Kilka tygodni temu pisałem o tym, jak bardzo byłem zaskoczony wydajnością nowej funkcji natywnej w SQL Server 2016, STRING_SPLIT() :
- Niespodzianki i założenia dotyczące wydajności:STRING_SPLIT()
Po opublikowaniu posta otrzymałem kilka komentarzy (publicznie i prywatnie) z tymi sugestiami (lub pytaniami, które zamieniłem w sugestie):
- Określenie jawnego typu danych wyjściowych dla podejścia JSON, aby ta metoda nie ucierpiała z powodu potencjalnego obciążenia wydajnością z powodu powrotu
nvarchar(max). - Testowanie nieco innego podejścia, w którym coś jest faktycznie robione z danymi — mianowicie
SELECT INTO #temp. - Pokazuje porównanie szacowanej liczby wierszy z istniejącymi metodami, szczególnie podczas zagnieżdżania operacji podziału.
Odpowiadałem niektórym osobom w trybie offline, ale pomyślałem, że warto opublikować dalsze informacje tutaj.
Bycie bardziej sprawiedliwym wobec JSON
Oryginalna funkcja JSON wyglądała tak, bez specyfikacji typu danych wyjściowych:
CREATE FUNCTION dbo.SplitStrings_JSON
...
RETURN (SELECT value FROM OPENJSON( CHAR(91) + @List + CHAR(93) )); Zmieniłem jego nazwę i utworzyłem jeszcze dwie, z następującymi definicjami:
CREATE FUNCTION dbo.SplitStrings_JSON_int
...
RETURN (SELECT value FROM OPENJSON( CHAR(91) + @List + CHAR(93) )
WITH ([value] int '$'));
GO
CREATE FUNCTION dbo.SplitStrings_JSON_varchar
...
RETURN (SELECT value FROM OPENJSON( CHAR(91) + @List + CHAR(93) )
WITH ([value] varchar(100) '$')); Myślałem, że to drastycznie poprawi wydajność, ale niestety tak nie było. Przeprowadziłem testy ponownie i wyniki były następujące:
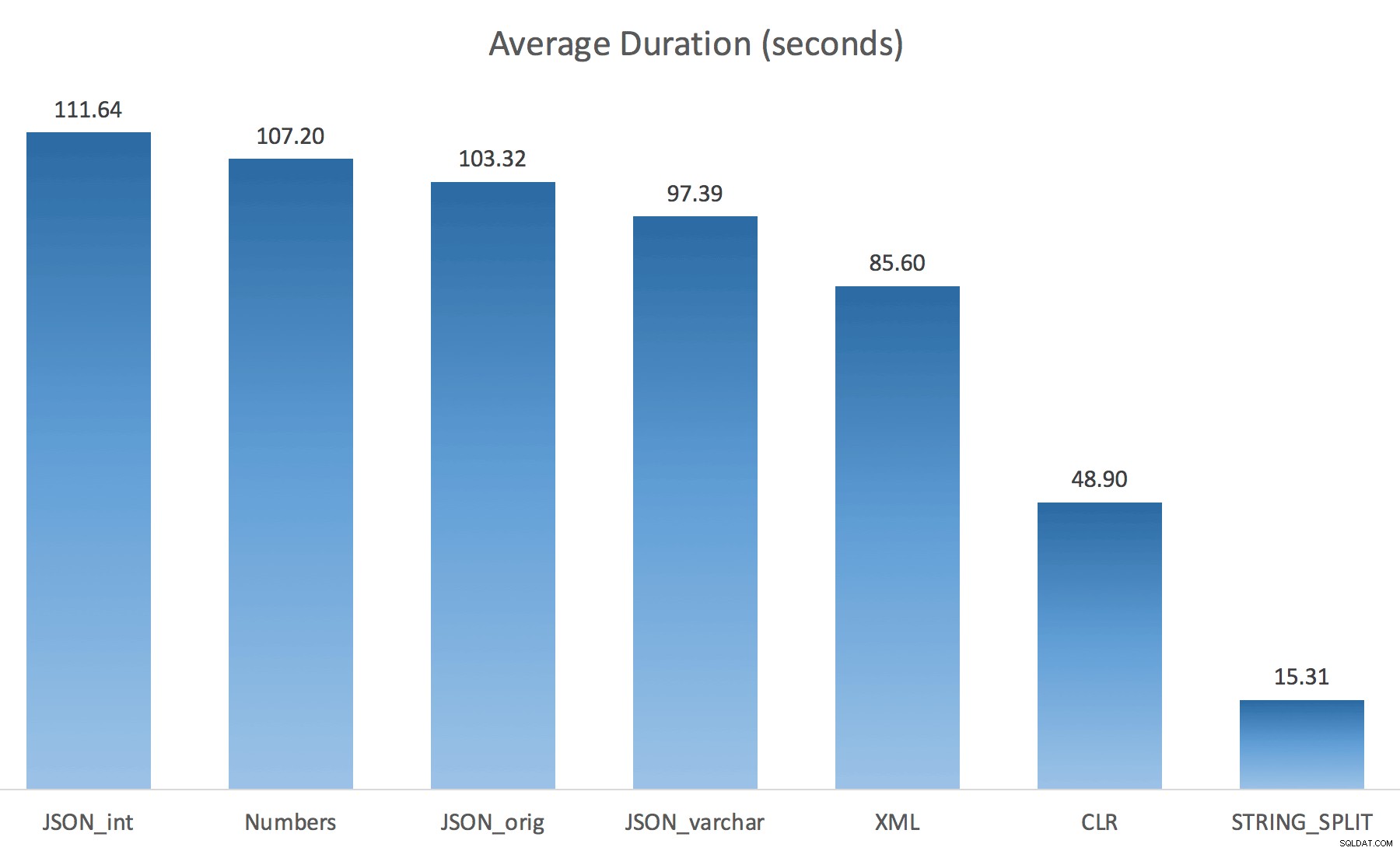
Oczekiwania zaobserwowane podczas losowej instancji testu (przefiltrowane do tych> 25):
| CLR | IO_COMPLETION | 1595 |
| SOS_SCHEDULER_YIELD | 76 | |
| RESERVED_MEMORY_ALLOCATION_EXT | 76 | |
| MEMORY_ALLOCATION_EXT | 28 | |
| JSON_int | MEMORY_ALLOCATION_EXT | 6294 |
| SOS_SCHEDULER_YIELD | 95 | |
| JSON_original | MEMORY_ALLOCATION_EXT | 4.307 |
| SOS_SCHEDULER_YIELD | 83 | |
| JSON_varchar | MEMORY_ALLOCATION_EXT | 6110 |
| SOS_SCHEDULER_YIELD | 87 | |
| Liczby | SOS_SCHEDULER_YIELD | 96 |
| XML | MEMORY_ALLOCATION_EXT | 1917 |
| IO_COMPLETION | 1616 | |
| SOS_SCHEDULER_YIELD | 147 | |
| RESERVED_MEMORY_ALLOCATION_EXT | 73 |
Zaobserwowano oczekiwanie> 25 (uwaga:nie ma wpisu dla STRING_SPLIT )
Podczas zmiany z domyślnego na varchar(100) poprawiło nieco wydajność, zysk był znikomy i zmienił się na int faktycznie to pogorszyło. Dodaj do tego, że prawdopodobnie musisz dodać STRING_ESCAPE() do przychodzącego ciągu w niektórych scenariuszach, na wypadek gdyby zawierały znaki, które mogą zepsuć przetwarzanie JSON. Mój wniosek jest nadal taki, że jest to fajny sposób na wykorzystanie nowej funkcjonalności JSON, ale przede wszystkim nowość nieodpowiednia do rozsądnej skali.
Materializacja wyniku
Jonathan Magnan dokonał tej wnikliwej obserwacji w moim poprzednim poście:
STRING_SPLIT jest rzeczywiście bardzo szybki, ale także powolny jak diabli podczas pracy z tabelą tymczasową (chyba że zostanie to naprawione w przyszłej kompilacji).SELECT f.value INTO #test FROM dbo.SourceTable AS s CROSS APPLY string_split(s.StringValue, ',') AS f
Będzie DUŻO wolniejsze niż rozwiązanie SQL CLR (15x i więcej!).
Stworzyłem więc kod, który wywoływał każdą z moich funkcji i wrzucał wyniki do tabeli #temp, a następnie mierzył czas:
SET NOCOUNT ON; SELECT N'SET NOCOUNT ON; TRUNCATE TABLE dbo.Timings; GO '; SELECT N'DECLARE @d DATETIME = SYSDATETIME(); INSERT dbo.Timings(dt, test, point, wait_type, wait_time_ms) SELECT @d, test = ''' + name + ''', point = ''Start'', wait_type, wait_time_ms FROM sys.dm_exec_session_wait_stats WHERE session_id = @@SPID; GO SELECT f.value INTO #test FROM dbo.SourceTable AS s CROSS APPLY dbo.'+name+'(s.StringValue, '','') AS f; GO DECLARE @d DATETIME = SYSDATETIME(); INSERT dbo.Timings(dt, test, point, wait_type, wait_time_ms) SELECT @d, '''+name+''', ''End'', wait_type, wait_time_ms FROM sys.dm_exec_session_wait_stats WHERE session_id = @@SPID; DROP TABLE #test; GO' FROM sys.objects WHERE name LIKE '%split%';
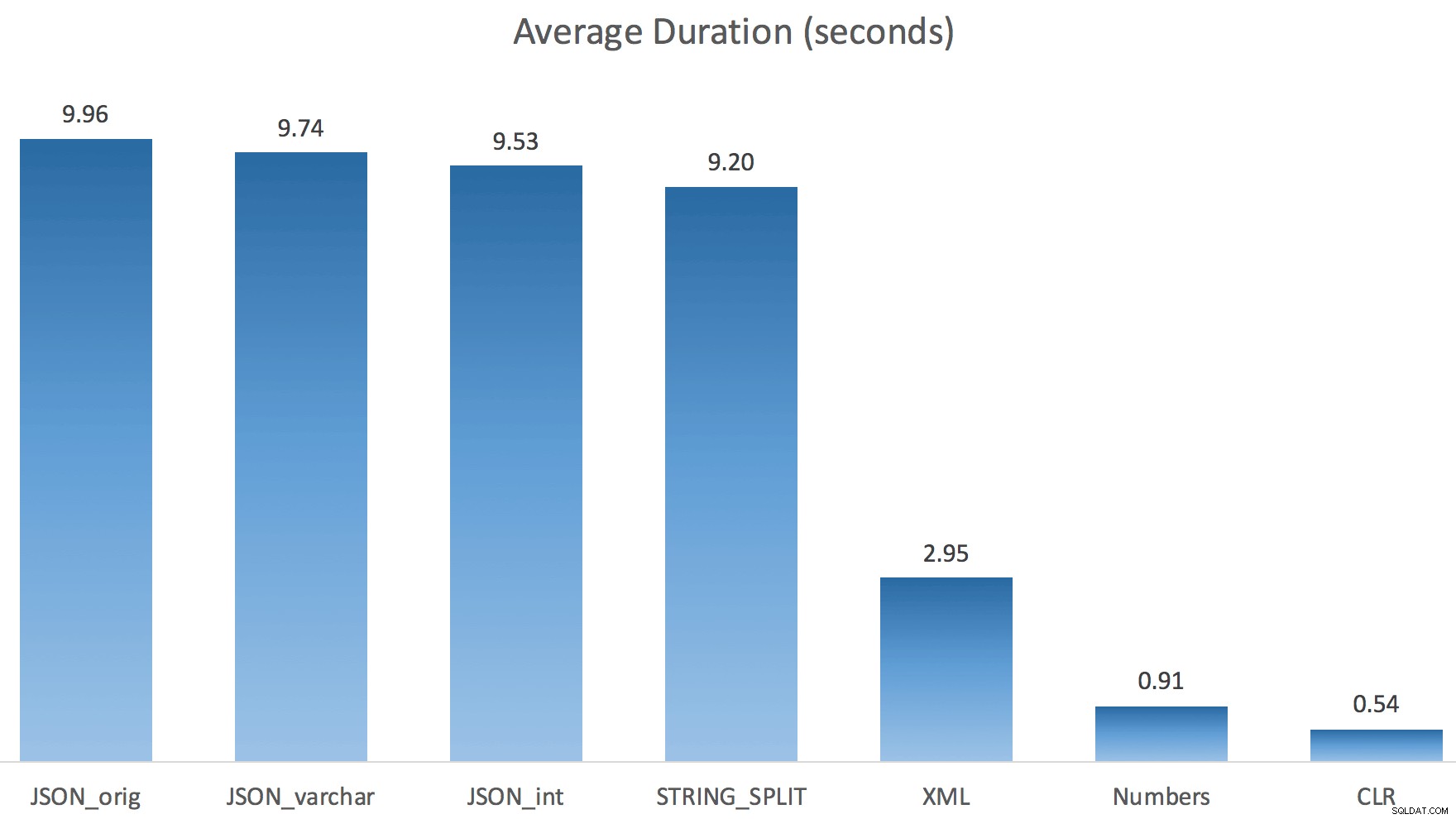
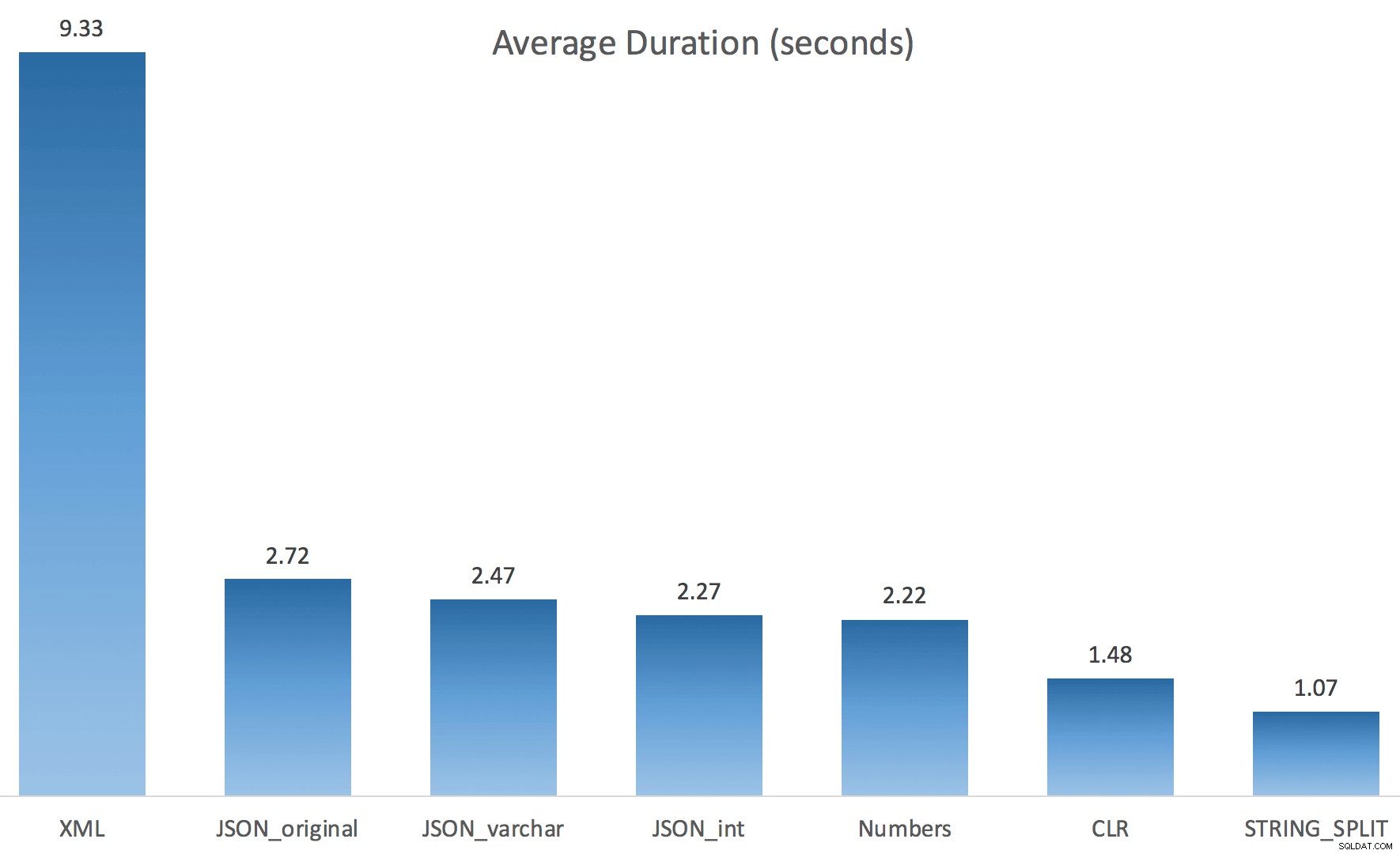
Po prostu uruchomiłem każdy test raz (zamiast pętli 100 razy), ponieważ nie chciałem całkowicie niszczyć I/O w moim systemie. Mimo to, po uśrednieniu trzech przebiegów testowych, Jonathan miał absolutną, stuprocentową rację. Oto czasy trwania wypełniania tabeli #temp ~500 000 wierszy przy użyciu każdej metody:
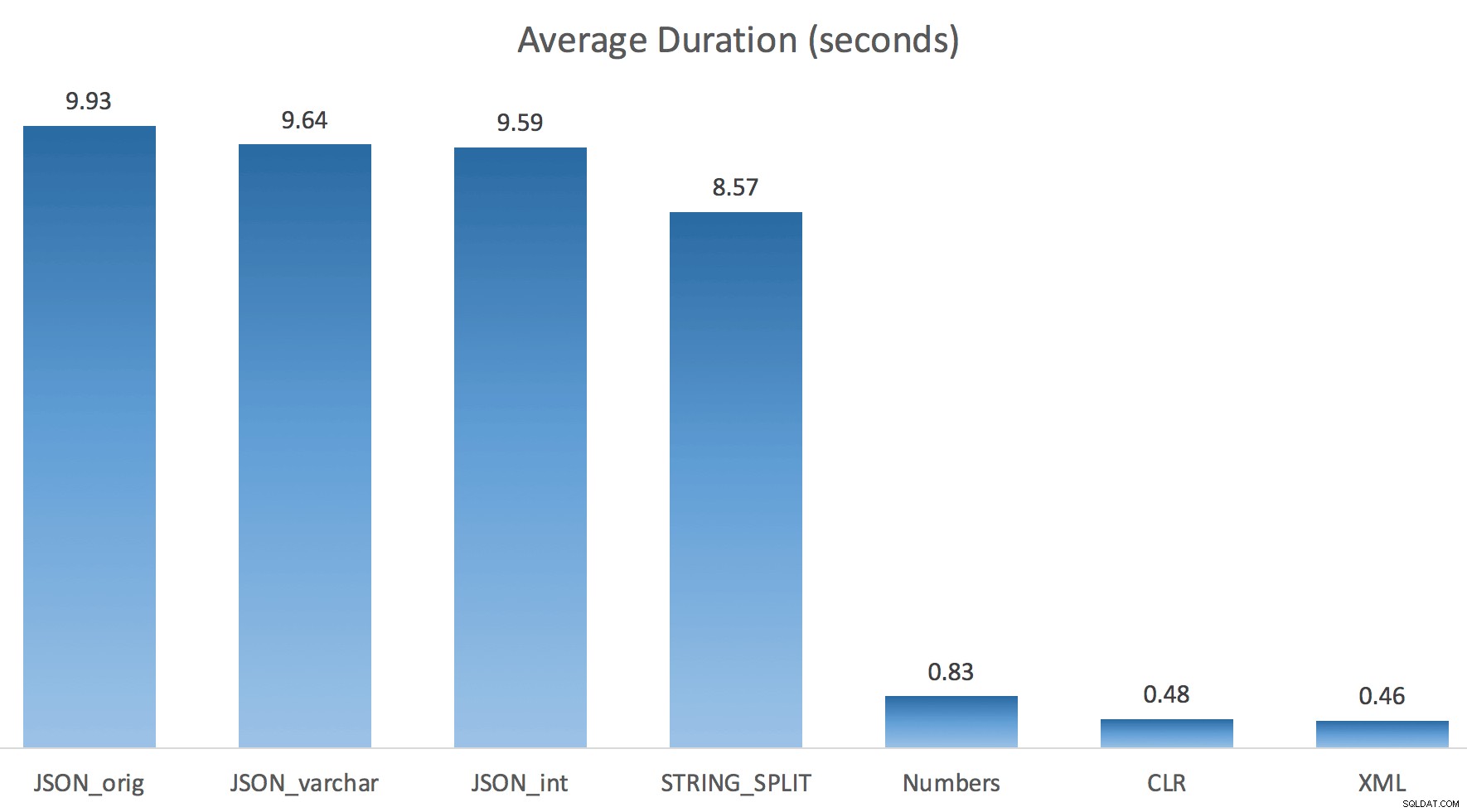
A więc tutaj JSON i STRING_SPLIT każda z metod zajęła około 10 sekund, podczas gdy metody dotyczące tabeli liczb, CLR i XML zajęły mniej niż sekundę. Zakłopotany zbadałem oczekiwania i rzeczywiście cztery metody po lewej stronie spowodowały znaczące LATCH_EX czekanie (około 25 sekund), którego nie widziano w pozostałych trzech, i nie było innych znaczących oczekiwań, o których można by mówić.
A ponieważ czas oczekiwania na zatrzask był dłuższy niż całkowity czas trwania, dało mi to wskazówkę, że ma to związek z równoległością (ta konkretna maszyna ma 4 rdzenie). Więc ponownie wygenerowałem kod testowy, zmieniając tylko jedną linię, aby zobaczyć, co by się stało bez równoległości:
CROSS APPLY dbo.'+name+'(s.StringValue, '','') AS f OPTION (MAXDOP 1);
Teraz STRING_SPLIT wypadło znacznie lepiej (podobnie jak metody JSON), ale wciąż co najmniej dwukrotnie dłuższe niż CLR:
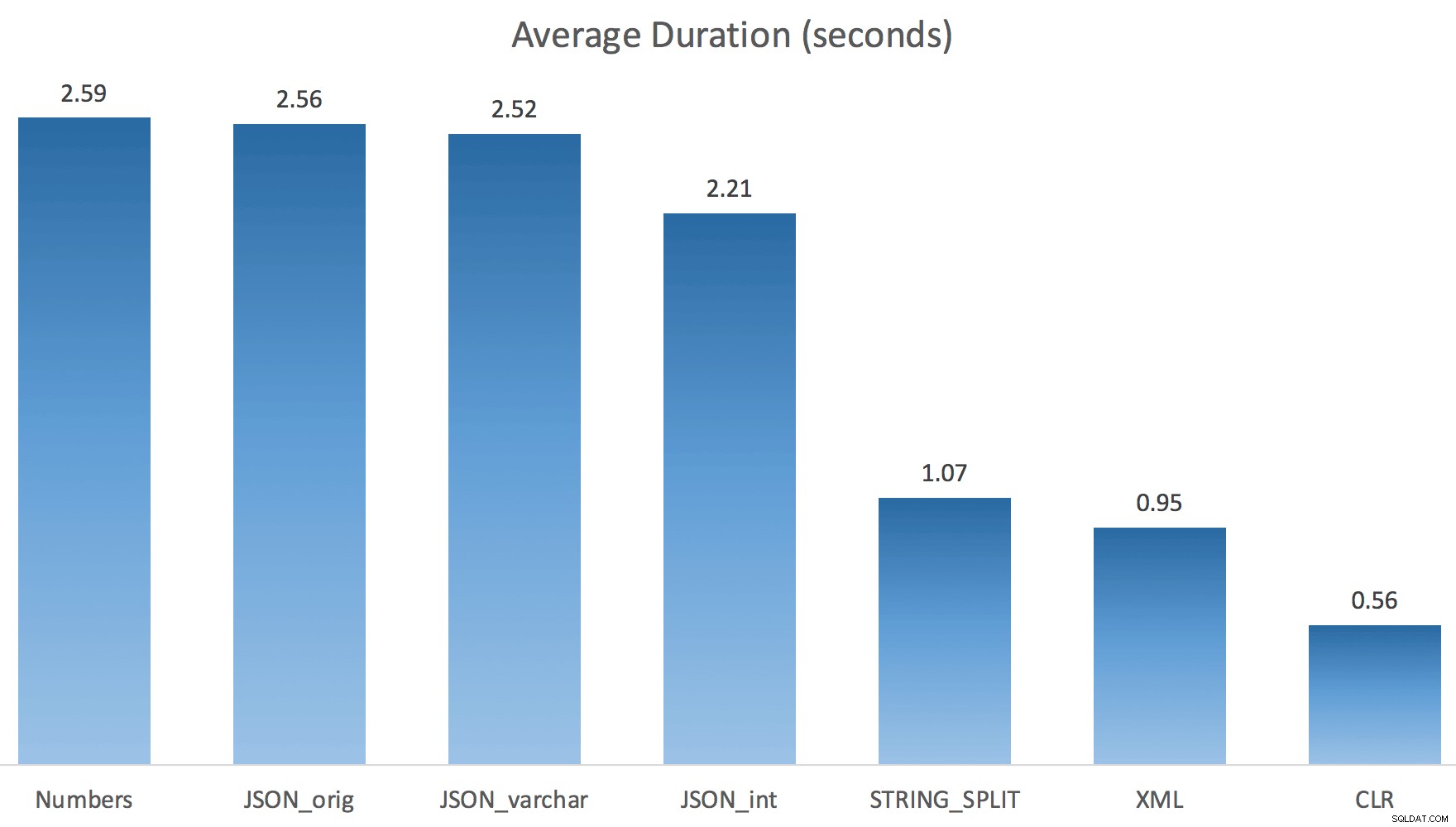
Tak więc może istnieć problem z tymi nowymi metodami, gdy w grę wchodzi równoległość. To nie był problem z dystrybucją wątków (sprawdziłem to), a CLR faktycznie miał gorsze szacunki (100x rzeczywiste vs. tylko 5x dla STRING_SPLIT ); tylko jakiś podstawowy problem z koordynacją zatrzasków między wątkami, jak przypuszczam. Na razie warto użyć MAXDOP 1 jeśli wiesz, że zapisujesz dane wyjściowe na nowych stronach.
Dołączyłem plany graficzne porównujące podejście CLR do natywnego, zarówno dla wykonywania równoległego, jak i szeregowego (przesłałem również plik analizy zapytań, który możesz otworzyć w SQL Sentry Plan Explorer, aby samodzielnie przeglądać):
STRING_SPLIT
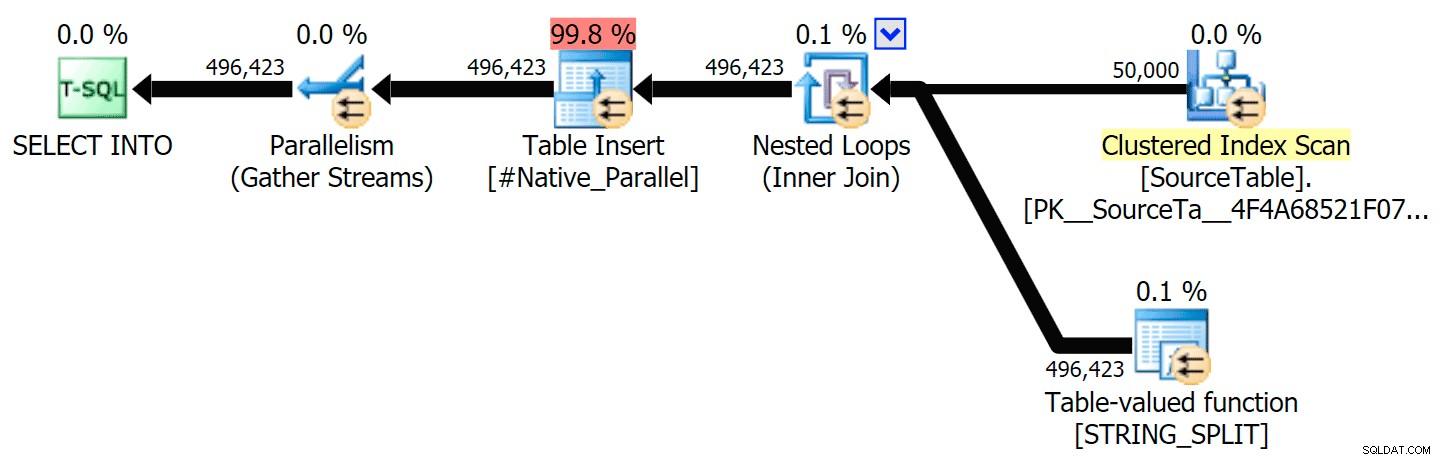
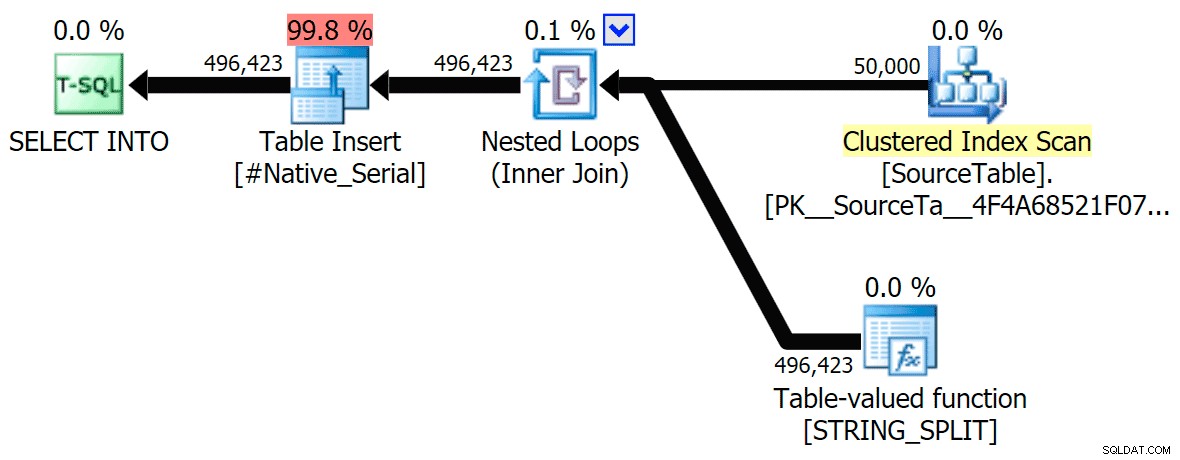
CLR
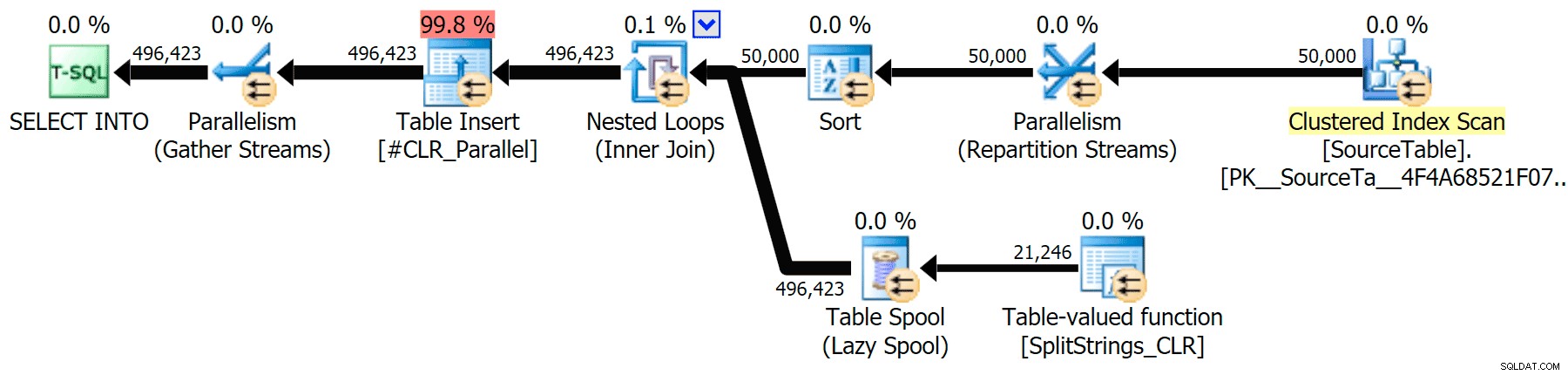
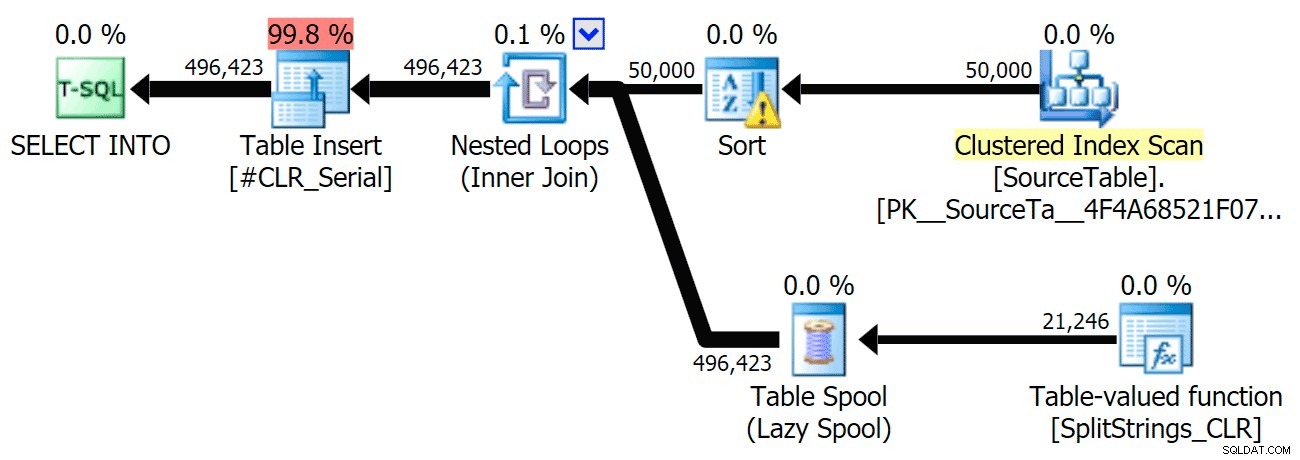
Ostrzeżenie o sortowaniu, FYI, nie było zbyt szokujące i oczywiście nie miało namacalnego wpływu na czas trwania zapytania:

- StringSplit.queryanalysis.zip (25kb)
Szpule na lato
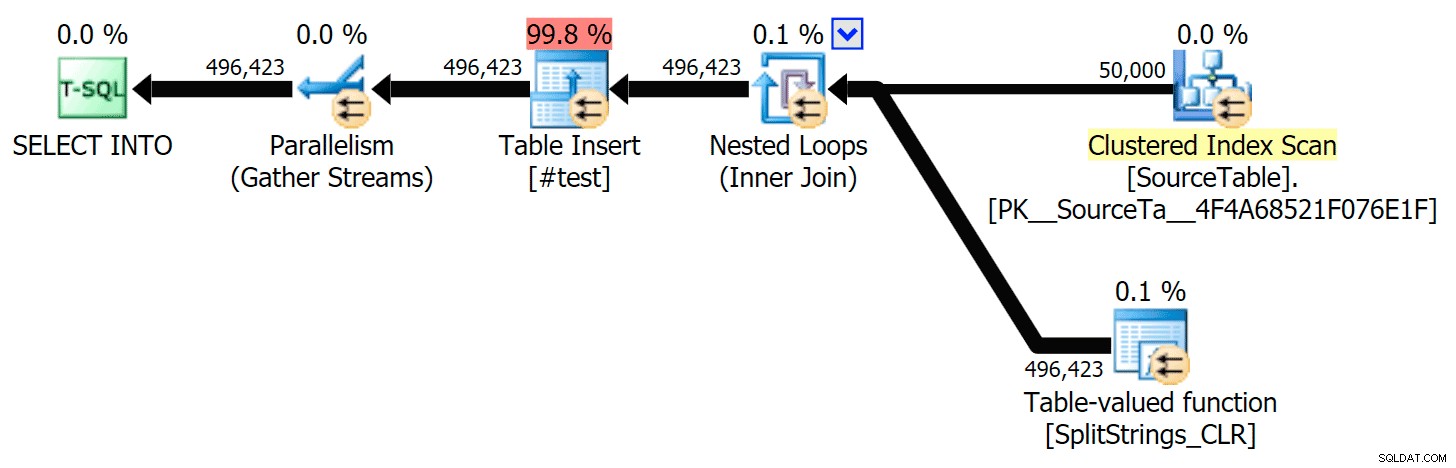
Kiedy przyjrzałem się nieco bliżej tym planom, zauważyłem, że w planie CLR jest leniwa szpula. Zostało to wprowadzone, aby upewnić się, że duplikaty są przetwarzane razem (aby zaoszczędzić pracę, wykonując mniej faktycznego podziału), ale ta szpula nie zawsze jest możliwa we wszystkich kształtach planu i może dać pewną przewagę tym, którzy mogą z niego korzystać ( np. plan CLR), w zależności od szacunków. Aby porównać bez buforowania, włączyłem flagę śledzenia 8690 i ponownie uruchomiłem testy. Po pierwsze, oto równoległy plan CLR bez bufora:
A oto nowe czasy trwania dla wszystkich zapytań działających równolegle z włączonym TF 8690:
Oto plan szeregowego CLR bez bufora:
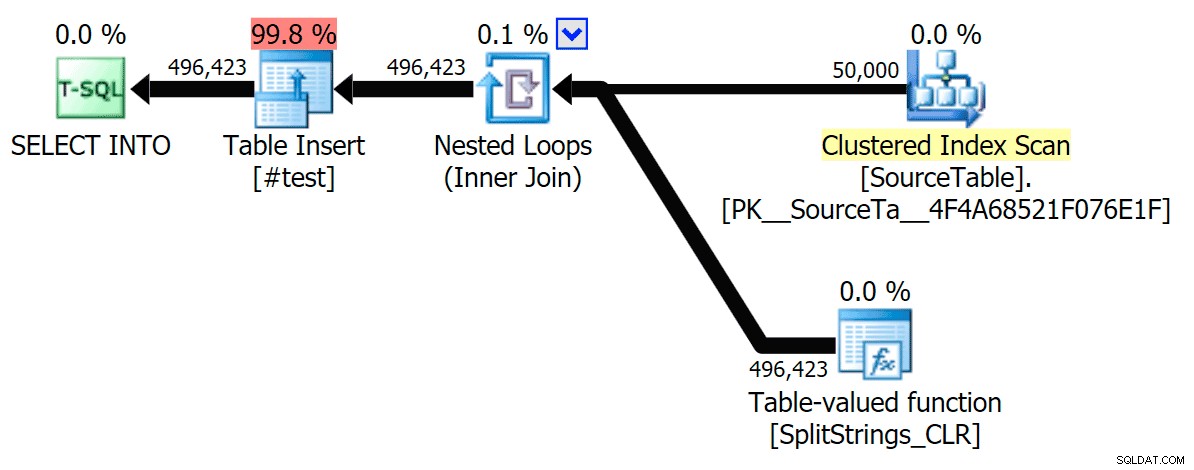
A oto wyniki czasowe dla zapytań używających zarówno TF 8690, jak i MAXDOP 1 :
(Zauważ, że poza planem XML większość pozostałych w ogóle się nie zmieniła, z flagą śledzenia lub bez niej).
Porównywanie szacowanej liczby wierszy
Dan Holmes zadał następujące pytanie:
Jak szacuje rozmiar danych po połączeniu z inną (lub wielokrotną) funkcją podziału? Poniższy link jest opisem implementacji podziału opartej na CLR. Czy 2016 robi „lepszą” pracę z szacunkami danych? (niestety nie mam jeszcze możliwości zainstalowania RC).https://sql.dnhlms.com/2016/02/sql-clr-based-string-splitting-and. html
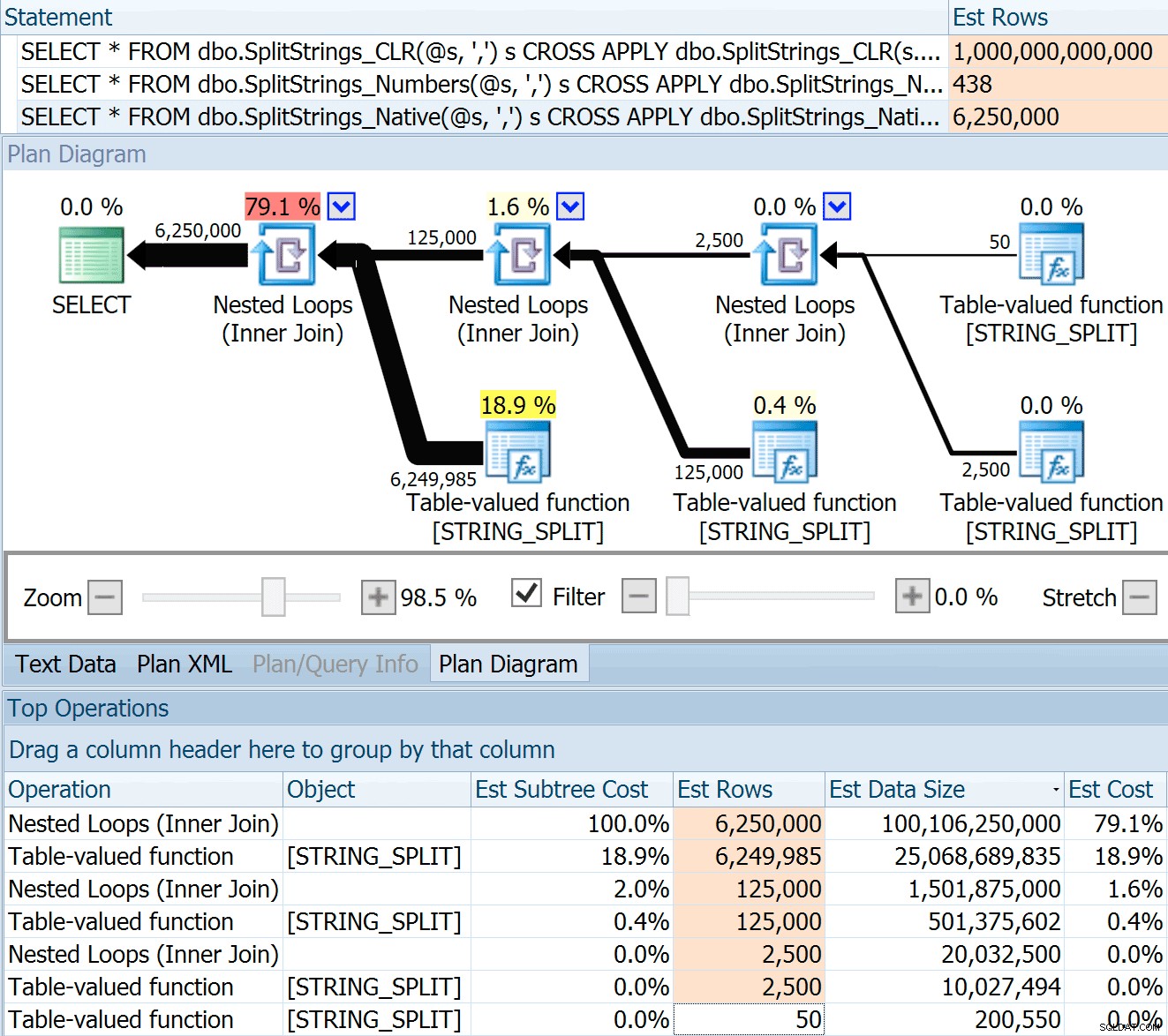
Więc przeciągnąłem kod z postu Dana, zmieniłem go tak, aby używał moich funkcji i uruchomiłem go w Eksploratorze planów:
DECLARE @s VARCHAR(MAX); SELECT * FROM dbo.SplitStrings_CLR(@s, ',') s CROSS APPLY dbo.SplitStrings_CLR(s.value, ';') s1 CROSS APPLY dbo.SplitStrings_CLR(s1.value, '!') s2 CROSS APPLY dbo.SplitStrings_CLR(s2.value, '#') s3; SELECT * FROM dbo.SplitStrings_Numbers(@s, ',') s CROSS APPLY dbo.SplitStrings_Numbers(s.value, ';') s1 CROSS APPLY dbo.SplitStrings_Numbers(s1.value, '!') s2 CROSS APPLY dbo.SplitStrings_Numbers(s2.value, '#') s3; SELECT * FROM dbo.SplitStrings_Native(@s, ',') s CROSS APPLY dbo.SplitStrings_Native(s.value, ';') s1 CROSS APPLY dbo.SplitStrings_Native(s1.value, '!') s2 CROSS APPLY dbo.SplitStrings_Native(s2.value, '#') s3;
SPLIT_STRING podejście z pewnością daje *lepsze* szacunki niż CLR, ale nadal rażąco skończone (w tym przypadku, gdy ciąg jest pusty; nie zawsze tak jest). Funkcja ma wbudowaną wartość domyślną, która szacuje, że przychodzący ciąg będzie miał 50 elementów, więc kiedy je zagnieżdżysz, otrzymasz 50 x 50 (2500); jeśli zagnieździsz je ponownie, 50 x 2500 (125 000); i wreszcie 50 x 125 000 (6 250 000):
Uwaga:OPENJSON() zachowuje się dokładnie tak samo jak STRING_SPLIT – zakłada również, że z dowolnej operacji podziału wyjdzie 50 wierszy. Myślę, że przydałby się sposób na wskazanie kardynalności dla takich funkcji, oprócz flag śledzenia, takich jak 4137 (przed 2014 r.), 9471 i 9472 (2014+) i oczywiście 9481…
Szacunek na 6,25 miliona wierszy nie jest świetny, ale jest znacznie lepszy niż podejście CLR, o którym mówił Dan, które szacuje BILILON WIERSZÓW , a straciłem liczenie przecinków do określenia rozmiaru danych – 16 petabajtów? eksabajty?
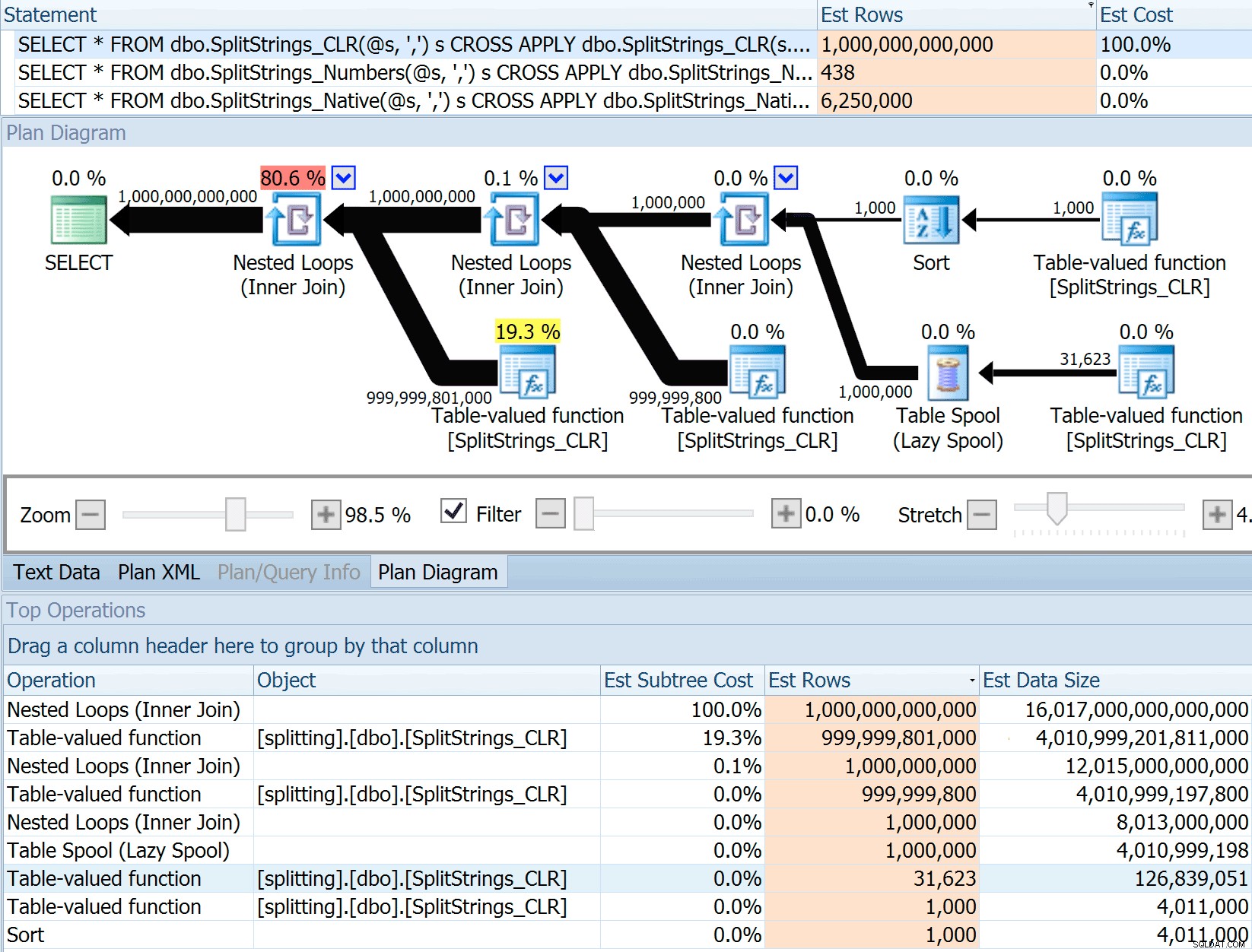
Niektóre inne podejścia ewidentnie wypadają lepiej pod względem szacunków. Na przykład tabela Numbers oszacowała o wiele bardziej rozsądne 438 wierszy (w SQL Server 2016 RC2). Skąd pochodzi ten numer? Cóż, w tabeli jest 8000 wierszy, a jeśli pamiętasz, funkcja ma zarówno predykat równości, jak i nierówności:
WHERE Number <= LEN(@List)
AND SUBSTRING(@Delimiter + @List, [Number], 1) = @Delimiter Zatem SQL Server mnoży liczbę wierszy w tabeli przez 10% (przypuszczalnie) dla filtru równości, a następnie pierwiastek kwadratowy 30% (ponownie, zgaduję) dla filtra nierówności. Pierwiastek kwadratowy wynika z wykładniczego odczekiwania, co wyjaśnia tutaj Paul White. To daje nam:
8000 * 0,1 * PIERWIASTEK (0,3) =438,178Wariant XML oszacowano na nieco ponad miliard wierszy (ze względu na bufor tabeli, który szacuje się na wykonanie 5,8 miliona razy), ale jego plan był zbyt złożony, aby próbować go tutaj zilustrować. W każdym razie pamiętaj, że szacunki wyraźnie nie mówią wszystkiego – tylko dlatego, że zapytanie ma dokładniejsze szacunki, nie oznacza, że będzie ono działać lepiej.
Istniało kilka innych sposobów, w jakie mogłem nieco poprawić oszacowania:mianowicie wymuszenie starego modelu szacowania kardynalności (który wpłynął zarówno na wariacje tabeli Liczb, jak i XML) oraz użycie TF 9471 i 9472 (co wpłynęło tylko na zmienność tabeli Liczb, ponieważ obaj kontrolują kardynalność wokół wielu predykatów). Oto sposoby, w jakie mogłem nieznacznie zmienić szacunki (lub DUŻO , w przypadku powrotu do starego modelu CE):

Stary model CE obniżył oszacowania XML o rząd wielkości, ale w przypadku tabeli Liczb całkowicie ją wysadził. Flagi predykatów zmieniły szacunki dla tabeli Liczb, ale te zmiany są znacznie mniej interesujące.
Żadna z tych flag śledzenia nie miała żadnego wpływu na szacunki dla CLR, JSON lub STRING_SPLIT odmiany.
Wniosek
Więc czego się tutaj nauczyłem? Właściwie cała masa:
- Równoległość może w niektórych przypadkach pomóc, ale kiedy nie pomaga, to naprawdę nie pomaga. Metody JSON były ~5x szybsze bez równoległości, a
STRING_SPLITbył prawie 10x szybszy. - Spool faktycznie pomógł podejściu CLR działać lepiej w tym przypadku, ale TF 8690 może być przydatny do eksperymentowania w innych przypadkach, w których widzisz spools i próbujesz poprawić wydajność. Jestem pewien, że są sytuacje, w których wyeliminowanie szpuli będzie ogólnie lepsze.
- Wyeliminowanie bufora naprawdę zaszkodziło podejściu XML (ale tylko drastycznie, gdy musiało być jednowątkowe).
- Wiele dziwnych rzeczy może się wydarzyć z oszacowaniami w zależności od podejścia, wraz ze zwykłymi statystykami, dystrybucją i flagami śledzenia. Cóż, przypuszczam, że już o tym wiedziałem, ale na pewno jest tu kilka dobrych, namacalnych przykładów.
Dziękuję osobom, które zadawały pytania lub nakłaniały mnie do podania dodatkowych informacji. I jak można się domyślić po tytule, w drugiej części odpowiedzi na kolejne pytanie, tym razem o TVP:
- STRING_SPLIT() w SQL Server 2016:kontynuacja nr 2