Te same zalecenia dotyczące tempdb przedstawiam odkąd zacząłem pracować z SQL Server ponad 15 lat temu, kiedy pracowałem z klientami korzystającymi z wersji 2000. Istota tego:tworzenie wielu plików danych o tym samym rozmiarze, z tym samym auto ustawienia wzrostu, włącz flagę śledzenia 1118 (i być może 1117) i zmniejsz użycie bazy danych tempdb. Po stronie klienta był to limit tego, co można zrobić*, aż do SQL Server 2019.
*Istnieje kilka dodatkowych zaleceń dotyczących kodowania, które Pam Lahoud omawia w swoim bardzo pouczającym poście, TEMPDB – Files and Trace Flags and Updates, Oh My!
Interesujące jest to, że po tak długim czasie tempdb nadal stanowi problem. Zespół SQL Server wprowadził na przestrzeni lat wiele zmian, aby spróbować złagodzić problemy, ale nadużycia nadal trwają. Najnowsza adaptacja zespołu SQL Server polega na przeniesieniu tabel systemowych (metadanych) dla tempdb do In-Memory OLTP (czyli zoptymalizowanego pod kątem pamięci). Niektóre informacje są dostępne w informacjach o wydaniu SQL Server 2019, a podczas pierwszego dnia przemówienia programu PASS Summit zaprezentowali prezentację Boba Warda i Conora Cunninghama. Pam Lahoud zrobiła również krótkie demo podczas swojej ogólnej sesji PASS Summit. Teraz, gdy CTP 3.2 2019 jest już dostępny, pomyślałem, że nadszedł czas, aby sam trochę przetestować.
Konfiguracja
Mam zainstalowany SQL Server 2019 CTP 3.2 na mojej maszynie wirtualnej, która ma 8 GB pamięci (maksymalna pamięć serwera ustawiona na 6 GB) i 4 vCPU. Utworzyłem cztery (4) pliki danych tempdb, każdy o rozmiarze 1 GB.
Przywróciłem kopię WideWorldImporters, a następnie utworzyłem trzy procedury składowane (definicje poniżej). Każda procedura składowana akceptuje dane wejściowe daty i wypycha wszystkie wiersze z Sales.Order i Sales.OrderLines dla tej daty do obiektu tymczasowego. W Sales.usp_OrderInfoTV obiekt jest zmienną tabeli, w Sales.usp_OrderInfoTT obiekt jest tabelą tymczasową zdefiniowaną przez SELECT … INTO z dodanym później nieklastrowanym, a w Sales.usp_OrderInfoTTALT obiektem jest predefiniowana tabela tymczasowa, która jest następnie zmieniana mieć dodatkową kolumnę. Po dodaniu danych do obiektu tymczasowego istnieje instrukcja SELECT w odniesieniu do obiektu, który łączy się z tabelą Sales.Customers.
/*
Create the stored procedures
*/
USE [WideWorldImporters];
GO
DROP PROCEDURE IF EXISTS Sales.usp_OrderInfoTV
GO
CREATE PROCEDURE Sales.usp_OrderInfoTV @OrderDate DATE
AS
BEGIN
DECLARE @OrdersInfo TABLE (
OrderID INT,
OrderLineID INT,
CustomerID INT,
StockItemID INT,
Quantity INT,
UnitPrice DECIMAL(18,2),
OrderDate DATE);
INSERT INTO @OrdersInfo (
OrderID,
OrderLineID,
CustomerID,
StockItemID,
Quantity,
UnitPrice,
OrderDate)
SELECT
o.OrderID,
ol.OrderLineID,
o.CustomerID,
ol.StockItemID,
ol.Quantity,
ol.UnitPrice,
OrderDate
FROM Sales.Orders o
INNER JOIN Sales.OrderLines ol
ON o.OrderID = ol.OrderID
WHERE o.OrderDate = @OrderDate;
SELECT o.OrderID,
c.CustomerName,
SUM (o.Quantity),
SUM (o.UnitPrice)
FROM @OrdersInfo o
JOIN Sales.Customers c
ON o.CustomerID = c.CustomerID
GROUP BY o.OrderID, c.CustomerName;
END
GO
DROP PROCEDURE IF EXISTS Sales.usp_OrderInfoTT
GO
CREATE PROCEDURE Sales.usp_OrderInfoTT @OrderDate DATE
AS
BEGIN
SELECT
o.OrderID,
ol.OrderLineID,
o.CustomerID,
ol.StockItemID,
ol.Quantity,
ol.UnitPrice,
OrderDate
INTO #temporderinfo
FROM Sales.Orders o
INNER JOIN Sales.OrderLines ol
ON o.OrderID = ol.OrderID
WHERE o.OrderDate = @OrderDate;
SELECT o.OrderID,
c.CustomerName,
SUM (o.Quantity),
SUM (o.UnitPrice)
FROM #temporderinfo o
JOIN Sales.Customers c
ON o.CustomerID = c.CustomerID
GROUP BY o.OrderID, c.CustomerName
END
GO
DROP PROCEDURE IF EXISTS Sales.usp_OrderInfoTTALT
GO
CREATE PROCEDURE Sales.usp_OrderInfoTTALT @OrderDate DATE
AS
BEGIN
CREATE TABLE #temporderinfo (
OrderID INT,
OrderLineID INT,
CustomerID INT,
StockItemID INT,
Quantity INT,
UnitPrice DECIMAL(18,2));
INSERT INTO #temporderinfo (
OrderID,
OrderLineID,
CustomerID,
StockItemID,
Quantity,
UnitPrice)
SELECT
o.OrderID,
ol.OrderLineID,
o.CustomerID,
ol.StockItemID,
ol.Quantity,
ol.UnitPrice
FROM Sales.Orders o
INNER JOIN Sales.OrderLines ol
ON o.OrderID = ol.OrderID
WHERE o.OrderDate = @OrderDate;
SELECT o.OrderID,
c.CustomerName,
SUM (o.Quantity),
SUM (o.UnitPrice)
FROM #temporderinfo o
JOIN Sales.Customers c
ON o.CustomerID c.CustomerID
GROUP BY o.OrderID, c.CustomerName
END
GO
/*
Create tables to hold testing data
*/
USE [WideWorldImporters];
GO
CREATE TABLE [dbo].[PerfTesting_Tests] (
[TestID] INT IDENTITY(1,1),
[TestName] VARCHAR (200),
[TestStartTime] DATETIME2,
[TestEndTime] DATETIME2
) ON [PRIMARY];
GO
CREATE TABLE [dbo].[PerfTesting_WaitStats] (
[TestID] [int] NOT NULL,
[CaptureDate] [datetime] NOT NULL DEFAULT (sysdatetime()),
[WaitType] [nvarchar](60) NOT NULL,
[Wait_S] [decimal](16, 2) NULL,
[Resource_S] [decimal](16, 2) NULL,
[Signal_S] [decimal](16, 2) NULL,
[WaitCount] [bigint] NULL,
[Percentage] [decimal](5, 2) NULL,
[AvgWait_S] [decimal](16, 4) NULL,
[AvgRes_S] [decimal](16, 4) NULL,
[AvgSig_S] [decimal](16, 4) NULL
) ON [PRIMARY];
GO
/*
Enable Query Store
(testing settings, not exactly what
I would recommend for production)
*/
USE [master];
GO
ALTER DATABASE [WideWorldImporters] SET QUERY_STORE = ON;
GO
ALTER DATABASE [WideWorldImporters] SET QUERY_STORE (
OPERATION_MODE = READ_WRITE,
CLEANUP_POLICY = (STALE_QUERY_THRESHOLD_DAYS = 30),
DATA_FLUSH_INTERVAL_SECONDS = 600,
INTERVAL_LENGTH_MINUTES = 10,
MAX_STORAGE_SIZE_MB = 1024,
QUERY_CAPTURE_MODE = AUTO,
SIZE_BASED_CLEANUP_MODE = AUTO);
GO Testowanie
Domyślnym zachowaniem SQL Server 2019 jest to, że metadane tempdb nie są zoptymalizowane pod kątem pamięci i możemy to potwierdzić, sprawdzając sys.configuration:
SELECT * FROM sys.configurations WHERE configuration_id = 1589;

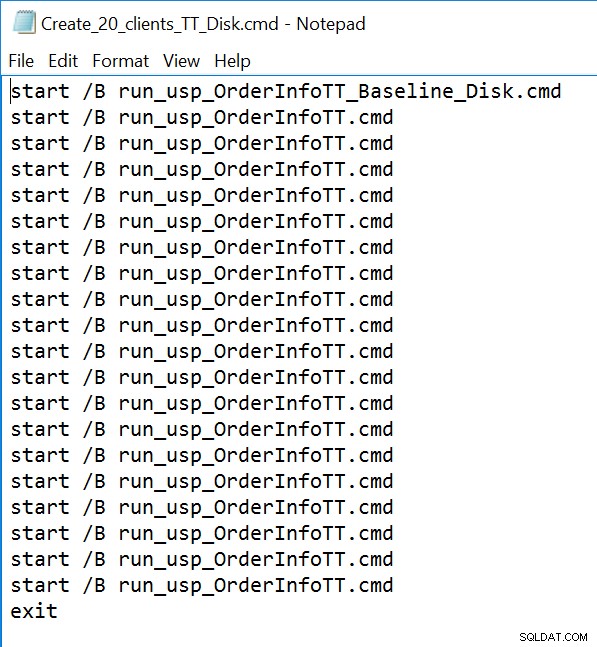
W przypadku wszystkich trzech procedur składowanych użyjemy sqlcmd do wygenerowania 20 współbieżnych wątków uruchamiających jeden z dwóch różnych plików .sql. Pierwszy plik .sql, który będzie używany przez 19 wątków, wykona procedurę w pętli 1000 razy. Drugi plik .sql, który będzie miał tylko jeden (1) wątek, wykona procedurę w pętli 3000 razy. Plik zawiera również TSQL do przechwytywania dwóch interesujących metryk:całkowitego czasu trwania i statystyk oczekiwania. Użyjemy Query Store, aby przechwycić średni czas trwania procedury.
/*
Example of first .sql file
which calls the SP 1000 times
*/
SET NOCOUNT ON;
GO
USE [WideWorldImporters];
GO
DECLARE @StartDate DATE;
DECLARE @MaxDate DATE;
DECLARE @Date DATE;
DECLARE @Counter INT = 1;
SELECT @StartDATE = MIN(OrderDate) FROM [WideWorldImporters].[Sales].[Orders];
SELECT @MaxDATE = MAX(OrderDate) FROM [WideWorldImporters].[Sales].[Orders];
SET @Date = @StartDate;
WHILE @Counter <= 1000
BEGIN
EXEC [Sales].[usp_OrderInfoTT] @Date;
IF @Date <= @MaxDate
BEGIN
SET @Date = DATEADD(DAY, 1, @Date);
END
ELSE
BEGIN
SET @Date = @StartDate;
END
SET @Counter = @Counter + 1;
END
GO
/*
Example of second .sql file
which calls the SP 3000 times
and captures total duration and
wait statisics
*/
SET NOCOUNT ON;
GO
USE [WideWorldImporters];
GO
DECLARE @StartDate DATE;
DECLARE @MaxDate DATE;
DECLARE @DATE DATE;
DECLARE @Counter INT = 1;
DECLARE @TestID INT;
DECLARE @TestName VARCHAR(200) = 'Execution of usp_OrderInfoTT - Disk Based System Tables';
INSERT INTO [WideWorldImporters].[dbo].[PerfTesting_Tests] ([TestName]) VALUES (@TestName);
SELECT @TestID = MAX(TestID) FROM [WideWorldImporters].[dbo].[PerfTesting_Tests];
SELECT @StartDATE = MIN(OrderDate) FROM [WideWorldImporters].[Sales].[Orders];
SELECT @MaxDATE = MAX(OrderDate) FROM [WideWorldImporters].[Sales].[Orders];
SET @Date = @StartDate;
IF EXISTS (SELECT * FROM [tempdb].[sys].[objects]
WHERE [name] = N'##SQLskillsStats1')
DROP TABLE [##SQLskillsStats1];
IF EXISTS (SELECT * FROM [tempdb].[sys].[objects]
WHERE [name] = N'##SQLskillsStats2')
DROP TABLE [##SQLskillsStats2];
SELECT [wait_type], [waiting_tasks_count], [wait_time_ms],
[max_wait_time_ms], [signal_wait_time_ms]
INTO ##SQLskillsStats1
FROM sys.dm_os_wait_stats;
/*
set start time
*/
UPDATE [WideWorldImporters].[dbo].[PerfTesting_Tests]
SET [TestStartTime] = SYSDATETIME()
WHERE [TestID] = @TestID;
WHILE @Counter <= 3000
BEGIN
EXEC [Sales].[usp_OrderInfoTT] @Date;
IF @Date <= @MaxDate
BEGIN
SET @Date = DATEADD(DAY, 1, @Date);
END
ELSE
BEGIN
SET @Date = @StartDate;
END
SET @Counter = @Counter + 1
END
/*
set end time
*/
UPDATE [WideWorldImporters].[dbo].[PerfTesting_Tests]
SET [TestEndTime] = SYSDATETIME()
WHERE [TestID] = @TestID;
SELECT [wait_type], [waiting_tasks_count], [wait_time_ms],
[max_wait_time_ms], [signal_wait_time_ms]
INTO ##SQLskillsStats2
FROM sys.dm_os_wait_stats;
WITH [DiffWaits] AS
(SELECT
-- Waits that weren't in the first snapshot
[ts2].[wait_type],
[ts2].[wait_time_ms],
[ts2].[signal_wait_time_ms],
[ts2].[waiting_tasks_count]
FROM [##SQLskillsStats2] AS [ts2]
LEFT OUTER JOIN [##SQLskillsStats1] AS [ts1]
ON [ts2].[wait_type] = [ts1].[wait_type]
WHERE [ts1].[wait_type] IS NULL
AND [ts2].[wait_time_ms] > 0
UNION
SELECT
-- Diff of waits in both snapshots
[ts2].[wait_type],
[ts2].[wait_time_ms] - [ts1].[wait_time_ms] AS [wait_time_ms],
[ts2].[signal_wait_time_ms] - [ts1].[signal_wait_time_ms] AS [signal_wait_time_ms],
[ts2].[waiting_tasks_count] - [ts1].[waiting_tasks_count] AS [waiting_tasks_count]
FROM [##SQLskillsStats2] AS [ts2]
LEFT OUTER JOIN [##SQLskillsStats1] AS [ts1]
ON [ts2].[wait_type] = [ts1].[wait_type]
WHERE [ts1].[wait_type] IS NOT NULL
AND [ts2].[waiting_tasks_count] - [ts1].[waiting_tasks_count] > 0
AND [ts2].[wait_time_ms] - [ts1].[wait_time_ms] > 0),
[Waits] AS
(SELECT
[wait_type],
[wait_time_ms] / 1000.0 AS [WaitS],
([wait_time_ms] - [signal_wait_time_ms]) / 1000.0 AS [ResourceS],
[signal_wait_time_ms] / 1000.0 AS [SignalS],
[waiting_tasks_count] AS [WaitCount],
100.0 * [wait_time_ms] / SUM ([wait_time_ms]) OVER() AS [Percentage],
ROW_NUMBER() OVER(ORDER BY [wait_time_ms] DESC) AS [RowNum]
FROM [DiffWaits]
WHERE [wait_type] NOT IN (
-- These wait types are almost 100% never a problem and so they are
-- filtered out to avoid them skewing the results.
N'BROKER_EVENTHANDLER', N'BROKER_RECEIVE_WAITFOR', N'BROKER_TASK_STOP',
N'BROKER_TO_FLUSH', N'BROKER_TRANSMITTER', N'CHECKPOINT_QUEUE',
N'CHKPT', N'CLR_AUTO_EVENT', N'CLR_MANUAL_EVENT',
N'CLR_SEMAPHORE', N'CXCONSUMER', N'DBMIRROR_DBM_EVENT',
N'DBMIRROR_EVENTS_QUEUE', N'DBMIRROR_WORKER_QUEUE', N'DBMIRRORING_CMD',
N'DIRTY_PAGE_POLL', N'DISPATCHER_QUEUE_SEMAPHORE', N'EXECSYNC',
N'FSAGENT', N'FT_IFTS_SCHEDULER_IDLE_WAIT', N'FT_IFTSHC_MUTEX',
N'HADR_CLUSAPI_CALL', N'HADR_FILESTREAM_IOMGR_IOCOMPLETION', N'HADR_LOGCAPTURE_WAIT',
N'HADR_NOTIFICATION_DEQUEUE', N'HADR_TIMER_TASK', N'HADR_WORK_QUEUE',
N'KSOURCE_WAKEUP', N'LAZYWRITER_SLEEP', N'LOGMGR_QUEUE',
N'MEMORY_ALLOCATION_EXT', N'ONDEMAND_TASK_QUEUE', N'PARALLEL_REDO_DRAIN_WORKER',
N'PARALLEL_REDO_LOG_CACHE', N'PARALLEL_REDO_TRAN_LIST', N'PARALLEL_REDO_WORKER_SYNC',
N'PARALLEL_REDO_WORKER_WAIT_WORK', N'PREEMPTIVE_XE_GETTARGETSTATE',
N'PWAIT_ALL_COMPONENTS_INITIALIZED', N'PWAIT_DIRECTLOGCONSUMER_GETNEXT',
N'QDS_PERSIST_TASK_MAIN_LOOP_SLEEP', N'QDS_ASYNC_QUEUE',
N'QDS_CLEANUP_STALE_QUERIES_TASK_MAIN_LOOP_SLEEP',
N'QDS_SHUTDOWN_QUEUE', N'REDO_THREAD_PENDING_WORK', N'REQUEST_FOR_DEADLOCK_SEARCH',
N'RESOURCE_QUEUE', N'SERVER_IDLE_CHECK', N'SLEEP_BPOOL_FLUSH',
N'SLEEP_DBSTARTUP', N'SLEEP_DCOMSTARTUP', N'SLEEP_MASTERDBREADY',
N'SLEEP_MASTERMDREADY', N'SLEEP_MASTERUPGRADED', N'SLEEP_MSDBSTARTUP',
N'SLEEP_SYSTEMTASK', N'SLEEP_TASK', N'SLEEP_TEMPDBSTARTUP',
N'SNI_HTTP_ACCEPT', N'SOS_WORK_DISPATCHER', N'SP_SERVER_DIAGNOSTICS_SLEEP',
N'SQLTRACE_BUFFER_FLUSH', N'SQLTRACE_INCREMENTAL_FLUSH_SLEEP',
N'SQLTRACE_WAIT_ENTRIES', N'WAIT_FOR_RESULTS', N'WAITFOR',
N'WAITFOR_TASKSHUTDOWN', N'WAIT_XTP_RECOVERY', N'WAIT_XTP_HOST_WAIT',
N'WAIT_XTP_OFFLINE_CKPT_NEW_LOG', N'WAIT_XTP_CKPT_CLOSE',
N'XE_DISPATCHER_JOIN', N'XE_DISPATCHER_WAIT', N'XE_TIMER_EVENT'
)
)
INSERT INTO [WideWorldImporters].[dbo].[PerfTesting_WaitStats] (
[TestID],
[WaitType] ,
[Wait_S] ,
[Resource_S] ,
[Signal_S] ,
[WaitCount] ,
[Percentage] ,
[AvgWait_S] ,
[AvgRes_S] ,
[AvgSig_S]
)
SELECT
@TestID,
[W1].[wait_type] AS [WaitType],
CAST ([W1].[WaitS] AS DECIMAL (16, 2)) AS [Wait_S],
CAST ([W1].[ResourceS] AS DECIMAL (16, 2)) AS [Resource_S],
CAST ([W1].[SignalS] AS DECIMAL (16, 2)) AS [Signal_S],
[W1].[WaitCount] AS [WaitCount],
CAST ([W1].[Percentage] AS DECIMAL (5, 2)) AS [Percentage],
CAST (([W1].[WaitS] / [W1].[WaitCount]) AS DECIMAL (16, 4)) AS [AvgWait_S],
CAST (([W1].[ResourceS] / [W1].[WaitCount]) AS DECIMAL (16, 4)) AS [AvgRes_S],
CAST (([W1].[SignalS] / [W1].[WaitCount]) AS DECIMAL (16, 4)) AS [AvgSig_S]
FROM [Waits] AS [W1]
INNER JOIN [Waits] AS [W2]
ON [W2].[RowNum] <= [W1].[RowNum]
GROUP BY [W1].[RowNum], [W1].[wait_type], [W1].[WaitS],
[W1].[ResourceS], [W1].[SignalS], [W1].[WaitCount], [W1].[Percentage]
HAVING SUM ([W2].[Percentage]) - [W1].[Percentage] < 95; -- percentage threshold
GO
-- Cleanup
IF EXISTS (SELECT * FROM [tempdb].[sys].[objects]
WHERE [name] = N'##SQLskillsStats1')
DROP TABLE [##SQLskillsStats1];
IF EXISTS (SELECT * FROM [tempdb].[sys].[objects]
WHERE [name] = N'##SQLskillsStats2')
DROP TABLE [##SQLskillsStats2];
GO Przykład pliku wiersza poleceń:
Wyniki
Po wykonaniu plików wiersza poleceń, które generują 20 wątków dla każdej procedury składowanej, sprawdzenie całkowitego czasu trwania 12 000 wykonań każdej procedury pokazuje, co następuje:
SELECT *, DATEDIFF(SECOND, TestStartTime, TestEndTime) AS [TotalDuration] FROM [dbo].[PerfTesting_Tests] ORDER BY [TestID];

Procedury składowane z tabelami tymczasowymi (usp_OrderInfoTT i usp_OrderInfoTTC) trwały dłużej. Jeśli spojrzymy na wydajność poszczególnych zapytań:
SELECT
[qsq].[query_id],
[qsp].[plan_id],
OBJECT_NAME([qsq].[object_id]) AS [ObjectName],
[rs].[count_executions],
[rs].[last_execution_time],
[rs].[avg_duration],
[rs].[avg_logical_io_reads],
[qst].[query_sql_text]
FROM [sys].[query_store_query] [qsq]
JOIN [sys].[query_store_query_text] [qst]
ON [qsq].[query_text_id] = [qst].[query_text_id]
JOIN [sys].[query_store_plan] [qsp]
ON [qsq].[query_id] = [qsp].[query_id]
JOIN [sys].[query_store_runtime_stats] [rs]
ON [qsp].[plan_id] = [rs].[plan_id]
WHERE ([qsq].[object_id] = OBJECT_ID('Sales.usp_OrderInfoTT'))
OR ([qsq].[object_id] = OBJECT_ID('Sales.usp_OrderInfoTV'))
OR ([qsq].[object_id] = OBJECT_ID('Sales.usp_OrderInfoTTALT'))
ORDER BY [qsq].[query_id], [rs].[last_execution_time];

Widzimy, że SELECT … INTO dla usp_OrderInfoTT trwało średnio około 28 ms (czas trwania w Query Store jest przechowywany w mikrosekundach), a zajęło tylko 9 ms, gdy wstępnie utworzono tabelę tymczasową. W przypadku zmiennej tabeli INSERT trwało średnio nieco ponad 22 ms. Co ciekawe, zapytanie SELECT zajęło nieco ponad 1 ms dla tabel tymczasowych i około 2,7 ms dla zmiennej tabeli.
Sprawdzenie danych statystyk oczekiwania pozwala znaleźć znajomy typ wait_type, PAGELATCH*:
SELECT * FROM [dbo].[PerfTesting_WaitStats] ORDER BY [TestID], [Percentage] DESC;

Zauważ, że widzimy tylko oczekiwanie PAGELATCH* na testy 1 i 2, które były procedurami z tabelami tymczasowymi. W przypadku usp_OrderInfoTV, które używały zmiennej tabeli, widzimy tylko oczekiwania SOS_SCHEDULER_YIELD. Uwaga: Nie oznacza to w żaden sposób, że należy używać zmiennych tabeli zamiast tabel tymczasowych , ani nie oznacza, że nie mieć PAGELATCH czeka ze zmiennymi tabeli. To jest wymyślony scenariusz; bardzo Zalecamy przetestowanie za pomocą SWOJEGO kodu, aby zobaczyć, jakie typy wait_type się pojawiają.
Teraz zmienimy instancję tak, aby używała tabel zoptymalizowanych pod kątem pamięci dla metadanych tempdb. Można to zrobić na dwa sposoby:poleceniem ALTER SERVER CONFIGURATION lub sp_configure. Ponieważ to ustawienie jest opcją zaawansowaną, jeśli używasz sp_configure, musisz najpierw włączyć opcje zaawansowane.
ALTER SERVER CONFIGURATION SET MEMORY_OPTIMIZED TEMPDB_METADATA = ON; GO
Po tej zmianie konieczne jest ponowne uruchomienie do instancji. (UWAGA:możesz to zmienić z powrotem, aby NIE używać tabel zoptymalizowanych pod kątem pamięci, wystarczy ponownie uruchomić instancję.) Po ponownym uruchomieniu, jeśli ponownie sprawdzimy sys.configuration, zobaczymy, że tabele metadanych są zoptymalizowane pod kątem pamięci:

Po ponownym wykonaniu plików wiersza poleceń całkowity czas trwania 21 000 wykonań każdej procedury przedstawia się następująco (należy zauważyć, że wyniki są uporządkowane według procedury przechowywanej w celu łatwiejszego porównania):

Zdecydowanie poprawiła się wydajność zarówno usp_OrderInfoTT, jak i usp_OrderInfoTTC oraz niewielki wzrost wydajności usp_OrderInfoTV. Sprawdźmy czasy trwania zapytań:
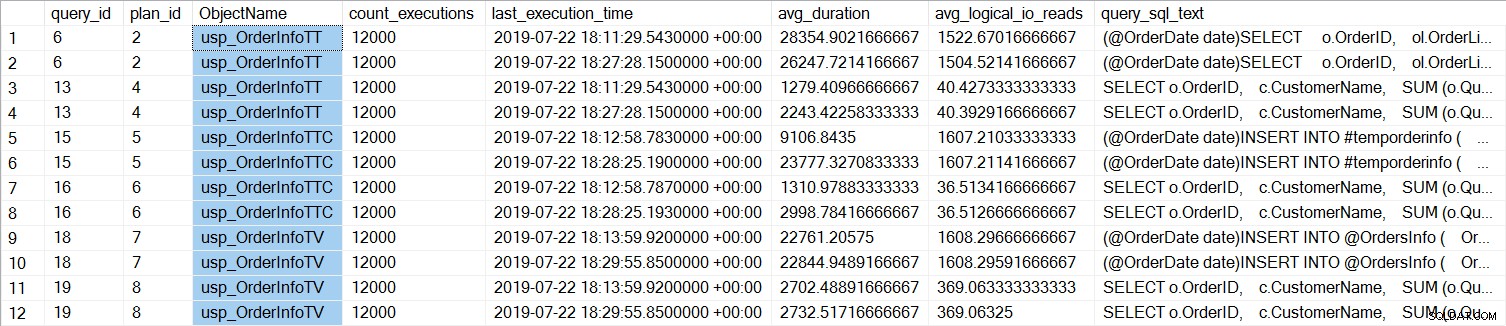
W przypadku wszystkich zapytań czas trwania zapytania jest prawie taki sam, z wyjątkiem wydłużenia czasu trwania INSERT, gdy tabela jest wstępnie utworzona, co jest całkowicie nieoczekiwane. Widzimy interesującą zmianę w statystykach oczekiwania:
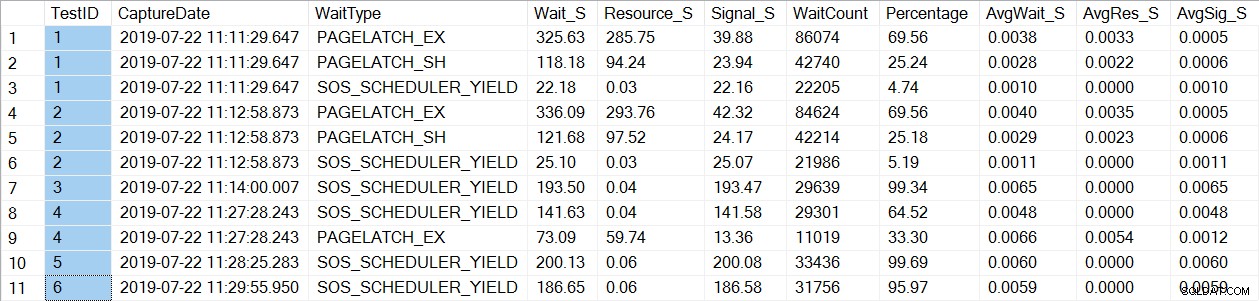
W przypadku usp_OrderInfoTT wykonywany jest SELECT … INTO w celu utworzenia tabeli tymczasowej. Czas oczekiwania zmienił się z PAGELATCH_EX i PAGELATCH_SH na tylko PAGELATCH_EX i SOS_SCHEDULER_YIELD. Nie widzimy już czekania PAGELATCH_SH.
W przypadku usp_OrderInfoTTC, która tworzy tabelę tymczasową, a następnie ją wstawia, oczekiwania PAGELATCH_EX i PAGELATCH_SH nie są już wyświetlane, a widzimy tylko oczekiwania SOS_SCHEDULER_YIELD.
Wreszcie, w przypadku OrderInfoTV, oczekiwania są spójne – tylko SOS_SCHEDULER_YIELD, z prawie takim samym całkowitym czasem oczekiwania.
Podsumowanie
Na podstawie tych testów widzimy poprawę we wszystkich przypadkach, znacząco w przypadku procedur składowanych z tabelami tymczasowymi. Wprowadzono niewielką zmianę w procedurze zmiennej tabeli. Niezwykle ważne jest, aby pamiętać, że jest to jeden scenariusz, z małym testem obciążenia. Byłem bardzo zainteresowany wypróbowaniem tych trzech bardzo prostych scenariuszy, aby spróbować zrozumieć, co może najbardziej skorzystać na zoptymalizowaniu pamięci metadanych tempdb. To obciążenie było niewielkie i trwało bardzo ograniczony czas – w rzeczywistości miałem bardziej zróżnicowane wyniki z większą liczbą wątków, co warto omówić w innym poście. Najważniejszym wnioskiem jest to, że podobnie jak w przypadku wszystkich nowych funkcji i funkcjonalności, testowanie jest ważne. W przypadku tej funkcji chcesz mieć podstawę bieżącej wydajności, z którą można porównywać metryki, takie jak żądania wsadowe/s i statystyki oczekiwania po zoptymalizowaniu pamięci metadanych.
Dodatkowe uwagi
Korzystanie z protokołu OLTP w pamięci wymaga grupy plików typu MEMORY ZOPTYMALIZOWANE DANE. Jednak po włączeniu MEMORY_OPTIMIZED TEMPDB_METADATA nie jest tworzona żadna dodatkowa grupa plików dla tempdb. Ponadto nie wiadomo, czy tabele zoptymalizowane pod kątem pamięci są trwałe (SCHEMA_AND_DATA), czy nie (SCHEMA_ONLY). Zazwyczaj można to określić za pomocą sys.tables (durability_desc), ale nic nie zwraca danych dotyczących zaangażowanych tabel systemowych podczas wykonywania kwerendy w tempdb, nawet przy użyciu dedykowanego połączenia administratora. Masz możliwość przeglądania indeksów nieklastrowanych dla tabel zoptymalizowanych pod kątem pamięci. Możesz użyć następującego zapytania, aby zobaczyć, które tabele są zoptymalizowane pod kątem pamięci w tempdb:
SELECT * FROM tempdb.sys.dm_db_xtp_object_stats x JOIN tempdb.sys.objects o ON x.object_id = o.object_id JOIN tempdb.sys.schemas s ON o.schema_id = s.schema_id;
Następnie dla dowolnej tabeli uruchom sp_helpindex, na przykład:
EXEC sys.sp_helpindex N'sys.sysobjvalues';

Pamiętaj, że jeśli jest to indeks skrótu (który wymaga oszacowania BUCKET_COUNT w ramach tworzenia), opis będzie zawierał „hasz nieklastrowany”.