Skalarne UDF zawsze były mieczem obosiecznym — są świetne dla programistów, którzy potrafią wyabstrahować żmudną logikę zamiast powtarzać ją we wszystkich swoich zapytaniach, ale są straszne pod względem wydajności w środowisku produkcyjnym, ponieważ optymalizator nie ładnie sobie z nimi radzić. Zasadniczo dzieje się tak, że wykonania UDF są trzymane oddzielnie od reszty planu wykonania, dlatego są wywoływane raz dla każdego wiersza i nie można ich zoptymalizować na podstawie szacowanej lub rzeczywistej liczby wierszy ani złożyć do reszty planu.
Skoro pomimo naszych najlepszych starań od czasu SQL Server 2000, nie możemy skutecznie powstrzymać używania skalarnych UDF, czy nie byłoby wspaniale, gdyby SQL Server po prostu lepiej sobie z nimi radził?
W SQL Server 2019 wprowadzono nową funkcję o nazwie Skalarne podszycie UDF. Zamiast oddzielać funkcję, jest ona włączona do ogólnego planu. Prowadzi to do znacznie lepszego planu wykonania, a co za tym idzie, lepszej wydajności w czasie wykonywania.
Ale najpierw, aby lepiej zilustrować źródło problemu, zacznijmy od pary prostych tabel z zaledwie kilkoma wierszami w bazie danych działającej na SQL Server 2017 (lub na 2019, ale z niższym poziomem zgodności):
CREATE DATABASE Whatever; GO ALTER DATABASE Whatever SET COMPATIBILITY_LEVEL = 140; GO USE Whatever; GO CREATE TABLE dbo.Languages ( LanguageID int PRIMARY KEY, Name sysname ); CREATE TABLE dbo.Employees ( EmployeeID int PRIMARY KEY, LanguageID int NOT NULL FOREIGN KEY REFERENCES dbo.Languages(LanguageID) ); INSERT dbo.Languages(LanguageID, Name) VALUES(1033, N'English'), (45555, N'Klingon'); INSERT dbo.Employees(EmployeeID, LanguageID) SELECT [object_id], CASE ABS([object_id]%2) WHEN 1 THEN 1033 ELSE 45555 END FROM sys.all_objects;
Teraz mamy proste zapytanie, w którym chcemy pokazać każdego pracownika i nazwę jego podstawowego języka. Załóżmy, że to zapytanie jest używane w wielu miejscach i/lub na różne sposoby, więc zamiast tworzyć sprzężenie w zapytaniu, piszemy skalarny UDF, aby oddzielić to sprzężenie:
CREATE FUNCTION dbo.GetLanguage(@id int) RETURNS sysname AS BEGIN RETURN (SELECT Name FROM dbo.Languages WHERE LanguageID = @id); END
Wtedy nasze rzeczywiste zapytanie wygląda mniej więcej tak:
SELECT TOP (6) EmployeeID, Language = dbo.GetLanguage(LanguageID) FROM dbo.Employees;
Jeśli spojrzymy na plan wykonania zapytania, czegoś dziwnie brakuje:
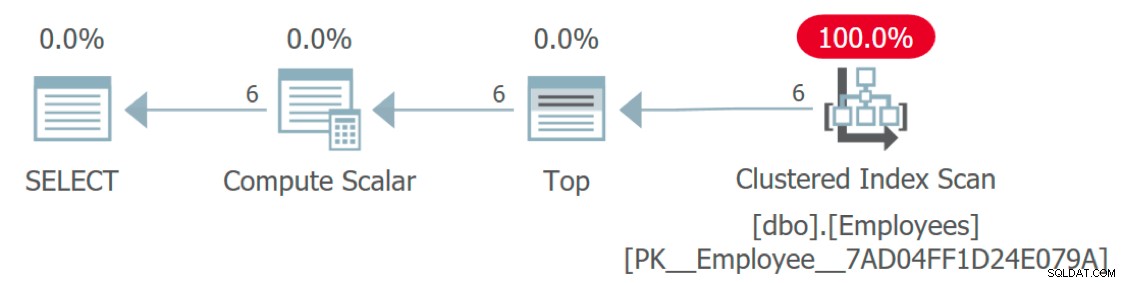 Plan wykonania pokazujący dostęp do pracowników, ale nie do języków
Plan wykonania pokazujący dostęp do pracowników, ale nie do języków
W jaki sposób uzyskuje się dostęp do tabeli języków? Ten plan wygląda bardzo wydajnie, ponieważ – podobnie jak sama funkcja – oddziela część związanej z nim złożoności. W rzeczywistości ten plan graficzny jest identyczny z zapytaniem, które po prostu przypisuje stałą lub zmienną do Language kolumna:
SELECT TOP (6) EmployeeID, Language = N'Sanskrit' FROM dbo.Employees;
Ale jeśli uruchomisz śledzenie względem oryginalnego zapytania, zobaczysz, że w rzeczywistości istnieje sześć wywołań funkcji (po jednym dla każdego wiersza) oprócz zapytania głównego, ale plany te nie są zwracane przez SQL Server.
Możesz to również zweryfikować, sprawdzając sys.dm_exec_function_stats , ale to nie jest gwarancją :
SELECT [function] = OBJECT_NAME([object_id]), execution_count FROM sys.dm_exec_function_stats WHERE object_name(object_id) IS NOT NULL;
function execution_count ----------- --------------- GetLanguage 6
SentryOne Plan Explorer pokaże zestawienia, jeśli wygenerujesz rzeczywisty plan z poziomu produktu, ale możemy je uzyskać tylko ze śledzenia i nadal nie ma planów zebranych ani pokazanych dla poszczególnych wywołań funkcji:
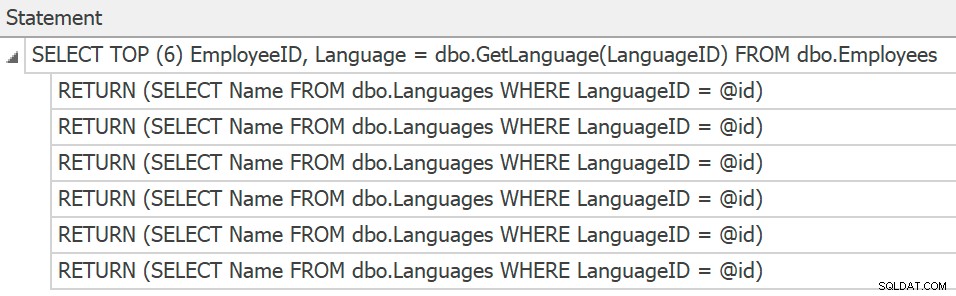 Instrukcje śledzenia dla poszczególnych wywołań skalarnych UDF
Instrukcje śledzenia dla poszczególnych wywołań skalarnych UDF
To wszystko sprawia, że bardzo trudno jest je rozwiązać, ponieważ musisz je polować, nawet jeśli już wiesz, że tam są. Może również spowodować prawdziwy bałagan w analizie wydajności, jeśli porównujesz dwa plany na podstawie takich rzeczy, jak szacunkowe koszty, ponieważ nie tylko odpowiedni operatorzy ukrywają się przed fizycznym diagramem, ale koszty nie są również nigdzie uwzględnione w planie.
Szybkie przejście do SQL Server 2019
Po tylu latach problematycznego zachowania i niejasnych przyczyn, stworzyli to tak, że niektóre funkcje można zoptymalizować w ogólnym planie wykonania. Scalar UDF Inlining sprawia, że obiekty, do których mają dostęp, są widoczne w celu rozwiązywania problemów *i* pozwalają na włączenie ich do strategii planu wykonania. Teraz oszacowania kardynalności (na podstawie statystyk) pozwalają na strategie łączenia, które po prostu nie były możliwe, gdy funkcja była wywoływana raz dla każdego wiersza.
Możemy użyć tego samego przykładu, co powyżej, albo utworzyć ten sam zestaw obiektów w bazie danych SQL Server 2019, albo wyczyścić pamięć podręczną planu i zwiększyć poziom zgodności do 150:
ALTER DATABASE SCOPED CONFIGURATION CLEAR PROCEDURE_CACHE; GO ALTER DATABASE Whatever SET COMPATIBILITY_LEVEL = 150; GO
Teraz, gdy ponownie uruchomimy nasze sześciowierszowe zapytanie:
SELECT TOP (6) EmployeeID, Language = dbo.GetLanguage(LanguageID) FROM dbo.Employees;
Otrzymujemy plan, który zawiera tabelę Języki i koszty związane z dostępem do niej:
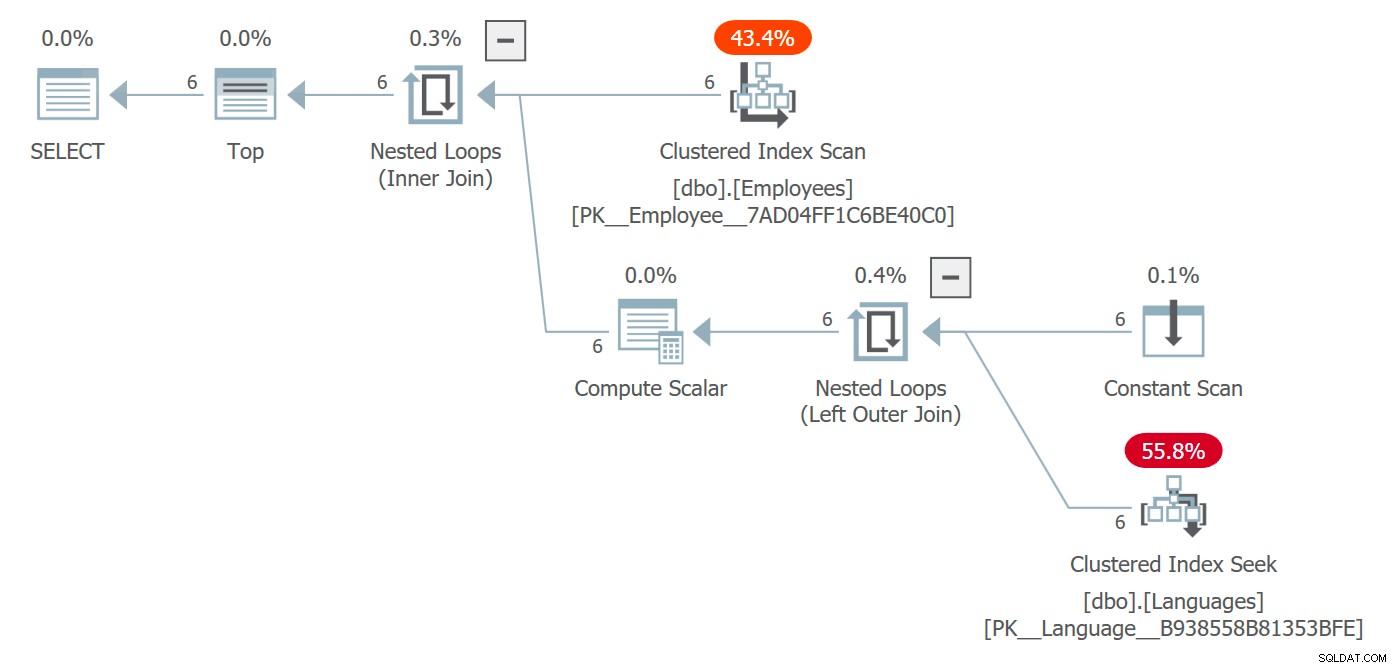 Plan obejmujący dostęp do obiektów, do których odwołuje się skalarny UDF
Plan obejmujący dostęp do obiektów, do których odwołuje się skalarny UDF
W tym przypadku optymalizator wybrał złącze zagnieżdżonych pętli, ale w różnych okolicznościach mógł wybrać inną strategię złączenia, przemyślany paralelizm i zasadniczo mógł całkowicie zmienić kształt planu. Prawdopodobnie nie zobaczysz tego w zapytaniu, które zwraca 6 wierszy i nie wpływa w żaden sposób na wydajność, ale w większej skali może.
Plan odzwierciedla, że funkcja nie jest wywoływana dla każdego wiersza – podczas gdy wyszukiwanie jest faktycznie wykonywane sześć razy, możesz zobaczyć, że sama funkcja nie pojawia się już w sys.dm_exec_function_stats . Jedną wadą, którą można usunąć, jest to, że jeśli użyjesz tego DMV do określenia, czy funkcja jest aktywnie używana (co często robimy w przypadku procedur i indeksów), nie będzie to już niezawodne.
Ostrzeżenia
Nie każda funkcja skalarna jest liniowa i nawet jeśli funkcja *jest* liniowa, niekoniecznie będzie liniowa w każdym scenariuszu. Często ma to związek ze złożonością funkcji, złożonością zapytania lub kombinacją obu. Możesz sprawdzić, czy funkcja jest inlineable w sys.sql_modules widok katalogu:
SELECT OBJECT_NAME([object_id]), definition, is_inlineable FROM sys.sql_modules;
A jeśli z jakiegoś powodu nie chcesz, aby określona funkcja (lub jakakolwiek funkcja w bazie danych) była wbudowana, nie musisz polegać na poziomie zgodności bazy danych, aby kontrolować to zachowanie. Nigdy nie lubiłem tego luźnego sprzężenia, które jest podobne do zmiany pokoju, aby obejrzeć inny program telewizyjny, zamiast po prostu zmienić kanał. Możesz to kontrolować na poziomie modułu za pomocą opcji INLINE:
ALTER FUNCTION dbo.GetLanguage(@id int) RETURNS sysname WITH INLINE = OFF AS BEGIN RETURN (SELECT Name FROM dbo.Languages WHERE LanguageID = @id); END GO
Możesz to kontrolować na poziomie bazy danych, ale niezależnie od poziomu zgodności:
ALTER DATABASE SCOPED CONFIGURATION SET TSQL_SCALAR_UDF_INLINING = OFF;
Chociaż musiałbyś mieć całkiem niezły przypadek użycia, aby wymachiwać tym młotkiem, IMHO.
Wniosek
Nie sugeruję teraz, że można przenieść każdy element logiki do skalarnego UDF i założyć, że teraz SQL Server zajmie się wszystkimi przypadkami. Jeśli masz bazę danych o dużym wykorzystaniu skalarnego UDF, powinieneś pobrać najnowszą wersję SQL Server 2019 CTP, przywrócić tam kopię zapasową swojej bazy danych i sprawdzić DMV, aby zobaczyć, ile z tych funkcji będzie nieliniowych, gdy nadejdzie czas. Może to być ważny punkt, gdy następnym razem będziesz argumentować o uaktualnieniu, ponieważ zasadniczo uzyskasz całą tę wydajność i zmarnujesz czas na rozwiązywanie problemów.
W międzyczasie, jeśli cierpisz na skalarną wydajność UDF i nie będziesz w najbliższym czasie aktualizować do SQL Server 2019, mogą istnieć inne sposoby na złagodzenie tego problemu.
Uwaga:napisałem ten artykuł i umieściłem go w kolejce, zanim zdałem sobie sprawę, że zamieściłem już inny artykuł w innym miejscu.



