W tym artykule omówimy punkty kontrolne SQL Server.
Aby zwiększyć wydajność, SQL Server stosuje modyfikacje stron bazy danych w pamięci. Często ta pamięć jest nazywana buforem buforowym lub pulą buforów. SQL Server nie opróżnia tych stron na dysk po każdej zmianie. Zamiast tego silnik bazy danych od czasu do czasu wykonuje operacje w punktach kontrolnych na każdej bazie danych. PUNKT KONTROLNY operacja zapisuje brudne strony (bieżące zmodyfikowane strony w pamięci), a także zapisuje szczegóły dotyczące dziennika transakcji.
SQL Server obsługuje cztery typy punktów kontrolnych:
1. Automatyczne — Ten typ punktów kontrolnych występuje w tle i zależy od konfiguracji serwera interwału odzyskiwania. Wartość mierzona jest w minutach, a domyślna wartość to 1 minuta (nie można ustawić niższej). Punkt kontrolny zakończy się w czasie, który zminimalizuje wpływ na wydajność.
EXEC sp_configure 'recovery interval', 'seconds'
W modelu odzyskiwania SIMPLE, automatyczny punkt kontrolny jest również uruchamiany, gdy dziennik transakcji jest zapełniony w 70%.
2. Pośrednie — Ten typ punktów kontrolnych występuje również w tle, zgodnie z ustawieniami czasu odzyskiwania bazy danych określonymi przez użytkownika. Począwszy od SQL Server 2016 CTP2 domyślną wartością dla tego typu punktu kontrolnego jest 1 minuta. Oznacza to, że baza danych będzie korzystać z pośrednich punktów kontrolnych. Dla starszych wersji SQL Server domyślną wartością jest 0. Oznacza to, że baza danych będzie używać automatycznych punktów kontrolnych, których częstotliwość zależy od ustawienia interwału odzyskiwania instancji SQL Server. Microsoft zaleca 1 minutę dla większości systemów.
ALTER DATABASE … SET TARGET_RECOVERY_TIME =
target_recovery_time { SECONDS | MINUTES }
Podczas ustawiania należy wziąć pod uwagę możliwości podstawowego podsystemu we/wy. Może mieć sens ustawienie niższej wartości dla szybszych podsystemów we/wy (np. SSD). Uważaj, to ustawienie utrzymuje się podczas tworzenia kopii zapasowej i przywracania, więc przywracanie na wolniejszym sprzęcie może powodować problemy z wydajnością spowodowane zbyt dużym obciążeniem we/wy.
3. Ręczny — Występuje podczas wykonywania polecenia T-SQL CHECKPOINT.
CHECKPOINT [ checkpoint_duration ]
czas trwania punktu kontrolnego to liczba całkowita używana do określenia czasu, w którym punkt kontrolny powinien się zakończyć. Ten parametr określa również, ile zasobów jest przypisanych do operacji w punkcie kontrolnym. Jeśli parametr nie zostanie określony, punkt kontrolny zakończy się w czasie, który minimalizuje wpływ na wydajność.
4. Wewnętrzny — Niektóre operacje programu SQL Server wystawiają tego typu punkty kontrolne, aby zapewnić zgodność obrazów dysków z bieżącym stanem dziennika transakcji. Są to punkty kontrolne, które są wykonywane, gdy ma miejsce określona operacja:
- Plik danych został dodany lub usunięty
- Następuje zamknięcie bazy danych (z jakiegokolwiek powodu)
- Utworzono kopię zapasową lub migawkę bazy danych
- Uruchamiane jest polecenie DBCC, które tworzy ukrytą migawkę bazy danych (lub np. DBCC_CHECKDB, DBCC_CHECKTABLE).
Dlaczego punkty kontrolne są przydatne?
Punkty kontrolne skracają czas odzyskiwania po awarii. Dzieje się tak, ponieważ strony pliku danych nie są zapisywane na dysku w tym samym czasie, co zapisy dziennika. W pamięci znajdują się strony plików danych, które są bardziej aktualne niż strony plików danych na dysku.
Punkty kontrolne redukują operacje we/wy na dysku i poprawiają wydajność. Powodem, dla którego strony pliku danych nie są zapisywane na dysku w momencie zatwierdzania transakcji, jest zmniejszenie liczby operacji we/wy. Wyobraź sobie kilka tysięcy transakcji UPDATE na jednej stronie danych. Bardziej efektywne jest zapisanie strony danych na dysku tylko raz, podczas punktu kontrolnego, niż po każdej zmianie.
Czyste i brudne strony
Pula buforów utrzymuje w pamięci pewną liczbę stron danych. Istnieją dwa rodzaje stron danych:czyste i brudne . Czysta strona to taka, która nie została zmieniona od czasu ostatniego odczytu z dysku lub zapisu na dysku. Brudna strona to strona, która została zmieniona, a zmiany nie zostały zapisane na dysku. Punkty kontrolne odnoszą się do „brudnych stron”.
Informacje o stronie można zobaczyć za pomocą sys.dm_os_buffer_descriptors . Zobaczmy, co zwraca ta funkcja:
SELECT * FROM sys.dm_os_buffer_descriptors dobd; GO
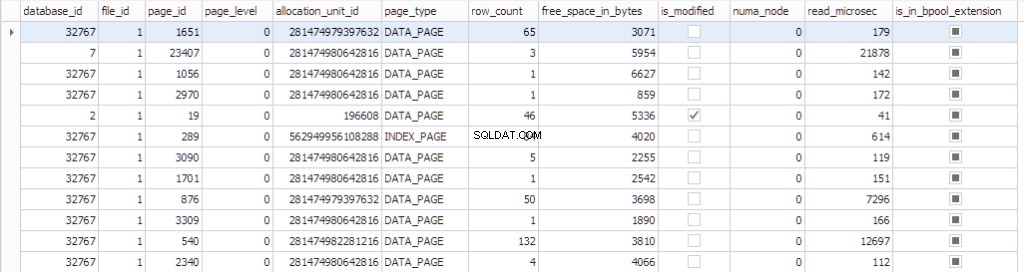
Każda strona ma powiązaną z nią strukturę kontrolną, która śledzi stan strony:
- Baza danych, która ma datdabase_id 32767 to baza danych zasobów tylko do odczytu, która zawiera wszystkie obiekty systemowe.
- identyfikator_pliku , identyfikator strony , allocation_unit_id ta strona należy.
- Co to za strona:strona danych lub strona indeksu.
- Liczba wierszy na stronie.
- Wolne miejsce na stronie
- Czy strona jest brudna, czy nie
- Numa_node, do którego należy dana strona
- Niektóre informacje na temat ostatnio używanego algorytmu
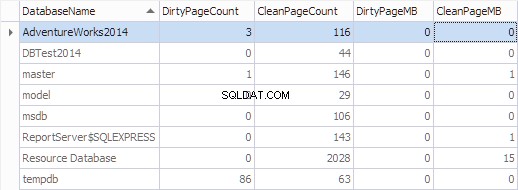
Zbierzmy te informacje według bazy danych, używając następującego kodu:
SELECT
*,
[DirtyPageCount] * 8 / 1024 AS [DirtyPageMB],
[CleanPageCount] * 8 / 1024 AS [CleanPageMB]
FROM (SELECT
(CASE
WHEN ([database_id] = 32767) THEN N'Resource Database'
ELSE DB_NAME([database_id])
END) AS [DatabaseName],
SUM(CASE
WHEN ([is_modified] = 1) THEN 1
ELSE 0
END) AS [DirtyPageCount],
SUM(CASE
WHEN ([is_modified] = 1) THEN 0
ELSE 1
END) AS [CleanPageCount]
FROM sys.dm_os_buffer_descriptors
GROUP BY [database_id]) AS [buffers]
ORDER BY [DatabaseName]
GO
Mechanizm punktów kontrolnych
Kiedy pojawia się punkt kontrolny, zapisuje wszystkie brudne strony na dysku. Strony oznaczone jako brudne po wprowadzeniu zmian. Nie ma znaczenia, czy transakcja, która wprowadziła zmianę, jest zatwierdzona czy niezatwierdzona w momencie punktu kontrolnego. Po zapisaniu stron na dysku bit „brudny” jest usuwany. Po pojawieniu się punktu kontrolnego wykonywane są następujące czynności:
- Nowy rekord dziennika wskazuje początek punktu kontrolnego
- Dodatkowe zapisy dziennika pojawiają się z informacjami o punkcie kontrolnym (takim jak stan dziennika transakcji w momencie uruchomienia punktu kontrolnego)
- Wszystkie brudne strony są zapisywane na dysku
- Oznacz LSN punktu kontrolnego na stronie startowej bazy danych (w dbi_checkptLSN), jest to krytyczne dla odzyskiwania po awarii
- Jeśli używany jest model odzyskiwania SIMPLE, spróbuj wyczyścić dziennik
- Ostateczny zapis dziennika wskazuje, że punkt kontrolny został zakończony
Możliwe jest równoległe występowanie punktów kontrolnych wielu baz danych. SQL Server 2000 był ograniczony do jednego punktu kontrolnego na raz. Gdy menedżer buforów zapisuje stronę, wyszukuje sąsiednie brudne strony, które można uwzględnić w pojedynczej operacji gromadzenia i zapisu. Ponadto pula buforów będzie próbowała upewnić się, że nie przeciąża podsystemu I/O. Śledzi, ile czasu zajmuje zakończenie operacji we/wy. Jeśli opóźnienie zapisu przekroczy 20 ms w punkcie kontrolnym, samoistnie się dławi. Podczas wyłączania próg dławienia wzrasta do 100 ms. Bardziej szczegółowe wyjaśnienie znajdziesz tutaj. Możesz użyć nieudokumentowanej opcji uruchamiania „-kXX”, aby ustawić szybkość we/wy punktu kontrolnego na XX MB/s.
Gdy strona pliku danych jest zapisywana na dysku przez punkt kontrolny, rejestrowanie z wyprzedzeniem gwarantuje, że wszystkie rekordy dziennika mające wpływ na tę stronę muszą zostać najpierw zapisane w dzienniku transakcji na dysku. Wszystkie rekordy dziennika, aż do ostatniego, który miał wpływ na stronę, są zapisywane, niezależnie od transakcji, w której są częścią. Zapisy dziennika są zapisywane na trzy sposoby:
- Kiedy jakakolwiek transakcja zostanie zatwierdzona lub przerwana
- Kiedy strona pliku danych jest zapisywana na dysku
- Kiedy blok dziennika osiągnie maksymalny rozmiar 60 KB i zostanie przymusowo zakończony
Zapis dziennika punktu kontrolnego
Punkty kontrolne zapisują wiele wpisów dziennika w dzienniku transakcji:
- LOP_BEGIN_CKPT — oznacza, że punkt kontrolny się rozpoczął
- LOP_XACT_CKPT z kontekstem NULL (tylko jeśli istnieją niezatwierdzone transakcje w momencie uruchomienia punktu kontrolnego) — zawiera liczbę niezatwierdzonych transakcji. Zawiera również listę LSN rekordów dziennika LOP_BEGIN_XACT niezatwierdzonych transakcji.
- LOP_BEGIN_CKPT z kontekstem LOP_BOOT_PAGE_CKPT (tylko SQL Server 2012) — oznacza, że strona startowa została zaktualizowana.
- LOP_END_CKPT — oznacza koniec punktu kontrolnego.
Monitorowanie punktów kontrolnych
Przydatne może być skorelowanie punktów kontrolnych występujących ze skokami we/wy, tak aby można było wprowadzić zmiany w określonej bazie danych (dla podsystemu we/wy) w celu złagodzenia skoku we/wy, jeśli przeciąży on podsystem we/wy. Na przykład wykonywanie częstszych, ręcznych punktów kontrolnych lub konfigurowanie niższego interwału odzyskiwania w programie SQL Server 2012 z pośrednimi punktami kontrolnymi. Spowoduje to bardziej stałe obciążenie we/wy bez wysokich skoków, które przeciążają podsystem we/wy. Jednak główną przyczyną może być większa liczba operacji we/wy z powodu jakiejś zmiany, więc nie akceptuj tylko nagłego wzrostu aktywności w punktach kontrolnych bez zbadania, dlaczego to nastąpiło.
Licznik Buffer Manager/Checkpoint pages/sec nie jest specyficzny dla bazy danych, więc określenie, która baza danych jest zaangażowana, wymaga flag śledzenia lub rozszerzonych zdarzeń.
Flaga śledzenia 3502 zapisuje w dzienniku błędów komunikaty dotyczące punktu kontrolnego bazy danych.
Flaga śledzenia 3504 zapisuje bardziej szczegółowe informacje o tym, ile stron zostało zapisanych i średnim czasie oczekiwania na zapis.
Te flagi śladowe są bezpieczne w produkcji dla ograniczonego wapna. Wszystko, co robią, to drukowanie komunikatów w dzienniku błędów.
Jeśli chcesz użyć rozszerzonych wydarzeń, możesz użyć dwóch wydarzeń:checkpoint_begin i checkpoint_end.
Podsumowanie
W tym artykule omówiliśmy punkty kontrolne w SQL Server — główny mechanizm zapisywania stron plików danych na dysk po ich zmianie.