W moim ostatnim poście rozpocząłem serię poświęconą proaktywnym kontrolom kondycji, które są niezbędne dla twojego SQL Server. Zaczęliśmy od miejsca na dysku, a w tym poście omówimy zadania konserwacyjne. Jednym z podstawowych obowiązków administratora baz danych jest zapewnienie regularnego wykonywania następujących zadań konserwacyjnych:
- Kopie zapasowe
- Kontrole integralności
- Utrzymanie indeksu
- Aktualizacje statystyk
Założę się, że masz już miejsca pracy, aby zarządzać tymi zadaniami. Założę się również, że masz skonfigurowane powiadomienia e-mail do Ciebie i Twojego zespołu, jeśli zadanie się nie powiedzie. Jeśli oba są prawdziwe, to już jesteś proaktywny w kwestii konserwacji. A jeśli nie robisz obu, to jest coś do naprawienia teraz – na przykład przestań to czytać, pobierz skrypty Ola Hallengren, zaplanuj je i upewnij się, że masz skonfigurowane powiadomienia. (Inną alternatywą specyficzną dla konserwacji indeksu, którą również zalecamy klientom, jest Menedżer fragmentacji SQL Sentry).
Jeśli nie wiesz, czy Twoje oferty pracy mają wysyłać do Ciebie e-maile, jeśli się nie powiedzie, użyj tego zapytania:
SELECT [Name], [Description] FROM [dbo].[sysjobs] WHERE [enabled] = 1 AND [notify_level_email] NOT IN (2,3) ORDER BY [Name];
Jednak proaktywne podejście do konserwacji idzie o krok dalej. Oprócz dbania o to, by Twoje zadania działały, musisz wiedzieć, jak długo one trwają. Możesz użyć tabel systemowych w msdb, aby to monitorować:
SELECT
[j].[name] AS [JobName],
[h].[step_id] AS [StepID],
[h].[step_name] AS [StepName],
CONVERT(CHAR(10), CAST(STR([h].[run_date],8, 0) AS DATETIME), 121) AS [RunDate],
STUFF(STUFF(RIGHT('000000' + CAST ( [h].[run_time] AS VARCHAR(6 ) ) ,6),5,0,':'),3,0,':')
AS [RunTime],
(([run_duration]/10000*3600 + ([run_duration]/100)%100*60 + [run_duration]%100 + 31 ) / 60)
AS [RunDuration_Minutes],
CASE [h].[run_status]
WHEN 0 THEN 'Failed'
WHEN 1 THEN 'Succeeded'
WHEN 2 THEN 'Retry'
WHEN 3 THEN 'Cancelled'
WHEN 4 THEN 'In Progress'
END AS [ExecutionStatus],
[h].[message] AS [MessageGenerated]
FROM [msdb].[dbo].[sysjobhistory] [h]
INNER JOIN [msdb].[dbo].[sysjobs] [j]
ON [h].[job_id] = [j].[job_id]
WHERE [j].[name] = 'DatabaseBackup - SYSTEM_DATABASES – FULL'
AND [step_id] = 0
ORDER BY [RunDate]; Lub, jeśli używasz skryptów Oli i informacji o logowaniu, możesz wysłać zapytanie do jego tabeli CommandLog:
SELECT [DatabaseName], [CommandType], [StartTime], [EndTime], DATEDIFF(MINUTE, [StartTime], [EndTime]) AS [Duration_Minutes] FROM [master].[dbo].[CommandLog] WHERE [DatabaseName] = 'AdventureWorks2014' AND [Command] LIKE 'BACKUP DATABASE%' ORDER BY [StartTime];
Powyższy skrypt wyświetla czas trwania kopii zapasowej dla każdej pełnej kopii zapasowej dla bazy danych AdventureWorks2014. Można oczekiwać, że czasy trwania zadań konserwacji będą powoli wzrastać w miarę upływu czasu w miarę rozrastania się baz danych. W związku z tym szukasz dużych wzrostów lub nieoczekiwanych spadków czasu trwania. Na przykład miałem klienta, którego średni czas tworzenia kopii zapasowej wynosił mniej niż 30 minut. Nagle kopie zapasowe zaczynają trwać dłużej niż godzinę. Baza danych nie zmieniła się znacząco pod względem rozmiaru, nie zmieniły się żadne ustawienia dla instancji lub bazy danych, nic się nie zmieniło w konfiguracji sprzętu lub dysku. Kilka tygodni później czas tworzenia kopii zapasowej spadł z powrotem do mniej niż pół godziny. Miesiąc później znowu podnieśli się w górę. Ostatecznie skorelowaliśmy zmianę czasu trwania kopii zapasowej z przełączaniem awaryjnym między węzłami klastra. Na jednym węźle tworzenie kopii zapasowych zajęło mniej niż pół godziny. Z drugiej zajęli ponad godzinę. Małe dochodzenie w sprawie konfiguracji kart sieciowych i sieci SAN i udało nam się zidentyfikować problem.
Ważne jest również zrozumienie średniego czasu wykonania operacji CHECKDB. To jest coś, o czym Paul mówi w naszym wydarzeniu zanurzeniowym dotyczącym wysokiej dostępności i odzyskiwania po awarii:musisz wiedzieć, ile czasu zwykle zajmuje polecenie CHECKDB, aby w przypadku znalezienia uszkodzenia i uruchomienia sprawdzania całej bazy danych wiedziałeś, jak długo powinno to trwać. weź dla CHECKDB, aby zakończyć. Kiedy twój szef pyta:„Ile jeszcze czasu zanim poznamy rozmiar problemu?” będziesz w stanie podać ilościową odpowiedź dotyczącą minimalnego czasu, jaki będziesz musiał czekać. Jeśli CHECKDB trwa dłużej niż zwykle, to wiesz, że coś znalazło (co niekoniecznie musi być uszkodzeniem; zawsze musisz pozwolić, aby sprawdzanie się zakończyło).
Teraz, jeśli zarządzasz setkami baz danych, nie chcesz uruchamiać powyższego zapytania dla każdej bazy danych lub każdego zadania. Zamiast tego możesz po prostu chcieć znaleźć oferty pracy, które wykraczają poza średni czas trwania o określony procent, co można uzyskać za pomocą tego zapytania:
SELECT
[j].[name] AS [JobName],
[h].[step_id] AS [StepID],
[h].[step_name] AS [StepName],
CONVERT(CHAR(10), CAST(STR([h].[run_date],8, 0) AS DATETIME), 121) AS [RunDate],
STUFF(STUFF(RIGHT('000000' + CAST ( [h].[run_time] AS VARCHAR(6 ) ) ,6),5,0,':'),3,0,':')
AS [RunTime],
(([run_duration]/10000*3600 + ([run_duration]/100)%100*60 + [run_duration]%100 + 31 ) / 60)
AS [RunDuration_Minutes],
[avdur].[Avg_RunDuration_Minutes]
FROM [dbo].[sysjobhistory] [h]
INNER JOIN [dbo].[sysjobs] [j]
ON [h].[job_id] = [j].[job_id]
INNER JOIN
(
SELECT
[j].[name] AS [JobName],
AVG((([run_duration]/10000*3600 + ([run_duration]/100)%100*60 + [run_duration]%100 + 31 ) / 60))
AS [Avg_RunDuration_Minutes]
FROM [dbo].[sysjobhistory] [h]
INNER JOIN [dbo].[sysjobs] [j]
ON [h].[job_id] = [j].[job_id]
WHERE [step_id] = 0
AND CONVERT(DATE, RTRIM(h.run_date)) >= DATEADD(DAY, -60, GETDATE())
GROUP BY [j].[name]
) AS [avdur]
ON [avdur].[JobName] = [j].[name]
WHERE [step_id] = 0
AND (([run_duration]/10000*3600 + ([run_duration]/100)%100*60 + [run_duration]%100 + 31 ) / 60)
> ([avdur].[Avg_RunDuration_Minutes] + ([avdur].[Avg_RunDuration_Minutes] * .25))
ORDER BY [j].[name], [RunDate]; To zapytanie zawiera listę zadań, które trwały o 25% dłużej niż średnia. Zapytanie będzie wymagało pewnych poprawek w celu dostarczenia konkretnych informacji, których potrzebujesz – niektóre zadania o krótkim czasie trwania (np. krótszym niż 5 minut) pojawią się, jeśli zajmą tylko kilka dodatkowych minut – to może nie być problemem. Niemniej jednak to zapytanie jest dobrym początkiem i zdajesz sobie sprawę, że istnieje wiele sposobów znajdowania odchyleń – możesz również porównać każde wykonanie z poprzednim i wyszukać zadania, które zajęły pewien procent dłużej niż poprzednie.
Oczywiście czas trwania zadania jest najbardziej logicznym identyfikatorem, którego można użyć w przypadku potencjalnych problemów – niezależnie od tego, czy jest to zadanie kopii zapasowej, sprawdzenie integralności, czy zadanie, które usuwa fragmentację i aktualizuje statystyki. Odkryłem, że największa zmienność czasu trwania występuje zazwyczaj w zadaniach usuwania fragmentacji i aktualizowania statystyk. W zależności od progów pomiędzy przebudową a przebudową i zmiennością danych, możesz mieć dni z przeważnie przebudową, a potem nagle pojawi się kilka przebudów indeksu dla dużych tabel, gdzie te przebudowy całkowicie zmieniają średni czas trwania. Możesz zmienić swoje progi dla niektórych indeksów lub dostosować współczynnik wypełnienia, aby przebudowy odbywały się częściej lub rzadziej – w zależności od indeksu i poziomu fragmentacji. Aby wprowadzić te poprawki, musisz sprawdzić, jak często każdy indeks jest przebudowywany lub reorganizowany, co możesz zrobić tylko wtedy, gdy korzystasz ze skryptów Ola i logujesz się do tabeli CommandLog lub jeśli masz własne rozwiązanie i rejestrujesz każda reorganizacja lub przebudowa. Aby przyjrzeć się temu za pomocą tabeli CommandLog, możesz zacząć od sprawdzenia, które indeksy są najczęściej zmieniane:
SELECT [DatabaseName], [ObjectName], [IndexName], COUNT(*) FROM [master].[dbo].[CommandLog] [c] WHERE [DatabaseName] = 'AdventureWorks2014' AND [Command] LIKE 'ALTER INDEX%' GROUP BY [DatabaseName], [ObjectName], [IndexName] ORDER BY COUNT(*) DESC;
Na podstawie tych wyników możesz zacząć sprawdzać, które tabele (a tym samym indeksy) mają największą zmienność, a następnie określić, czy należy dostosować próg dla ponownego organizowania w porównaniu z przebudową, czy też zmodyfikować współczynnik wypełnienia.
Ułatwianie życia
Teraz istnieje prostsze rozwiązanie niż pisanie własnych zapytań, o ile używasz programu SQL Sentry Event Manager (EM). Narzędzie monitoruje wszystkie zadania agenta skonfigurowane w instancji, a korzystając z widoku kalendarza, możesz szybko sprawdzić, które zadania nie powiodły się, zostały anulowane lub trwały dłużej niż zwykle:
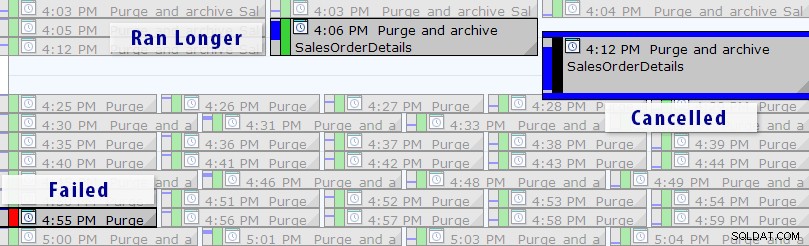 Widok kalendarza programu SQL Sentry Event Manager (z etykietami dodanymi w programie Photoshop)
Widok kalendarza programu SQL Sentry Event Manager (z etykietami dodanymi w programie Photoshop)
Możesz także zagłębić się w poszczególne wykonania, aby zobaczyć, ile czasu zajęło wykonanie zadania, a także przydatne wykresy czasu wykonywania, które pozwalają szybko zwizualizować wszelkie wzorce dotyczące anomalii czasu trwania lub warunków awarii. W tym przypadku widzę, że mniej więcej co 15 minut czas działania dla tego konkretnego zadania skoczył o prawie 400%:
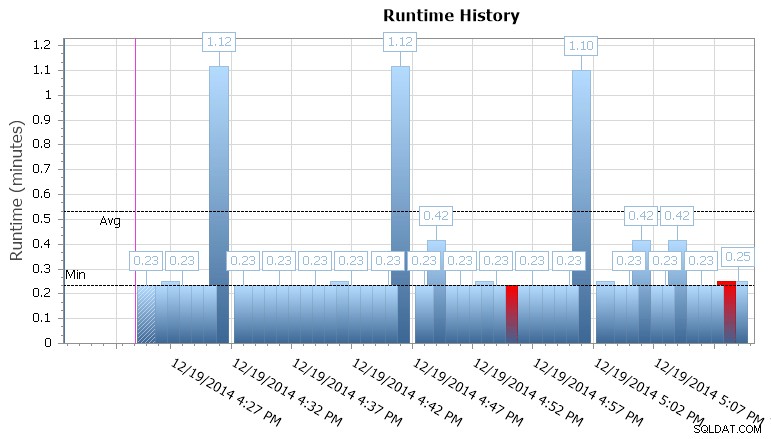 Wykres czasu wykonywania programu SQL Sentry Event Manager
Wykres czasu wykonywania programu SQL Sentry Event Manager
Daje mi to wskazówkę, że powinienem przyjrzeć się innym zaplanowanym zadaniom, które mogą tutaj powodować pewne problemy ze współbieżnością. Mógłbym ponownie pomniejszyć kalendarz, aby zobaczyć, jakie inne zadania działają w tym samym czasie, lub nawet nie muszę szukać, aby rozpoznać, że jest to zadanie raportowania lub tworzenia kopii zapasowej, które działa w tej bazie danych.
Podsumowanie
Założę się, że większość z was ma już na swoim miejscu niezbędne prace konserwacyjne, a także ma skonfigurowane powiadomienia o niepowodzeniach w pracy. Jeśli nie znasz średniego czasu trwania swoich prac, to kolejny krok w kierunku proaktywności. Uwaga:może być również konieczne sprawdzenie, jak długo przechowujesz historię pracy. Szukając odchyleń w czasie pracy, wolę patrzeć na dane z kilku miesięcy niż z kilku tygodni. Nie musisz zapamiętywać tych czasów działania, ale po sprawdzeniu, czy przechowujesz wystarczającą ilość danych, aby mieć historię do wykorzystania w badaniach, zacznij regularnie szukać odmian. W idealnym scenariuszu wydłużony czas działania może ostrzegać o potencjalnym problemie, umożliwiając rozwiązanie go, zanim problem wystąpi w środowisku produkcyjnym.