Jeden z przypadków użycia filtrowanego indeksu wspomniany w Books Online dotyczy kolumny zawierającej głównie NULLs wartości. Pomysł polega na utworzeniu filtrowanego indeksu, który wyklucza NULLs , co skutkuje mniejszym indeksem nieklastrowanym, który wymaga mniej konserwacji niż równoważny indeks niefiltrowany. Innym popularnym zastosowaniem filtrowanych indeksów jest filtrowanie NULLs z UNIQUE indeks, dający zachowanie, którego użytkownicy innych silników baz danych mogą oczekiwać od domyślnego UNIQUE indeks lub ograniczenie:unikalność jest wymuszana tylko dla wartości innych niż NULLs wartości.
Niestety optymalizator zapytań ma ograniczenia, jeśli chodzi o indeksy filtrowane. W tym poście przyjrzymy się kilku mniej znanym przykładom.
Przykładowe tabele
Będziemy używać dwóch tabel (A i B), które mają tę samą strukturę:zastępczy klastrowany klucz podstawowy, najczęściej NULLs kolumna, która jest unikalna (bez uwzględnienia NULLs ) oraz kolumnę wypełniającą, która reprezentuje inne kolumny, które mogą znajdować się w rzeczywistej tabeli.
Kolumna zainteresowania to najczęściej NULLs jeden, który zadeklarowałem jako SPARSE . Opcja rzadka nie jest wymagana, po prostu ją uwzględniam, ponieważ nie mam zbyt wielu szans, aby z niej skorzystać. W każdym razie SPARSE prawdopodobnie ma sens w wielu scenariuszach, w których oczekuje się, że dane kolumny będą w większości NULLs . Jeśli chcesz, możesz usunąć rzadki atrybut z przykładów.
CREATE TABLE dbo.TableA
(
pk integer IDENTITY PRIMARY KEY,
data bigint SPARSE NULL,
padding binary(250) NOT NULL DEFAULT 0x
);
CREATE TABLE dbo.TableB
(
pk integer IDENTITY PRIMARY KEY,
data bigint SPARSE NULL,
padding binary(250) NOT NULL DEFAULT 0x
);
Każda tabela zawiera liczby od 1 do 2000 w kolumnie danych z dodatkowymi 40 000 wierszami, w których kolumna danych ma wartość NULLs :
-- Numbers 1 - 2,000
INSERT
dbo.TableA WITH (TABLOCKX)
(data)
SELECT TOP (2000)
ROW_NUMBER() OVER (ORDER BY (SELECT NULL))
FROM sys.columns AS c
CROSS JOIN sys.columns AS c2
ORDER BY
ROW_NUMBER() OVER (ORDER BY (SELECT NULL));
-- NULLs
INSERT TOP (40000)
dbo.TableA WITH (TABLOCKX)
(data)
SELECT
CONVERT(bigint, NULL)
FROM sys.columns AS c
CROSS JOIN sys.columns AS c2;
-- Copy into TableB
INSERT dbo.TableB WITH (TABLOCKX)
(data)
SELECT
ta.data
FROM dbo.TableA AS ta;
Obie tabele otrzymują UNIQUE filtrowany indeks dla 2000 innych niż NULLs wartości danych:
CREATE UNIQUE NONCLUSTERED INDEX uqA ON dbo.TableA (data) WHERE data IS NOT NULL; CREATE UNIQUE NONCLUSTERED INDEX uqB ON dbo.TableB (data) WHERE data IS NOT NULL;
Wyjście DBCC SHOW_STATISTICS podsumowuje sytuację:
DBCC SHOW_STATISTICS (TableA, uqA) WITH STAT_HEADER; DBCC SHOW_STATISTICS (TableB, uqB) WITH STAT_HEADER;

Przykładowe zapytanie
Poniższe zapytanie wykonuje proste łączenie dwóch tabel — wyobraź sobie, że tabele są w jakiejś relacji rodzic-dziecko, a wiele kluczy obcych ma wartość NULL. W każdym razie coś w tym stylu.
SELECT
ta.data,
tb.data
FROM dbo.TableA AS ta
JOIN dbo.TableB AS tb
ON ta.data = tb.data; Domyślny plan wykonania
Z SQL Server w domyślnej konfiguracji, optymalizator wybiera plan wykonania zawierający równoległe łączenie zagnieżdżonych pętli:
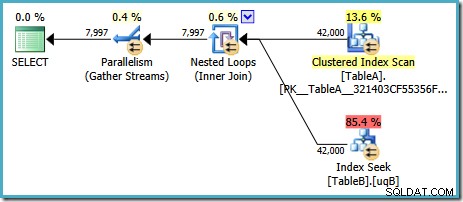
Ten plan ma szacunkowy koszt 7.7768 magic Optimizer Units™.
Jest jednak kilka dziwnych rzeczy związanych z tym planem. Wyszukiwanie indeksu używa naszego filtrowanego indeksu w tabeli B, ale zapytanie jest sterowane przez klastrowane skanowanie indeksu tabeli A. Predykat złączenia to test równości w kolumnach danych, który odrzuci NULLs (niezależnie od ANSI_NULLS ustawienie). Mogliśmy mieć nadzieję, że optymalizator przeprowadzi jakieś zaawansowane wnioskowanie na podstawie tej obserwacji, ale nie. Ten plan odczytuje każdy wiersz z tabeli A (w tym 40 000 NULLs ), przeprowadza wyszukiwanie w filtrowanym indeksie w tabeli B dla każdego z nich, opierając się na fakcie, że NULLs nie będzie pasować do NULLs w tym poszukiwaniu. To ogromna strata wysiłku.
Dziwne jest to, że optymalizator musiał zdać sobie sprawę, że łączenie odrzuca NULLs w celu wybrania filtrowanego indeksu dla tabeli B search, ale nie pomyślał o filtrowaniu NULLs z tabeli A najpierw – lub jeszcze lepiej, aby po prostu zeskanować NULLs -bezpłatny indeks filtrowany w tabeli A. Można się zastanawiać, czy jest to decyzja oparta na kosztach, może statystyki nie są zbyt dobre? Może powinniśmy wymusić stosowanie filtrowanego indeksu podpowiedzią? Wskazywanie na filtrowany indeks w tabeli A skutkuje tym samym planem z odwróconymi rolami – skanowanie tabeli B i wyszukiwanie w tabeli A. Wymuszenie filtrowanego indeksu dla obu tabel powoduje błąd 8622 :procesor zapytań nie mógł stworzyć planu zapytań.
Dodawanie predykatu NOT NULL
Podejrzewam, że przyczyna ma związek z dorozumianym NULLs - odrzucenie predykatu join, dodajemy jawny NOT NULL predykat do ON klauzula (lub WHERE klauzula jeśli wolisz, tutaj chodzi o to samo):
SELECT
ta.data,
tb.data
FROM dbo.TableA AS ta
JOIN dbo.TableB AS tb
ON ta.data = tb.data
AND ta.data IS NOT NULL;
Dodaliśmy NOT NULL sprawdź kolumnę tabeli A, ponieważ pierwotny plan przeskanował indeks klastrowy tej tabeli, zamiast używać naszego filtrowanego indeksu (przeszukiwanie do tabeli B było w porządku – używał filtrowanego indeksu). Nowe zapytanie jest semantycznie dokładnie takie samo jak poprzednie, ale plan wykonania jest inny:
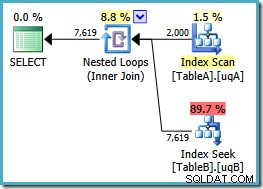
Teraz mamy oczekiwane skanowanie przefiltrowanego indeksu w tabeli A, dające 2000 znaków innych niż NULLs wierszy do kierowania zagnieżdżoną pętlą do tabeli B. Obie tabele używają naszych filtrowanych indeksów najwyraźniej teraz optymalnie:nowy plan kosztuje tylko 0,362835 jednostek (spadek z 7.7768). Możemy jednak zrobić lepiej.
Dodawanie dwóch predykatów NOT NULL
Zbędny NOT NULL predykat dla tabeli A zdziałały cuda; co się stanie, jeśli dodamy jeden również do tabeli B?
SELECT
ta.data,
tb.data
FROM dbo.TableA AS ta
JOIN dbo.TableB AS tb
ON ta.data = tb.data
AND ta.data IS NOT NULL
AND tb.data IS NOT NULL; To zapytanie jest nadal logicznie takie samo jak w dwóch poprzednich próbach, ale plan wykonania jest znowu inny:
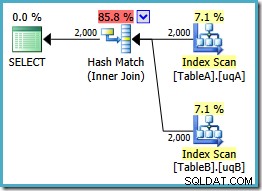
Ten plan tworzy tablicę mieszającą dla 2000 wierszy z tabeli A, a następnie sprawdza dopasowania przy użyciu 2000 wierszy z tabeli B. Szacunkowa liczba zwracanych wierszy jest znacznie lepsza niż poprzedni plan (czy zauważyłeś tam oszacowanie 7619?), a szacowany koszt wykonania ponownie spadł z 0,362835 do 0,0772056 .
Możesz spróbować wymusić sprzężenie haszujące, używając podpowiedzi na oryginale lub pojedynczego NOT NULL zapytań, ale nie dostaniesz taniego planu pokazanego powyżej. Optymalizator po prostu nie ma możliwości pełnego uzasadnienia NULLs -odrzucanie zachowania sprzężenia, ponieważ dotyczy ono naszych filtrowanych indeksów bez obu zbędnych predykatów.
Możesz być tym zaskoczony – nawet jeśli chodzi o pomysł, że jeden zbędny predykat nie wystarczył (na pewno, jeśli ta.data jest NOT NULL i ta.data = tb.data , wynika z tego, że tb.data jest również NOT NULL , prawda?)
Nadal nie idealny
To trochę zaskakujące, że dołączył tam hash. Jeśli znasz główne różnice między trzema fizycznymi operatorami złączenia, prawdopodobnie wiesz, że hash join jest najlepszym kandydatem, gdzie:
- Wstępnie posortowane dane wejściowe są niedostępne
- Wejście kompilacji skrótu jest mniejsze niż wejście sondy
- Wejście sondy jest dość duże
Żadna z tych rzeczy nie jest tutaj prawdziwa. Oczekujemy, że najlepszym planem dla tego zapytania i zestawu danych będzie sprzężenie scalające, wykorzystujące uporządkowane dane wejściowe dostępne z naszych dwóch filtrowanych indeksów. Możemy spróbować podpowiedzieć połączenie scalające, zachowując dwa dodatkowe ON predykaty klauzul:
SELECT
ta.data,
tb.data
FROM dbo.TableA AS ta
JOIN dbo.TableB AS tb
ON ta.data = tb.data
AND ta.data IS NOT NULL
AND tb.data IS NOT NULL
OPTION (MERGE JOIN); Kształt planu jest taki, jak się spodziewaliśmy:
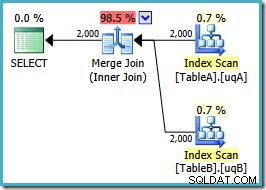
Uporządkowane skanowanie obu filtrowanych indeksów, świetne szacunki kardynalności, fantastyczne. Tylko jeden mały problem:ten plan wykonania jest znacznie gorszy; szacowany koszt wzrósł z 0,0772056 do 0,741527 . Przyczyna skoku w szacowanym koszcie jest ujawniana przez sprawdzenie właściwości operatora łączenia scalającego:
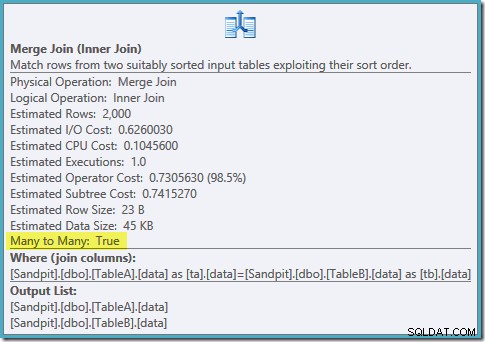
Jest to kosztowne łączenie wiele-do-wielu, w którym silnik wykonawczy musi śledzić duplikaty z zewnętrznych danych wejściowych w tabeli roboczej i przewijać w razie potrzeby. Duplikaty? Skanujemy unikalny indeks! Okazuje się, że optymalizator nie wie, że filtrowany unikalny indeks daje unikalne wartości (podłącz element tutaj). W rzeczywistości jest to złączenie jeden-do-jednego, ale optymalizator kosztuje je tak, jakby było to wiele do wielu, wyjaśniając, dlaczego preferuje plan łączenia mieszającego.
Alternatywna strategia
Wygląda na to, że wciąż napotykamy ograniczenia optymalizatora podczas korzystania z filtrowanych indeksów (pomimo tego, że jest to wyróżniony przypadek użycia w Books Online). Co się stanie, jeśli zamiast tego spróbujemy użyć widoków?
Korzystanie z widoków
Następujące dwa widoki po prostu filtrują tabele podstawowe, aby pokazać wiersze, w których kolumna danych ma wartość NOT NULL :
CREATE VIEW dbo.VA
WITH SCHEMABINDING AS
SELECT
pk,
data,
padding
FROM dbo.TableA
WHERE data IS NOT NULL;
GO
CREATE VIEW dbo.VB
WITH SCHEMABINDING AS
SELECT
pk,
data,
padding
FROM dbo.TableB
WHERE data IS NOT NULL; Przepisanie oryginalnego zapytania do widoków jest trywialne:
SELECT
v.data,
v2.data
FROM dbo.VA AS v
JOIN dbo.VB AS v2
ON v.data = v2.data; Pamiętaj, że to zapytanie pierwotnie wygenerowało plan równoległych pętli zagnieżdżonych, którego koszt wynosił 7.7768 jednostki. Z referencjami widoków otrzymujemy ten plan wykonania:
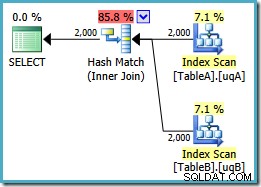
To jest dokładnie ten sam plan łączenia haszowego, który musieliśmy dodać zbędny NOT NULL predykaty do uzyskania z filtrowanymi indeksami (koszt to 0,0772056 jednostek jak poprzednio). Jest to oczekiwane, ponieważ zasadniczo wszystko, co tutaj zrobiliśmy, to wypchnięcie dodatkowego NOT NULL predykaty z zapytania do widoku.
Indeksowanie widoków
Możemy również spróbować zmaterializować widoki, tworząc unikalny indeks klastrowy w kolumnie pk:
CREATE UNIQUE CLUSTERED INDEX cuq ON dbo.VA (pk); CREATE UNIQUE CLUSTERED INDEX cuq ON dbo.VB (pk);
Teraz możemy dodać unikalne indeksy nieklastrowane do filtrowanej kolumny danych w widoku indeksowanym:
CREATE UNIQUE NONCLUSTERED INDEX ix ON dbo.VA (data); CREATE UNIQUE NONCLUSTERED INDEX ix ON dbo.VB (data);
Zauważ, że filtrowanie jest przeprowadzane w widoku, te indeksy nieklastrowane same w sobie nie są filtrowane.
Idealny plan
Jesteśmy teraz gotowi do uruchomienia naszego zapytania względem widoku za pomocą NOEXPAND wskazówka do tabeli:
SELECT
v.data,
v2.data
FROM dbo.VA AS v WITH (NOEXPAND)
JOIN dbo.VB AS v2 WITH (NOEXPAND)
ON v.data = v2.data; Plan wykonania to:
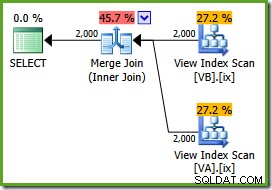
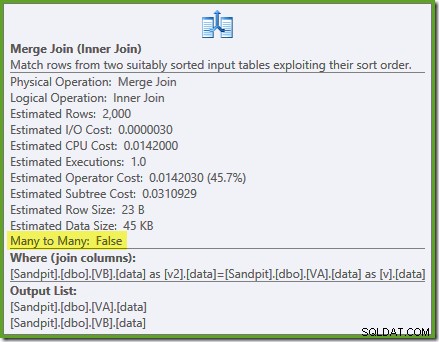
Optymalizator widzi niefiltrowane Indeksy widoku nieklastrowego są unikatowe, więc łączenie scalające wiele do wielu nie jest potrzebne. Ten ostateczny plan wykonania ma szacunkowy koszt 0,0310929 jednostek – nawet mniej niż plan łączenia haszowego (0.0772056 jednostek). To potwierdza nasze oczekiwania, że połączenie scalające powinno mieć najniższy szacowany koszt dla tego zapytania i przykładowego zestawu danych.
NOEXPAND wskazówki są potrzebne nawet w wersji Enterprise, aby zapewnić, że gwarancja unikalności zapewniana przez indeksy widoków jest używana przez optymalizator.
Podsumowanie
Ten post podkreśla dwa ważne ograniczenia optymalizatora z filtrowanymi indeksami:
- Zbędne predykaty złączeń mogą być konieczne do dopasowania filtrowanych indeksów
- Przefiltrowane unikalne indeksy nie dostarczają optymalizatorowi informacji o niepowtarzalności
W niektórych przypadkach może być praktyczne dodanie nadmiarowych predykatów do każdego zapytania. Alternatywą jest enkapsulacja żądanych domniemanych predykatów w widoku nieindeksowanym. Plan dopasowywania skrótów w tym poście był znacznie lepszy niż plan domyślny, mimo że optymalizator powinien być w stanie znaleźć nieco lepszy plan łączenia przez scalanie. Czasami może być konieczne zindeksowanie widoku i użycie NOEXPAND podpowiedzi (wymagane w przypadku instancji w wersji Standard Edition). W jeszcze innych okolicznościach żadne z tych podejść nie będzie odpowiednie. Przepraszam za to :)