Opóźniona trwałość to nowatorska, ale interesująca funkcja programu SQL Server 2014; wysokość windy na wysokim poziomie tej funkcji jest po prostu:
- "Zamień trwałość na wydajność."
Najpierw trochę tła. Domyślnie SQL Server używa dziennika zapisu z wyprzedzeniem (WAL), co oznacza, że zmiany są zapisywane w dzienniku, zanim zostaną zatwierdzone. W systemach, w których zapisy dziennika transakcji stają się wąskim gardłem i gdzie istnieje umiarkowana tolerancja na utratę danych , masz teraz możliwość tymczasowego zawieszenia wymagania oczekiwania na opróżnienie dziennika i potwierdzenie. Tak się składa, że dosłownie usuwa D z ACID, przynajmniej dla małej porcji danych (więcej o tym później).
Poniekąd już teraz dokonujesz tego poświęcenia. W trybie pełnego odzyskiwania zawsze istnieje pewne ryzyko utraty danych, mierzy się je tylko czasem, a nie rozmiarem. Na przykład, jeśli tworzysz kopię zapasową dziennika transakcji co pięć minut, możesz stracić do 5 minut danych, jeśli wydarzy się coś katastroficznego. Nie mówię tutaj o prostym przełączaniu awaryjnym, ale powiedzmy, że serwer dosłownie się zapala lub ktoś potyka się o przewód zasilający – baza danych może być bardzo niemożliwa do odzyskania i może być konieczne cofnięcie się do punktu w czasie, w którym wykonano ostatnią kopię zapasową dziennika . A to przy założeniu, że nawet testujesz kopie zapasowe, przywracając je gdzieś — w przypadku krytycznej awarii możesz nie mieć punktu przywracania, o którym myślisz, że masz. Oczywiście nie myślimy o tym scenariuszu, ponieważ nigdy nie oczekujemy złych rzeczy™ się wydarzyć.
Jak to działa
Opóźniona trwałość umożliwia kontynuowanie działania transakcji zapisu tak, jakby dziennik został opróżniony na dysk; w rzeczywistości zapisy na dysku zostały pogrupowane i odroczone, aby były obsługiwane w tle. Transakcja jest optymistyczna; zakłada, że opróżnianie dziennika będzie zdarzyć. System używa 60KB fragmentu bufora dziennika i próbuje opróżnić dziennik na dysk, gdy ten 60KB blok jest pełny (najpóźniej – może się to zdarzyć i często zdarza się wcześniej). Możesz ustawić tę opcję na poziomie bazy danych, na poziomie pojedynczej transakcji lub – w przypadku natywnie skompilowanych procedur w In-Memory OLTP – na poziomie procedury. Ustawienie bazy danych wygrywa w przypadku konfliktu; na przykład, jeśli baza danych jest wyłączona, próba zatwierdzenia transakcji przy użyciu opcji opóźnionej zostanie po prostu zignorowana, bez komunikatu o błędzie. Ponadto niektóre transakcje są zawsze w pełni trwałe, niezależnie od ustawień bazy danych lub ustawień zatwierdzania; na przykład transakcje systemowe, transakcje między bazami danych i operacje obejmujące tabelę plików, śledzenie zmian, przechwytywanie danych zmian i replikację.
Na poziomie bazy danych możesz użyć:
ALTER DATABASE dbname SET DELAYED_DURABILITY = DISABLED | ALLOWED | FORCED;
Jeśli ustawisz go na ALLOWED , oznacza to, że każda pojedyncza transakcja może korzystać z opóźnionej trwałości; FORCED oznacza, że wszystkie transakcje, które mogą korzystać z opóźnionej trwałości, będą miały zastosowanie (w tym przypadku nadal obowiązują powyższe wyjątki). Prawdopodobnie będziesz chciał użyć ALLOWED zamiast FORCED – ale to ostatnie może być przydatne w przypadku istniejącej aplikacji, w której chcesz korzystać z tej opcji przez cały czas, a także zminimalizować ilość kodu, który trzeba dotknąć. Ważna rzecz do zapamiętania na temat ALLOWED jest to, że w pełni trwałe transakcje mogą wymagać dłuższego oczekiwania, ponieważ najpierw wymuszą opróżnienie wszelkich opóźnionych trwałych transakcji.
Na poziomie transakcji możesz powiedzieć:
COMMIT TRANSACTION WITH (DELAYED_DURABILITY = ON);
A w natywnie skompilowanej procedurze OLTP w pamięci można dodać następującą opcję do BEGIN ATOMIC blok:
BEGIN ATOMIC WITH (DELAYED_DURABILITY = ON, ...)
Częste pytanie dotyczy tego, co dzieje się z semantyką blokowania i izolacji. Tak naprawdę nic się nie zmienia. Blokowanie i blokowanie nadal ma miejsce, a transakcje są zatwierdzane w ten sam sposób i na tych samych zasadach. Jedyna różnica polega na tym, że pozwalając na wykonanie zatwierdzenia bez oczekiwania na opróżnienie dziennika na dysk, wszelkie powiązane blokady są zwalniane znacznie wcześniej.
Kiedy należy go używać
Oprócz korzyści wynikających z umożliwienia kontynuacji transakcji bez oczekiwania na zapis dziennika, uzyskujesz również mniej zapisów dziennika o większych rozmiarach. Może to działać bardzo dobrze, jeśli twój system ma wysoki odsetek transakcji, które są w rzeczywistości mniejsze niż 60 KB, a zwłaszcza gdy dysk dziennika jest wolny (chociaż znalazłem podobne korzyści na dysku SSD i tradycyjnym dysku twardym). To nie działa tak dobrze, jeśli twoje transakcje są w większości większe niż 60 KB, jeśli zazwyczaj są długotrwałe lub jeśli masz wysoką przepustowość i wysoką współbieżność. To, co może się tutaj zdarzyć, to to, że możesz wypełnić cały bufor dziennika przed zakończeniem opróżniania, co oznacza po prostu przeniesienie swoich oczekiwań do innego zasobu i ostatecznie nie poprawianie postrzeganej wydajności przez użytkowników aplikacji.
Innymi słowy, jeśli Twój dziennik transakcji nie jest obecnie wąskim gardłem, nie włączaj tej funkcji. Jak możesz stwierdzić, czy Twój dziennik transakcji jest obecnie wąskim gardłem? Pierwszy wskaźnik byłby wysoki WRITELOG czeka, szczególnie w połączeniu z PAGEIOLATCH_** . Paul Randal (@PaulRandal) ma świetną czteroczęściową serię poświęconą identyfikowaniu problemów z dziennikiem transakcji, a także konfigurowaniu pod kątem optymalnej wydajności:
- Przycinanie tłuszczu dziennika transakcji
- Przycinanie większej ilości tłuszczu w dzienniku transakcji
- Problemy z konfiguracją dziennika transakcji
- Monitorowanie dziennika transakcji
Zobacz także ten wpis na blogu autorstwa Kimberly Tripp (@KimberlyLTripp), 8 kroków do lepszej przepustowości dziennika transakcji oraz wpis na blogu zespołu SQL CAT Diagnosing Transaction Log Issues and Limits of the Log Manager.
To badanie może prowadzić do wniosku, że warto przyjrzeć się opóźnionej trwałości; może nie. Testowanie obciążenia będzie najbardziej niezawodnym sposobem, aby wiedzieć na pewno. Podobnie jak wiele innych dodatków w ostatnich wersjach SQL Server (*cough* Hekaton ), ta funkcja NIE jest przeznaczona do poprawy każdego pojedynczego obciążenia — i jak wspomniano powyżej, może faktycznie pogorszyć niektóre obciążenia. Zobacz ten wpis na blogu autorstwa Simona Harveya, aby poznać inne pytania, które powinieneś zadać sobie na temat obciążenia, aby określić, czy można poświęcić trochę trwałości, aby uzyskać lepszą wydajność.
Możliwość utraty danych
Wspomnę o tym kilka razy i za każdym razem będę podkreślał:Musisz być tolerancyjny na utratę danych . W przypadku dobrze działającego dysku maksymalna strata, jakiej można się spodziewać w przypadku katastrofy – lub nawet planowanego i pełnego wdzięku wyłączenia – wynosi do jednego pełnego bloku (60 KB). Jednak w przypadku, gdy podsystem we/wy nie nadąża, możliwe jest, że stracisz nawet cały bufor dziennika (~7 MB).
Aby wyjaśnić, z dokumentacji (podkreślenie moje):
W przypadku opóźnionej trwałości nie ma różnicy między nieoczekiwanym zamknięciem a oczekiwanym zamknięciem/ponowne uruchomieniem programu SQL Server . Podobnie jak w przypadku katastrof, należy zaplanować utratę danych . W planowanym zamknięciu/restartowaniu niektóre transakcje, które nie zostały zapisane na dysku, mogą być najpierw zapisane na dysku, ale nie należy tego planować. Planuj tak, jakby wyłączenie/ponowne uruchomienie, zaplanowane lub nieplanowane, spowodowało utratę danych tak samo, jak w przypadku katastrofy.Dlatego bardzo ważne jest, aby rozważyć ryzyko utraty danych z potrzebą złagodzenia problemów z wydajnością dziennika transakcji. Jeśli prowadzisz bank lub cokolwiek, co ma do czynienia z pieniędzmi, może być o wiele bezpieczniejsze i bardziej odpowiednie dla ciebie, aby przenieść swój dziennik na szybszy dysk niż rzucać kostką za pomocą tej funkcji. Jeśli próbujesz poprawić czas odpowiedzi w aplikacji Web Gamerz Chat Room, być może ryzyko jest mniej poważne.
Możesz do pewnego stopnia kontrolować to zachowanie, aby zminimalizować ryzyko utraty danych. Możesz wymusić opróżnienie wszystkich opóźnionych trwałych transakcji na dysk na jeden z dwóch sposobów:
- Zatwierdź każdą w pełni trwałą transakcję.
- Zadzwoń do
sys.sp_flush_logręcznie.
Pozwala to na powrót do kontrolowania utraty danych pod względem czasu, a nie rozmiaru; możesz na przykład zaplanować spłukiwanie co 5 sekund. Ale będziesz chciał znaleźć tutaj swoje ulubione miejsce; zbyt częste spłukiwanie może przede wszystkim zrównoważyć korzyść opóźnionej trwałości. W każdym razie nadal musisz być odporny na utratę danych , nawet jeśli jest wart tylko
Można by pomyśleć, że CHECKPOINT może tu pomóc, ale ta operacja właściwie nie gwarantuje technicznie, że dziennik zostanie opróżniony na dysk.
Interakcja z HA/DR
Być może zastanawiasz się, jak funkcja opóźnionej trwałości działa z funkcjami HA/DR, takimi jak wysyłanie dzienników, replikacja i grupy dostępności. W przypadku większości z nich działa to bez zmian. Wysyłanie i replikacja dziennika będzie odtwarzać rekordy dziennika, które zostały wzmocnione, więc istnieje tam taki sam potencjał utraty danych. W przypadku AG w trybie asynchronicznym i tak nie czekamy na potwierdzenie pomocnicze, więc będzie ono zachowywać się tak samo jak dzisiaj. Jednak w przypadku synchronous nie możemy zatwierdzić na podstawowym, dopóki transakcja nie zostanie zatwierdzona i zabezpieczona w zdalnym dzienniku. Nawet w tym scenariuszu możemy mieć pewne korzyści lokalnie, ponieważ nie musimy czekać na zapis lokalnego dziennika, nadal musimy czekać na zdalną aktywność. Tak więc w tym scenariuszu korzyści są mniejsze, a potencjalnie żadne; z wyjątkiem być może rzadkiego scenariusza, w którym dysk dziennika podstawowego jest naprawdę wolny, a dysk dziennika dodatkowego jest naprawdę szybki. Podejrzewam, że te same warunki obowiązują w przypadku kopii lustrzanej synchronizacji/asynchronicznej, ale nie otrzymasz ode mnie żadnego oficjalnego oświadczenia, jak działa nowa, błyszcząca funkcja z przestarzałą. :-)
Obserwacje wydajności
Nie byłby to zbyt duży post, gdybym nie pokazał pewnych rzeczywistych obserwacji wydajności. Skonfigurowałem 8 baz danych, aby przetestować efekty dwóch różnych wzorców obciążenia z następującymi atrybutami:
- Model odzyskiwania:prosty vs. pełny
- Lokalizacja dziennika:SSD vs. HDD
- Trwałość:opóźniona vs. w pełni trwała
Jestem naprawdę, naprawdę, naprawdę leniwy skuteczny w tego typu sprawach. Ponieważ chcę uniknąć powtarzania tych samych operacji w każdej bazie danych, tymczasowo utworzyłem poniższą tabelę w model :
USE model; GO CREATE TABLE dbo.TheTable ( TheID INT IDENTITY(1,1) PRIMARY KEY, TheDate DATETIME NOT NULL DEFAULT CURRENT_TIMESTAMP, RowGuid UNIQUEIDENTIFIER NOT NULL DEFAULT NEWID() );
Następnie zbudowałem zestaw dynamicznych poleceń SQL, aby zbudować te 8 baz danych, zamiast tworzyć bazy danych pojedynczo, a potem zamieniać ustawienia:
-- C and D are SSD, G is HDD
DECLARE @sql NVARCHAR(MAX) = N'';
;WITH l AS (SELECT l FROM (VALUES('D'),('G')) AS l(l)),
r AS (SELECT r FROM (VALUES('FULL'),('SIMPLE')) AS r(r)),
d AS (SELECT d FROM (VALUES('FORCED'),('DISABLED')) AS d(d)),
x AS (SELECT l.l, r.r, d.d, n = CONVERT(CHAR(1),ROW_NUMBER() OVER
(ORDER BY d.d DESC, l.l)) FROM l CROSS JOIN r CROSS JOIN d)
SELECT @sql += N'
CREATE DATABASE dd' + n + ' ON '
+ '(name = ''dd' + n + '_data'','
+ ' filename = ''C:\SQLData\dd' + n + '.mdf'', size = 1024MB)
LOG ON (name = ''dd' + n + '_log'','
+ ' filename = ''' + l + ':\SQLLog\dd' + n + '.ldf'', size = 1024MB);
ALTER DATABASE dd' + n + ' SET RECOVERY ' + r + ';
ALTER DATABASE dd' + n + ' SET DELAYED_DURABILITY = ' + d + ';'
FROM x ORDER BY d, l;
PRINT @sql;
-- EXEC sp_executesql @sql;
Możesz samodzielnie uruchomić ten kod (za pomocą EXEC nadal skomentowano), aby zobaczyć, że utworzy to 4 bazy danych z funkcją Delayed Durability OFF (dwie w trybie pełnego odzyskiwania, dwie w trybie SIMPLE, po jednej z logowaniem na wolnym dysku i jedna z logowaniem na dysk SSD). Powtórz ten wzorzec dla 4 baz danych z Delayed Durability FORCED – zrobiłem to, aby uprościć kod w teście, zamiast odzwierciedlać to, co zrobiłbym w prawdziwym życiu (gdzie prawdopodobnie chciałbym traktować niektóre transakcje jako krytyczne, a niektóre jako, cóż, mniej niż krytyczne).
W celu sprawdzenia poprawności uruchomiłem następujące zapytanie, aby upewnić się, że bazy danych mają odpowiednią macierz atrybutów:
SELECT d.name, d.recovery_model_desc, d.delayed_durability_desc, log_disk = CASE WHEN mf.physical_name LIKE N'D%' THEN 'SSD' else 'HDD' END FROM sys.databases AS d INNER JOIN sys.master_files AS mf ON d.database_id = mf.database_id WHERE d.name LIKE N'dd[1-8]' AND mf.[type] = 1; -- log
Wyniki:
| nazwa | model_odzyskiwania | delayed_durability | log_disk |
|---|---|---|---|
| dd1 | PEŁNE | WYMUSZONE | SSD |
| dd2 | PROSTE | WYMUSZONE | SSD |
| dd3 | PEŁNE | WYMUSZONE | Dysk twardy |
| dd4 | PROSTE | WYMUSZONE | Dysk twardy |
| dd5 | PEŁNE | WYŁĄCZONE | SSD |
| dd6 | PROSTE | WYŁĄCZONE | SSD |
| dd7 | PEŁNE | WYŁĄCZONE | Dysk twardy |
| dd8 | PROSTE | WYŁĄCZONE | Dysk twardy |
Odpowiednia konfiguracja 8 testowych baz danych
Przeprowadziłem również test kilka razy, aby upewnić się, że plik danych o pojemności 1 GB i plik dziennika o rozmiarze 1 GB wystarczy do uruchomienia całego zestawu obciążeń bez wprowadzania do równania żadnych zdarzeń autowzrostu. W ramach najlepszej praktyki rutynowo robię wszystko, aby zapewnić systemom klientów wystarczającą ilość przydzielonego miejsca (i wbudowane odpowiednie alerty), aby żadne zdarzenie wzrostu nigdy nie wystąpiło w nieoczekiwanym czasie. Wiem, że w prawdziwym świecie nie zawsze tak się dzieje, ale jest to idealne rozwiązanie.
Skonfigurowałem system do monitorowania za pomocą SQL Sentry – dzięki temu mogłem łatwo pokazać większość wskaźników wydajności, które chciałem wyróżnić. Ale stworzyłem również tymczasową tabelę do przechowywania metryk partii, w tym czasu trwania i bardzo konkretnych danych wyjściowych z sys.dm_io_virtual_file_stats:
SELECT test = 1, cycle = 1, start_time = GETDATE(), *
INTO #Metrics
FROM sys.dm_io_virtual_file_stats(DB_ID('dd1'), 2) WHERE 1 = 0; To pozwoliłoby mi zarejestrować czas rozpoczęcia i zakończenia każdej pojedynczej partii oraz zmierzyć delty w DMV między czasem rozpoczęcia a czasem zakończenia (w tym przypadku wiarygodne, ponieważ wiem, że jestem jedynym użytkownikiem w systemie).
Wiele małych transakcji
Pierwszym testem, który chciałem wykonać, było wiele małych transakcji. W przypadku każdej bazy danych chciałem uzyskać 500 000 oddzielnych partii, z których każda zawierała jedną wstawkę:
INSERT #Metrics SELECT 1, 1, GETDATE(), *
FROM sys.dm_io_virtual_file_stats(DB_ID('dd1'), 2);
GO
INSERT dbo.TheTable DEFAULT VALUES;
GO 500000
INSERT #Metrics SELECT 1, 2, GETDATE(), *
FROM sys.dm_io_virtual_file_stats(DB_ID('dd1'), 2);
Pamiętaj, staram się być leniwy skuteczny w tego typu sprawach. Aby wygenerować kod dla wszystkich 8 baz danych, uruchomiłem to:
;WITH x AS
(
SELECT TOP (8) number FROM master..spt_values
WHERE type = N'P' ORDER BY number
)
SELECT CONVERT(NVARCHAR(MAX), N'') + N'
INSERT #Metrics SELECT 1, 1, GETDATE(), *
FROM sys.dm_io_virtual_file_stats(DB_ID(''dd' + RTRIM(number+1) + '''), 2);
GO
INSERT dbo.TheTable DEFAULT VALUES;
GO 500000
INSERT #Metrics SELECT 1, 2, GETDATE(), *
FROM sys.dm_io_virtual_file_stats(DB_ID(''dd' + RTRIM(number+1) + '''), 2);'
FROM x;
Przeprowadziłem ten test, a następnie spojrzałem na #Metrics tabela z następującym zapytaniem:
SELECT
[database] = db_name(m1.database_id),
num_writes = m2.num_of_writes - m1.num_of_writes,
write_bytes = m2.num_of_bytes_written - m1.num_of_bytes_written,
bytes_per_write = (m2.num_of_bytes_written - m1.num_of_bytes_written)*1.0
/(m2.num_of_writes - m1.num_of_writes),
io_stall_ms = m2.io_stall_write_ms - m1.io_stall_write_ms,
m1.start_time,
end_time = m2.start_time,
duration = DATEDIFF(SECOND, m1.start_time, m2.start_time)
FROM #Metrics AS m1
INNER JOIN #Metrics AS m2
ON m1.database_id = m2.database_id
WHERE m1.cycle = 1 AND m2.cycle = 2
AND m1.test = 1 AND m2.test = 1; Dało to następujące wyniki (i potwierdziłem w wielu testach, że wyniki były spójne):
| baza danych | pisze | bajty | bajty/zapis | io_stall_ms | czas_rozpoczęcia | end_time | czas trwania (sekundy) |
|---|---|---|---|---|---|---|---|
| dd1 | 8068 | 261,894,656 | 32 460,91 | 6232 | 26-04-2014 17:20:00 | 2014-04-26 17:21:08 | 68 |
| dd2 | 8072 | 2616826888 | 32 418,56 | 2740 | 2014-04-26 17:21:08 | 2014-04-26 17:22:16 | 68 |
| dd3 | 8246 | 262 254592 | 31 803,85 | 3996 | 2014-04-26 17:22:16 | 2014-04-26 17:23:24 | 68 |
| dd4 | 8055 | 261.688.320 | 32 487,68 | 4231 | 2014-04-26 17:23:24 | 2014-04-26 17:24:32 | 68 |
| dd5 | 500 012 | 526.448.640 | 1052,87 | 35 593 | 2014-04-26 17:24:32 | 2014-04-26 17:26:32 | 120 |
| dd6 | 500,014 | 525 870 080 | 1051,71 | 35 435 | 2014-04-26 17:26:32 | 2014-04-26 17:28:31 | 119 |
| dd7 | 500 015 | 526 120 448 | 1.052.20 | 50 857 | 2014-04-26 17:28:31 | 26-04-2014 17:30:45 | 134 |
| dd8 | 500 017 | 525 886 976 | 1051,73 | 49 680 | 133 |
Małe transakcje:czas trwania i wyniki z sys.dm_io_virtual_file_stats
Na pewno kilka ciekawych spostrzeżeń:
- Liczba pojedynczych operacji zapisu była bardzo mała w przypadku baz danych opóźnionej trwałości (~60X w przypadku tradycyjnych).
- Całkowita liczba zapisanych bajtów została zmniejszona o połowę przy użyciu opóźnionej trwałości (przypuszczam, że wszystkie zapisy w tradycyjnym przypadku zawierały dużo zmarnowanego miejsca).
- Liczba bajtów na zapis była znacznie wyższa w przypadku opóźnionej trwałości. Nie było to zbyt zaskakujące, ponieważ głównym celem tej funkcji jest łączenie zapisów w większe partie.
- Całkowity czas trwania przestojów we/wy był niestabilny, ale mniej więcej o rząd wielkości niższy w przypadku opóźnionej trwałości. Stragany w przypadku w pełni trwałych transakcji były znacznie bardziej wrażliwe na rodzaj dysku.
- Jeśli coś Cię dotychczas nie przekonało, kolumna czasu trwania jest bardzo wymowna. W pełni trwałe partie, które trwają dwie minuty lub dłużej, są cięte prawie o połowę.
Kolumny czasu rozpoczęcia/zakończenia pozwoliły mi skupić się na panelu Performance Advisor dokładnie w okresie, w którym miały miejsce te transakcje, gdzie możemy narysować wiele dodatkowych wskaźników wizualnych:
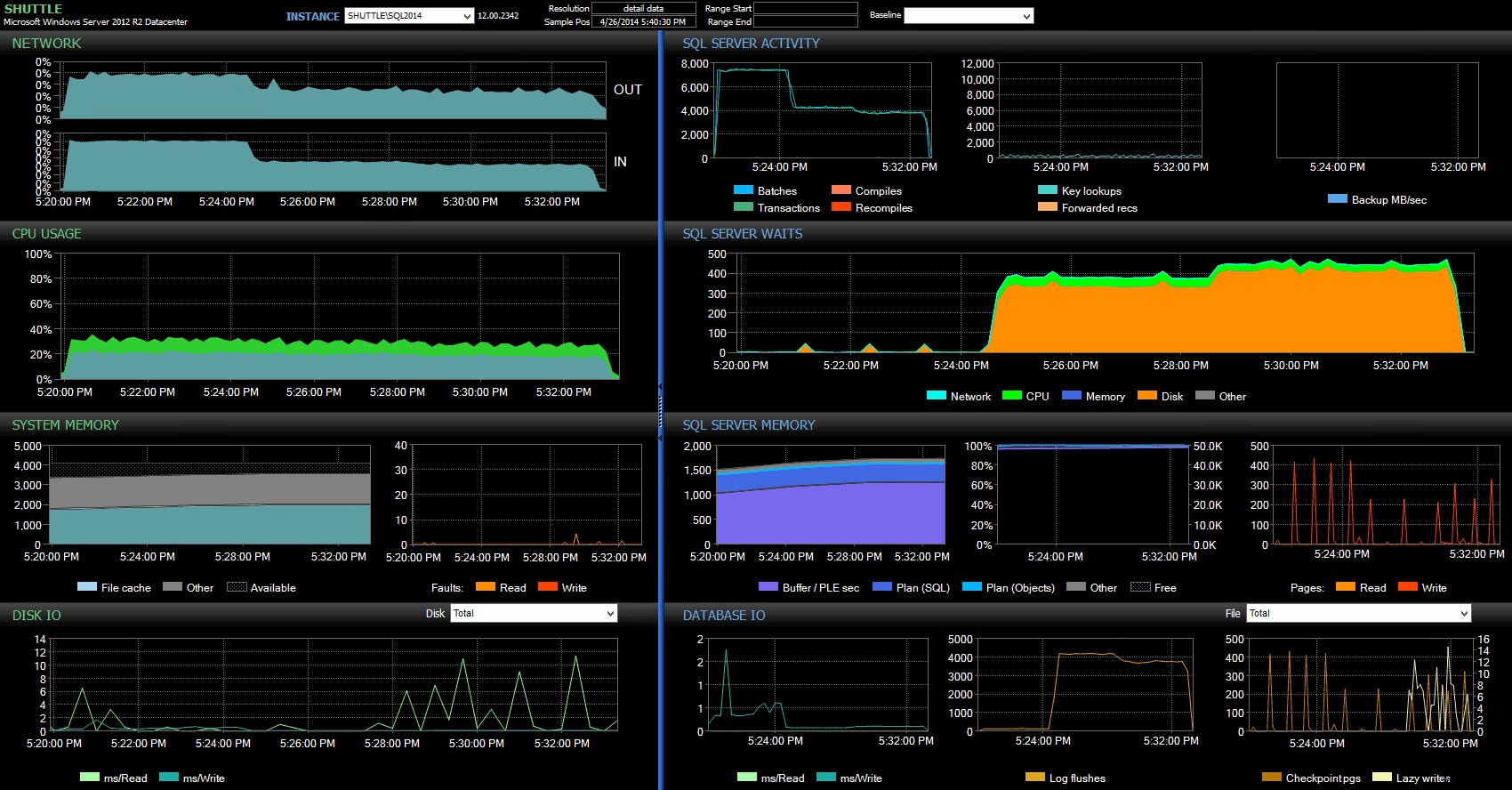
Panel SQL Sentry – kliknij, aby powiększyć
Dalsze obserwacje tutaj:
- Na kilku wykresach można wyraźnie zobaczyć, kiedy przejęła część partii nie opóźniona trwałości (~17:24:32).
- Nie ma zauważalnego wpływu na procesor ani pamięć podczas korzystania z opóźnionej trwałości.
- Możesz zobaczyć ogromny wpływ na partie/transakcje na sekundę na pierwszym wykresie w sekcji Aktywność serwera SQL.
- Program SQL Server czeka na rozpoczęcie w pełni trwałych transakcji. Składały się one prawie wyłącznie z
WRITELOGczeka, z niewielką liczbąPAGEIOLOATCH_EXiPAGEIOLATCH_UPczeka na dobrą miarę. - Całkowita liczba opróżnień dziennika podczas operacji opóźnionej trwałości była dość niewielka (niskie 100 s/s), podczas gdy w przypadku tradycyjnego zachowania liczba ta wzrosła do ponad 4000/s (i nieco niższa w przypadku testu dysku twardego).
Mniej, większe transakcje
W następnym teście chciałem zobaczyć, co by się stało, gdybyśmy wykonali mniej operacji, ale upewniłem się, że każda instrukcja wpływa na większą ilość danych. Chciałem, aby ta partia działała w każdej bazie danych:
CREATE TABLE dbo.Rnd
(
batch TINYINT,
TheID INT
);
INSERT dbo.Rnd SELECT TOP (1000) 1, TheID FROM dbo.TheTable ORDER BY NEWID();
INSERT dbo.Rnd SELECT TOP (10) 2, TheID FROM dbo.TheTable ORDER BY NEWID();
INSERT dbo.Rnd SELECT TOP (300) 3, TheID FROM dbo.TheTable ORDER BY NEWID();
GO
INSERT #Metrics SELECT 1, GETDATE(), *
FROM sys.dm_io_virtual_file_stats(DB_ID('dd1'), 2);
GO
UPDATE t SET TheDate = DATEADD(MINUTE, 1, TheDate)
FROM dbo.TheTable AS t
INNER JOIN dbo.Rnd AS r
ON t.TheID = r.TheID
WHERE r.batch = 1;
GO 10000
UPDATE t SET RowGuid = NEWID()
FROM dbo.TheTable AS t
INNER JOIN dbo.Rnd AS r
ON t.TheID = r.TheID
WHERE r.batch = 2;
GO 10000
DELETE dbo.TheTable WHERE TheID IN (SELECT TheID FROM dbo.Rnd WHERE batch = 3);
DELETE dbo.TheTable WHERE TheID IN (SELECT TheID+1 FROM dbo.Rnd WHERE batch = 3);
DELETE dbo.TheTable WHERE TheID IN (SELECT TheID-1 FROM dbo.Rnd WHERE batch = 3);
GO
INSERT #Metrics SELECT 2, GETDATE(), *
FROM sys.dm_io_virtual_file_stats(DB_ID('dd1'), 2); Więc ponownie użyłem leniwej metody, aby utworzyć 8 kopii tego skryptu, po jednej na bazę danych:
;WITH x AS (SELECT TOP (8) number FROM master..spt_values WHERE type = N'P' ORDER BY number)
SELECT N'
USE dd' + RTRIM(Number+1) + ';
GO
CREATE TABLE dbo.Rnd
(
batch TINYINT,
TheID INT
);
INSERT dbo.Rnd SELECT TOP (1000) 1, TheID FROM dbo.TheTable ORDER BY NEWID();
INSERT dbo.Rnd SELECT TOP (10) 2, TheID FROM dbo.TheTable ORDER BY NEWID();
INSERT dbo.Rnd SELECT TOP (300) 3, TheID FROM dbo.TheTable ORDER BY NEWID();
GO
INSERT #Metrics SELECT 2, 1, GETDATE(), *
FROM sys.dm_io_virtual_file_stats(DB_ID(''dd' + RTRIM(number+1) + ''', 2);
GO
UPDATE t SET TheDate = DATEADD(MINUTE, 1, TheDate)
FROM dbo.TheTable AS t
INNER JOIN dbo.rnd AS r
ON t.TheID = r.TheID
WHERE r.cycle = 1;
GO 10000
UPDATE t SET RowGuid = NEWID()
FROM dbo.TheTable AS t
INNER JOIN dbo.rnd AS r
ON t.TheID = r.TheID
WHERE r.cycle = 2;
GO 10000
DELETE dbo.TheTable WHERE TheID IN (SELECT TheID FROM dbo.rnd WHERE cycle = 3);
DELETE dbo.TheTable WHERE TheID IN (SELECT TheID+1 FROM dbo.rnd WHERE cycle = 3);
DELETE dbo.TheTable WHERE TheID IN (SELECT TheID-1 FROM dbo.rnd WHERE cycle = 3);
GO
INSERT #Metrics SELECT 2, 2, GETDATE(), *
FROM sys.dm_io_virtual_file_stats(DB_ID(''dd' + RTRIM(number+1) + '''), 2);'
FROM x;
Uruchomiłem tę partię, a następnie zmieniłem zapytanie na #Metrics powyżej, aby spojrzeć na drugi test zamiast pierwszego. Wyniki:
| baza danych | pisze | bajty | bajty/zapis | io_stall_ms | czas_rozpoczęcia | end_time | czas trwania (sekundy) |
|---|---|---|---|---|---|---|---|
| dd1 | 20 970 | 1271 911 936 | 60 653,88 | 12 577 | 2014-04-26 17:41:21 | 2014-04-26 17:43:46 | 145 |
| dd2 | 20 997 | 1.272.145,408 | 60 587,00 | 14 698 | 2014-04-26 17:43:46 | 2014-04-26 17:46:11 | 145 |
| dd3 | 20 973 | 1272982016 | 60 696,22 | 12 085 | 2014-04-26 17:46:11 | 2014-04-26 17:48:33 | 142 |
| dd4 | 20 958 | 1272064512 | 60 695,89 | 11 795 | 143 | ||
| dd5 | 30 138 | 12822231808 | 42 545,35 | 7402 | 2014-04-26 17:50:56 | 2014-04-26 17:53:23 | 147 |
| dd6 | 30 138 | 1282260992 | 42 546,31 | 7806 | 2014-04-26 17:53:23 | 2014-04-26 17:55:53 | 150 |
| dd7 | 30 129 | 1281575424 | 42 536,27 | 9888 | 2014-04-26 17:55:53 | 2014-04-26 17:58:25 | 152 |
| dd8 | 30 130 | 1281449472 | 42 530,68 | 11 452 | 2014-04-26 17:58:25 | 26-04-2014 18:00:55 | 150 |
Większe transakcje:czas trwania i wyniki z sys.dm_io_virtual_file_stats
Tym razem wpływ opóźnionej trwałości jest znacznie mniej zauważalny. Widzimy nieco mniejszą liczbę operacji zapisu, przy nieco większej liczbie bajtów na zapis, z całkowitą liczbą zapisanych bajtów prawie identyczną. W tym przypadku widzimy, że opóźnienia we/wy są wyższe w przypadku opóźnionej trwałości, co prawdopodobnie tłumaczy fakt, że czasy trwania również były prawie identyczne.
W panelu Performance Advisor mamy pewne podobieństwa z poprzednim testem, a także kilka wyraźnych różnic:
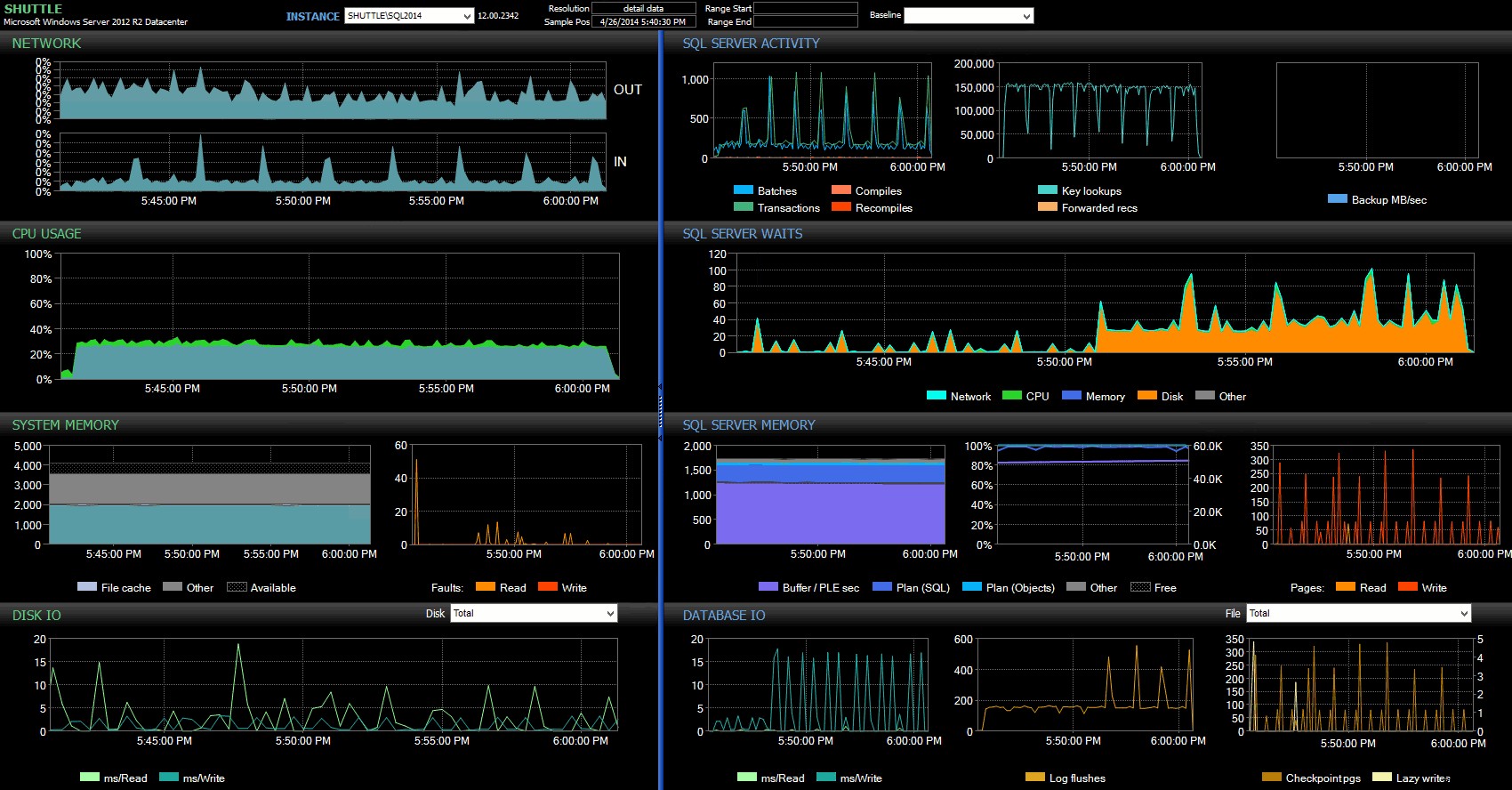
Panel SQL Sentry – kliknij, aby powiększyć
Jedną z dużych różnic, na które należy zwrócić uwagę, jest to, że delta w statystykach oczekiwania nie jest tak wyraźna, jak w poprzednim teście – nadal występuje znacznie wyższa częstotliwość WRITELOG czeka na w pełni trwałe partie, ale nie zbliża się do poziomów obserwowanych przy mniejszych transakcjach. Inną rzeczą, którą możesz natychmiast zauważyć, jest to, że wcześniej obserwowany wpływ na partie i transakcje na sekundę nie jest już obecny. I wreszcie, chociaż w przypadku w pełni trwałych transakcji występuje więcej opróżnień logów niż w przypadku opóźnień, ta rozbieżność jest znacznie mniej wyraźna niż w przypadku mniejszych transakcji.
Wniosek
Powinno być jasne, że istnieją pewne typy obciążeń, które mogą znacznie skorzystać na opóźnionej trwałości – oczywiście pod warunkiem, że masz tolerancję na utratę danych . Ta funkcja nie jest ograniczona do OLTP w pamięci, jest dostępna we wszystkich wersjach programu SQL Server 2014 i można ją zaimplementować z niewielkimi zmianami w kodzie lub bez nich. Z pewnością może to być potężna technika, jeśli Twoje obciążenie może ją obsłużyć. Ale znowu, będziesz musiał przetestować swoje obciążenie, aby mieć pewność, że skorzysta z tej funkcji, a także mocno zastanowić się, czy zwiększa to ryzyko utraty danych.
Nawiasem mówiąc, może się to wydawać tłumowi SQL Server nowym nowym pomysłem, ale w rzeczywistości Oracle wprowadziło to jako „Asynchronous Commit” w 2006 roku (patrz COMMIT WRITE ... NOWAIT zgodnie z dokumentacją tutaj i blogiem w 2007 r.). A sam pomysł istnieje od prawie 3 dekad; zobacz krótką kronikę Hala Berensona o jego historii.
Następnym razem
Jednym z pomysłów, który ominąłem, jest próba poprawy wydajności tempdb wymuszając tam Opóźnioną Trwałość. Jedna specjalna właściwość tempdb to sprawia, że jest tak kuszącym kandydatem, że jest z natury przemijający – wszystko w tempdb został zaprojektowany tak, aby można go było rzucać w wyniku szerokiej gamy zdarzeń systemowych. Mówię to teraz, nie mając pojęcia, czy istnieje kształt obciążenia pracą, w którym będzie to dobrze działać; ale planuję to wypróbować, a jeśli znajdę coś interesującego, możesz być pewien, że opublikuję o tym tutaj.