W poprzednim artykule omówiliśmy model schematu gwiazdy. Schemat płatka śniegu jest obok schematu gwiaździstego pod względem jego znaczenia w modelowaniu hurtowni danych. Został opracowany na podstawie schematu gwiazdy i ma pewne zalety w stosunku do swojego poprzednika. Ale te zalety mają swoją cenę. W tym artykule omówimy, kiedy i jak korzystać ze schematu płatka śniegu.
Schemat płatka śniegu
Nazwa schematu płatka śniegu wzięła się stąd, że tabele wymiarów rozgałęziają się i wyglądają jak płatek śniegu. Kiedy spojrzymy na powyższy model, zauważymy, że jest to tabela faktów otoczona kilkoma tabelami wymiarów, z których niektóre wykonują wspomniane wcześniej rozgałęzienia. W przeciwieństwie do schematu gwiaździstego, tabele wymiarów w schemacie płatka śniegu mogą mieć własne kategorie.
Główną ideą stojącą za schematem płatka śniegu jest to, że tabele wymiarów są całkowicie znormalizowane. Każda tabela wymiarów może być opisana przez co najmniej jedną tabelę przeglądową. Każda tabela przeglądowa może być opisana przez jedną lub więcej dodatkowych tabel przeglądowych. Jest to powtarzane, aż model zostanie w pełni znormalizowany. Proces normalizacji tabel wymiarów schematu gwiazdy nazywa się płatkiem śniegu.
W tym artykule dużo usłyszysz o normalizacji. Czym jest normalizacja? Zasadniczo organizuje bazę danych w sposób minimalizujący nadmiarowość i chroniący integralność danych. Sprawdź ten post, aby dowiedzieć się więcej o normalizacji i denormalizacji.
Przykład schematu płatka śniegu:model sprzedaży
Wcześniej używaliśmy schematu gwiaździstego do modelowania fikcyjnego działu sprzedaży — byłoby to podobne do bazy danych używanej do śledzenia działań sprzedażowych i wyników. Model ma pięć wymiarów:produkt , czas , sklep , sprzedaż typ i pracownik . W fact_sales stół, cena i ilość są przechowywane i grupowane na podstawie wartości w tabelach wymiarów. Dla odświeżenia, spójrz na poniższy model sprzedaży schematu gwiazdy:
Oto ten sam model zorganizowany jako schemat płatka śniegu:
dim_employee i dim_sales_type tabele wymiarów są dokładnie takie same jak w modelu schematu gwiazdy, ponieważ są już znormalizowane.
Z drugiej strony zastosowaliśmy reguły normalizacji do pozostałych tabel wymiarów.


dim_product tabela wymiarów ze schematu gwiazdy jest podzielona na dwie tabele w modelu płatka śniegu. dim_product_type tabela została dodana w celu odniesienia do typu dopasowania w dim_product stół. Dzięki temu uniknęliśmy niektórych problemów z integralnością danych.
Logiczne jest założenie, że w ramach procesu ETL wprowadzimy już wszystkie nazwy produktów i powiązane z nimi typy, ale załóżmy, że musimy dodać więcej nazw i typów produktów. W schemacie gwiazdy możemy omyłkowo wpisać do tabeli niewłaściwy typ produktu. W schemacie płatka śniegu:
- Jeśli napotkamy nową nazwę typu produktu, możemy dodać nowy typ produktu, a następnie powiązać ten typ z nowo dodanym rekordem. Może to jednak spowodować, że użytkownik wprowadzi błędne informacje, tak jak w schemacie gwiazdy.
- Możemy sprawdzić, czy nazwa produktu, który chcemy dodać, już istnieje. Jeśli tak, możemy uzyskać jego identyfikator; jeśli nie, pojawi się ostrzeżenie z pytaniem, czy chcemy dodać nowy produkt i powiązany typ.

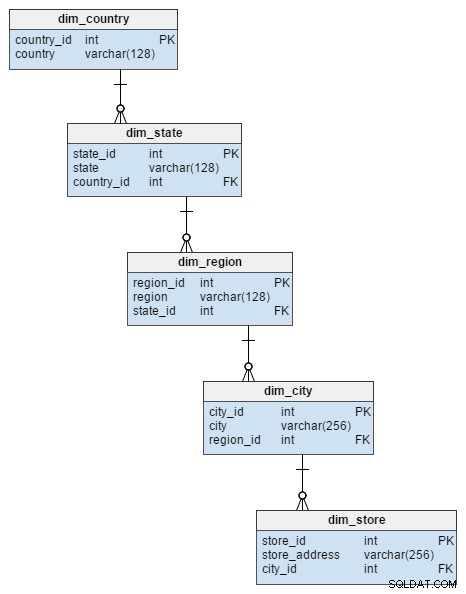
dim_store tabela wymiarów ze schematu gwiaździstego jest reprezentowana przez 5 tabel w schemacie płatka śniegu. Dzielą one atrybuty miasta, regionu, stanu i kraju, które były przechowywane w dim_store stół. Normalizacja tej tabeli nie tylko pozwoliła uniknąć ryzyka integralności danych, ale także pozwoliła zaoszczędzić trochę miejsca na dysku.
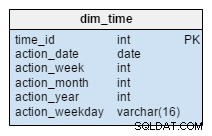
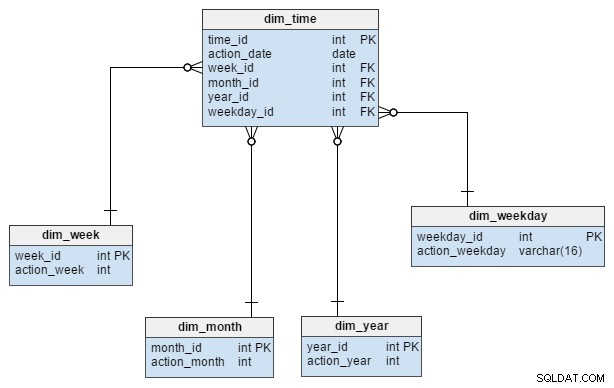
dim_time wymiar jest reprezentowany przez pięć tabel. Możemy pomyśleć o dim_week , dim_month , dim_year i dim_weekday tabele jako słowniki opisujące dim_time stół.
dim_week , dim_month , dim_year i dim_weekday tabele to cztery różne hierarchie używane do opisania naszego wymiaru czasu. W razie potrzeby moglibyśmy dodać więcej wymiarów, takich jak ćwiartki lub inne powiązane tabele. W tym przykładzie dim_month to słownik zawierający 12 miesięcy; tylko z tego wymiaru nie wiemy, do którego roku należy dany miesiąc; to jest funkcja dim_year stół.
Przykład schematu płatka śniegu:model zamówień dostaw
Inny omawiany przez nas mart danych dotyczył zamówień na dostawy. Chodzi o to, aby przechowywać i agregować wszystkie dane zamówienia dostaw dla następujących czterech wymiarów:produkt , czas , dostawca i pracownik . Jeszcze raz przyjrzymy się odpowiedniemu schematowi gwiazdy:
Konwertując to na schemat płatka śniegu, otrzymujemy następujący model:
W dim_product , dim_time i dim_supplier tabele wymiarów.
Zalety i wady schematu płatka śniegu
Istnieją dwie główne zalety do schematu płatka śniegu:
- Lepsza jakość danych (dane są bardziej uporządkowane, więc problemy z integralnością danych są zmniejszone)
- Mniej miejsca na dysku jest używane niż w modelu zdenormalizowanym
Najbardziej zauważalna wada dla modelu płatka śniegu jest to, że wymaga bardziej złożonych zapytań. Te zapytania, z ich zwiększoną liczbą złączeń, mogą znacznie obniżyć wydajność.
Przepiszemy to samo zapytanie, które zostało użyte w artykule o schemacie gwiaździstym dla modelu sprzedaży schematu płatka śniegu. Oto zapytanie potrzebne do zwrócenia ilości wszystkich produktów typu telefon sprzedanych w berlińskich sklepach w 2016 roku:
SELECT dim_store.store_address, SUM(fact_sales.quantity) AS quantity_sold FROM fact_sales INNER JOIN dim_product ON fact_sales.product_id = dim_product.product_id INNER JOIN dim_product_type ON dim_product.product_type_id = dim_product_type.product_type_id INNER JOIN dim_time ON fact_sales.time_id = dim_time.time_id INNER JOIN dim_year ON dim_time.year_id = dim_year.year_id INNER JOIN dim_store ON fact_sales.store_id = dim_store.store_id INNER JOIN dim_city ON dim_store.city_id = dim_city.city_id WHERE dim_year.action_year = 2016 AND dim_city.city = 'Berlin' AND dim_product_type.product_type_name = 'phone' GROUP BY dim_store.store_id, dim_store.store_address
Schemat Starflake
Schemat gwiezdnego płatka to połączenie schematu płatka śniegu i gwiezdnego. Możemy zobaczyć to jako schemat płatka śniegu, w którym niektóre tabele wymiarów są zdenormalizowane. Przy prawidłowym użyciu schemat gwiezdnego płatka może dać najlepsze podejście do obu światów. Oczywiście część modelu z płatkami śniegu powinna oszczędzać miejsce na dysku, podczas gdy część w kształcie gwiazdy powinna poprawić wydajność.
Powyższy model to w zasadzie model płatka śniegu ze zdenormalizowanym dim_time stół. Ponieważ ten schemat zmniejsza liczbę wymaganych sprzężeń zapytań, może to poprawić wydajność. Z drugiej strony nie stracimy znacznej ilości miejsca na dysku, ponieważ większość atrybutów tabeli i atrybutów kluczy obcych współdzieli int typ.
Schemat galaktyki
W hurtowni danych schemat galaktyki występuje wtedy, gdy co najmniej dwie tabele faktów współdzielą co najmniej jedną tabelę wymiarów. Jednym z powodów używania tego schematu jest oszczędność miejsca na dysku. Stworzyliśmy przykładowy schemat galaktyki poniżej:
Tutaj mamy dwie tabele faktów, fact_sales i fact_supply_order , które bezpośrednio współdzielą tabele trzech wymiarów:dim_product , dim_employee i dim_time . Zauważ, że nawet dim_store i dim_supplier współdziel tę samą tabelę wyszukiwania, dim_city .
W ten sposób zaoszczędzimy miejsce, ale zanim połączymy dwie hurtownie danych (w tym przypadku zamówienia sprzedaży i zaopatrzenia) w jeden schemat galaktyki, musimy pamiętać o kilku rzeczach:
- Czy za dołączeniem do nich kryje się jakaś logika? Np. Czy oba magazyny danych byłyby używane przez ten sam dział?
- Czy jesteśmy pewni, że potrzebujemy dokładnie tego samego wymiaru i granulacji? dla obu data martów?
Schemat płatka śniegu jest często używany w modelowaniu danych. Może to być właściwy wybór w sytuacjach, w których miejsce na dysku jest ważniejsze niż wydajność. Jeśli chcemy zachować równowagę między oszczędnością miejsca a wydajnością, możemy użyć schematu starflake. Jednak właściwe dopasowanie do konkretnego problemu zależy od wielu parametrów. To jeden z obszarów IT, w którym możemy „bawić się” czynnikami, aby znaleźć najlepsze rozwiązanie.