Ile czasu spędzasz na rozwiązywaniu problemów z wydajnością jako administrator bazy danych lub programista? Czy kiedykolwiek go śledziłeś? Jako średni całkowity procent twojego dnia, może to nie wyglądać na dużo czasu, ale gdy problem jest poważny, możesz spędzić godziny na śledzeniu go i analizowaniu przyczyn źródłowych. Czasami problem znika i nie znasz prawdziwego pochodzenia. A co gorsza? Kiedy musisz walczyć z tymi problemami w środku nocy lub w weekend. Nie tylko starasz się rozwiązać problem, ale także tracisz swój osobisty wolny czas. Jak to złagodzić? W jaki sposób usuwamy nasz czas i wysiłek z równania, jednocześnie poprawiając wydajność?
Funkcja automatycznego dostrajania w programie SQL Server 2017 Enterprise Edition i Azure SQL Database to pierwszy krok w skróceniu czasu, jaki specjaliści ds. danych poświęcają na rozwiązywanie problemów i rozwiązywanie problemów z wydajnością. Ta funkcja obejmuje automatyczną korektę planu i automatyczne zarządzanie indeksem (dostępne tylko w Azure SQL Database), które są włączane niezależnie. W tym poście chcę skupić się na funkcji automatycznej korekty planu. Dzięki automatycznej korekcji planu, jeśli SQL Server stwierdzi, że zapytanie uległo znacznej regresji, wymusi ustabilizowanie wydajności ostatniego znanego dobrego planu zapytania. Zasadniczo, zamiast Ciebie, DBA lub Dewelopera, dzwoniącego w weekend w sprawie wydajności systemu, SQL Server zajmie się tym za Ciebie. Brzmi zbyt łatwo, prawda? Rzućmy okiem.
Pod kołdrą
Po pierwsze, ważne jest, aby zrozumieć, że Automatyczna korekta planu korzysta z Query Store, więc musi być włączona dla bazy danych. Po drugie, automatyczna korekta planu to po prostu automatyczne wymuszanie planu. Chociaż Query Store jest sprzedawany jako rejestrator lotów dla Twojej bazy danych, który śledzi tekst zapytania, plany, statystyki czasu wykonywania i statystyki oczekiwania, umożliwia również wymuszenie planu dla zapytania, aby zapewnić stałą wydajność. Automatyczna korekta planu to wymuszenie planu bez Twojej interwencji.
Włączanie automatycznej korekty planu
Jak wspomniano, magazyn zapytań musi być najpierw włączony dla bazy danych użytkowników. Można to zrobić w SSMS, T-SQL i REST API dla Azure SQL DB. Pamiętaj, że magazyn zapytań jest domyślnie włączony dla baz danych na platformie Azure i działa od IV kw. 2016 r.
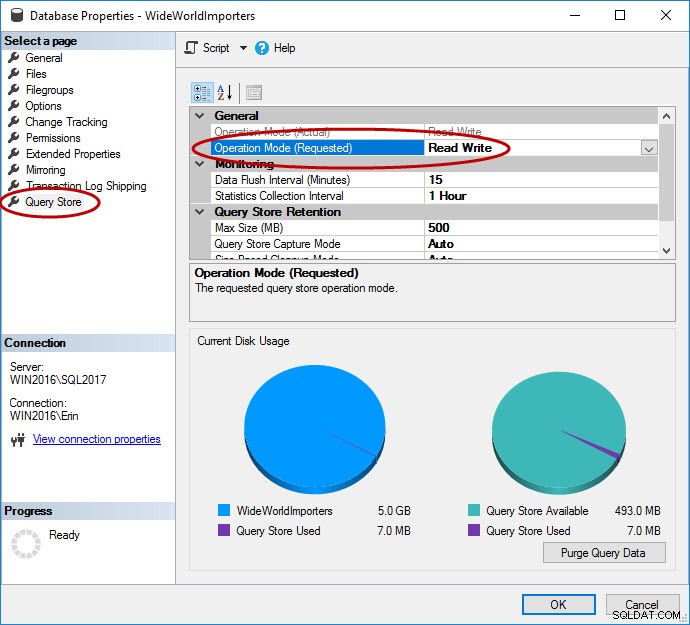
Włączanie przechowywania zapytań przez SSMS
USE [master]; GO ALTER DATABASE [WideWorldImporters] SET QUERY_STORE = ON; GO ALTER DATABASE [WideWorldImporters] SET QUERY_STORE (OPERATION_MODE = READ_WRITE); GO
Włączanie magazynu zapytań przy użyciu T-SQL
Powyższy kod jest domyślnym T-SQL z SSMS, jeśli go oskryptujesz. W Azure SQL Database nie uruchamiasz instrukcji USE. Jeśli chcesz zmienić którąkolwiek z domyślnych opcji, przeczytaj mój wpis Ustawienia magazynu zapytań na temat tych opcji i rozważań dotyczących wartości alternatywnych.
Po włączeniu Query Store możesz użyć Azure Portal, T-SQL lub EST API, aby włączyć automatyczną korektę planów w Azure SQL Database ((a C# i PowerShell są w toku). Można to włączyć tylko za pomocą T-SQL w SQL Server 2017.
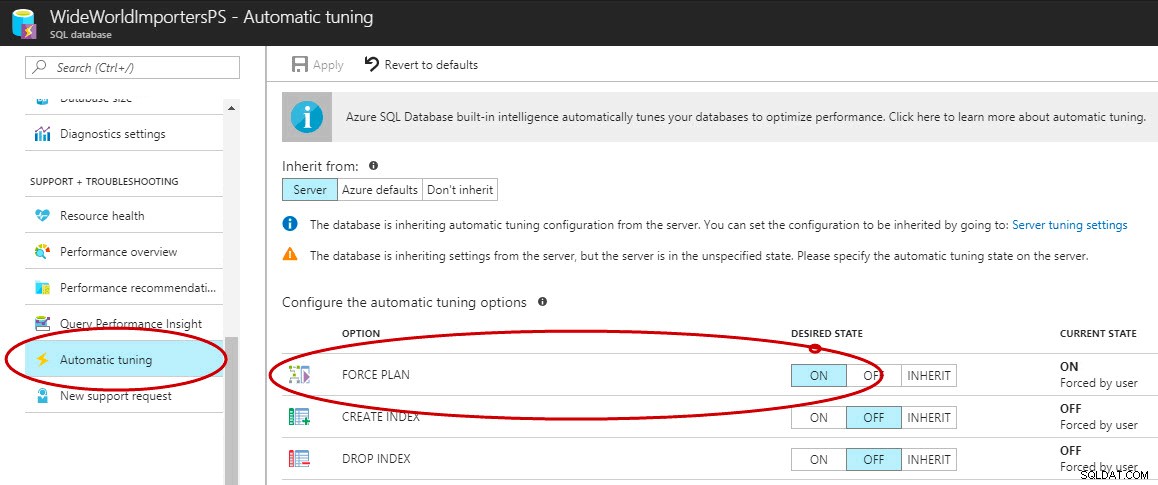
Włączanie automatycznej korekty planu w portalu Azure
ALTER DATABASE [WideWorldImporters] SET AUTOMATIC_TUNING ( FORCE_LAST_GOOD_PLAN = ON ); GO
Włączanie automatycznej korekty planów w T-SQL
Należy pamiętać, że w najbliższej przyszłości automatyczna korekta planu będzie domyślnie włączona dla nowych baz danych na platformie Azure. Od stycznia 2018 r. Automatyczne dostrajanie zostanie włączone dla baz danych Azure SQL, które jeszcze go nie miały, z powiadomieniami wysyłanymi do administratorów, aby w razie potrzeby można było wyłączyć tę opcję.
Jak to działa
Po włączeniu automatycznej korekty planu SQL Server monitoruje wydajność zapytań przy użyciu danych z magazynu zapytań. Poszukuje znaczącej zmiany* wydajności procesora** w 48-godzinnym oknie***. Zwróć uwagę na gwiazdki w tym zdaniu… są one celowe:
- *Próg określający istotną zmianę nie jest udokumentowany, ponieważ firma Microsoft zastrzega sobie prawo do jego zmiany.
- **Mierniki używane do określenia zmiany wydajności (CPU) nie są udokumentowane, ponieważ firma Microsoft zastrzega sobie prawo do ich zmiany. Oznacza to, że Microsoft może rozważyć dodatkowe wymiary, aby spojrzeć na wydajność, jeśli byłoby to lepsze / lepsze niż sam procesor.
- ***Okres czasu, w którym porównywane są dane dotyczące wydajności zapytania, nie został udokumentowany z tego samego powodu, firma Microsoft zastrzega sobie prawo do jego zmiany.
- Uwaga:chociaż wyżej wymienione elementy nie są udokumentowane, potwierdziłem odpowiednim osobom w firmie Microsoft, że te informacje mogą zostać udostępnione w przypadku złamania jakiejkolwiek umowy NDA. Niezwykle ważne jest, aby zrozumieć, że wartości nie są stałe i mogą się zmieniać, oczekując, że zmienią się w celu poprawy niezawodności funkcji.
Brak dokumentacji i możliwość zmiany progu mogą być frustrujące dla niektórych osób, ale oto, o czym naprawdę należy pamiętać:
Microsoft codziennie przechwytuje terabajty operacyjnych danych telemetrycznych z baz danych SQL Azure, a dane te mają kluczowe znaczenie dla opracowywanych funkcji automatycznych. Te dane obejmują takie elementy, jak query_id, query_plan_id i query_hash, a firma Microsoft NIE przechwytuje query_text ani query_plan (nie przeglądają rzeczywistych danych). Microsoft nie tylko archiwizuje dane operacyjne lub używa ich do rozwiązywania problemów, ale eksploruje te dane i wykorzystuje je do opracowywania algorytmów i modeli, aby umożliwić SQL Server podejmowanie niezależnych, inteligentnych decyzji.
SQL Server może korzystać z ogromnej ilości danych w Query Store, które szczegółowo opisują wydajność zapytań, a automatyczna korekta planu rozpoczyna się od porównania bieżącej wydajności zapytania z poprzednią wydajnością w celu określenia, czy wystąpiła regresja wydajności. Czy wydajność spadła lub pogorszyła się, a jeśli tak, to czy jest to znacząca wartość?
Jeśli nastąpił regres w wydajności zapytań, SQL Server wymusi ostatni znany dobry plan dla tego zapytania, który oczywiście jest pobierany z magazynu zapytań. Ale to nie koniec. SQL Server następnie kontynuuje monitorowanie wydajności — nadal używając Query Store — w celu potwierdzenia, że wymuszony plan jest nadal dobrym planem dla tego zapytania, co oznacza, że zapytanie z wymuszonym planem działa lepiej niż wersja z regresją. Jeśli to zapytanie nie działa lepiej, anuluje plan. Plan może również zostać cofnięty, jeśli nastąpi ponowna kompilacja lub jeśli wymuszenie się nie powiedzie.
Ten cykl trwa; jeśli zapytanie ma wymuszony plan, a następnie ten plan nie jest wymuszony z jednego z wyżej wymienionych powodów, ten sam plan może zostać wymuszony ponownie później lub może być wymuszony inny plan dla tego zapytania w późniejszym czasie. Jest to ciągły proces, który występuje tak długo, jak masz włączoną opcję automatycznej korekty planu dla bazy danych. Co ciekawe, możesz spojrzeć na te same informacje, które przechwytuje ta funkcja, i użyć ich ręcznie wymuszać plany. Oznacza to, że w SQL Server 2017 Enterprise Edition i Azure SQL Database dane te są gromadzone w DMV sys.dm_db_tuning_recommendations nawet wtedy, gdy funkcja automatycznej korekty planów nie jest włączona, dzięki czemu można zbadać te dane i postępować zgodnie z ich zaleceniami, aby wymusić plany dla konkretnych zapytań na własną rękę. Pamiętaj, że jeśli wymusisz plan za pomocą zaleceń z sys.dm_db_tuning_recommendations, nigdy nie zostanie on automatycznie cofnięty. Co więcej, jeśli masz włączoną automatyczną korektę planu i ręcznie wymuszasz plan, nigdy nie zostanie on automatycznie cofnięty. Tylko plany wymuszone funkcją automatycznej korekty planów zostaną automatycznie anulowane.
Czy naprawdę pozwolę, aby SQL Server przejął kontrolę?
Jeśli jesteś sceptyczny i zastanawiasz się, czy naprawdę możesz zaufać SQL Server w podejmowaniu decyzji wymuszających planowanie, oto, o czym zachęcam do zapamiętania:
- Ta funkcja została opracowana z oszałamiającą ilością danych przechwyconych z prawie dwóch milionów baz danych Azure SQL Database. Jest to nowa funkcja w SQL Server 2017, ale została udostępniona globalnie w 2016 roku na platformie Azure, więc ta funkcja jest naprawdę dostępna od ponad roku i została udoskonalona.
- Inżynierowie wprowadzili z czasem zmiany w algorytmie, ponieważ przechwycili więcej danych. Może nie znaleźć każdej regresji, która się pojawi – ponieważ regresja może nie być wystarczająco dotkliwa, ale założę się, że wielu z was wolałoby mieć tę cechę rzadziej niż zbyt często.
- Ponadto, jeśli plan jest wymuszony, ale kończy się problemem, możliwość odzyskania i wycofania planu przez SQL Server jest niezwykle niezawodna i odbywa się bardzo szybko.
Podsumowanie
Być może nie czujesz się komfortowo z pomysłem, aby SQL Server zajmował się za Ciebie problemami z wydajnością. Ale czy to dyskomfort, ponieważ uważasz, że to zła decyzja? A może obawiasz się, że automatyzacja przejmie Twoją pracę? Wiem, całkiem bezpośrednie pytanie. Jeśli to pierwsze, to moim zaleceniem jest przyjrzenie się danym przechwyconym w sys.dm_db_tuning_recommendations (bez włączania Automatycznej korekty planu) i zobaczenie, co SQL Server chciałby zrobić. Czy to zgadza się z tym, co byś zrobił? Czy znajduje regresje, które możesz przegapić? Jeśli nie chcesz włączać tej funkcji, ponieważ obawiasz się, że nagle nie będziesz mieć wystarczająco dużo do zrobienia, zachęcam do przeczytania najnowszego posta Conora Cunninghama Jak prędkość chmury pomaga administratorom baz danych SQL Server. Microsoft nie próbuje kodować Cię z pracy. Po prostu próbują poradzić sobie z nisko wiszącymi owocami, abyś mógł skupić się na ważniejszych zadaniach.