Ograniczenia w SQL Server to wstępnie zdefiniowane reguły, które można wymusić na jednej lub wielu kolumnach. Te ograniczenia pomagają zachować integralność, niezawodność i dokładność wartości przechowywanych w tych kolumnach. Ograniczenia można tworzyć za pomocą instrukcji CREATE TABLE lub ALTER Table. Jeśli użyjesz instrukcji ALTER TABLE, SQL Server sprawdzi istniejące dane kolumn przed utworzeniem ograniczenia.
Jeśli wstawisz dane w kolumnie, która spełnia kryteria reguły ograniczenia, SQL Server wstawi dane pomyślnie. Jeśli jednak dane naruszają ograniczenie, instrukcja INSERT jest przerywana z komunikatem o błędzie.
Załóżmy na przykład, że masz tabelę [Pracownik], w której przechowywane są dane pracowników Twojej organizacji, w tym ich wynagrodzenie. Istnieje kilka praktycznych zasad dotyczących wartości w kolumnie wynagrodzeń.
- Kolumna nie może mieć wartości ujemnych, takich jak -10 000 lub -15 000 USD.
- Chcesz również określić maksymalną wartość wynagrodzenia. Na przykład maksymalna pensja powinna być mniejsza niż 2 000 000 USD.
Jeśli wstawisz nowy rekord z wprowadzonym ograniczeniem, SQL Server sprawdzi poprawność wartości zgodnie ze zdefiniowanymi regułami.
Wstawiona wartość:
Wynagrodzenie 80 000:wstawiono pomyślnie
Wynagrodzenie -50 000: Błąd
W tym artykule omówimy następujące ograniczenia w SQL Server.
- NIE BRAK
- UNIKALNE
- SPRAWDŹ
- KLUCZ PODSTAWOWY
- KLUCZ OBCY
- DOMYŚLNE
Ograniczenie NIEZEROWE
Domyślnie SQL Server umożliwia przechowywanie wartości NULL w kolumnach. Te wartości NULL nie reprezentują prawidłowych danych.
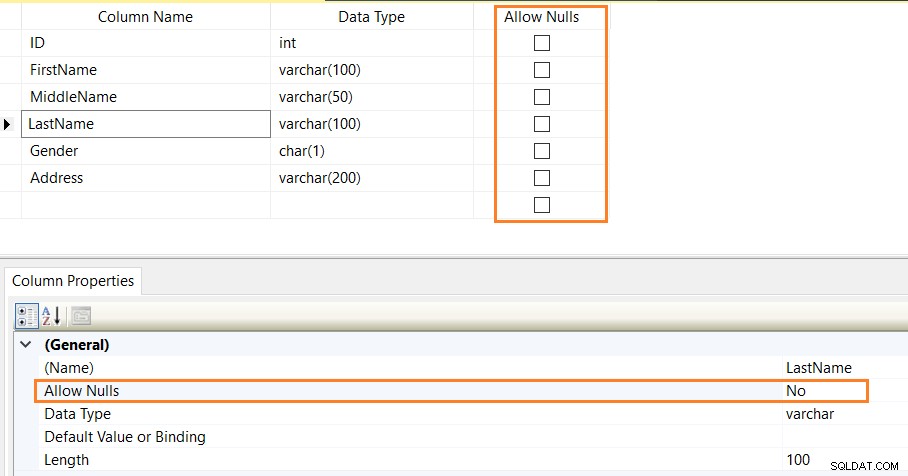
Na przykład każdy pracownik w organizacji musi mieć identyfikator Emp ID, imię, płeć i adres. Dlatego możesz określić kolumnę z ograniczeniami NOT NULL, aby zawsze zapewnić prawidłowe wartości.
Poniższy skrypt CREATE TABLE definiuje ograniczenia NOT NULL dla kolumn [ID],[Imię],[Nazwisko],[Płeć] i [Adres].
CREATE TABLE Employees ( ID INT NOT NULL, [FirstName] Varchar(100) NOT NULL, [MiddleName] Varchar(50) NULL, [LastName] Varchar(100) NOT NULL, [Gender] char(1) NOT NULL, [Address] Varchar(200) NOT NULL )
Aby sprawdzić poprawność zachowania ograniczeń NOT NULL, używamy następujących instrukcji INSERT.
- Wstaw wartości dla wszystkich kolumn (NULL i NOT NULL) – wstawia pomyślnie
INSERT INTO Employees (ID,[FirstName],[MiddleName],[LastName],[gender],[Address]) VALUES(1,'Raj','','Gupta','M','India')
- Wstaw wartości dla kolumn z właściwością NOT NULL – wstawia się pomyślnie
INSERT INTO Employees (ID,[FirstName],[LastName],[gender],[Address]) VALUES(2, 'Shyam','Agarwal','M','UK')
- Pomiń wstawianie wartości dla kolumny [LastName] mającej ograniczenia NOT NULL – Niepowodzenie+
INSERT INTO Employees (ID,[FirstName],[gender],[Address]) VALUES(3,'Sneha','F','India')
Ostatnia instrukcja INSERT wywołała błąd – Nie można wstawić wartości NULL do kolumny .

Ta tabela zawiera następujące wartości wstawione w tabeli [Pracownicy].
Załóżmy, że nie wymagamy wartości NULL w kolumnie [MiddleName] zgodnie z wymaganiami HR. W tym celu możesz użyć instrukcji ALTER TABLE.
ALTER TABLE Employees ALTER COLUMN [MiddleName] VARCHAR(50) NOT NULL
Ta instrukcja ALTER TABLE kończy się niepowodzeniem z powodu istniejących wartości kolumny [MiddleName]. Aby wymusić ograniczenie, musisz wyeliminować te wartości NULL, a następnie uruchomić instrukcję ALTER.
UPDATE Employees SET [MiddleName]='' WHERE [MiddleName] IS NULL Go ALTER TABLE Employees ALTER COLUMN [MiddleName] VARCHAR(50) NOT NULL
Możesz sprawdzić poprawność ograniczeń NOT NULL również za pomocą projektanta tabel SSMS.
UNIKALNE ograniczenie
Ograniczenie UNIQUE w SQL Server zapewnia, że nie masz zduplikowanych wartości w pojedynczej kolumnie lub kombinacji kolumn. Te kolumny powinny być częścią ograniczeń UNIQUE. SQL Server automatycznie tworzy indeks po zdefiniowaniu ograniczeń typu UNIQUE. W kolumnie możesz mieć tylko jedną unikalną wartość (łącznie z NULL).
Na przykład utwórz [DemoTable] z kolumną [ID] z ograniczeniem UNIQUE.
CREATE TABLE DemoTable ( [ID] INT UNIQUE NOT NULL, [EmpName] VARCHAR(50) NOT NULL )
Następnie rozwiń tabelę w SSMS, a otrzymasz unikalny indeks (nie klastrowany), jak pokazano poniżej.
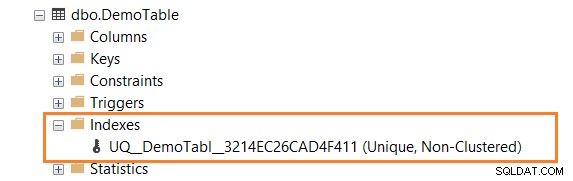
Kliknij indeks prawym przyciskiem myszy i wygeneruj jego skrypt. Jak pokazano poniżej, do ograniczenia używa słowa kluczowego ADD UNIQUE NOCLUSTERED.

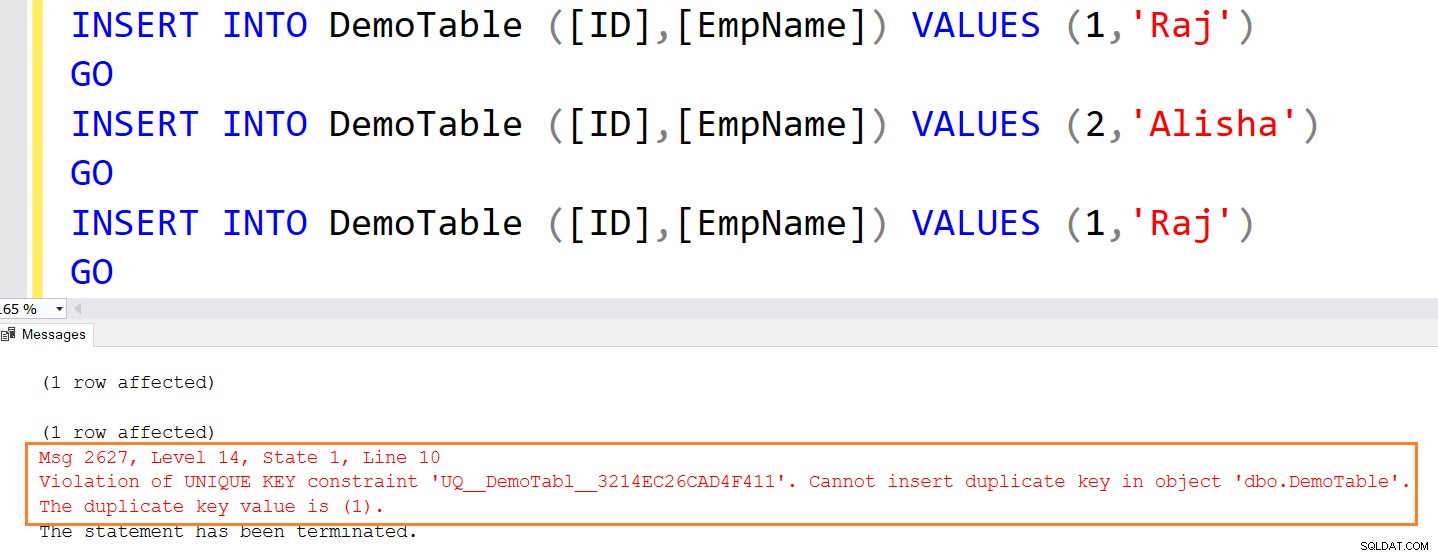
Poniższa instrukcja insert wyświetla błąd, ponieważ próbuje wstawić zduplikowane wartości.
INSERT INTO DemoTable ([ID],[EmpName]) VALUES (1,'Raj') GO INSERT INTO DemoTable ([ID],[EmpName]) VALUES (2,'Alisha') GO INSERT INTO DemoTable ([ID],[EmpName]) VALUES (1,'Raj') GO
SPRAWDŹ ograniczenie
Ograniczenie CHECK w SQL Server definiuje prawidłowy zakres wartości, które można wstawić do określonych kolumn. Ocenia każdą wstawioną lub zmodyfikowaną wartość, a jeśli jest spełniona, instrukcja SQL jest zakończona pomyślnie.
Poniższy skrypt SQL umieszcza ograniczenie dla kolumny [Wiek]. Jego wartość powinna być większa niż 18 lat.
CREATE TABLE DemoCheckConstraint ( ID INT PRIMARY KEY, [EmpName] VARCHAR(50) NULL, [Age] INT CHECK (Age>18) ) GO
Wstawmy dwa rekordy w tej tabeli. Zapytanie pomyślnie wstawia pierwszy rekord.
INSERT INTO DemoCheckConstraint (ID,[EmpName],[Age])VALUES (1,'Raj',20) Go INSERT INTO DemoCheckConstraint (ID,[EmpName],[Age])VALUES (2,'Sohan',17) GO
Druga instrukcja INSERT nie powiedzie się, ponieważ nie spełnia warunku ograniczenia CHECK.
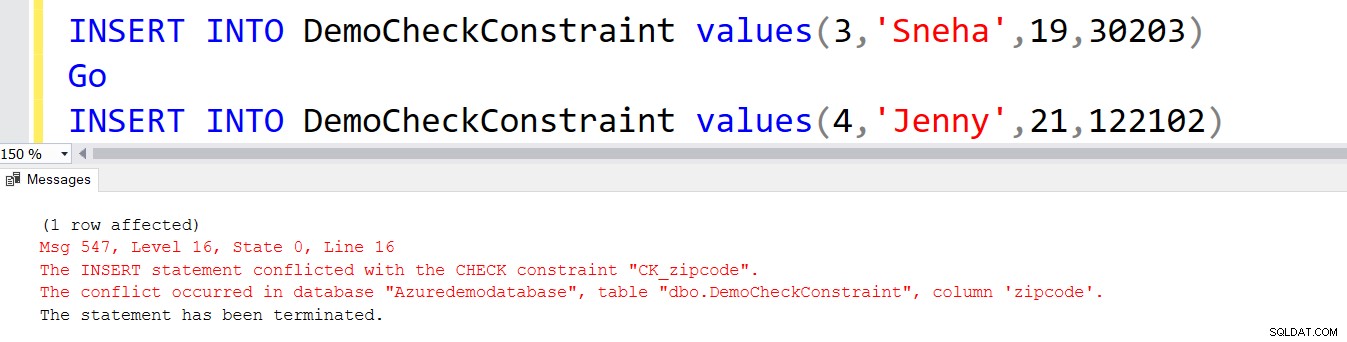
Innym przypadkiem użycia ograniczenia CHECK jest przechowywanie prawidłowych wartości kodów pocztowych. W poniższym skrypcie dodajemy nową kolumnę [KodZip] i używa ona ograniczenia CHECK do sprawdzania wartości.
ALTER TABLE DemoCheckConstraint ADD zipcode int
GO
ALTER TABLE DemoCheckConstraint
ADD CONSTRAINT CK_zipcode CHECK (zipcode LIKE REPLICATE ('[0-9]', 5)) To ograniczenie CHECK nie zezwala na nieprawidłowe kody pocztowe. Na przykład druga instrukcja INSERT generuje błąd.
INSERT INTO DemoCheckConstraint values(3,'Sneha',19,30203) Go INSERT INTO DemoCheckConstraint values(4,'Jenny',21,122102)
Ograniczenie klucza podstawowego
Ograniczenie PRIMARY KEY w SQL Server jest popularnym wyborem wśród specjalistów od baz danych do implementowania unikalnych wartości w tabeli relacyjnej. Łączy ograniczenia UNIQUE i NOT NULL. SQL Server automatycznie tworzy indeks klastrowy, gdy zdefiniujemy ograniczenie na klucz podstawowy. Możesz użyć pojedynczej kolumny lub zestawu kombinacji do zdefiniowania unikalnych wartości w rzędzie.
Jego głównym celem jest wymuszenie integralności tabeli przy użyciu unikalnej jednostki lub wartości kolumny.
Jest podobny do ograniczenia UNIQUE z następującymi różnicami.
| KLUCZ PODSTAWOWY | UNIKALNY KLUCZ |
| Używa unikalnego identyfikatora dla każdego wiersza w tabeli. | Unikatowo definiuje wartości w kolumnie tabeli. |
| Nie można wstawić wartości NULL w kolumnie PRIMARY KEY. | Może przyjąć jedną wartość NULL w unikalnej kolumnie klucza. |
| Tabela może mieć tylko jedno ograniczenie PRIMARY KEY. | Możesz utworzyć wiele ograniczeń UNIQUE KEY w SQL Server. |
| Domyślnie tworzy indeks klastrowy dla kolumn PRIMARY KEY. | UNIKALNY KLUCZ tworzy indeks nieklastrowy dla kolumn klucza podstawowego. |
Poniższy skrypt definiuje KLUCZ PODSTAWOWY w kolumnie ID.
CREATE TABLE PrimaryKeyDemo ( ID INT PRIMARY KEY, [Name] VARCHAR(100) NULL )
Jak pokazano poniżej, po zdefiniowaniu klucza podstawowego w kolumnie ID masz klastrowany indeks kluczy.
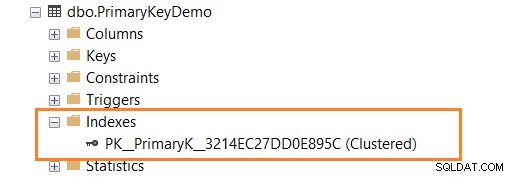
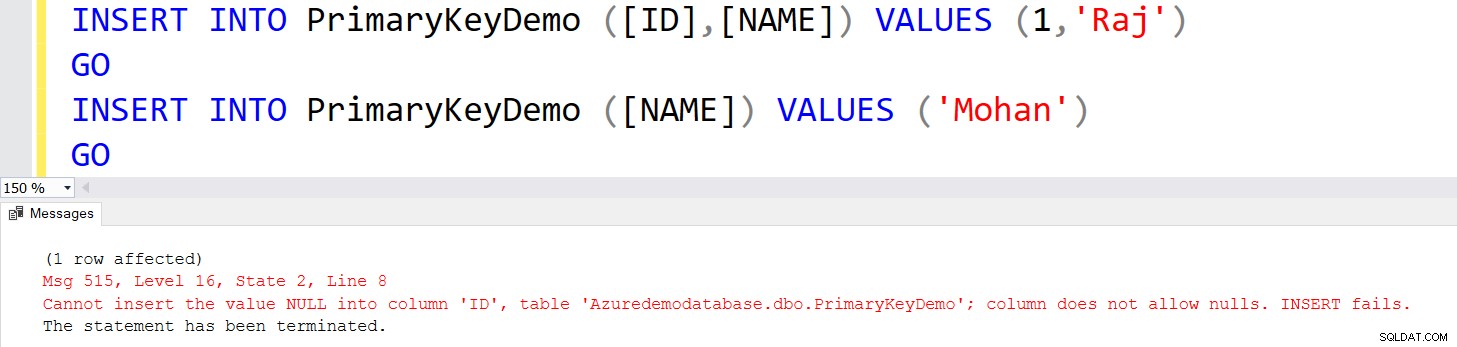
Wstawmy rekordy do tabeli [PrimaryKeyDemo] z następującymi instrukcjami INSERT.
INSERT INTO PrimaryKeyDemo ([ID],[NAME]) VALUES (1,'Raj')
GO
INSERT INTO PrimaryKeyDemo ([NAME]) VALUES ('Mohan')
GO Pojawia się błąd w drugiej instrukcji INSERT, ponieważ próbuje ona wstawić wartość NULL.
Podobnie, jeśli spróbujesz wstawić zduplikowane wartości, otrzymasz następujący komunikat o błędzie.

Ograniczenie klucza obcego
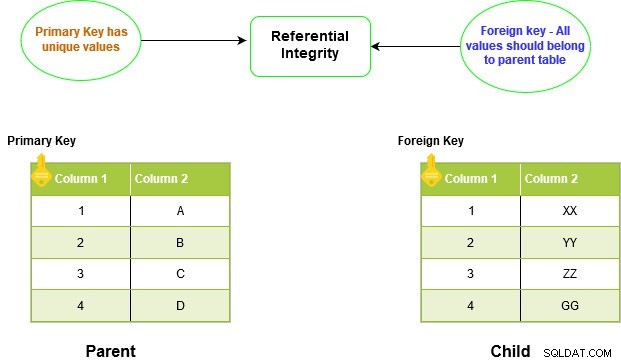
Ograniczenie FOREIGN KEY w SQL Server tworzy relacje między dwiema tabelami. Ta relacja jest znana jako relacja rodzic-dziecko. Wymusza integralność referencyjną w SQL Server.
Klucz obcy tabeli podrzędnej powinien mieć odpowiedni wpis w kolumnie nadrzędnego klucza podstawowego. Nie można wstawić wartości do tabeli podrzędnej bez uprzedniego wstawienia jej do tabeli nadrzędnej. Podobnie, najpierw musimy usunąć wartość z tabeli podrzędnej, zanim będzie można ją usunąć z tabeli nadrzędnej.
Ponieważ nie możemy mieć zduplikowanych wartości w ograniczeniu PRIMARY KEY, nie zezwala ono również na duplikowanie lub NULL w tabeli podrzędnej.
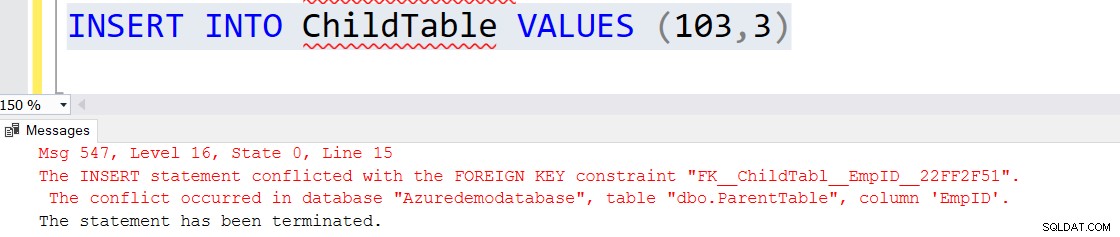
Poniższy skrypt SQL tworzy tabelę nadrzędną z kluczem podstawowym i tabelę podrzędną z odniesieniem do klucza podstawowego i obcego do kolumny tabeli nadrzędnej [EmpID].
CREATE TABLE ParentTable ( [EmpID] INT PRIMARY KEY, [Name] VARCHAR(50) NULL ) GO CREATE TABLE ChildTable ( [ID] INT PRIMARY KEY, [EmpID] INT FOREIGN KEY REFERENCES ParentTable(EmpID) )
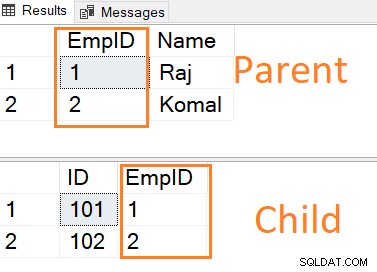
Wstaw rekordy w obu tabelach. Zwróć uwagę, że wartość klucza obcego tabeli podrzędnej ma wpis w tabeli nadrzędnej.
INSERT INTO ParentTable VALUES (1,'Raj'),(2,'Komal') INSERT INTO ChildTable VALUES (101,1),(102,2)
Jeśli spróbujesz wstawić rekord bezpośrednio w tabeli podrzędnej, który nie odwołuje się do klucza podstawowego tabeli nadrzędnej, pojawi się następujący komunikat o błędzie.
Ograniczenie DOMYŚLNE
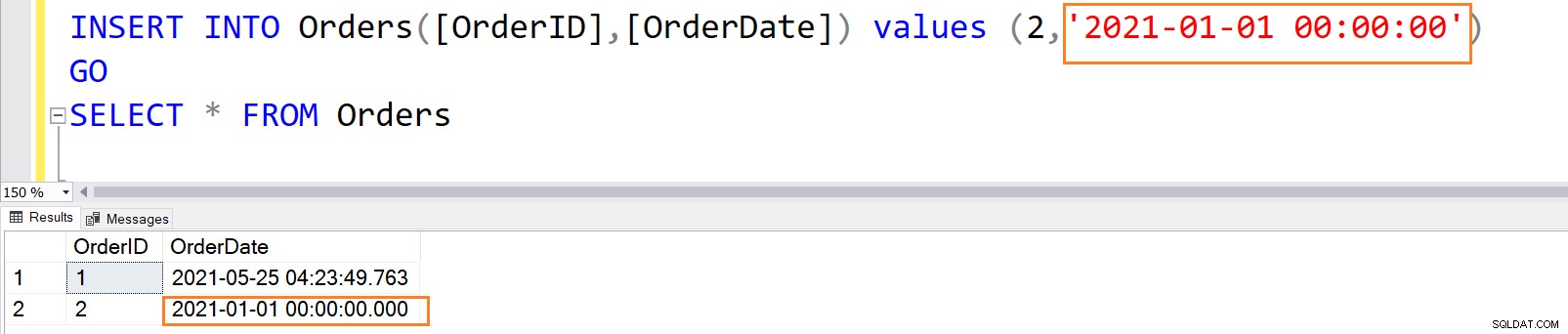
Ograniczenie DEFAULT w SQL Server zapewnia wartość domyślną dla kolumny. Jeśli nie określimy wartości w instrukcji INSERT dla kolumny z ograniczeniem DEFAULT, SQL Server użyje domyślnej przypisanej wartości. Załóżmy na przykład, że tabela zamówień zawiera rekordy dla wszystkich zamówień klientów. Możesz użyć funkcji GETDATE(), aby przechwycić datę zamówienia bez określania żadnej wyraźnej wartości.
CREATE TABLE Orders ( [OrderID] INT PRIMARY KEY, [OrderDate] DATETIME NOT NULL DEFAULT GETDATE() ) GO
Aby wstawić rekordy do tej tabeli, możemy pominąć przypisywanie wartości dla kolumny [DataZamówienia].
INSERT INTO Orders([OrderID]) values (1) GO
WYBIERZ * Z Zamówienia 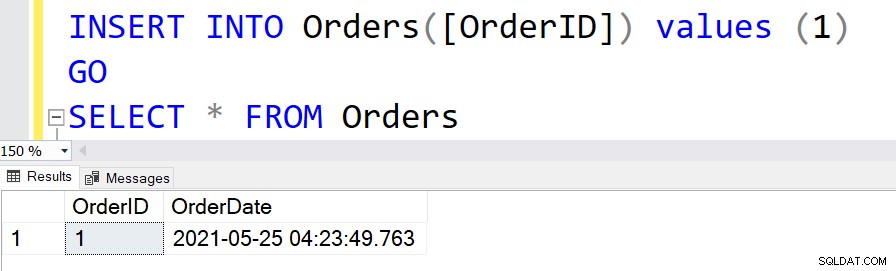
Gdy kolumna ograniczenia DEFAULT określa jawną wartość, SQL Server przechowuje tę jawną wartość zamiast wartości domyślnej.
Korzyści z ograniczeń
Ograniczenia w SQL Server mogą być korzystne w następujących przypadkach:
- Egzekwowanie logiki biznesowej
- Egzekwowanie integralności referencyjnej
- Zapobieganie przechowywaniu niewłaściwych danych w tabelach SQL Server
- Wymuszanie unikalności danych kolumn
- Poprawa wydajności zapytań, ponieważ optymalizator zapytań jest świadomy unikalnych danych i weryfikuje zestawy wartości
- Zapobieganie przechowywaniu wartości NULL w tabelach SQL
- Pisanie kodów, aby uniknąć NULL podczas wyświetlania danych w aplikacji