Znajomość replikacji jest koniecznością dla każdego zarządzającego bazami danych. Jest to temat, który prawdopodobnie widziałeś w kółko, ale nigdy się nie starzeje. W tym blogu przyjrzymy się trochę historii wbudowanych funkcji replikacji PostgreSQL i zagłębimy się w sposób, w jaki działa replikacja strumieniowa.
Mówiąc o replikacji, będziemy dużo mówić o warstwach WAL. Przyjrzyjmy się więc trochę dziennikom zapisu z wyprzedzeniem.
Dziennik zapisu z wyprzedzeniem (WAL)
Dziennik zapisu z wyprzedzeniem to standardowa metoda zapewniania integralności danych i jest domyślnie włączona automatycznie.
WAL to dzienniki REDO w PostgreSQL. Ale czym dokładnie są dzienniki REDO?
Dzienniki REDO zawierają wszystkie zmiany wprowadzone w bazie danych i są używane do replikacji, odzyskiwania, tworzenia kopii zapasowych online i odzyskiwania do punktu w czasie (PITR). Wszelkie zmiany, które nie zostały zastosowane na stronach danych, można ponownie wykonać w dziennikach REDO.
Korzystanie z WAL powoduje znaczne zmniejszenie liczby zapisów na dysku, ponieważ tylko plik dziennika musi zostać opróżniony na dysk, aby zagwarantować, że transakcja jest zatwierdzona, a nie każdy plik danych zmieniony przez transakcję.
Rekord WAL określi zmiany wprowadzone w danych, bit po bicie. Każdy rekord WAL zostanie dołączony do pliku WAL. Pozycja wstawiania to numer sekwencyjny dziennika (LSN), przesunięcie bajtów w dziennikach, zwiększające się z każdym nowym rekordem.
WAL są przechowywane w katalogu pg_wal (lub pg_xlog w wersjach PostgreSQL <10) w katalogu data. Pliki te mają domyślny rozmiar 16 MB (możesz zmienić rozmiar, zmieniając opcję konfiguracji --with-wal-segsize podczas budowania serwera). Mają unikalną nazwę przyrostową w następującym formacie:„00000001 00000000 00000000”.
Liczba plików WAL zawartych w pg_wal będzie zależeć od wartości przypisanej do parametru checkpoint_segments (lub min_wal_size i max_wal_size, w zależności od wersji) w pliku konfiguracyjnym postgresql.conf.
Jednym z parametrów, który należy ustawić podczas konfigurowania wszystkich instalacji PostgreSQL, jest wal_level. Wal_level określa, ile informacji jest zapisywanych w WAL. Wartość domyślna to minimalna, która zapisuje tylko informacje potrzebne do odzyskania systemu po awarii lub natychmiastowym zamknięciu. Archiwum dodaje rejestrowanie wymagane do archiwizacji WAL; hot_standby dodatkowo dodaje informacje potrzebne do uruchamiania zapytań tylko do odczytu na serwerze rezerwowym; logiczna dodaje informacje niezbędne do obsługi dekodowania logicznego. Ten parametr wymaga ponownego uruchomienia, więc może być trudno zmienić go w działających produkcyjnych bazach danych, jeśli o tym zapomnisz.
Więcej informacji można znaleźć w oficjalnej dokumentacji tutaj lub tutaj. Teraz, gdy omówiliśmy WAL, przejrzyjmy historię replikacji w PostgreSQL.
Historia replikacji w PostgreSQL
Pierwsza metoda replikacji (warm standby), którą zaimplementował PostgreSQL (wersja 8.2, w 2006 r.) była oparta na metodzie przesyłania dzienników.
Oznacza to, że rekordy WAL są bezpośrednio przenoszone z jednego serwera bazy danych na inny w celu zastosowania. Można powiedzieć, że jest to ciągły PITR.
PostgreSQL implementuje przesyłanie dziennika oparte na plikach, przesyłając rekordy WAL jeden plik (segment WAL) na raz.
Ta implementacja replikacji ma wadę:jeśli wystąpi poważna awaria na głównych serwerach, transakcje, które nie zostały jeszcze wysłane, zostaną utracone. Jest więc okno na utratę danych (możesz to dostroić za pomocą parametru archive_timeout, który można ustawić na zaledwie kilka sekund. Jednak tak niskie ustawienie znacznie zwiększy przepustowość wymaganą do wysyłki plików).
Możemy przedstawić tę opartą na plikach metodę wysyłki dzienników za pomocą poniższego obrazu:
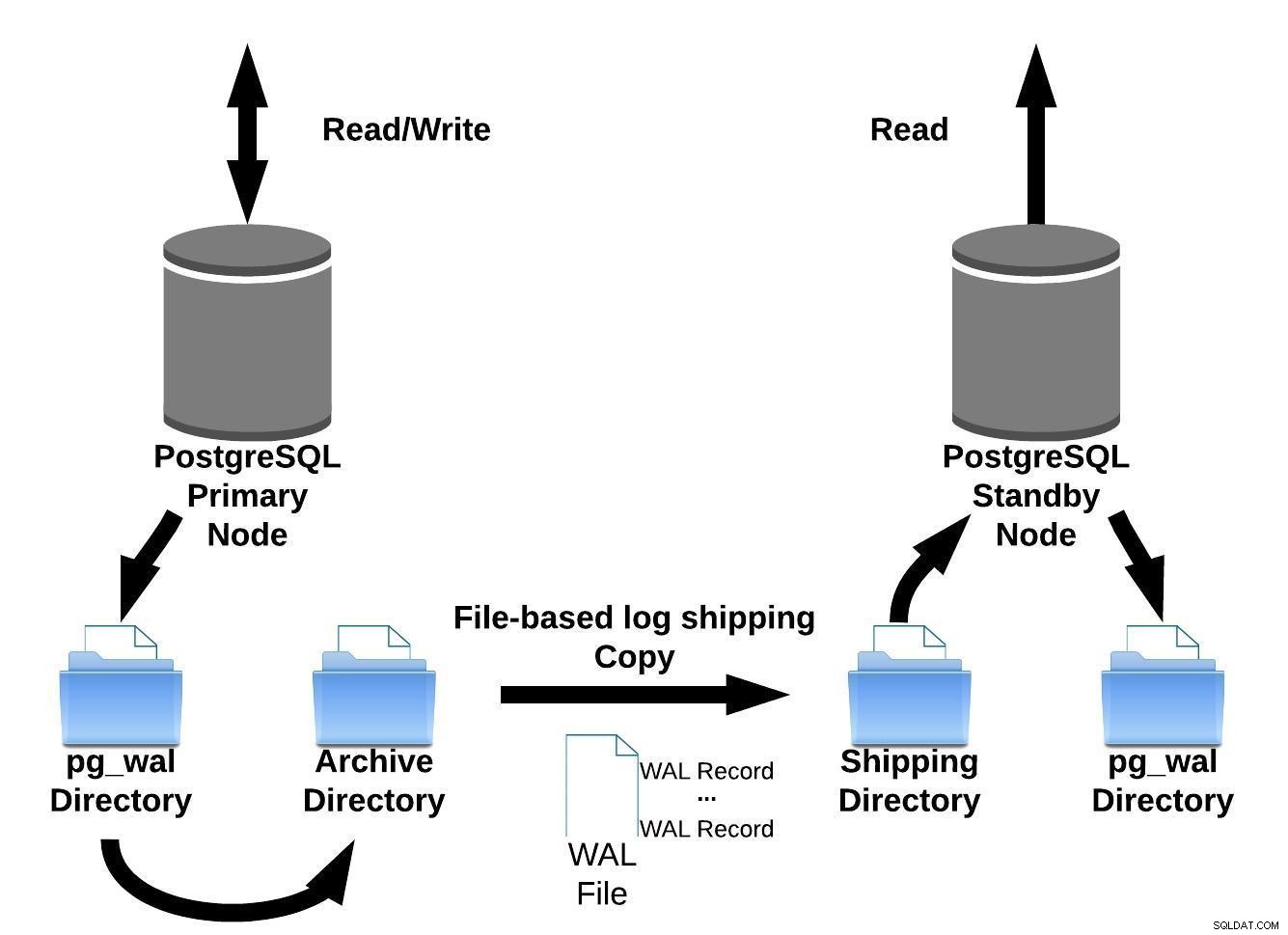 Wysyłka dziennika oparta na plikach PostgreSQL
Wysyłka dziennika oparta na plikach PostgreSQLNastępnie w wersji 9.0 (w 2010 r. ), wprowadzono replikację strumieniową.
Replikacja strumieniowa pozwala być na bieżąco, niż jest to możliwe w przypadku przesyłania dziennika opartego na plikach. Działa to poprzez przesyłanie rekordów WAL (plik WAL składa się z rekordów WAL) w locie (przesyłanie dzienników na podstawie rekordów) między serwerem głównym a jednym lub kilkoma serwerami rezerwowymi bez oczekiwania na wypełnienie pliku WAL.
W praktyce proces zwany odbiornikiem WAL, działający na serwerze rezerwowym, połączy się z serwerem głównym za pomocą połączenia TCP/IP. Na serwerze głównym istnieje inny proces o nazwie WAL sender, który odpowiada za wysyłanie rejestrów WAL do serwera rezerwowego w miarę ich występowania.
Poniższy diagram przedstawia replikację strumieniową:
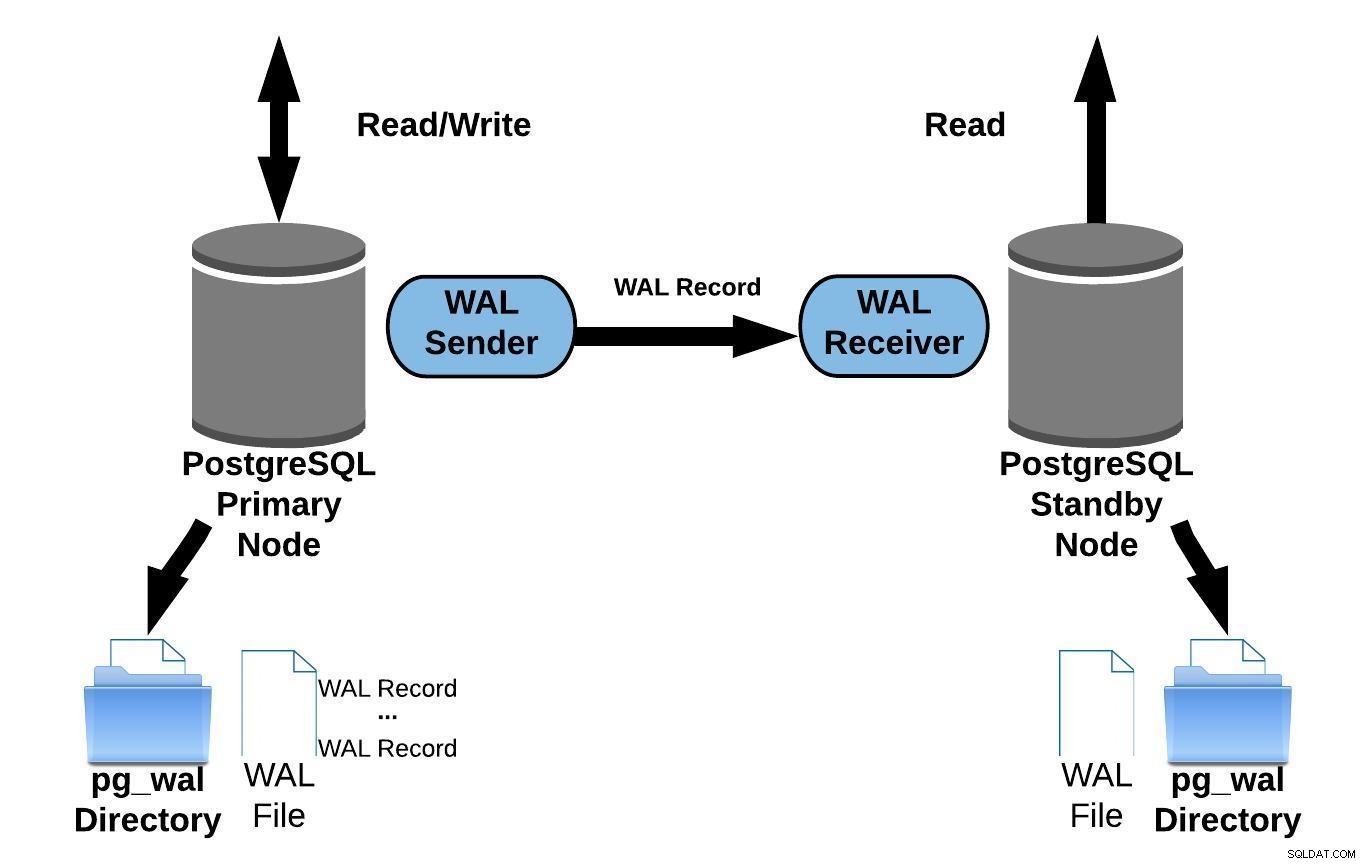 Replikacja PostgreSQL Streaming
Replikacja PostgreSQL StreamingPatrząc na powyższy diagram, możesz się zastanawiać, co się dzieje kiedy komunikacja między nadawcą WAL a odbiorcą WAL zawodzi?
Podczas konfigurowania replikacji strumieniowej masz możliwość włączenia archiwizacji WAL.
Ten krok nie jest obowiązkowy, ale jest niezwykle ważny dla niezawodnej konfiguracji replikacji. Niezbędne jest, aby serwer główny nie przetwarzał starych plików WAL, które nie zostały jeszcze zastosowane na serwerze rezerwowym. W takim przypadku konieczne będzie odtworzenie repliki od zera.
Konfigurując replikację z ciągłą archiwizacją, rozpoczyna się ona od kopii zapasowej. Aby osiągnąć stan synchronizacji z podstawowym, musi zastosować wszystkie zmiany hostowane w warstwie WAL, które nastąpiły po utworzeniu kopii zapasowej. Podczas tego procesu stan gotowości najpierw odtworzy wszystkie pliki WAL dostępne w lokalizacji archiwum (wywołując polecenie restore_command). Restore_command nie powiedzie się, gdy dotrze do ostatniego zarchiwizowanego rekordu WAL, więc po tym rezerwa będzie sprawdzać w katalogu pg_wal, czy istnieje tam zmiana (działa to, aby uniknąć utraty danych w przypadku awarii serwerów głównych i niektórych zmian, które zostały już przeniesione i zastosowane do repliki, nie zostały jeszcze zarchiwizowane).
Jeśli to się nie powiedzie, a żądany rekord tam nie istnieje, rozpocznie komunikację z serwerem głównym poprzez replikację strumieniową.
W przypadku niepowodzenia replikacji strumieniowej nastąpi powrót do kroku 1 i ponowne przywrócenie rekordów z archiwum. Ta pętla ponownych prób z archiwum, pg_wal i za pośrednictwem replikacji strumieniowej trwa do momentu zatrzymania serwera lub wyzwolenia przełączania awaryjnego przez plik wyzwalacza.
Poniższy diagram przedstawia konfigurację replikacji strumieniowej z ciągłą archiwizacją:
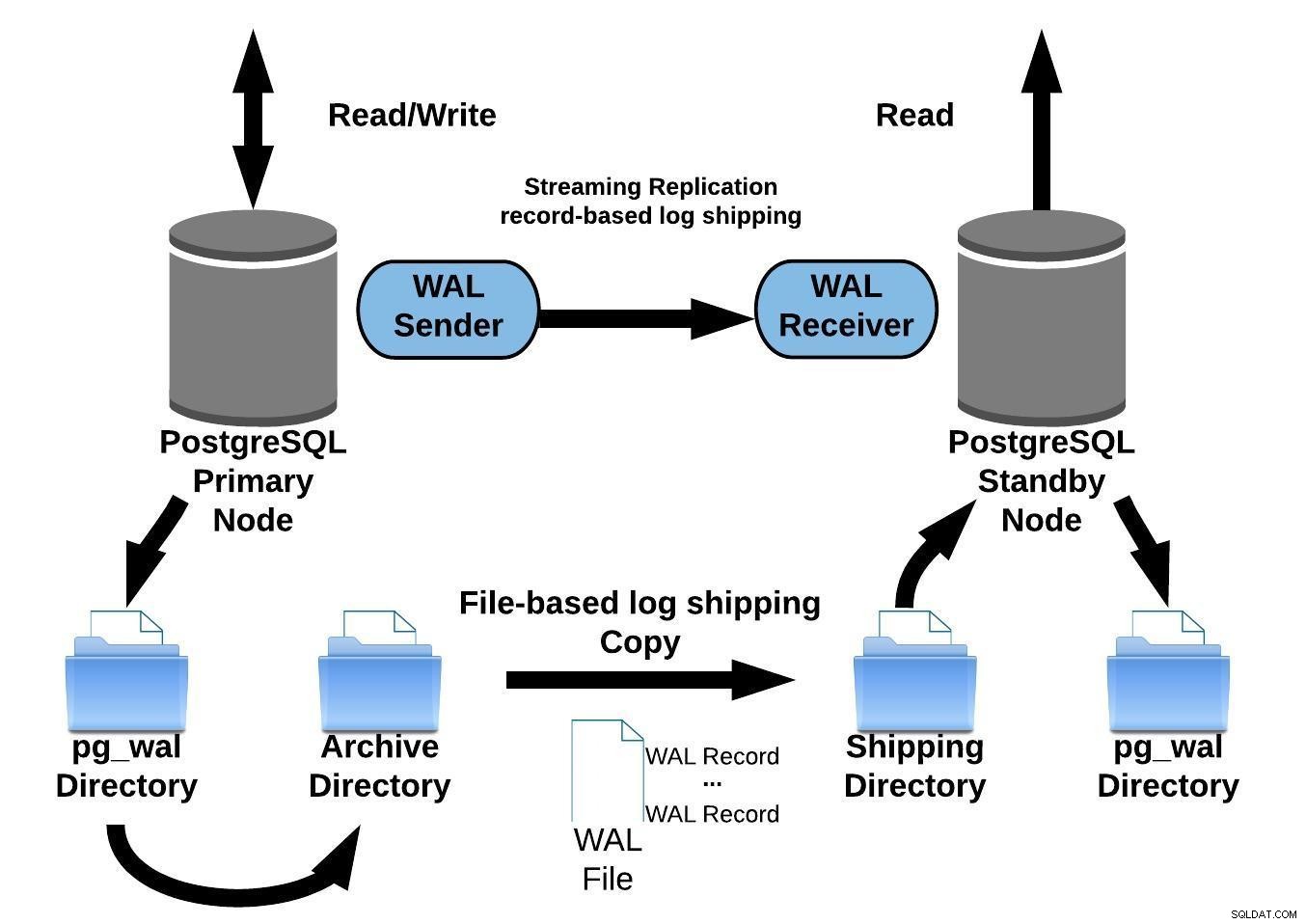 Replikacja strumieniowa PostgreSQL z ciągłą archiwizacją
Replikacja strumieniowa PostgreSQL z ciągłą archiwizacjąReplikacja strumieniowa jest domyślnie asynchroniczna, więc na w dowolnym momencie możesz mieć pewne transakcje, które mogą zostać zatwierdzone na serwerze głównym i jeszcze nie zreplikowane na serwer rezerwowy. Oznacza to potencjalną utratę danych.
Jednak to opóźnienie między zatwierdzeniem a wpływem zmian w replice ma być naprawdę małe (kilka milisekund), zakładając oczywiście, że serwer replik jest wystarczająco silny, aby nadążyć za ładunek.
W przypadkach, w których nawet ryzyko niewielkiej utraty danych jest niedopuszczalne, w wersji 9.1 wprowadzono funkcję replikacji synchronicznej.
W replikacji synchronicznej każde zatwierdzenie transakcji zapisu czeka na otrzymanie potwierdzenia, że zatwierdzenie zostało zapisane w dzienniku zapisu z wyprzedzeniem na dysku zarówno serwera podstawowego, jak i rezerwowego.
Ta metoda minimalizuje możliwość utraty danych; aby tak się stało, będziesz potrzebować jednocześnie awarii głównego i rezerwowego.
Oczywistą wadą tej konfiguracji jest to, że czas odpowiedzi dla każdej transakcji zapisu wzrasta, ponieważ musi czekać, aż wszystkie strony odpowiedzą. Tak więc czas na zatwierdzenie to co najmniej podróż w obie strony między pierwotną a repliką. Nie będzie to miało wpływu na transakcje tylko do odczytu.
Aby skonfigurować replikację synchroniczną, należy określić nazwę aplikacji w primary_conninfo odzyskiwania dla każdego pliku server.conf w trybie gotowości:primary_conninfo ='...nazwa_aplikacji=standbyX' .
Musisz także określić listę serwerów rezerwowych, które będą brać udział w replikacji synchronicznej:synchronous_standby_name ='standbyX,standbyY'.
Można skonfigurować jeden lub kilka serwerów synchronicznych, a ten parametr określa również, którą metodę (PIERWSZA i DOWOLNA) wybrać synchroniczne tryby gotowości spośród wymienionych. Więcej informacji na temat konfigurowania trybu replikacji synchronicznej można znaleźć w tym blogu. Możliwe jest również skonfigurowanie replikacji synchronicznej podczas wdrażania za pośrednictwem ClusterControl.
Po skonfigurowaniu replikacji i uruchomieniu, będziesz musiał wdrożyć monitorowanie
Monitorowanie replikacji PostgreSQL
Widok pg_stat_replication na serwerze głównym zawiera wiele istotnych informacji:
postgres=# SELECT * FROM pg_stat_replication;
-[ RECORD 1 ]----+------------------------------
pid | 756
usesysid | 16385
usename | cmon_replication
application_name | pgsql_0_node_0
client_addr | 10.10.10.137
client_hostname |
client_port | 36684
backend_start | 2022-04-13 17:45:56.517518+00
backend_xmin |
state | streaming
sent_lsn | 0/400001C0
write_lsn | 0/400001C0
flush_lsn | 0/400001C0
replay_lsn | 0/400001C0
write_lag |
flush_lag |
replay_lag |
sync_priority | 0
sync_state | async
reply_time | 2022-04-13 17:53:03.454864+00Zobaczmy to szczegółowo:
-
pid:Identyfikator procesu walsendera.
-
usesysid:OID użytkownika używany do replikacji strumieniowej.
-
username:Nazwa użytkownika używana do replikacji strumieniowej.
-
application_name:Nazwa aplikacji połączona z masterem.
-
client_addr:Adres replikacji w trybie gotowości/strumieniowej.
-
nazwa_hosta_klienta:nazwa hosta w trybie gotowości.
-
client_port:numer portu TCP, na którym tryb gotowości komunikuje się z nadawcą WAL.
-
backend_start:Czas rozpoczęcia, gdy SR jest połączony z głównym.
-
stan:Bieżący stan nadawcy WAL, np. przesyłanie strumieniowe.
-
sent_lsn:Ostatnia lokalizacja transakcji wysłana do trybu gotowości.
-
write_lsn:Ostatnia transakcja zapisana na dysku w trybie gotowości.
-
flush_lsn:Ostatnia transakcja opróżniona na dysku w trybie gotowości.
-
replay_lsn:Ostatnia transakcja opróżniona na dysku w trybie gotowości.
-
sync_priority:Priorytet serwera rezerwowego wybrany jako synchroniczny tryb gotowości.
-
sync_state:Synchronizacja stanu gotowości (czy jest asynchroniczna, czy synchroniczna).
Możesz również zobaczyć procesy nadawcy/odbiorcy WAL działające na serwerach.
Nadawca (węzeł główny):
[example@sqldat.com ~]# ps aux |grep postgres
postgres 727 0.0 2.2 917060 47936 ? Ss 17:45 0:00 /usr/pgsql-14/bin/postmaster -D /var/lib/pgsql/14/data/
postgres 732 0.0 0.2 351904 5280 ? Ss 17:45 0:00 postgres: 14/main: logger
postgres 734 0.0 0.5 917188 10560 ? Ss 17:45 0:00 postgres: 14/main: checkpointer
postgres 735 0.0 0.4 917208 9908 ? Ss 17:45 0:00 postgres: 14/main: background writer
postgres 736 0.0 1.0 917060 22928 ? Ss 17:45 0:00 postgres: 14/main: walwriter
postgres 737 0.0 0.4 917748 9128 ? Ss 17:45 0:00 postgres: 14/main: autovacuum launcher
postgres 738 0.0 0.3 917060 6320 ? Ss 17:45 0:00 postgres: 14/main: archiver last was 00000001000000000000003F
postgres 739 0.0 0.2 354160 5340 ? Ss 17:45 0:00 postgres: 14/main: stats collector
postgres 740 0.0 0.3 917632 6892 ? Ss 17:45 0:00 postgres: 14/main: logical replication launcher
postgres 756 0.0 0.6 918252 13124 ? Ss 17:45 0:00 postgres: 14/main: walsender cmon_replication 10.10.10.137(36684) streaming 0/400001C0Odbiornik (węzeł czuwania):
[example@sqldat.com ~]# ps aux |grep postgres
postgres 727 0.0 2.2 917060 47576 ? Ss 17:45 0:00 /usr/pgsql-14/bin/postmaster -D /var/lib/pgsql/14/data/
postgres 732 0.0 0.2 351904 5396 ? Ss 17:45 0:00 postgres: 14/main: logger
postgres 733 0.0 0.3 917196 6360 ? Ss 17:45 0:00 postgres: 14/main: startup recovering 000000010000000000000040
postgres 734 0.0 0.4 917060 10056 ? Ss 17:45 0:00 postgres: 14/main: checkpointer
postgres 735 0.0 0.3 917060 6304 ? Ss 17:45 0:00 postgres: 14/main: background writer
postgres 736 0.0 0.2 354160 5456 ? Ss 17:45 0:00 postgres: 14/main: stats collector
postgres 737 0.0 0.6 924532 12948 ? Ss 17:45 0:00 postgres: 14/main: walreceiver streaming 0/400001C0Jednym ze sposobów sprawdzenia aktualności replikacji jest sprawdzenie ilości rekordów WAL wygenerowanych na serwerze głównym, ale jeszcze nie zastosowanych na serwerze rezerwowym.
Główny:
postgres=# SELECT pg_current_wal_lsn();
pg_current_wal_lsn
--------------------
0/400001C0
(1 row)Tryb gotowości:
postgres=# SELECT pg_last_wal_receive_lsn();
pg_last_wal_receive_lsn
-------------------------
0/400001C0
(1 row)
postgres=# SELECT pg_last_wal_replay_lsn();
pg_last_wal_replay_lsn
------------------------
0/400001C0
(1 row)Możesz użyć następującego zapytania w węźle gotowości, aby uzyskać opóźnienie w ciągu kilku sekund:
postgres=# SELECT CASE WHEN pg_last_wal_receive_lsn() = pg_last_wal_replay_lsn()
THEN 0
ELSE EXTRACT (EPOCH FROM now() - pg_last_xact_replay_timestamp())
END AS log_delay;
log_delay
-----------
0
(1 row)Możesz także zobaczyć ostatnią otrzymaną wiadomość:
postgres=# SELECT status, last_msg_receipt_time FROM pg_stat_wal_receiver;
status | last_msg_receipt_time
-----------+------------------------------
streaming | 2022-04-13 18:32:39.83118+00
(1 row)Monitorowanie replikacji PostgreSQL za pomocą ClusterControl
Aby monitorować swój klaster PostgreSQL, możesz użyć ClusterControl, który umożliwia monitorowanie i wykonywanie kilku dodatkowych zadań zarządzania, takich jak wdrażanie, tworzenie kopii zapasowych, skalowanie w poziomie i nie tylko.
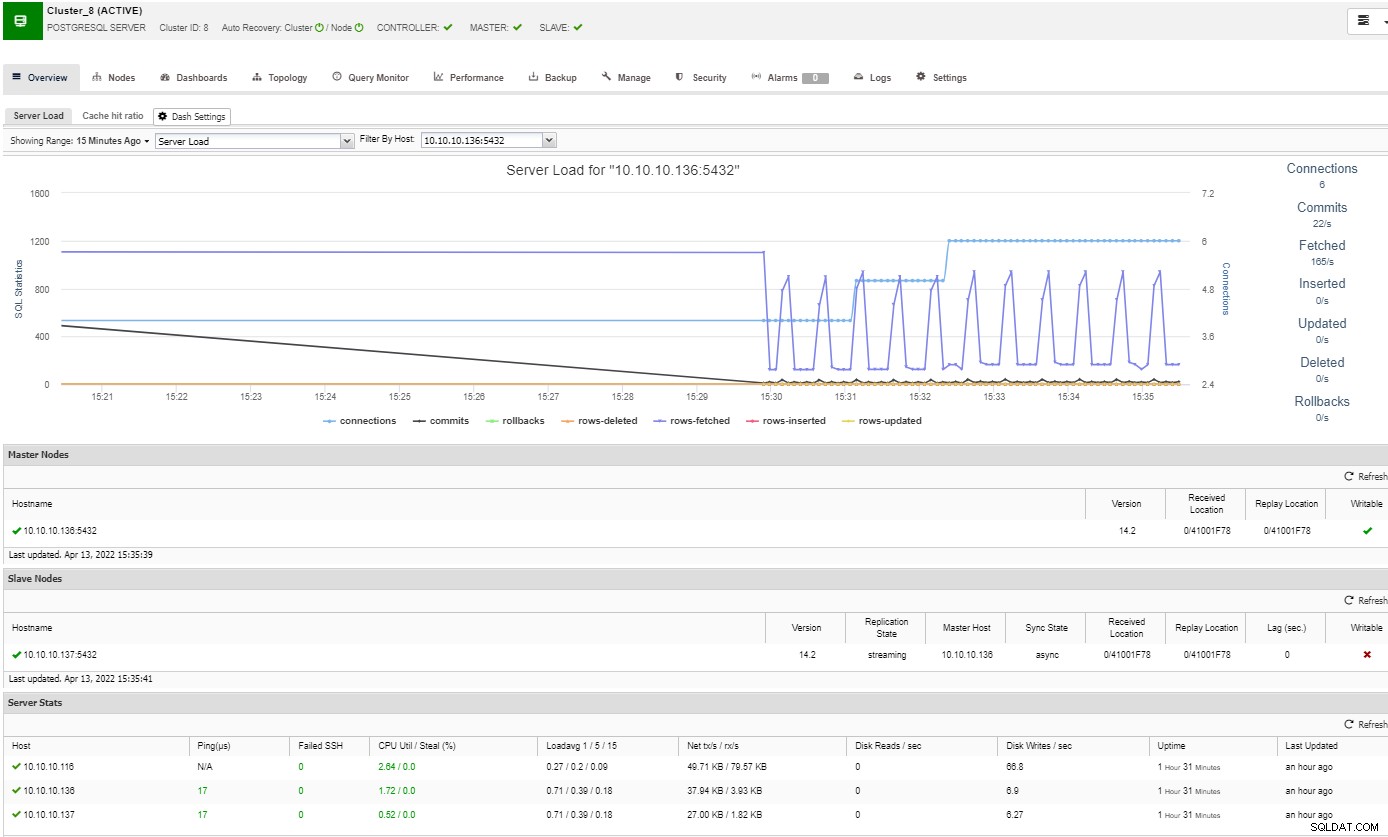
W sekcji przeglądu zobaczysz pełny obraz klastra bazy danych aktualny stan. Aby zobaczyć więcej szczegółów, możesz przejść do sekcji pulpitu nawigacyjnego, w której zobaczysz wiele przydatnych informacji podzielonych na różne wykresy.
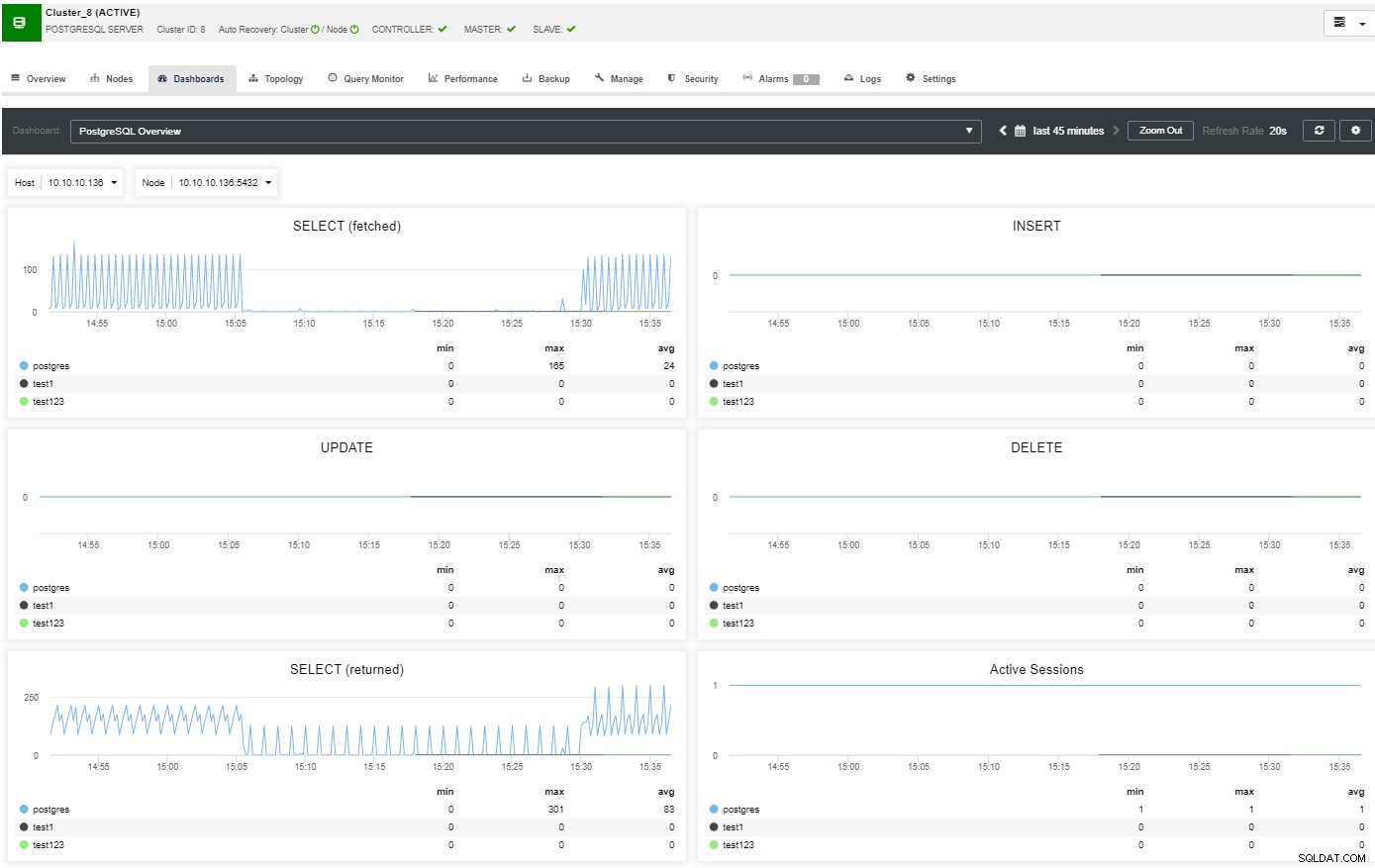
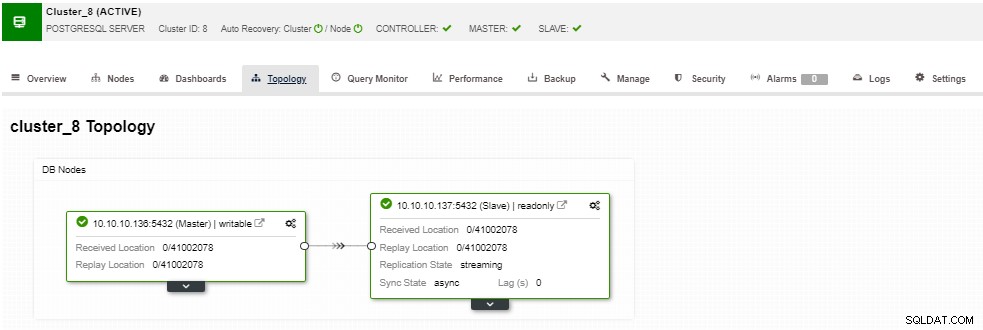
W sekcji topologii możesz zobaczyć swoją aktualną topologię w przyjazny sposób, a także możesz wykonywać różne zadania na węzłach za pomocą przycisku Akcja węzła.
Replikacja strumieniowa polega na wysłaniu rekordów WAL i zastosowaniu ich w trybie gotowości serwer, dyktuje jakie bajty dodać lub zmienić w jakim pliku. W rezultacie serwer rezerwowy jest w rzeczywistości kopią bit po bicie serwera podstawowego. Istnieją jednak pewne dobrze znane ograniczenia:
-
Nie można replikować do innej wersji lub architektury.
-
Nie można nic zmienić na serwerze rezerwowym.
-
Nie masz dużej szczegółowości tego, co replikujesz.
Aby przezwyciężyć te ograniczenia, PostgreSQL 10 dodał obsługę replikacji logicznej
Replikacja logiczna
Replikacja logiczna również wykorzysta informacje z pliku WAL, ale zdekoduje je na logiczne zmiany. Zamiast wiedzieć, który bajt się zmienił, będzie wiedział dokładnie, jakie dane zostały wstawione do której tabeli.
Opiera się na modelu „publikuj” i „subskrybuj” z co najmniej jednym subskrybentem subskrybującym co najmniej jedną publikację w węźle wydawcy, który wygląda tak:
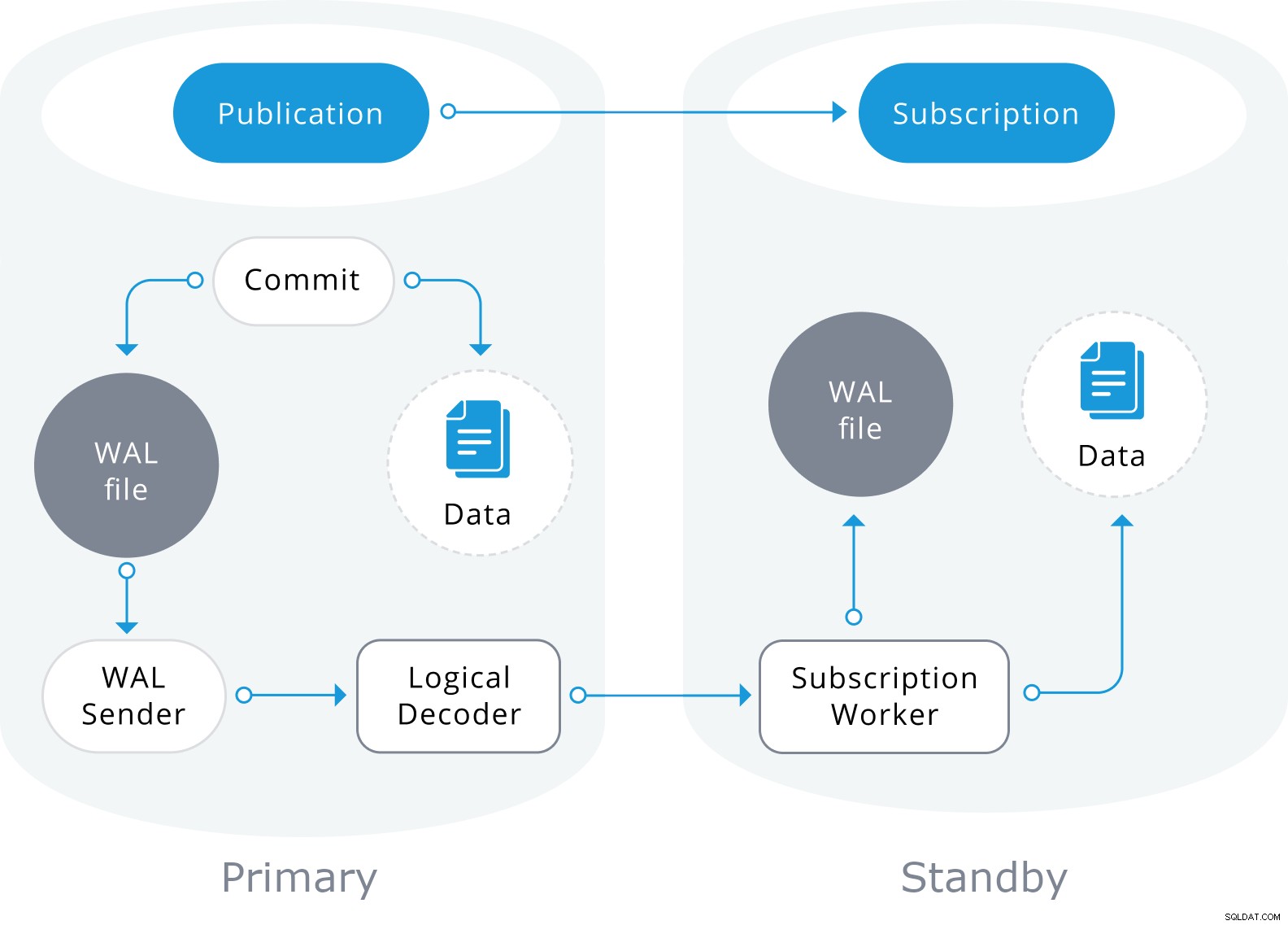
Zawijanie
Dzięki replikacji strumieniowej możesz stale wysyłać i stosować rekordy WAL do serwerów rezerwowych, zapewniając, że informacje zaktualizowane na serwerze głównym są przesyłane do serwera rezerwowego w czasie rzeczywistym, co pozwala na synchronizację obu .
ClusterControl sprawia, że konfigurowanie replikacji strumieniowej jest proste i możesz ją wypróbować za darmo przez 30 dni.
Jeśli chcesz dowiedzieć się więcej o replikacji logicznej w PostgreSQL, zapoznaj się z tym omówieniem replikacji logicznej i tym postem na temat najlepszych praktyk replikacji PostgreSQL.
Aby uzyskać więcej wskazówek i najlepszych praktyk dotyczących zarządzania bazą danych opartą na otwartym kodzie źródłowym, śledź nas na Twitterze i LinkedIn oraz subskrybuj nasz biuletyn, aby otrzymywać regularne aktualizacje.