SQL Server 2008 wprowadził rzadkie kolumny jako metodę zmniejszania ilości miejsca na wartości null i zapewniania bardziej rozszerzalnych schematów. Kompromis polega na tym, że istnieje dodatkowe obciążenie podczas przechowywania i pobierania wartości innych niż NULL. Po rozmowie z klientem, który używał tego typu danych w środowisku przejściowym, interesowało mnie zrozumienie kosztów przechowywania wartości innych niż NULL. Chcą zoptymalizować wydajność zapisu i zastanawiałem się, czy użycie rzadkich kolumn miało jakiś efekt, ponieważ ich metoda wymagała wstawienia wiersza do tabeli, a następnie jej aktualizacji. Stworzyłem wymyślony przykład dla tego demo, wyjaśniony poniżej, aby ustalić, czy jest to dobra metodologia dla nich.
Przegląd wewnętrzny
W ramach szybkiego przeglądu pamiętaj, że tworząc kolumnę dla tabeli, która dopuszcza wartości NULL, jeśli jest to kolumna o stałej długości (np. INT), zawsze zużyje całą szerokość kolumny na stronie, nawet jeśli kolumna jest ZERO. Jeśli jest to kolumna o zmiennej długości (np. VARCHAR), zużyje co najmniej dwa bajty w tablicy przesunięć kolumn, gdy NULL, chyba że kolumny są po ostatniej wypełnionej kolumnie (zobacz wpis na blogu Kimberly Kolejność kolumn nie ma znaczenia… ogólnie , ale – TO ZALEŻY). Rozrzedzona kolumna nie wymaga miejsca na stronie dla wartości NULL, niezależnie od tego, czy jest to kolumna o stałej długości, czy o zmiennej długości, i niezależnie od tego, jakie inne kolumny są wypełnione w tabeli. Kompromis polega na tym, że gdy kolumna rzadka jest zapełniona, zajmuje cztery (4) więcej bajtów pamięci niż kolumna nierzadka. Na przykład:
| Typ kolumny | Wymaganie dotyczące przechowywania |
|---|---|
| Kolumna BIGINT, nierzadka, z nie wartość | 8 bajtów |
| Kolumna BIGINT, nierzadka, z wartość | 8 bajtów |
| Kolumna BIGINT, rzadka, z nie wartość | 0 bajtów |
| Kolumna BIGINT, rzadka, z wartość | 12 bajtów |
Dlatego ważne jest, aby potwierdzić, że korzyści związane z przechowywaniem przewyższają potencjalny spadek wydajności związany z pobieraniem — który może być pomijalny na podstawie bilansu odczytów i zapisów z danymi. Szacunkowe oszczędności miejsca dla różnych typów danych są udokumentowane w linku Books Online podanym powyżej.
Scenariusze testowe
Skonfigurowałem cztery różne scenariusze testowania, opisane poniżej, a każda tabela miała kolumnę ID (INT), kolumnę Name (VARCHAR(100)) i kolumnę Type (INT), a następnie 997 kolumn NULLABLE.
| Identyfikator testu | Opis tabeli | Operacje DML |
|---|---|---|
| 1 | 997 kolumn typu danych INT, NULLABLE, non-sparse | Wstawiaj po jednym wierszu na raz, wypełniając identyfikator, nazwę, typ i dziesięć (10) losowych kolumn NULLABLE |
| 2 | 997 kolumn typu danych INT, NULLABLE, sparse | Wstawiaj po jednym wierszu na raz, wypełniając identyfikator, nazwę, typ i dziesięć (10) losowych kolumn NULLABLE |
| 3 | 997 kolumn typu danych INT, NULLABLE, non-sparse | Wstawiaj jeden wiersz na raz, wypełniając identyfikator, nazwę, tylko typ, a następnie zaktualizuj wiersz, dodając wartości dla dziesięciu (10) losowych kolumn NULLABLE |
| 4 | 997 kolumn typu danych INT, NULLABLE, sparse | Wstawiaj jeden wiersz na raz, wypełniając identyfikator, nazwę, tylko typ, a następnie zaktualizuj wiersz, dodając wartości dla dziesięciu (10) losowych kolumn NULLABLE |
| 5 | 997 kolumn typu danych VARCHAR, NULLABLE, nierozrzedzone | Wstawiaj po jednym wierszu na raz, wypełniając identyfikator, nazwę, typ i dziesięć (10) losowych kolumn NULLABLE |
| 6 | 997 kolumn typu danych VARCHAR, NULLABLE, sparse | Wstawiaj po jednym wierszu na raz, wypełniając identyfikator, nazwę, typ i dziesięć (10) losowych kolumn NULLABLE |
| 7 | 997 kolumn typu danych VARCHAR, NULLABLE, nierozrzedzone | Wstawiaj jeden wiersz na raz, wypełniając identyfikator, nazwę, tylko typ, a następnie zaktualizuj wiersz, dodając wartości dla dziesięciu (10) losowych kolumn NULLABLE |
| 8 | 997 kolumn typu danych VARCHAR, NULLABLE, sparse | Wstawiaj jeden wiersz na raz, wypełniając identyfikator, nazwę, tylko typ, a następnie zaktualizuj wiersz, dodając wartości dla dziesięciu (10) losowych kolumn NULLABLE |
Każdy test był uruchamiany dwukrotnie z zestawem danych składającym się z 10 milionów wierszy. Załączone skrypty mogą być użyte do powtórzenia testów, a kroki dla każdego testu były następujące:
- Utwórz nową bazę danych ze wstępnie dobranymi plikami danych i dzienników
- Utwórz odpowiednią tabelę
- Statystyki oczekiwania na migawkę i statystyki plików
- Zanotuj czas rozpoczęcia
- Wykonaj DML (jedna wstawka lub jedna wstawka i jedna aktualizacja) dla 10 milionów wierszy
- Zanotuj czas zatrzymania
- Statystyka oczekiwania na migawkę i statystyki plików oraz zapis do tabeli rejestrowania w oddzielnej bazie danych w osobnym miejscu
- Migawka dm_db_index_physical_stats
- Upuść bazę danych
Testy przeprowadzono na serwerze Dell PowerEdge R720 z 64 GB pamięci i 12 GB przydzielonymi do wystąpienia SQL Server 2014 SP1 CU4. Dyski SSD Fusion-IO były używane do przechowywania danych dla plików baz danych.
Wyniki
Wyniki testów przedstawiono poniżej dla każdego scenariusza testowego.
Czas trwania
We wszystkich przypadkach wypełnienie tabeli zajęło mniej czasu (średnio 11,6 minuty), gdy używane były rzadkie kolumny, nawet gdy wiersz został najpierw wstawiony, a następnie zaktualizowany. Gdy wiersz został po raz pierwszy wstawiony, a następnie zaktualizowany, wykonanie testu trwało prawie dwa razy dłużej niż po wstawieniu wiersza, ponieważ wykonano dwa razy więcej modyfikacji danych.
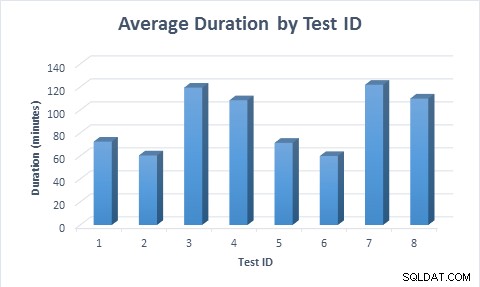 Średni czas trwania każdego scenariusza testowego
Średni czas trwania każdego scenariusza testowego
Statystyki oczekiwania
| Identyfikator testu | Średnia wartość procentowa | Średni czas oczekiwania (sekundy) |
|---|---|---|
| 1 | 16.47 | 0.0001 |
| 2 | 14.00 | 0.0001 |
| 3 | 16,65 | 0.0001 |
| 4 | 15.07 | 0.0001 |
| 5 | 12,80 | 0.0001 |
| 6 | 13,99 | 0.0001 |
| 7 | 14,85 | 0.0001 |
| 8 | 15.02 | 0.0001 |
Statystyki oczekiwania były zgodne dla wszystkich testów i na podstawie tych danych nie można wyciągnąć żadnych wniosków. Sprzęt wystarczająco spełnił wymagania dotyczące zasobów we wszystkich przypadkach testowych.
Statystyki plików
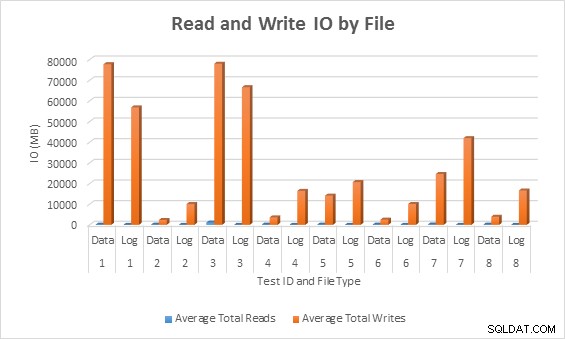 Średnia liczba operacji we/wy (odczyt i zapis) na plik bazy danych
Średnia liczba operacji we/wy (odczyt i zapis) na plik bazy danych
We wszystkich przypadkach testy z rzadkimi kolumnami generowały mniej IO (zwłaszcza zapisów) w porównaniu z nierzadkimi kolumnami.
Indeksuj statystyki fizyczne
| Przypadek testowy | Liczba wierszy | Całkowita liczba stron (indeks klastrowy) | Całkowita przestrzeń (GB) | Średnia przestrzeń używana dla stron liści w CI (%) | Średni rozmiar rekordu (w bajtach) |
|---|---|---|---|---|---|
| 1 | 10 000 000 | 10 037 312 | 76 | 51,70 | 4,184,49 |
| 2 | 10 000 000 | 301 429 | 2 | 98,51 | 237,50 |
| 3 | 10 000 000 | 10 037 312 | 76 | 51,70 | 4,184,50 |
| 4 | 10 000 000 | 460 960 | 3 | 64,41 | 237,50 |
| 5 | 10 000 000 | 1.823 083 | 13 | 90,31 | 1326,08 |
| 6 | 10 000 000 | 324 162 | 2 | 98,40 | 255.28 |
| 7 | 10 000 000 | 3 161 224 | 24 | 52.09 | 1326,39 |
| 8 | 10 000 000 | 503 592 | 3 | 63,33 | 255.28 |
Istnieją znaczne różnice w wykorzystaniu przestrzeni między tabelami nierzadkimi i rzadkimi. Jest to najbardziej godne uwagi, gdy spojrzymy na przypadki testowe 1 i 3, w których zastosowano typ danych o stałej długości (INT), w porównaniu z przypadkami testowymi 5 i 7, w których zastosowano typ danych o zmiennej długości (VARCHAR(255)). Kolumny liczb całkowitych zajmują miejsce na dysku, nawet jeśli mają wartość NULL. Kolumny o zmiennej długości zajmują mniej miejsca na dysku, ponieważ tylko dwa bajty są używane w tablicy przesunięć dla kolumn o wartości NULL i nie ma bajtów dla tych kolumn o wartości NULL, które znajdują się za ostatnią wypełnioną kolumną w wierszu.
Ponadto proces wstawiania wiersza, a następnie aktualizowania go powoduje fragmentację dla testu kolumny o zmiennej długości (przypadek 7), w porównaniu z prostym wstawianiem wiersza (przypadek 5). Rozmiar tabeli prawie się podwaja, gdy po wstawieniu następuje aktualizacja, z powodu podziałów stron, które występują podczas aktualizacji wierszy, co powoduje, że strony są w połowie pełne (w porównaniu do 90% pełnych).
Podsumowanie
Podsumowując, widzimy znaczne zmniejszenie miejsca na dysku i we/wy, gdy używane są kolumny rzadkie, i działają one nieco lepiej niż kolumny niesparse w naszych prostych testach modyfikacji danych (należy zwrócić uwagę, że należy również wziąć pod uwagę wydajność pobierania; być może temat innego post).
Rzadkie kolumny mają bardzo specyficzny scenariusz użycia i ważne jest, aby zbadać ilość zaoszczędzonego miejsca na dysku na podstawie typu danych dla kolumny i liczby kolumn, które będą zwykle wypełniane w tabeli. W naszym przykładzie mieliśmy 997 rzadkich kolumn i wypełniliśmy tylko 10 z nich. Co najwyżej w przypadku, gdy użyty typ danych był liczbą całkowitą, wiersz na poziomie liścia indeksu klastrowanego zużyłby 188 bajtów (4 bajty na identyfikator, 100 bajtów maksymalnie na nazwę, 4 bajty na typ, a następnie 80 bajtów na 10 kolumn). Gdy 997 kolumn nie było rozrzedzonych, wtedy 4 bajty były przydzielane dla każdej kolumny, nawet gdy NULL, więc każdy wiersz miał co najmniej 4000 bajtów na poziomie liścia. W naszym scenariuszu rzadkie kolumny są absolutnie dopuszczalne. Ale jeśli wypełnimy 500 lub więcej rzadkich kolumn wartościami dla kolumny INT, wówczas oszczędność miejsca zostanie utracona, a wydajność modyfikacji może nie być już lepsza.
W zależności od typu danych dla Twoich kolumn i oczekiwanej liczby kolumn, które mają być wypełnione w sumie, możesz chcieć przeprowadzić podobne testy, aby upewnić się, że w przypadku korzystania z rzadkich kolumn wydajność wstawiania i pamięć są porównywalne lub lepsze niż w przypadku korzystania z innych -rzadkie kolumny. W przypadkach, w których nie wszystkie kolumny są wypełnione, zdecydowanie warto rozważyć rzadkie kolumny.