieć, jak działa nowy estymator kardynalności. Na razie pokażę Ci przykład z wykorzystaniem założenia niezależności i kluczy rosnących. Przetestowałem również założenie jednorodności, ale do tej pory nie byłem w stanie znaleźć żadnej różnicy w estymacji.
Zacznijmy od przykładu założenia niezależności. Najpierw przyjrzyjmy się obecnemu zachowaniu. W tym celu upewnij się, że używasz starego estymatora liczności, uruchamiając następującą instrukcję w bazie danych AdventureWorks2012:
ALTER DATABASE AdventureWorks2012 SET COMPATIBILITY_LEVEL = 110;
Następnie uruchom:
SELECT * FROM Person.Address WHERE City = 'Burbank';
Otrzymujemy szacunkowo 196 rekordów, jak pokazano poniżej:

W podobny sposób następujące stwierdzenie otrzyma szacunkowo 194:
SELECT * FROM Person.Address WHERE PostalCode = '91502';
Jeśli użyjemy obu predykatów, otrzymamy następujące zapytanie, które będzie miało szacunkową liczbę wierszy 1.93862 (zaokrągloną do 2 wierszy w przypadku korzystania z SQL Sentry Plan Explorer):
SELECT * FROM Person.Address WHERE City = 'Burbank' AND PostalCode = '91502';
Wartość ta jest obliczana przy założeniu całkowitej niezależności obu predykatów przy użyciu formuły (196 * 194) / 19614.0 (gdzie 19614 to łączna liczba wierszy w tabeli). Użycie całkowitej korelacji powinno dać nam szacunkową liczbę 194, ponieważ wszystkie rekordy z kodem pocztowym 91502 należą do Burbank. Nowy estymator kardynalności szacuje wartość, która nie zakłada całkowitej niezależności ani całkowitej korelacji. Zmień na nowy estymator kardynalności, używając następującego stwierdzenia:
ALTER DATABASE AdventureWorks2012 SET COMPATIBILITY_LEVEL = 120; GO SELECT * FROM Person.Address WHERE City = 'Burbank' AND PostalCode = '91502';
Ponowne uruchomienie tej samej instrukcji da szacunkową liczbę 19,3931 wierszy, co, jak widać, jest wartością między założeniem całkowitej niezależności a całkowitą korelacją (w zaokrągleniu do 19 wierszy w Eksploratorze planów). Zastosowany wzór to selektywność najbardziej selektywnego filtra * SQRT (selektywność następnego najbardziej selektywnego filtra) lub (194/19614.0) * SQRT(196/19614.0) * 19614 co daje 19,393:

Jeśli włączyłeś nowy estymator kardynalności na poziomie bazy danych, kup chcesz wyłączyć go dla określonego zapytania, aby uniknąć regresji planu, możesz użyć flagi śledzenia 9481, jak wyjaśniono wcześniej:
ALTER DATABASE AdventureWorks2012 SET COMPATIBILITY_LEVEL = 120; GO SELECT * FROM Person.Address WHERE City = 'Burbank' AND PostalCode = '91502' OPTION (QUERYTRACEON 9481);
Uwaga:Wskazówka dotycząca zapytania QUERYTRACEON służy do stosowania flagi śledzenia na poziomie zapytania i obecnie jest obsługiwana tylko w ograniczonej liczbie scenariuszy. Więcej informacji o wskazówce dotyczącej zapytania QUERYTRACEON można znaleźć pod adresem https://support.microsoft.com/kb/2801413.
Przyjrzyjmy się teraz rosnącemu kluczowemu problemowi, który szczegółowo wyjaśniłem w tym poście. Tradycyjną rekomendacją firmy Microsoft dotyczącą rozwiązania tego problemu jest ręczna aktualizacja statystyk po załadowaniu danych, jak wyjaśniono tutaj – opisując problem w następujący sposób:
Statystyki dotyczące rosnących lub malejących kolumn kluczy, takich jak IDENTITY lub kolumny sygnatury czasowej w czasie rzeczywistym, mogą wymagać częstszych aktualizacji statystyk niż wykonuje optymalizator zapytań. Operacje wstawiania dodają nowe wartości do kolumn rosnących lub malejących. Liczba dodanych wierszy może być zbyt mała, aby wyzwolić aktualizację statystyk. Jeśli statystyki nie są aktualne, a zapytania wybierają spośród ostatnio dodanych wierszy, bieżące statystyki nie będą zawierały szacunków kardynalności dla tych nowych wartości. Może to skutkować niedokładnymi szacunkami kardynalności i niską wydajnością zapytań. Na przykład zapytanie, które wybiera spośród ostatnich dat zamówień sprzedaży, będzie zawierało niedokładne szacunki liczności, jeśli statystyki nie zostaną zaktualizowane w celu uwzględnienia szacunkowych liczności dla najnowszych dat zamówień sprzedaży.
Zaleceniem w moim artykule było użycie flag śledzenia 2389 i 2390, które zostały po raz pierwszy opublikowane przez Iana Jose w jego artykule Ascending Keys and Auto Quick Corrected Statistics. Możesz przeczytać mój artykuł, aby uzyskać wyjaśnienie i przykład, jak używać tych flag śledzenia, aby uniknąć tego problemu. Te flagi śledzenia nadal działają w programie SQL Server 2014 CTP2. Ale jeszcze lepiej, nie są już potrzebne, jeśli korzystasz z nowego estymatora kardynalności.
Używając tego samego przykładu w moim poście:
CREATE TABLE dbo.SalesOrderHeader (
SalesOrderID int NOT NULL,
RevisionNumber tinyint NOT NULL,
OrderDate datetime NOT NULL,
DueDate datetime NOT NULL,
ShipDate datetime NULL,
Status tinyint NOT NULL,
OnlineOrderFlag dbo.Flag NOT NULL,
SalesOrderNumber nvarchar(25) NOT NULL,
PurchaseOrderNumber dbo.OrderNumber NULL,
AccountNumber dbo.AccountNumber NULL,
CustomerID int NOT NULL,
SalesPersonID int NULL,
TerritoryID int NULL,
BillToAddressID int NOT NULL,
ShipToAddressID int NOT NULL,
ShipMethodID int NOT NULL,
CreditCardID int NULL,
CreditCardApprovalCode varchar(15) NULL,
CurrencyRateID int NULL,
SubTotal money NOT NULL,
TaxAmt money NOT NULL,
Freight money NOT NULL,
TotalDue money NOT NULL,
Comment nvarchar(128) NULL,
rowguid uniqueidentifier NOT NULL,
ModifiedDate datetime NOT NULL
); Wstaw jakieś dane:
INSERT INTO dbo.SalesOrderHeader SELECT * FROM Sales.SalesOrderHeader WHERE OrderDate < '2008-07-20 00:00:00.000'; CREATE INDEX IX_OrderDate ON SalesOrderHeader(OrderDate);
Odkąd stworzyliśmy indeks, mamy właśnie nowe statystyki. Uruchomienie następującego zapytania da dobre oszacowanie 35 wierszy:
SELECT * FROM dbo.SalesOrderHeader WHERE OrderDate = '2008-07-19 00:00:00.000';
Jeśli wstawimy nowe dane:
INSERT INTO dbo.SalesOrderHeader SELECT * FROM Sales.SalesOrderHeader WHERE OrderDate = '2008-07-20 00:00:00.000';
Możesz zobaczyć oszacowanie ze starym estymatorem kardynalności, jak pokazano poniżej:
ALTER DATABASE AdventureWorks2012 SET COMPATIBILITY_LEVEL = 110; GO SELECT * FROM dbo.SalesOrderHeader WHERE OrderDate = '2008-07-20 00:00:00.000';

Ponieważ mała liczba wstawionych rekordów nie była wystarczająca, aby wyzwolić automatyczną aktualizację obiektu statystyk, bieżący histogram nie jest świadomy dodanych nowych rekordów, a optymalizator zapytań używa szacunkowo 1 wiersza. Opcjonalnie można użyć flag śledzenia 2389 i 2390, aby uzyskać lepsze oszacowanie. Ale jeśli wypróbujesz to samo zapytanie z nowym estymatorem kardynalności, otrzymasz następujące oszacowanie:
ALTER DATABASE AdventureWorks2012 SET COMPATIBILITY_LEVEL = 120; GO SELECT * FROM dbo.SalesOrderHeader WHERE OrderDate = '2008-07-20 00:00:00.000';
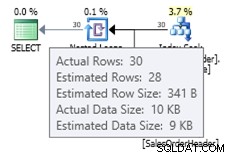
W tym przypadku otrzymujemy lepsze oszacowanie niż stary estymator kardynalności (lub otrzymujemy takie samo oszacowanie, jak przy użyciu flag śledzenia 2389 lub 2390). Szacunkowa wartość 27,9631 (ponownie, zaokrąglona do 28 przez Plan Explorer) jest obliczana przy użyciu informacji o gęstości obiektu statystyki pomnożonej przez liczbę wierszy tabeli; czyli 0,0008992806 * 31095. Wartość gęstości można uzyskać za pomocą:
DBCC SHOW_STATISTICS('dbo.SalesOrderHeader', 'IX_OrderDate'); Na koniec należy pamiętać, że nic, o czym wspomniano w tym artykule, nie jest udokumentowane i jest to zachowanie, które do tej pory zaobserwowałem w SQL Server 2014 CTP2. Wszystko to może się zmienić w późniejszej wersji CTP lub RTM produktu.