Zespół SQLskills uwielbia statystyki oczekiwania. Jeśli przejrzysz posty na tym blogu (zobacz posty Paula na temat statystyk Knee-Jerk Wait) i na stronie SQLskills, zobaczysz posty od nas wszystkich omawiające wartość statystyk oczekiwania, czego szukamy i dlaczego dany konkretny czekać jest problemem. Paul pisze o tym najczęściej, ale każdy z nas zazwyczaj zaczyna od statystyk oczekiwania podczas rozwiązywania problemów z wydajnością. Co to oznacza, jeśli chodzi o bycie proaktywnym?
Aby uzyskać pełny obraz tego, co oznaczają statystyki oczekiwania podczas problemów z wydajnością, musisz wiedzieć, jakie są twoje normalne oczekiwania. Oznacza to proaktywne przechwytywanie tych informacji i używanie tej linii bazowej jako odniesienia. Jeśli nie masz tych danych, to gdy wystąpi problem z wydajnością, nie będziesz wiedział, czy oczekiwania PAGELATCH są typowe w Twoim środowisku (całkiem możliwe), czy też nagle pojawił się problem związany z tempdb z powodu dodania nowego kodu .
Dane statystyczne oczekiwania
Opublikowałem wcześniej skrypt, którego używam do przechwytywania statystyk oczekiwania i jest to skrypt, którego używam od dawna dla klientów. Jednak ostatnio wprowadziłem zmiany w moim skrypcie i nieznacznie poprawiłem moją metodę. Pozwól, że wyjaśnię, dlaczego…
Podstawową przesłanką statystyk oczekiwania jest to, że SQL Server śledzi za każdym razem, gdy wątek musi czekać na „coś”. Czekasz na odczytanie strony z dysku? PAGEIOLATCH_XX czekaj. Czekasz na blokadę, aby dokonać modyfikacji danych? LCX_M_XXX czekaj. Czekasz na przyznanie pamięci, aby można było wykonać zapytanie? RESOURCE_SEMAPHORE czekaj. Wszystkie te oczekiwania są śledzone w DMV sys.dm_os_wait_stats, a dane po prostu gromadzą się w czasie… to skumulowany reprezentant oczekiwań.
Na przykład mam instancję SQL Server 2014 w jednej z moich maszyn wirtualnych, która działa od około 9:30 dziś rano:
SELECT [sqlserver_start_time] FROM [sys].[dm_os_sys_info];
 Godzina uruchomienia serwera SQL
Godzina uruchomienia serwera SQL
Teraz, jeśli przyjrzę się, jak wyglądają moje statystyki oczekiwania (pamiętaj, kumulatywne do tej pory) za pomocą skryptu Paula, widzę, że TRACEWRITE to moje obecne „standardowe” czekanie:
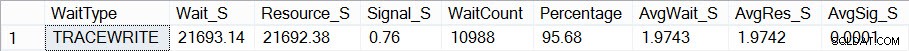 Bieżące zagregowane oczekiwania
Bieżące zagregowane oczekiwania
Ok, teraz przedstawmy pięć minut rywalizacji o tempdb i zobaczmy, jak wpływa to na moje ogólne statystyki oczekiwania. Mam skrypt, którego Jonathan używał wcześniej do tworzenia rywalizacji o tempdb, i skonfigurowałem go tak, aby działał przez 5 minut:
USE AdventureWorks2012;
GO
SET NOCOUNT ON;
GO
DECLARE @CurrentTime SMALLDATETIME = SYSDATETIME(), @EndTime SMALLDATETIME = DATEADD(MINUTE, 5, SYSDATETIME());
WHILE @CurrentTime < @EndTime
BEGIN
IF OBJECT_ID('tempdb..#temp') IS NOT NULL
BEGIN
DROP TABLE #temp;
END
CREATE TABLE #temp
(
ProductID INT PRIMARY KEY,
OrderQty INT,
TotalDiscount MONEY,
LineTotal MONEY,
Filler NCHAR(500) DEFAULT(N'') NOT NULL
);
INSERT INTO #temp(ProductID, OrderQty, TotalDiscount, LineTotal)
SELECT
sod.ProductID,
SUM(sod.OrderQty),
SUM(sod.LineTotal),
SUM(sod.OrderQty + sod.UnitPriceDiscount)
FROM Sales.SalesOrderDetail AS sod
GROUP BY ProductID;
DECLARE
@ProductNumber NVARCHAR(25),
@Name NVARCHAR(50),
@TotalQty INT,
@SalesTotal MONEY,
@TotalDiscount MONEY;
SELECT
@ProductNumber = p.ProductNumber,
@Name = p.Name,
@TotalQty = t1.OrderQty,
@SalesTotal = t1.LineTotal,
@TotalDiscount = t1.TotalDiscount
FROM Production.Product AS p
JOIN #temp AS t1 ON p.ProductID = t1.ProductID;
SET @CurrentTime = SYSDATETIME()
END Użyłem wiersza polecenia, aby uruchomić 10 sesji, które uruchamiały ten skrypt, i jednocześnie uruchomiłem skrypt, który przechwycił moje ogólne statystyki oczekiwania, migawkę oczekiwania w ciągu 5 minut, a następnie ponownie ogólne statystyki oczekiwania. Po pierwsze, mały sekret, ponieważ ignorujemy łagodne oczekiwania przez cały czas, przydatne może być umieszczenie ich w tabeli, aby można było odwoływać się do obiektu zamiast ciągłego kodowania listy ciągów wykluczających w zapytaniu. A więc:
USE SQLskills_WaitStats; GO CREATE TABLE dbo.WaitsToIgnore(WaitType SYSNAME PRIMARY KEY); INSERT dbo.WaitsToIgnore(WaitType) VALUES(N'BROKER_EVENTHANDLER'), (N'BROKER_RECEIVE_WAITFOR'), (N'BROKER_TASK_STOP'), (N'BROKER_TO_FLUSH'), (N'BROKER_TRANSMITTER'), (N'CHECKPOINT_QUEUE'), (N'CHKPT'), (N'CLR_AUTO_EVENT'), (N'CLR_MANUAL_EVENT'), (N'CLR_SEMAPHORE'), (N'DBMIRROR_DBM_EVENT'), (N'DBMIRROR_EVENTS_QUEUE'), (N'DBMIRROR_WORKER_QUEUE'), (N'DBMIRRORING_CMD'), (N'DIRTY_PAGE_POLL'), (N'DISPATCHER_QUEUE_SEMAPHORE'), (N'EXECSYNC'), (N'FSAGENT'), (N'FT_IFTS_SCHEDULER_IDLE_WAIT'), (N'FT_IFTSHC_MUTEX'), (N'HADR_CLUSAPI_CALL'), (N'HADR_FILESTREAM_IOMGR_IOCOMPLETIO(N'), (N'HADR_LOGCAPTURE_WAIT'), (N'HADR_NOTIFICATION_DEQUEUE'), (N'HADR_TIMER_TASK'), (N'HADR_WORK_QUEUE'), (N'KSOURCE_WAKEUP'), (N'LAZYWRITER_SLEEP'), (N'LOGMGR_QUEUE'), (N'ONDEMAND_TASK_QUEUE'), (N'PWAIT_ALL_COMPONENTS_INITIALIZED'), (N'QDS_PERSIST_TASK_MAIN_LOOP_SLEEP'), (N'QDS_CLEANUP_STALE_QUERIES_TASK_MAIN_LOOP_SLEEP'), (N'REQUEST_FOR_DEADLOCK_SEARCH'), (N'RESOURCE_QUEUE'), (N'SERVER_IDLE_CHECK'), (N'SLEEP_BPOOL_FLUSH'), (N'SLEEP_DBSTARTUP'), (N'SLEEP_DCOMSTARTUP'), (N'SLEEP_MASTERDBREADY'), (N'SLEEP_MASTERMDREADY'), (N'SLEEP_MASTERUPGRADED'), (N'SLEEP_MSDBSTARTUP'), (N'SLEEP_SYSTEMTASK'), (N'SLEEP_TASK'), (N'SLEEP_TEMPDBSTARTUP'), (N'SNI_HTTP_ACCEPT'), (N'SP_SERVER_DIAGNOSTICS_SLEEP'), (N'SQLTRACE_BUFFER_FLUSH'), (N'SQLTRACE_INCREMENTAL_FLUSH_SLEEP'), (N'SQLTRACE_WAIT_ENTRIES'), (N'WAIT_FOR_RESULTS'), (N'WAITFOR'), (N'WAITFOR_TASKSHUTDOW(N'), (N'WAIT_XTP_HOST_WAIT'), (N'WAIT_XTP_OFFLINE_CKPT_NEW_LOG'), (N'WAIT_XTP_CKPT_CLOSE'), (N'XE_DISPATCHER_JOIN'), (N'XE_DISPATCHER_WAIT'), (N'XE_TIMER_EVENT');
Teraz jesteśmy gotowi, aby uchwycić nasze oczekiwania:
/* Capture the instance start time
(in this case, time since waits have been accumulating) */
SELECT [sqlserver_start_time] FROM [sys].[dm_os_sys_info];
GO
/* Get the current time */
SELECT SYSDATETIME() AS [Before Test 1];
/* Get aggregate waits until now */
WITH [Waits] AS
(
SELECT
[wait_type],
[wait_time_ms] / 1000.0 AS [WaitS],
([wait_time_ms] - [signal_wait_time_ms]) / 1000.0 AS [ResourceS],
[signal_wait_time_ms] / 1000.0 AS [SignalS],
[waiting_tasks_count] AS [WaitCount],
100.0 * [wait_time_ms] / SUM ([wait_time_ms]) OVER() AS [Percentage],
ROW_NUMBER() OVER(ORDER BY [wait_time_ms] DESC) AS [RowNum]
FROM sys.dm_os_wait_stats
WHERE [wait_type] NOT IN (SELECT WaitType FROM SQLskills_Waits.WaitsToIgnore)
AND [waiting_tasks_count] > 0
)
SELECT
MAX ([W1].[wait_type]) AS [WaitType],
CAST (MAX ([W1].[WaitS]) AS DECIMAL (16,2)) AS [Wait_S],
CAST (MAX ([W1].[ResourceS]) AS DECIMAL (16,2)) AS [Resource_S],
CAST (MAX ([W1].[SignalS]) AS DECIMAL (16,2)) AS [Signal_S],
MAX ([W1].[WaitCount]) AS [WaitCount],
CAST (MAX ([W1].[Percentage]) AS DECIMAL (5,2)) AS [Percentage],
CAST ((MAX ([W1].[WaitS]) / MAX ([W1].[WaitCount])) AS DECIMAL (16,4)) AS [AvgWait_S],
CAST ((MAX ([W1].[ResourceS]) / MAX ([W1].[WaitCount])) AS DECIMAL (16,4)) AS [AvgRes_S],
CAST ((MAX ([W1].[SignalS]) / MAX ([W1].[WaitCount])) AS DECIMAL (16,4)) AS [AvgSig_S]
FROM [Waits] AS [W1]
INNER JOIN [Waits] AS [W2]
ON [W2].[RowNum] <= [W1].[RowNum]
GROUP BY [W1].[RowNum]
HAVING SUM ([W2].[Percentage]) - MAX ([W1].[Percentage]) < 95; -- percentage threshold
GO
/* Get the current time */
SELECT SYSDATETIME() AS [Before Test 2];
/* Capture a snapshot of waits over a 5 minute period */
IF EXISTS (SELECT * FROM [tempdb].[sys].[objects] WHERE [name] = N'##SQLskillsStats1')
DROP TABLE [##SQLskillsStats1];
IF EXISTS (SELECT * FROM [tempdb].[sys].[objects] WHERE [name] = N'##SQLskillsStats2')
DROP TABLE [##SQLskillsStats2];
GO
SELECT [wait_type], [waiting_tasks_count], [wait_time_ms],
[max_wait_time_ms], [signal_wait_time_ms]
INTO ##SQLskillsStats1
FROM sys.dm_os_wait_stats;
GO
WAITFOR DELAY '00:05:00';
GO
SELECT [wait_type], [waiting_tasks_count], [wait_time_ms],
[max_wait_time_ms], [signal_wait_time_ms]
INTO ##SQLskillsStats2
FROM sys.dm_os_wait_stats;
GO
WITH [DiffWaits] AS
(
SELECT -- Waits that weren't in the first snapshot
[ts2].[wait_type],
[ts2].[wait_time_ms],
[ts2].[signal_wait_time_ms],
[ts2].[waiting_tasks_count]
FROM [##SQLskillsStats2] AS [ts2]
LEFT OUTER JOIN [##SQLskillsStats1] AS [ts1]
ON [ts2].[wait_type] = [ts1].[wait_type]
WHERE [ts1].[wait_type] IS NULL
AND [ts2].[wait_time_ms] > 0
UNION
SELECT -- Diff of waits in both snapshots
[ts2].[wait_type],
[ts2].[wait_time_ms] - [ts1].[wait_time_ms] AS [wait_time_ms],
[ts2].[signal_wait_time_ms] - [ts1].[signal_wait_time_ms] AS [signal_wait_time_ms],
[ts2].[waiting_tasks_count] - [ts1].[waiting_tasks_count] AS [waiting_tasks_count]
FROM [##SQLskillsStats2] AS [ts2]
LEFT OUTER JOIN [##SQLskillsStats1] AS [ts1]
ON [ts2].[wait_type] = [ts1].[wait_type]
WHERE [ts1].[wait_type] IS NOT NULL
AND [ts2].[waiting_tasks_count] - [ts1].[waiting_tasks_count] > 0
AND [ts2].[wait_time_ms] - [ts1].[wait_time_ms] > 0
),
[Waits] AS
(
SELECT
[wait_type],
[wait_time_ms] / 1000.0 AS [WaitS],
([wait_time_ms] - [signal_wait_time_ms]) / 1000.0 AS [ResourceS],
[signal_wait_time_ms] / 1000.0 AS [SignalS],
[waiting_tasks_count] AS [WaitCount],
100.0 * [wait_time_ms] / SUM ([wait_time_ms]) OVER() AS [Percentage],
ROW_NUMBER() OVER(ORDER BY [wait_time_ms] DESC) AS [RowNum]
FROM [DiffWaits]
WHERE [wait_type] NOT IN (SELECT WaitType FROM SQLskills_WaitStats.dbo.WaitsToIgnore)
)
SELECT
[W1].[wait_type] AS [WaitType],
CAST ([W1].[WaitS] AS DECIMAL (16, 2)) AS [Wait_S],
CAST ([W1].[ResourceS] AS DECIMAL (16, 2)) AS [Resource_S],
CAST ([W1].[SignalS] AS DECIMAL (16, 2)) AS [Signal_S],
[W1].[WaitCount] AS [WaitCount],
CAST ([W1].[Percentage] AS DECIMAL (5, 2)) AS [Percentage],
CAST (([W1].[WaitS] / [W1].[WaitCount]) AS DECIMAL (16, 4)) AS [AvgWait_S],
CAST (([W1].[ResourceS] / [W1].[WaitCount]) AS DECIMAL (16, 4)) AS [AvgRes_S],
CAST (([W1].[SignalS] / [W1].[WaitCount]) AS DECIMAL (16, 4)) AS [AvgSig_S]
FROM [Waits] AS [W1]
INNER JOIN [Waits] AS [W2]
ON [W2].[RowNum] <= [W1].[RowNum]
GROUP BY [W1].[RowNum], [W1].[wait_type], [W1].[WaitS],
[W1].[ResourceS], [W1].[SignalS], [W1].[WaitCount], [W1].[Percentage]
HAVING SUM ([W2].[Percentage]) - [W1].[Percentage] < 95; -- percentage threshold
GO
-- Cleanup
IF EXISTS (SELECT * FROM [tempdb].[sys].[objects] WHERE [name] = N'##SQLskillsStats1')
DROP TABLE [##SQLskillsStats1];
IF EXISTS (SELECT * FROM [tempdb].[sys].[objects] WHERE [name] = N'##SQLskillsStats2')
DROP TABLE [##SQLskillsStats2];
GO
/* Get the current time */
SELECT SYSDATETIME() AS [After Test 1];
/* Get aggregate waits again */
WITH [Waits] AS
(
SELECT
[wait_type],
[wait_time_ms] / 1000.0 AS [WaitS],
([wait_time_ms] - [signal_wait_time_ms]) / 1000.0 AS [ResourceS],
[signal_wait_time_ms] / 1000.0 AS [SignalS],
[waiting_tasks_count] AS [WaitCount],
100.0 * [wait_time_ms] / SUM ([wait_time_ms]) OVER() AS [Percentage],
ROW_NUMBER() OVER(ORDER BY [wait_time_ms] DESC) AS [RowNum]
FROM sys.dm_os_wait_stats
WHERE [wait_type] NOT IN (SELECT WaitType FROM SQLskills_WaitStats.dbo.WaitsToIgnore)
AND [waiting_tasks_count] > 0
)
SELECT
MAX ([W1].[wait_type]) AS [WaitType],
CAST (MAX ([W1].[WaitS]) AS DECIMAL (16,2)) AS [Wait_S],
CAST (MAX ([W1].[ResourceS]) AS DECIMAL (16,2)) AS [Resource_S],
CAST (MAX ([W1].[SignalS]) AS DECIMAL (16,2)) AS [Signal_S],
MAX ([W1].[WaitCount]) AS [WaitCount],
CAST (MAX ([W1].[Percentage]) AS DECIMAL (5,2)) AS [Percentage],
CAST ((MAX ([W1].[WaitS]) / MAX ([W1].[WaitCount])) AS DECIMAL (16,4)) AS [AvgWait_S],
CAST ((MAX ([W1].[ResourceS]) / MAX ([W1].[WaitCount])) AS DECIMAL (16,4)) AS [AvgRes_S],
CAST ((MAX ([W1].[SignalS]) / MAX ([W1].[WaitCount])) AS DECIMAL (16,4)) AS [AvgSig_S]
FROM [Waits] AS [W1]
INNER JOIN [Waits] AS [W2]
ON [W2].[RowNum] <= [W1].[RowNum]
GROUP BY [W1].[RowNum]
HAVING SUM ([W2].[Percentage]) - MAX ([W1].[Percentage]) < 95; -- percentage threshold
GO
/* Get the current time */
SELECT SYSDATETIME() AS [After Test 2]; Jeśli spojrzymy na dane wyjściowe, zobaczymy, że podczas gdy 10 wystąpień skryptu tworzącego rywalizację o tempdb było uruchomionych, SOS_SCHEDULER_YIELD był naszym najbardziej rozpowszechnionym typem oczekiwania, a także, zgodnie z oczekiwaniami, mieliśmy oczekiwania PAGELATCH_XX:
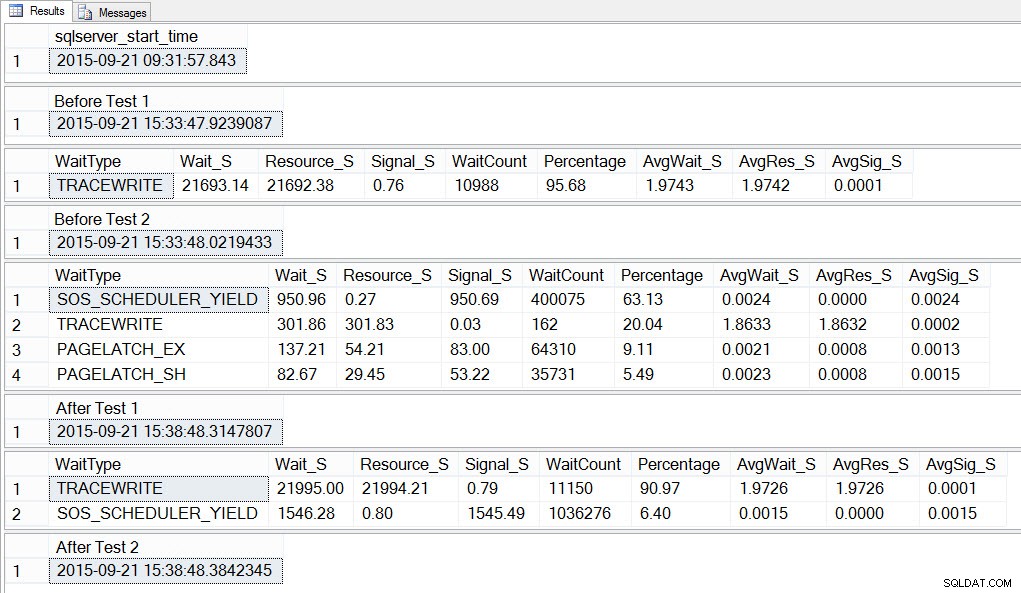
Jeśli spojrzymy na średnie oczekiwania PO zakończeniu testu, ponownie zobaczymy TRACEWRITE jako najwyższy czas oczekiwania i widzimy SOS_SCHEDULER_YIELD jako oczekiwanie. W zależności od tego, co jeszcze działa w środowisku, to oczekiwanie może lub nie może utrzymywać się w naszym górnym czasie przez długi czas i może, ale nie musi, pojawiać się jako typ oczekiwania do zbadania.
Proaktywne przechwytywanie statystyk oczekiwania
Domyślnie statystyki oczekiwania są kumulowane . Tak, możesz je wyczyścić w dowolnym momencie za pomocą DBCC SQLPERF, ale uważam, że większość ludzi nie robi tego regularnie, po prostu pozwala im się kumulować. I to jest w porządku, ale zrozum, jak wpływa to na twoje dane. Jeśli ponownie uruchomisz instancję dopiero po jej załataniu lub w przypadku wystąpienia problemu (co, miejmy nadzieję, zdarza się rzadko), dane mogą gromadzić się miesiącami. Im więcej masz danych, tym trudniej dostrzec małe różnice… rzeczy, które mogą powodować problemy z wydajnością. Nawet jeśli masz „duży problem”, który wpływa na cały serwer przez kilka minut, tak jak zrobiliśmy to tutaj z tempdb, może to nie spowodować wystarczającej zmiany w twoich danych, aby zostać wykrytym w skumulowanych danych. Zamiast tego musisz zrobić zrzut danych (przechwyć je, poczekaj kilka minut, przechwyć ponownie, a następnie porównaj dane), aby zobaczyć, co naprawdę się dzieje teraz .
W związku z tym, jeśli po prostu robisz migawkę statystyk oczekiwania co kilka godzin, zebrane dane pokazują tylko ciągłą agregację w czasie. możesz porównaj te migawki, aby zrozumieć wydajność między migawkami, ale mogę powiedzieć, że nie musisz pisać tego kodu na dużym zestawie danych, to jest uciążliwe (ale nie jestem programistą, więc może to dla ciebie łatwe ).
Moja tradycyjna metoda przechwytywania statystyk oczekiwania polegała na wykonywaniu co kilka godzin migawki sys.dm_os_wait_stats przy użyciu oryginalnego skryptu Paula:
USE [BaselineData];
GO
IF NOT EXISTS (SELECT * FROM [sys].[tables] WHERE [name] = N'SQLskills_WaitStats_OldMethod')
BEGIN
CREATE TABLE [dbo].[SQLskills_WaitStats_OldMethod]
(
[RowNum] [bigint] IDENTITY(1,1) NOT NULL,
[CaptureDate] [datetime] NULL,
[WaitType] [nvarchar](120) NULL,
[Wait_S] [decimal](14, 2) NULL,
[Resource_S] [decimal](14, 2) NULL,
[Signal_S] [decimal](14, 2) NULL,
[WaitCount] [bigint] NULL,
[Percentage] [decimal](4, 2) NULL,
[AvgWait_S] [decimal](14, 4) NULL,
[AvgRes_S] [decimal](14, 4) NULL,
[AvgSig_S] [decimal](14, 4) NULL
);
CREATE CLUSTERED INDEX [CI_SQLskills_WaitStats_OldMethod]
ON [dbo].[SQLskills_WaitStats_OldMethod] ([CaptureDate],[RowNum]);
END
GO
/* Query to use in scheduled job */
USE [BaselineData];
GO
INSERT INTO [dbo].[SQLskills_WaitStats_OldMethod]
(
[CaptureDate] ,
[WaitType] ,
[Wait_S] ,
[Resource_S] ,
[Signal_S] ,
[WaitCount] ,
[Percentage] ,
[AvgWait_S] ,
[AvgRes_S] ,
[AvgSig_S]
)
EXEC ('WITH [Waits] AS (SELECT
[wait_type],
[wait_time_ms] / 1000.0 AS [WaitS],
([wait_time_ms] - [signal_wait_time_ms]) / 1000.0 AS [ResourceS],
[signal_wait_time_ms] / 1000.0 AS [SignalS],
[waiting_tasks_count] AS [WaitCount],
100.0 * [wait_time_ms] / SUM ([wait_time_ms]) OVER() AS [Percentage],
ROW_NUMBER() OVER(ORDER BY [wait_time_ms] DESC) AS [RowNum]
FROM sys.dm_os_wait_stats
WHERE [wait_type] NOT IN (SELECT WaitType FROM SQLskills_WaitStats.dbo.WaitsToIgnore)
)
SELECT
GETDATE(),
[W1].[wait_type] AS [WaitType],
CAST ([W1].[WaitS] AS DECIMAL(14, 2)) AS [Wait_S],
CAST ([W1].[ResourceS] AS DECIMAL(14, 2)) AS [Resource_S],
CAST ([W1].[SignalS] AS DECIMAL(14, 2)) AS [Signal_S],
[W1].[WaitCount] AS [WaitCount],
CAST ([W1].[Percentage] AS DECIMAL(4, 2)) AS [Percentage],
CAST (([W1].[WaitS] / [W1].[WaitCount]) AS DECIMAL (14, 4)) AS [AvgWait_S],
CAST (([W1].[ResourceS] / [W1].[WaitCount]) AS DECIMAL (14, 4)) AS [AvgRes_S],
CAST (([W1].[SignalS] / [W1].[WaitCount]) AS DECIMAL (14, 4)) AS [AvgSig_S]
FROM [Waits] AS [W1]
INNER JOIN [Waits] AS [W2]
ON [W2].[RowNum] <= [W1].[RowNum]
GROUP BY [W1].[RowNum], [W1].[wait_type], [W1].[WaitS], [W1].[ResourceS],
[W1].[SignalS], [W1].[WaitCount], [W1].[Percentage]
HAVING SUM ([W2].[Percentage]) - [W1].[Percentage] < 95;'
); Następnie przejrzałbym i spojrzał na górę, czekając na każdą migawkę, na przykład:
SELECT [w].[CaptureDate] , [w].[WaitType] , [w].[Percentage] , [w].[Wait_S] , [w].[WaitCount] , [w].[AvgWait_S] FROM [dbo].[SQLskills_WaitStats_OldMethod] w JOIN ( SELECT MIN([RowNum]) AS [RowNumber] , [CaptureDate] FROM [dbo].[SQLskills_WaitStats_OldMethod] WHERE [CaptureDate] IS NOT NULL AND [CaptureDate] > GETDATE() - 60 GROUP BY [CaptureDate] ) m ON [w].[RowNum] = [m].[RowNumber] ORDER BY [w].[CaptureDate];
Moją nową, alternatywną metodą jest porównywanie kilku migawek statystyk oczekiwania (z dwiema do trzech minut między migawkami) mniej więcej co godzinę. Ta informacja mówi mi dokładnie, na co w tym czasie czekał system:
USE [BaselineData];
GO
IF NOT EXISTS ( SELECT * FROM [sys].[tables] WHERE [name] = N'SQLskills_WaitStats')
BEGIN
CREATE TABLE [dbo].[SQLskills_WaitStats]
(
[RowNum] [bigint] IDENTITY(1,1) NOT NULL,
[CaptureDate] [datetime] NOT NULL DEFAULT (sysdatetime()),
[WaitType] [nvarchar](60) NOT NULL,
[Wait_S] [decimal](16, 2) NULL,
[Resource_S] [decimal](16, 2) NULL,
[Signal_S] [decimal](16, 2) NULL,
[WaitCount] [bigint] NULL,
[Percentage] [decimal](5, 2) NULL,
[AvgWait_S] [decimal](16, 4) NULL,
[AvgRes_S] [decimal](16, 4) NULL,
[AvgSig_S] [decimal](16, 4) NULL
) ON [PRIMARY];
CREATE CLUSTERED INDEX [CI_SQLskills_WaitStats]
ON [dbo].[SQLskills_WaitStats] ([CaptureDate],[RowNum]);
END
/* Query to use in scheduled job */
USE [BaselineData];
GO
IF EXISTS (SELECT * FROM [tempdb].[sys].[objects] WHERE [name] = N'##SQLskillsStats1')
DROP TABLE [##SQLskillsStats1];
IF EXISTS (SELECT * FROM [tempdb].[sys].[objects] WHERE [name] = N'##SQLskillsStats2')
DROP TABLE [##SQLskillsStats2];
GO
/* Capture wait stats */
SELECT [wait_type], [waiting_tasks_count], [wait_time_ms],
[max_wait_time_ms], [signal_wait_time_ms]
INTO ##SQLskillsStats1
FROM sys.dm_os_wait_stats;
GO
/* Wait some amount of time */
WAITFOR DELAY '00:02:00';
GO
/* Capture wait stats again */
SELECT [wait_type], [waiting_tasks_count], [wait_time_ms],
[max_wait_time_ms], [signal_wait_time_ms]
INTO ##SQLskillsStats2
FROM sys.dm_os_wait_stats;
GO
/* Diff the waits */
WITH [DiffWaits] AS
(
SELECT -- Waits that weren't in the first snapshot
[ts2].[wait_type],
[ts2].[wait_time_ms],
[ts2].[signal_wait_time_ms],
[ts2].[waiting_tasks_count]
FROM [##SQLskillsStats2] AS [ts2]
LEFT OUTER JOIN [##SQLskillsStats1] AS [ts1]
ON [ts2].[wait_type] = [ts1].[wait_type]
WHERE [ts1].[wait_type] IS NULL
AND [ts2].[wait_time_ms] > 0
UNION
SELECT -- Diff of waits in both snapshots
[ts2].[wait_type],
[ts2].[wait_time_ms] - [ts1].[wait_time_ms] AS [wait_time_ms],
[ts2].[signal_wait_time_ms] - [ts1].[signal_wait_time_ms] AS [signal_wait_time_ms],
[ts2].[waiting_tasks_count] - [ts1].[waiting_tasks_count] AS [waiting_tasks_count]
FROM [##SQLskillsStats2] AS [ts2]
LEFT OUTER JOIN [##SQLskillsStats1] AS [ts1]
ON [ts2].[wait_type] = [ts1].[wait_type]
WHERE [ts1].[wait_type] IS NOT NULL
AND [ts2].[waiting_tasks_count] - [ts1].[waiting_tasks_count] > 0
AND [ts2].[wait_time_ms] - [ts1].[wait_time_ms] > 0
),
[Waits] AS
(
SELECT
[wait_type],
[wait_time_ms] / 1000.0 AS [WaitS],
([wait_time_ms] - [signal_wait_time_ms]) / 1000.0 AS [ResourceS],
[signal_wait_time_ms] / 1000.0 AS [SignalS],
[waiting_tasks_count] AS [WaitCount],
100.0 * [wait_time_ms] / SUM ([wait_time_ms]) OVER() AS [Percentage],
ROW_NUMBER() OVER(ORDER BY [wait_time_ms] DESC) AS [RowNum]
FROM [DiffWaits]
WHERE [wait_type] NOT IN (SELECT WaitType FROM SQLskills_WaitStats.dbo.WaitsToIgnore)
)
INSERT INTO [BaselineData].[dbo].[SQLskills_WaitStats]
(
[WaitType] ,
[Wait_S] ,
[Resource_S] ,
[Signal_S] ,
[WaitCount] ,
[Percentage] ,
[AvgWait_S] ,
[AvgRes_S] ,
[AvgSig_S]
)
SELECT
[W1].[wait_type],
CAST ([W1].[WaitS] AS DECIMAL (16, 2)) ,
CAST ([W1].[ResourceS] AS DECIMAL (16, 2)) ,
CAST ([W1].[SignalS] AS DECIMAL (16, 2)) ,
[W1].[WaitCount] ,
CAST ([W1].[Percentage] AS DECIMAL (5, 2)) ,
CAST (([W1].[WaitS] / [W1].[WaitCount]) AS DECIMAL (16, 4)) ,
CAST (([W1].[ResourceS] / [W1].[WaitCount]) AS DECIMAL (16, 4)) ,
CAST (([W1].[SignalS] / [W1].[WaitCount]) AS DECIMAL (16, 4))
FROM [Waits] AS [W1]
INNER JOIN [Waits] AS [W2]
ON [W2].[RowNum] <= [W1].[RowNum]
GROUP BY [W1].[RowNum], [W1].[wait_type], [W1].[WaitS], [W1].[ResourceS],
[W1].[SignalS], [W1].[WaitCount], [W1].[Percentage]
HAVING SUM ([W2].[Percentage]) - [W1].[Percentage] < 95; -- percentage threshold
GO
/* Clean up the temp tables */
IF EXISTS (SELECT * FROM [tempdb].[sys].[objects] WHERE [name] = N'##SQLskillsStats1')
DROP TABLE [##SQLskillsStats1];
IF EXISTS (SELECT * FROM [tempdb].[sys].[objects] WHERE [name] = N'##SQLskillsStats2')
DROP TABLE [##SQLskillsStats2]; Czy moja nowa metoda jest lepsza? Myślę, że tak, ponieważ jest to lepsza reprezentacja tego, jak wyglądają oczekiwania w momencie przechwytywania, i nadal próbkuje w regularnych odstępach czasu. W przypadku obu metod zwykle sprawdzam, jaki był najwyższy czas oczekiwania w momencie przechwytywania:
SELECT [w].[CaptureDate] , [w].[WaitType] , [w].[Percentage] , [w].[Wait_S] , [w].[WaitCount] , [w].[AvgWait_S] FROM [dbo].[SQLskills_WaitStats] w JOIN ( SELECT MIN([RowNum]) AS [RowNumber], [CaptureDate] FROM [dbo].[SQLskills_WaitStats] WHERE [CaptureDate] > GETDATE() - 30 GROUP BY [CaptureDate] ) m ON [w].[RowNum] = [m].[RowNumber] ORDER BY [w].[CaptureDate];
Wyniki:
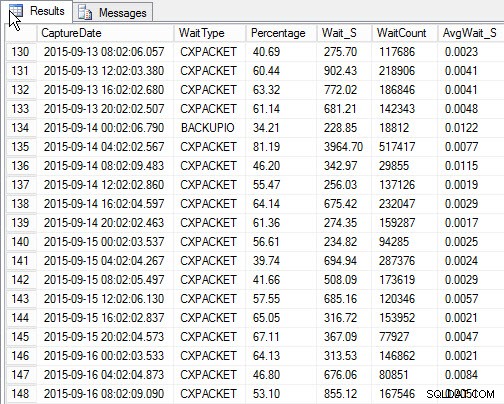 Najważniejsze oczekiwanie na każdy zrzut (przykładowe dane wyjściowe)
Najważniejsze oczekiwanie na każdy zrzut (przykładowe dane wyjściowe)
Wadą mojego oryginalnego skryptu jest to, że nadal jest to tylko migawka . Z czasem mogę trendować najwięcej oczekiwań, ale jeśli wystąpi problem między migawkami, to się nie pojawi. Więc co możesz zrobić?
Możesz zwiększyć częstotliwość przechwytywania. Być może zamiast rejestrować statystyki oczekiwania co godzinę, rejestrujesz je co 15 minut. A może co 10. Im częściej zbierasz dane, tym większa szansa, że wykryjesz problem z wydajnością.
Inną opcją byłoby użycie aplikacji innej firmy, takiej jak SQL Sentry Performance Advisor, do monitorowania oczekiwania. Performance Advisor pobiera dokładnie te same informacje z DMV sys.dm_os_wait_stats. Odpytuje sys.dm_os_wait_stats co 10 sekund za pomocą bardzo prostego zapytania:
SELECT * FROM sys.dm_os_wait_stats WHERE wait_time_ms > 0;
Za kulisami Performance Advisor pobiera te dane i dodaje je do swojej bazy danych monitorowania. Gdy zobaczysz dane, łagodne oczekiwania są usuwane, a delty są obliczane za Ciebie. Ponadto Performance Advisor ma fantastyczny wyświetlacz (patrzenie na deskę rozdzielczą jest znacznie ładniejsze niż tekst powyżej) i możesz dostosować kolekcję, jeśli chcesz. Jeśli spojrzymy na Performance Advisor i spojrzymy na dane z całego dnia, mogę łatwo zobaczyć, gdzie miałem problem w okienku SQL Server Waits:
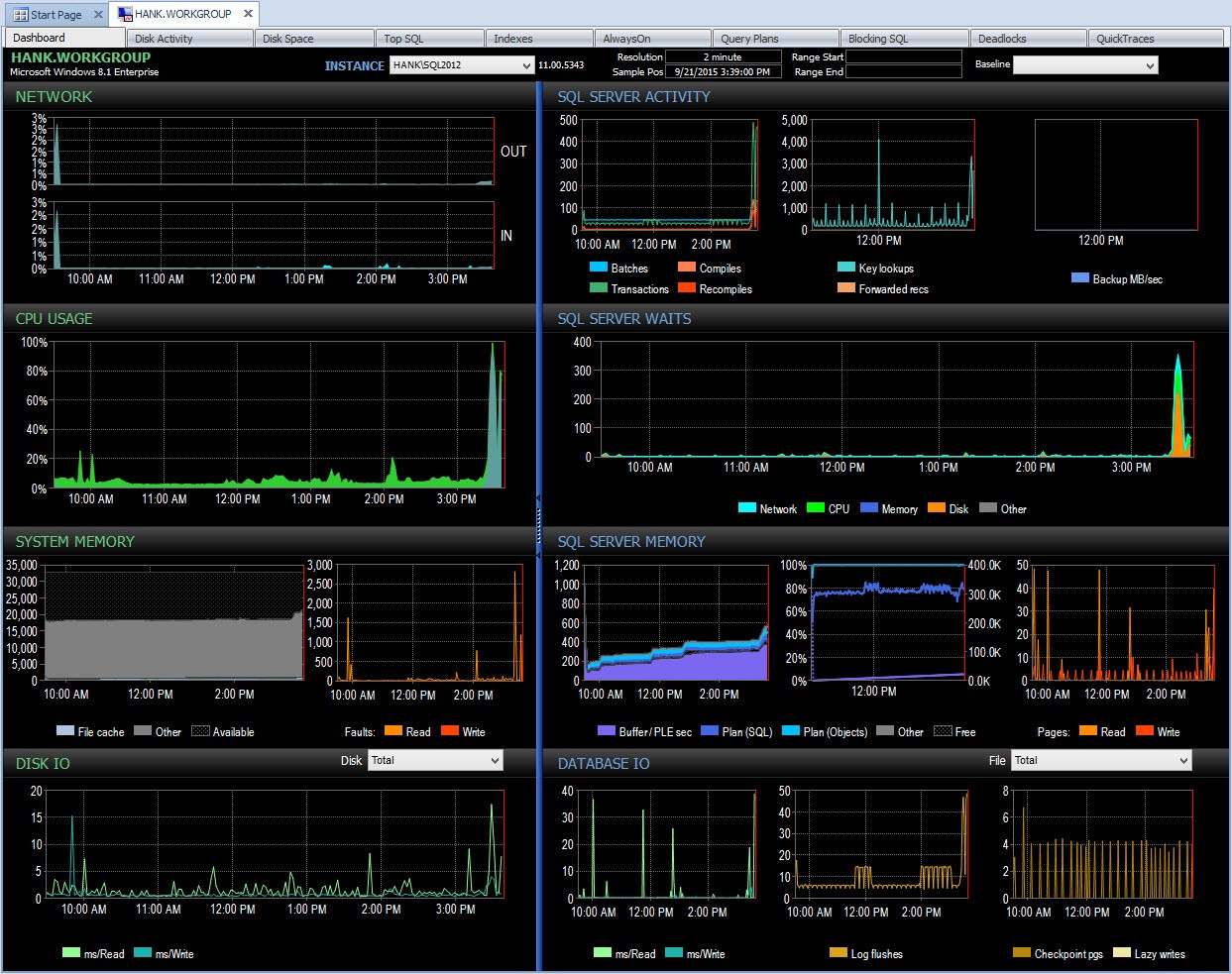 Panel doradcy wydajności na dany dzień
Panel doradcy wydajności na dany dzień
Następnie mogę zagłębić się w ten okres po godzinie 15:00, aby dokładniej zbadać, co się stało:
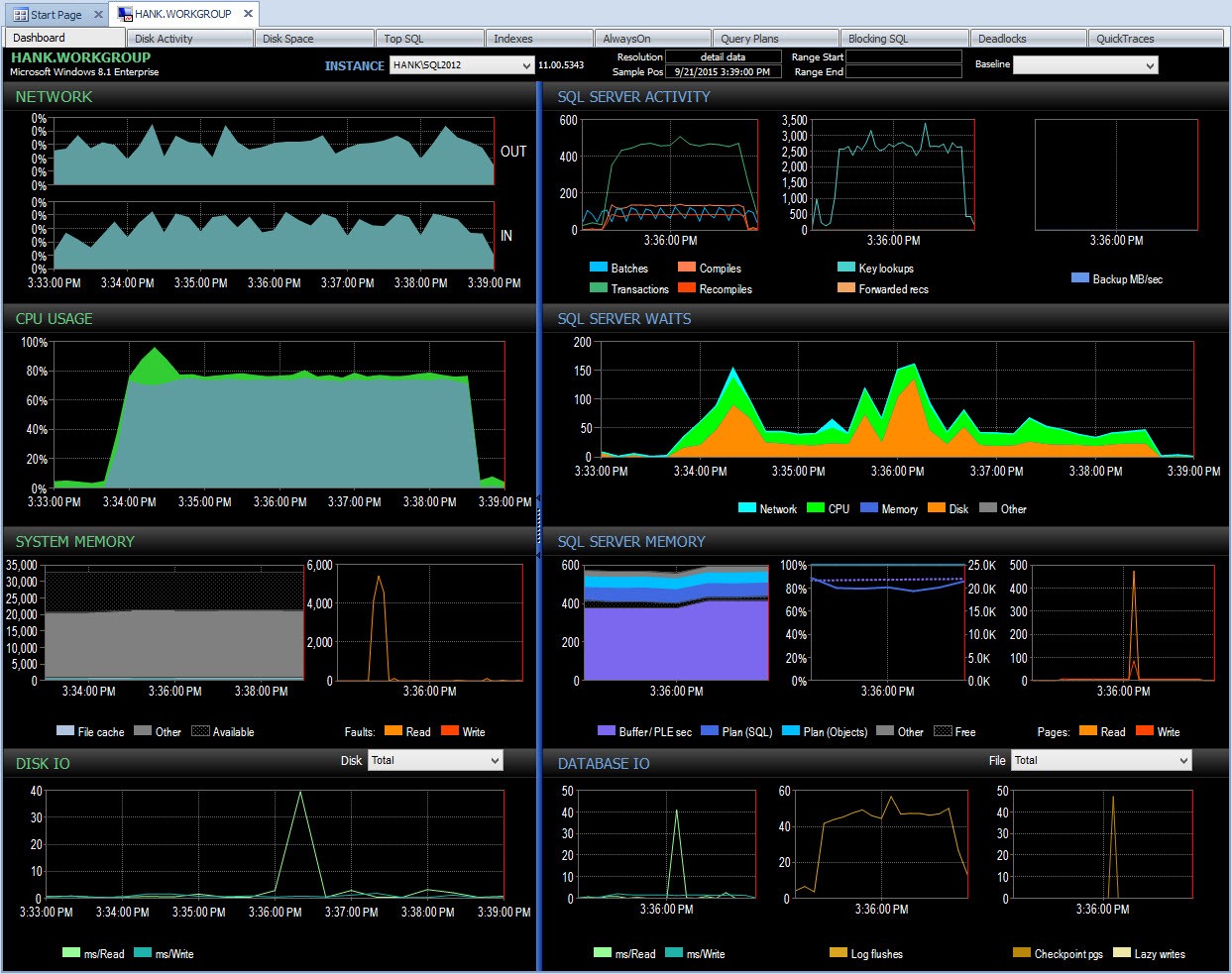 Przeanalizuj PA podczas problemów z wydajnością
Przeanalizuj PA podczas problemów z wydajnością
Samodzielne monitorowanie, chyba że zdarzyło mi się zrobić migawkowe statystyki oczekiwania w tym samym czasie za pomocą skryptu, przegapiłbym przechwycenie jakichkolwiek danych dotyczących tego problemu z wydajnością. Ponieważ Performance Advisor przechowuje informacje przez dłuższy czas, w przypadku spadku wydajności tak masz dostępne statystyki oczekiwania (wraz z wieloma innymi informacjami), które pomogą zbadać problem, a także dane historyczne, dzięki którym zrozumiesz, jakie normalne oczekiwania istnieją w Twoim środowisku.
Podsumowanie
Niezależnie od wybranej metody monitorowania, najpierw ważne jest, aby zrozumieć, jak SQL Server przechowuje informacje o oczekiwaniu, dzięki czemu możesz zrozumieć dane, które widzisz, jeśli przechwytujesz je regularnie. Jeśli musisz tworzyć własne skrypty, aby przechwytywać oczekiwania, jesteś ograniczony, ponieważ możesz nie wychwytywać odchyleń tak łatwo, jak w przypadku oprogramowania innych firm. Ale to jest w porządku – posiadanie pewnej ilości danych podstawowych, dzięki czemu możesz zacząć rozumieć, co jest „normalne”, jest lepsze niż nie posiadanie w ogóle niczego . Kiedy budujesz swoje repozytorium i zaczynasz oswajać się ze środowiskiem, możesz odpowiednio dostosować swoje skrypty przechwytywania, aby rozwiązać wszelkie problemy, które mogą wystąpić. Jeśli korzystasz z oprogramowania stron trzecich, wykorzystaj te informacje w pełni i upewnij się, że rozumiesz, w jaki sposób gromadzi się i przechowuje oczekiwania.