Analizowanie danych z XML przy użyciu XQuery to rutynowa praktyka. Aby zrobić to najskuteczniej, wymagany jest niewielki wysiłek.
Załóżmy, że musimy przeanalizować dane z pliku na dysku o następującej strukturze:
<tables> <table name="Accounting" schema="Production" object="Accounting"> <column name="Date" order="3" visible="1" /> <column name="DateFrom" order="5" visible="1" /> <column name="DateTo" order="6" visible="1" /> <column name="Description" order="4" visible="1" /> <column name="DocumentUID" order="1" visible="0" /> <column name="Number" order="2" visible="1" /> <column name="Warehouse" order="7" visible="1" /> </table> </tables>
Użyj BULK INSERT, jeśli chcesz odczytać dane z pliku:
SELECT BulkColumn FROM OPENROWSET(BULK 'D:\data.xml', SINGLE_BLOB) x sample xml file
Przykładowy plik xml jest tutaj.
Pamiętaj jednak o jednej szczególnej rzeczy… Staraj się nie czytać danych bezpośrednio:
;WITH cte AS
(
SELECT x = CAST(BulkColumn AS XML)
FROM OPENROWSET(BULK 'D:\data.xml', SINGLE_BLOB) x
)
SELECT t.c.value('@name', 'VARCHAR(100)')
FROM cte
CROSS APPLY x.nodes('tables/table') t(c) Przypisz dane do zmiennej. W ten sposób możesz uzyskać bardziej wydajny plan wykonania:
DECLARE @xml XML
SELECT @xml = BulkColumn
FROM OPENROWSET(BULK 'D:\data.xml', SINGLE_BLOB) x
SELECT t.c.value('@name', 'VARCHAR(100)')
FROM @xml.nodes('tables/table') t(c) Porównaj wyniki:
Table 'Worktable'. Scan count 0, logical reads 729, physical reads 0, read-ahead reads 0, lob logical reads 62655,... SQL Server Execution Times: CPU time = 1203 ms, elapsed time = 1214 ms. Table 'Worktable'. Scan count 0, logical reads 7, physical reads 0, read-ahead reads 0, lob logical reads 202,.... SQL Server Execution Times: CPU time = 16 ms, elapsed time = 4 ms. SQL Server Execution Times: CPU time = 0 ms, elapsed time = 3 ms.
Jak widać, druga opcja jest znacznie szybsza.
Inną ważną cechą SQL Server podczas pracy z XQuery jest to, że odczytywanie elementu nadrzędnego może skutkować niską wydajnością. Rozważ następujący przykład:
SET STATISTICS PROFILE OFF
DECLARE @xml XML
SELECT @xml = BulkColumn
FROM OPENROWSET(BULK 'D:\data.xml', SINGLE_BLOB) x
SET STATISTICS PROFILE ON
SELECT
t.c.value('@name', 'SYSNAME')
, t.c.value('@order', 'INT')
, t.c.value('@visible', 'BIT')
, t.c.value('../@name', 'SYSNAME')
, t.c.value('../@schema', 'SYSNAME')
, t.c.value('../@object', 'SYSNAME')
FROM @xml.nodes('tables/table/*') t(c) Spójrzmy na rzeczywistą liczbę wierszy otrzymanych od operatora. Wartość jest nienormalnie duża:
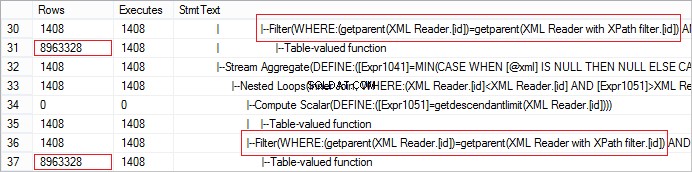
Żądanie można łatwo zoptymalizować za pomocą CROSS APPLY:
SELECT
t2.c2.value('@name', 'SYSNAME')
, t2.c2.value('@order', 'INT')
, t2.c2.value('@visible', 'BIT')
, t.c.value('@name', 'SYSNAME')
, t.c.value('@schema', 'SYSNAME')
, t.c.value('@object', 'SYSNAME')
FROM @xml.nodes('tables/table') t(c)
CROSS APPLY t.c.nodes('column') t2(c2) Porównajmy czas wykonania:
(1408 row(s) affected) SQL Server Execution Times: CPU time = 10125 ms, elapsed time = 10135 ms. (1408 row(s) affected) SQL Server Execution Times: CPU time = 78 ms, elapsed time = 156 ms.
Jak widać na przykładzie, żądanie z CROSS APPLY działa natychmiast.
Dziękuję za uwagę. Mam nadzieję, że ten artykuł był przydatny. Zachęcamy do zadawania pytań, zostawiania komentarzy i sugestii dotyczących tego artykułu.