W dzisiejszych czasach często można zobaczyć dużą ilość danych w firmowej bazie danych, ale w zależności od wielkości może to być trudne do zarządzania, a wydajność może ulec pogorszeniu podczas dużego ruchu, jeśli nie skonfigurujemy lub zaimplementujemy go w prawidłowy sposób . Ogólnie rzecz biorąc, jeśli mamy ogromną bazę danych i chcemy mieć krótki czas odpowiedzi, będziemy chcieli ją skalować. PostgreSQL nie jest tu wyjątkiem. Dostępnych jest wiele podejść do skalowania PostgreSQL, ale najpierw dowiedzmy się, czym jest skalowanie.
Skalowalność jest właściwością systemu/bazy danych, która umożliwia obsługę rosnącej liczby wymagań poprzez dodawanie zasobów.
Przyczyny takiej ilości żądań mogą być tymczasowe, na przykład, jeśli wprowadzamy zniżkę na wyprzedaż, lub stałe, w celu zwiększenia liczby klientów lub pracowników. W każdym razie powinniśmy być w stanie dodawać lub usuwać zasoby, aby zarządzać tymi zmianami w zależności od zapotrzebowania lub wzrostu ruchu.
W tym blogu przyjrzymy się, jak możemy skalować naszą bazę danych PostgreSQL i kiedy musimy to zrobić.
Skalowanie w poziomie a skalowanie w pionie
Istnieją dwa główne sposoby skalowania naszej bazy danych...
- Skalowanie poziome (skalowanie w poziomie):jest wykonywane przez dodanie większej liczby węzłów bazy danych, tworząc lub zwiększając klaster bazy danych.
- Skalowanie w pionie (skalowanie w górę):jest wykonywane przez dodanie większej liczby zasobów sprzętowych (procesora, pamięci, dysku) do istniejącego węzła bazy danych.
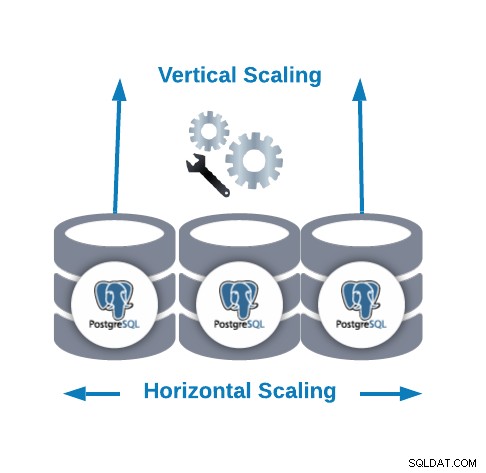
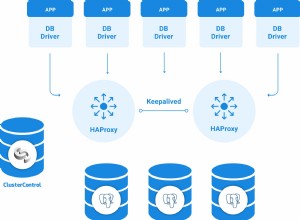
W przypadku skalowania poziomego możemy dodać więcej węzłów bazy danych jako węzłów podrzędnych. Pomoże nam to poprawić wydajność odczytu, równoważąc ruch między węzłami. W takim przypadku musimy dodać system równoważenia obciążenia, aby dystrybuować ruch do właściwego węzła w zależności od zasad i stanu węzła.
Aby uniknąć pojedynczego punktu awarii, dodając tylko jeden system równoważenia obciążenia, powinniśmy rozważyć dodanie dwóch lub więcej węzłów równoważenia obciążenia i użycie narzędzia, takiego jak „Keepalived”, aby zapewnić dostępność.
Ponieważ PostgreSQL nie ma natywnej obsługi wielu wzorców, jeśli chcemy ją zaimplementować w celu poprawy wydajności zapisu, do tego zadania będziemy potrzebować zewnętrznego narzędzia.
W przypadku skalowania pionowego może być konieczna zmiana niektórych parametrów konfiguracyjnych, aby umożliwić PostgreSQL korzystanie z nowego lub lepszego zasobu sprzętowego. Zobaczmy niektóre z tych parametrów z dokumentacji PostgreSQL.
- work_mem:Określa ilość pamięci, jaka ma być używana przez wewnętrzne operacje sortowania i tablice mieszające przed zapisaniem do tymczasowych plików dyskowych. Kilka uruchomionych sesji może wykonywać takie operacje jednocześnie, więc całkowita użyta pamięć może być wielokrotnie większa niż wartość work_mem.
- maintenance_work_mem:Określa maksymalną ilość pamięci, która ma być używana przez operacje konserwacyjne, takie jak VACUUM, CREATE INDEX i ALTER TABLE ADD FOREIGN KEY. Większe ustawienia mogą poprawić wydajność odkurzania i przywracania zrzutów bazy danych.
- autovacuum_work_mem:Określa maksymalną ilość pamięci, która ma być używana przez każdy proces roboczy autovacuum.
- autovacuum_max_workers:Określa maksymalną liczbę procesów autovacuum, które mogą być uruchomione jednocześnie.
- max_worker_processes:Ustawia maksymalną liczbę procesów w tle obsługiwanych przez system. Określ limit procesu, taki jak odkurzanie, punkty kontrolne i więcej prac konserwacyjnych.
- max_parallel_workers:Ustawia maksymalną liczbę pracowników obsługiwanych przez system dla operacji równoległych. Pracownicy równolegli są pobierani z puli procesów roboczych ustanowionych przez poprzedni parametr.
- max_parallel_maintenance_workers:Ustawia maksymalną liczbę równoległych procesów roboczych, które można uruchomić za pomocą pojedynczego polecenia narzędzia. Obecnie jedynym poleceniem narzędzia równoległego, które obsługuje użycie procesów roboczych równoległych, jest CREATE INDEX i to tylko podczas budowania indeksu B-drzewa.
- Effective_cache_size:Ustawia założenie planisty dotyczące efektywnego rozmiaru pamięci podręcznej dysku, która jest dostępna dla pojedynczego zapytania. Jest to uwzględniane w szacunkowych kosztach korzystania z indeksu; wyższa wartość sprawia, że bardziej prawdopodobne jest, że zostaną użyte skany indeksu, niższa wartość sprawia, że będzie bardziej prawdopodobne, że zostaną użyte skany sekwencyjne.
- shared_buffers:Ustawia ilość pamięci używanej przez serwer bazy danych na bufory pamięci współdzielonej. Aby uzyskać dobrą wydajność, zwykle potrzebne są ustawienia znacznie wyższe niż minimum.
- temp_buffers:Ustawia maksymalną liczbę tymczasowych buforów używanych przez każdą sesję bazy danych. Są to lokalne bufory sesji używane tylko do dostępu do tabel tymczasowych.
- Effective_io_concurrency:Ustawia liczbę jednoczesnych operacji dyskowych I/O, które według PostgreSQL mogą być wykonywane jednocześnie. Zwiększenie tej wartości zwiększy liczbę operacji I/O, które każda pojedyncza sesja PostgreSQL próbuje równolegle zainicjować. Obecnie to ustawienie wpływa tylko na skanowanie sterty bitmap.
- max_connections:Określa maksymalną liczbę jednoczesnych połączeń z serwerem bazy danych. Zwiększenie tego parametru pozwala PostgreSQL na jednoczesne uruchamianie większej liczby procesów backendowych.
W tym momencie musimy zadać pytanie. Skąd możemy wiedzieć, czy musimy skalować naszą bazę danych i skąd możemy wiedzieć, jak najlepiej to zrobić?
Monitorowanie
Skalowanie naszej bazy danych PostgreSQL to złożony proces, dlatego powinniśmy sprawdzić niektóre metryki, aby móc określić najlepszą strategię jej skalowania.
Możemy monitorować użycie procesora, pamięci i dysku, aby określić, czy jest jakiś problem z konfiguracją, czy rzeczywiście musimy skalować naszą bazę danych. Na przykład, jeśli widzimy duże obciążenie serwera, ale aktywność bazy danych jest niska, prawdopodobnie nie ma potrzeby jej skalowania, wystarczy sprawdzić parametry konfiguracyjne, aby dopasować je do naszych zasobów sprzętowych.
Sprawdzenie miejsca na dysku używanego przez węzeł PostgreSQL na bazę danych może nam pomóc w ustaleniu, czy potrzebujemy więcej dysku, a nawet partycjonowania tabeli. Aby sprawdzić miejsce na dysku używane przez bazę danych/tabele, możemy użyć funkcji PostgreSQL, takiej jak pg_database_size lub pg_table_size.
Od strony bazy danych powinniśmy sprawdzić
- Ilość połączenia
- Wykonywanie zapytań
- Użycie indeksu
- Wzdęcie
- Opóźnienie replikacji
Mogą to być jasne wskaźniki potwierdzające, czy skalowanie naszej bazy danych jest potrzebne.
ClusterControl jako system skalowania i monitorowania
ClusterControl może pomóc nam poradzić sobie z obydwoma sposobami skalowania, które widzieliśmy wcześniej, oraz monitorować wszystkie niezbędne metryki w celu potwierdzenia wymagania skalowania. Zobaczmy, jak...
Jeśli jeszcze nie korzystasz z ClusterControl, możesz go zainstalować i wdrożyć lub zaimportować aktualną bazę danych PostgreSQL, wybierając opcję „Importuj” i postępuj zgodnie z instrukcjami, aby skorzystać ze wszystkich funkcji ClusterControl, takich jak kopie zapasowe, automatyczne przełączanie awaryjne, alerty, monitorowanie, i nie tylko.
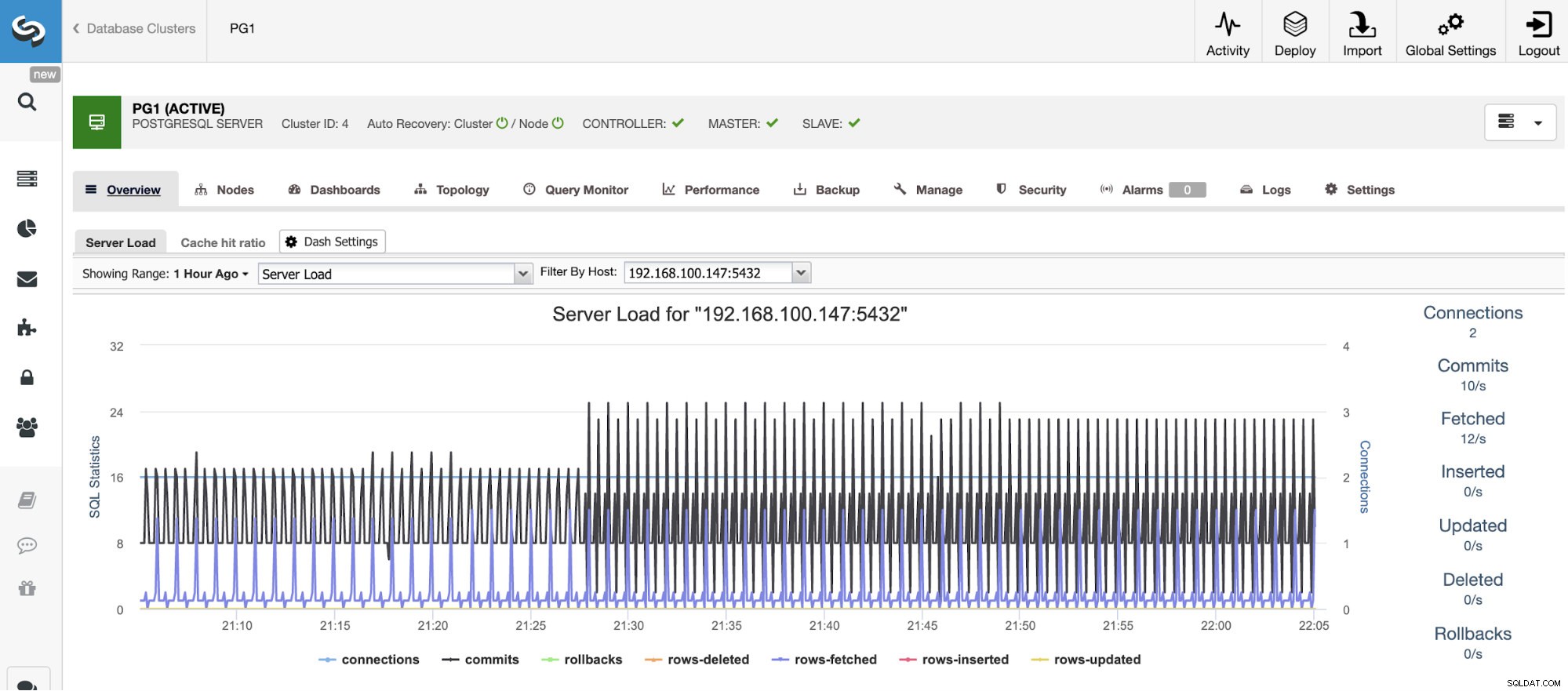
Skalowanie w poziomie
W przypadku skalowania poziomego, jeśli przejdziemy do działań klastrowych i wybierzemy „Dodaj moduł replikacji”, możemy albo utworzyć nową replikę od zera, albo dodać istniejącą bazę danych PostgreSQL jako replikę.
Zobaczmy, jak dodanie nowego urządzenia podrzędnego replikacji może być naprawdę łatwym zadaniem.
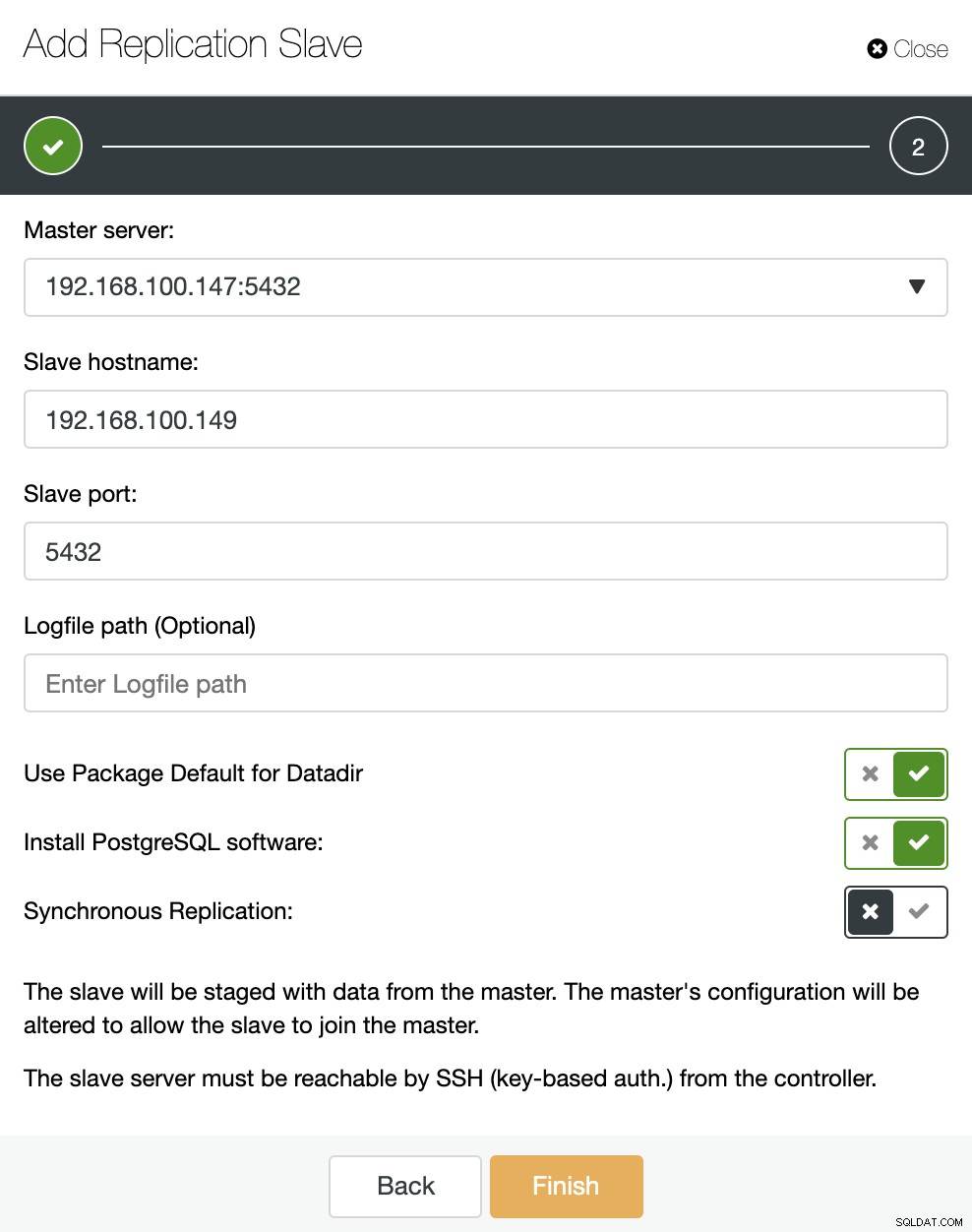
Jak widać na obrazku, wystarczy wybrać nasz serwer główny, wpisać adres IP naszego nowego serwera podrzędnego i port bazy danych. Następnie możemy wybrać, czy chcemy, aby ClusterControl zainstalował oprogramowanie za nas i czy urządzenie podrzędne replikacji powinno być synchroniczne czy asynchroniczne.
W ten sposób możemy dodać dowolną liczbę replik i rozłożyć między nimi ruch odczytu za pomocą load balancera, który możemy również zaimplementować za pomocą ClusterControl.
Teraz, jeśli przejdziemy do działań klastrowych i wybierzemy „Dodaj Load Balancer”, możemy wdrożyć nowy HAProxy Load Balancer lub dodać istniejący.
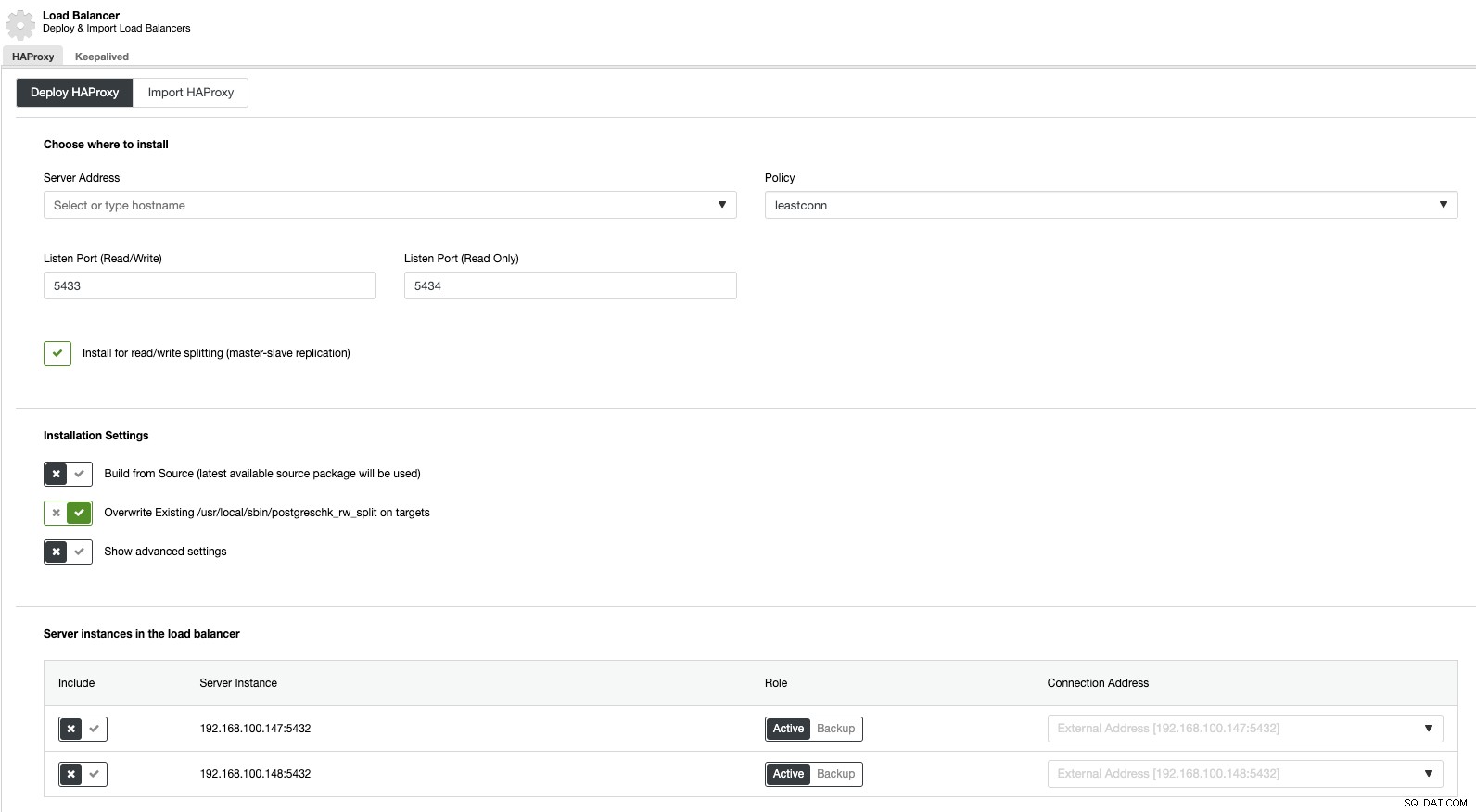
A następnie, w tej samej sekcji równoważenia obciążenia, możemy dodać usługę Keepalved działającą w węzłach równoważenia obciążenia, aby ulepszyć nasze środowisko wysokiej dostępności.
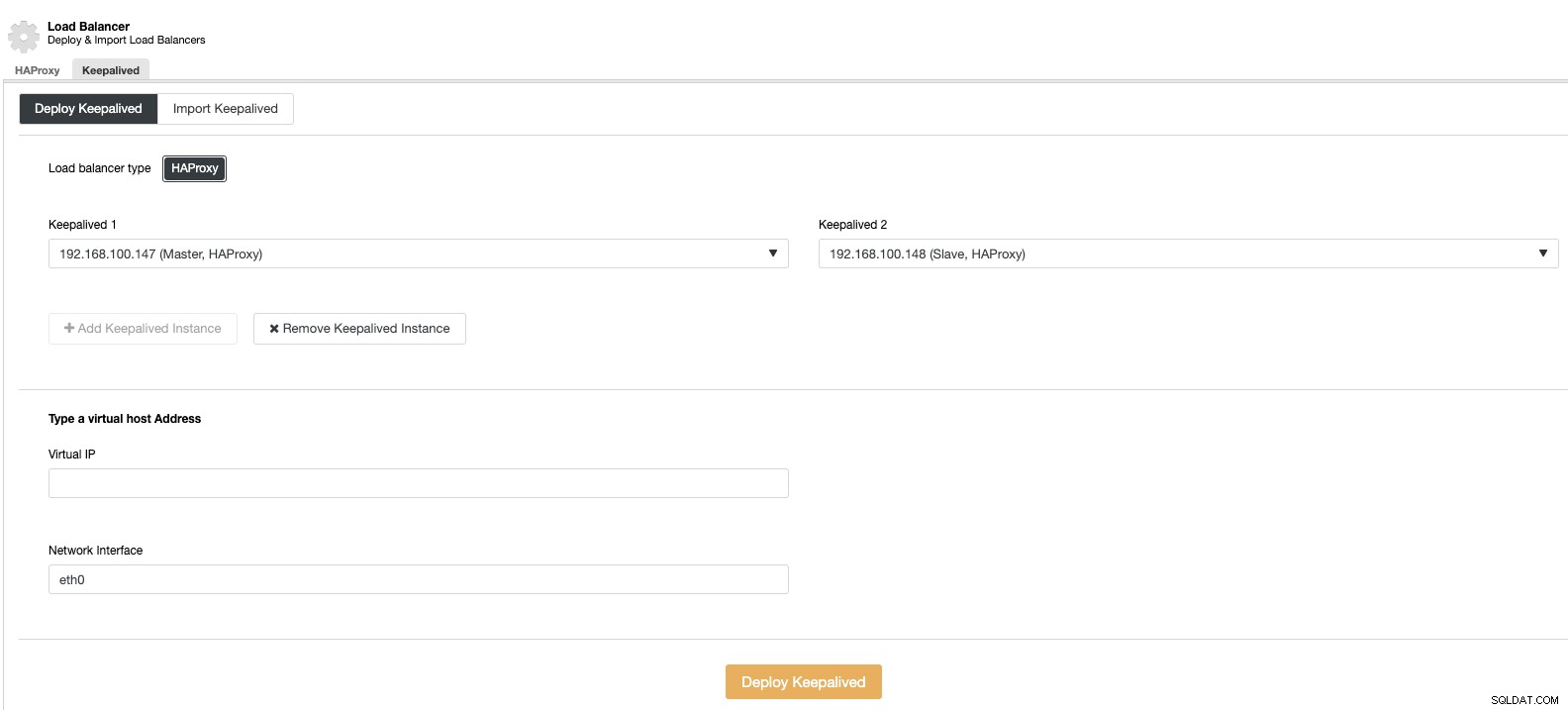
Skalowanie w pionie
W przypadku skalowania pionowego za pomocą ClusterControl możemy monitorować węzły naszej bazy danych zarówno od strony systemu operacyjnego, jak i bazy danych. Możemy sprawdzić niektóre metryki, takie jak użycie procesora, pamięć, połączenia, najpopularniejsze zapytania, uruchomione zapytania, a nawet więcej. Możemy również włączyć sekcję Pulpit nawigacyjny, która pozwala nam zobaczyć metryki w bardziej szczegółowy i przyjazny sposób.
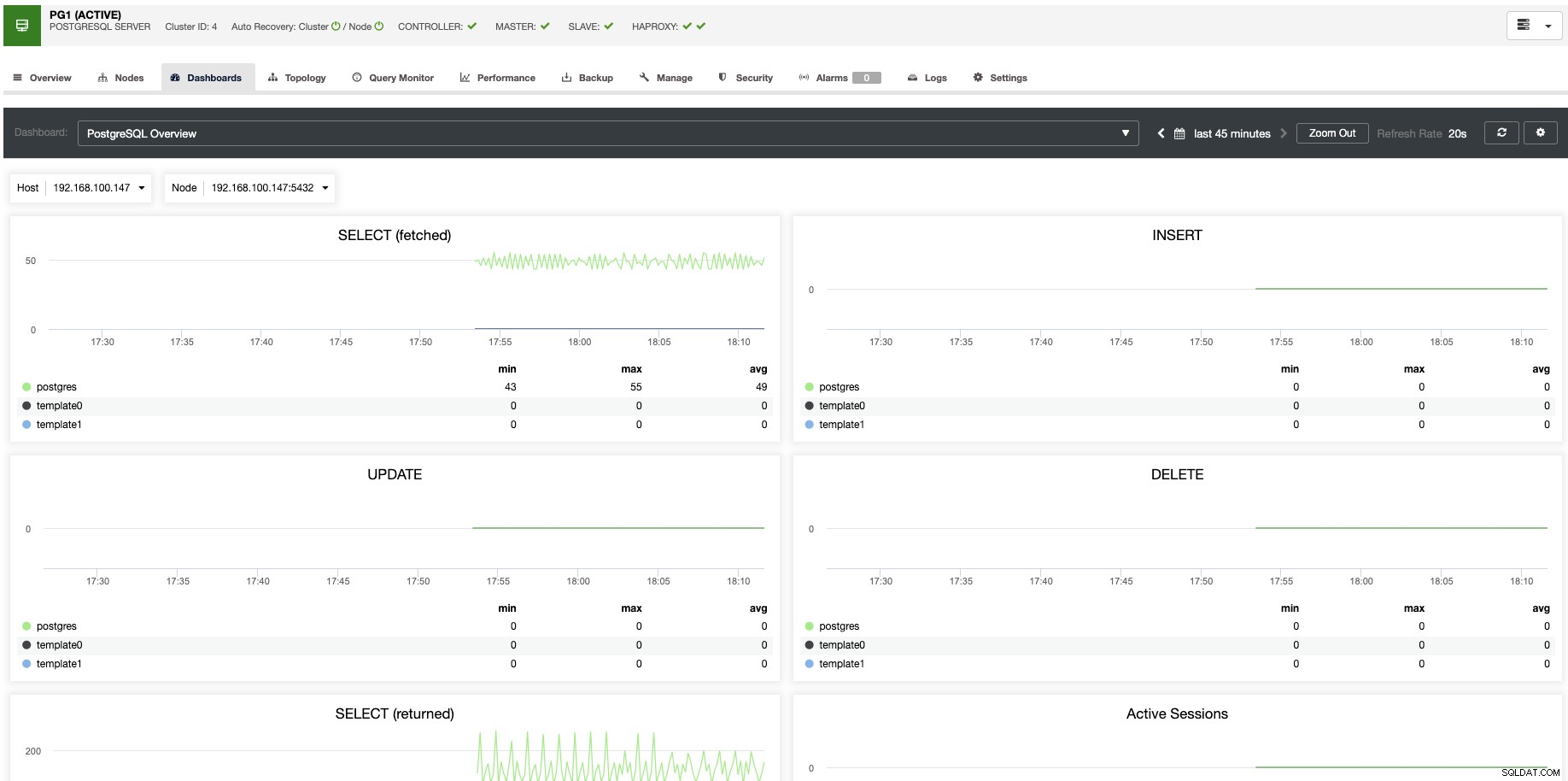
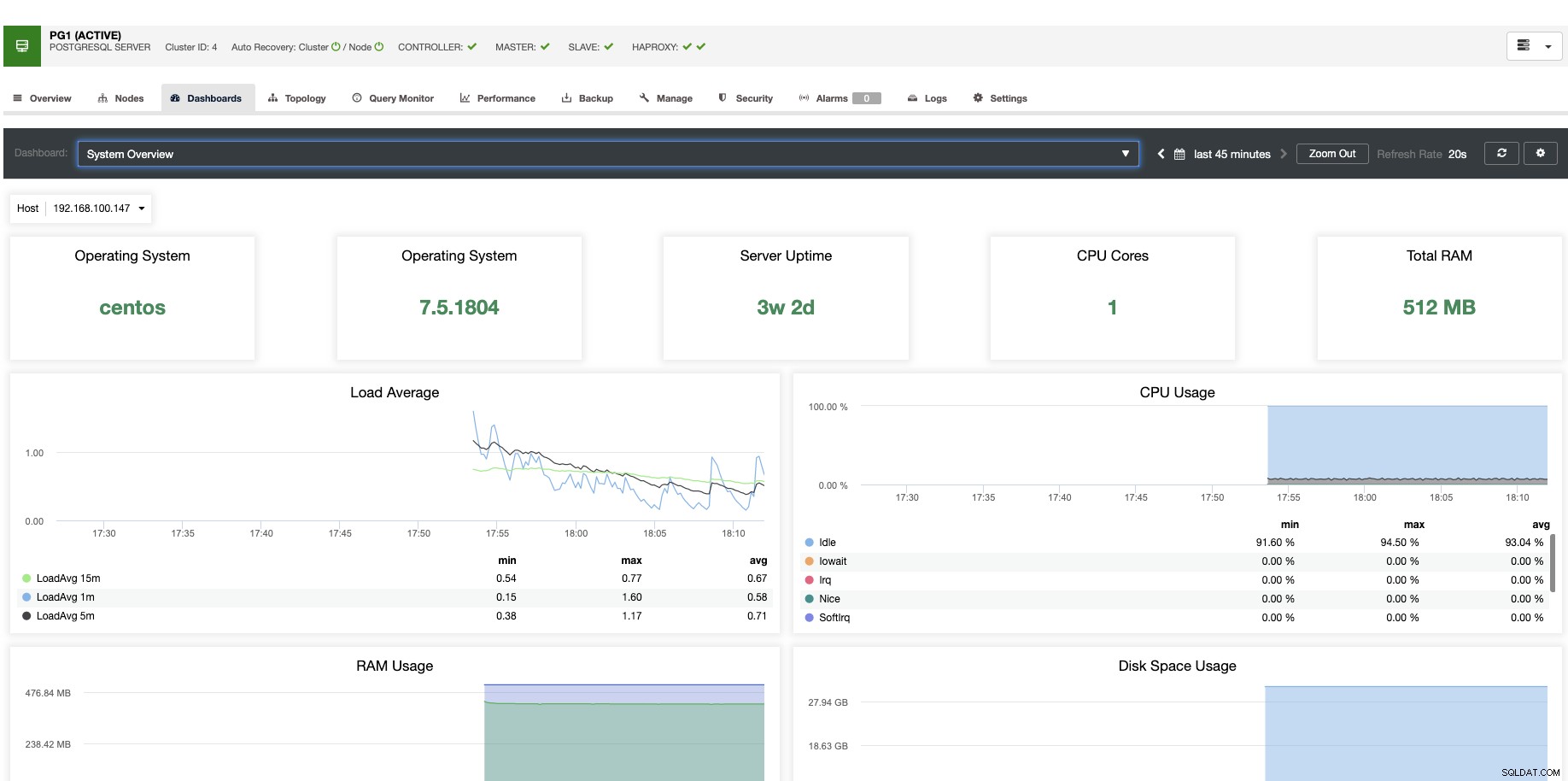
Z ClusterControl możesz również jednym kliknięciem wykonywać różne zadania zarządzania, takie jak Reboot Host, Rebuild Replication Slave lub Prome Slave.
Wniosek
Skalowanie baz danych PostgreSQL może być czasochłonnym zadaniem. Musimy wiedzieć, co musimy skalować i jaki jest najlepszy sposób, aby to zrobić. Ostatecznie ręczne zarządzanie i skalowanie klastrów staje się dość uciążliwe po pewnym momencie, więc większość korzysta z narzędzi takich jak nasze.
Jeśli wybierzesz trasę ręczną, sprawdź, kiedy rozważyć dodanie dodatkowego węzła do klastra. Chcesz uniknąć kłopotów? Oceń ClusterControl za darmo przez 30 dni, aby zobaczyć, jak jego funkcje sprawiają, że radzenie sobie z rozwiązaniami typu open source na dużą skalę jest proste i wydajne.
Niezależnie od tego, czy chcesz zarządzać swoimi bazami danych i je skalować, śledź nas na Twitterze lub LinkedIn albo subskrybuj nasz biuletyn, aby otrzymywać najnowsze wiadomości i najlepsze praktyki dotyczące zarządzania infrastrukturą baz danych opartą na otwartym kodzie źródłowym, a do zobaczenia wkrótce!