W poprzednim artykule omówiliśmy wymagania dotyczące indeksu SQL Server i kwestie dotyczące wydajności. Jeśli chodzi o wydajność bazy danych, strojenie wydajności jest bez wątpienia jedną z najważniejszych i najbardziej złożonych funkcji. Składa się z wielu różnych obszarów, takich jak optymalizacja zapytań SQL, dostrajanie indeksów i dostrajanie zasobów systemowych, z których wszystkie należy wykonać poprawnie, aby pomyślnie szybko pobrać dane.
Istnieje kilka ważnych obszarów, które należy wziąć pod uwagę, jeśli chodzi o indeksy SQL Server, ponieważ mogą one mieć znaczący wpływ zarówno na wysiłki związane z dostrajaniem wydajności, jak i ogólną wydajność bazy danych. Poniżej znajduje się kilka szczegółów na temat każdego z nich oraz kluczowych ról, jakie odgrywają.
Najlepsze praktyki dotyczące indeksowania SQL Server
1. Dowiedz się, jak projekt bazy danych wpływa na indeksy SQL Server
Wymagania dotyczące indeksowania różnią się między bazami danych przetwarzania transakcji online (OLTP) i przetwarzania analitycznego online (OLAP).
W bazie danych OLTP użytkownicy często wykonują operacje odczytu i zapisu, wstawiając nowe dane i modyfikując istniejące. Używają zapytań języka manipulacji danymi (Insert, Update, Delete) wraz z instrukcjami Select do pobierania i modyfikowania danych. W przypadku baz danych OLTP najlepiej utworzyć indeksy w kolumnie Selected tabeli. Wiele indeksów może mieć negatywny wpływ na wydajność i obciążać zasoby systemowe. Zamiast tego zaleca się utworzenie minimalnej liczby indeksów, które mogą spełnić Twoje wymagania dotyczące indeksowania. Z kolei w bazach danych OLAP używasz głównie instrukcji Select do pobierania danych do dalszych celów analitycznych. W takim przypadku możesz dodać więcej indeksów z wieloma kolumnami klucza na indeks. Możesz także wykorzystać indeksy magazynu kolumn do szybszego pobierania danych w zapytaniach hurtowni danych
2. Utwórz indeksy zgodnie z wymaganiami dotyczącymi obciążenia
Tworząc nową tabelę w swojej bazie danych, nie dodawaj indeksów na ślepo. Czasami programiści umieszczają na nim jeden indeks klastrowy i kilka indeksów nieklastrowych, nie szukając zapytań korzystających z tych indeksów. Może istnieć indeks, który nie spełnia wymagań optymalizatora zapytań; dlatego należy odpowiednio przeanalizować obciążenie i zapytania SQL (procedury składowane, funkcje, widoki i zapytania ad-hoc). Możesz przechwycić obciążenie za pomocą profilera SQL, rozszerzonych zdarzeń i dynamicznych widoków zarządzania, a następnie utworzyć indeksy w celu optymalizacji zapytań intensywnie korzystających z zasobów.
3. Twórz indeksy dla najczęściej używanych zapytań
Ważne jest, aby pogrupować obciążenia dla najczęściej używanych zapytań w systemie. Tworząc najlepsze indeksy dla tych zapytań, będzie to najmniej obciążać Twój system.
4. Zastosuj sprawdzone metody dotyczące kolumn indeksu SQL Server
Ponieważ w tabeli może być wiele kolumn, oto kilka uwag dotyczących kolumn kluczy indeksu.
- Kolumny z tekstem, obrazem, ntext, varchar(max), nvarchar(max) i varbinary(max) nie mogą być używane w kolumnach klucza indeksu.
- Zaleca się użycie typu danych całkowitych w kolumnie klucza indeksu. Ma niewielkie zapotrzebowanie na miejsce i działa wydajnie. Z tego powodu będziesz chciał utworzyć kolumnę klucza podstawowego, zwykle na typie danych całkowitych.
- W indeksie XML można używać tylko typu danych XML.
- Zastanów się nad utworzeniem klucza podstawowego dla kolumny z unikalnymi wartościami. Jeśli tabela nie zawiera żadnych unikatowych kolumn wartości, można zdefiniować kolumnę tożsamości dla typu danych całkowitych. Klucz podstawowy tworzy również indeks klastrowy dla dystrybucji wierszy.
- Możesz rozważyć kolumnę z wartościami Unique i Not NULL jako użytecznym kandydatem na klucz indeksu.
- Należy zbudować indeks na podstawie predykatów w klauzuli Where. Na przykład możesz rozważyć kolumny użyte w klauzuli Where, sprzężenia SQL, takie jak, sortowanie według, grupowanie według predykatów i tak dalej.
- Tabele należy łączyć w taki sposób, aby zmniejszyć liczbę wierszy w pozostałej części zapytania. Pomoże to optymalizatorowi zapytań przygotować plan wykonania przy minimalnych zasobach systemowych.
- Jeśli używasz wielu kolumn dla klucza indeksu, ważne jest również rozważenie ich pozycji w kluczu indeksu.
- Powinieneś również rozważyć użycie uwzględnionych kolumn w swoich indeksach.
5. Przeanalizuj dystrybucję danych w kolumnach indeksu SQL Server
Należy sprawdzić dystrybucję danych w kolumnach klucza indeksu SQL Server. Kolumna z nieunikatowymi wartościami może spowodować opóźnienie w pobieraniu danych i skutkować długotrwałą transakcją. Możesz analizować rozkład danych za pomocą histogramu w statystykach.
6. Użyj kolejności sortowania danych
Należy również wziąć pod uwagę wymagania dotyczące sortowania danych w zapytaniach i indeksach. Domyślnie SQL Server sortuje dane w kolejności rosnącej w indeksie. Załóżmy, że tworzysz indeks w porządku rosnącym, ale Twoje zapytania używają klauzuli Order By do sortowania danych w kolejności malejącej.
Na przykład spójrz na rzeczywisty plan wykonania następującego zapytania.
SELECT [SalesOrderID],
[UnitPrice]
FROM [AdventureWorks].[Sales].[SalesOrderDetail]
ORDER BY UnitPrice DESC,
SalesOrderID ASC;
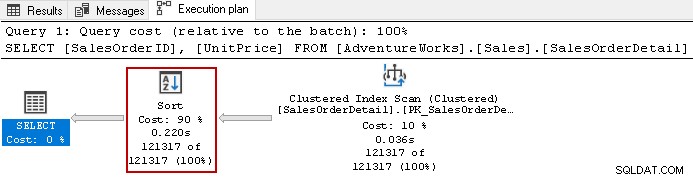
Używa kosztownego operatora sortowania z całkowitym kosztem 90% w tym zapytaniu. Zdecydowaliśmy się zbudować indeks nieklastrowy na [CenaJednostkowa] i [SalesOrderID]. Używa domyślnej kolejności sortowania dla obu kolumn w indeksie.
CREATE NONCLUSTERED INDEX IX_SalesOrderDetail_Unitprice
ON [AdventureWorks].[Sales].[SalesOrderDetail]
(UnitPrice ASC, SalesOrderID ASC);
Ponownie uruchomiliśmy instrukcję Select, a optymalizator zapytań nadal używa operatora sortowania. Może używać indeksu nieklastrowego, ale sortuje dane, aby przygotować wynik.
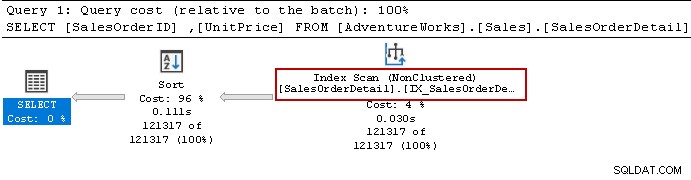
Odtwórzmy indeks za pomocą następującego zapytania. Tym razem sortuje dane w kolejności malejącej według [Cena jednostkowa] w definicji indeksu.
DROP INDEX IX_SalesOrderDetail_Unitprice ON [AdventureWorks].[Sales].[SalesOrderDetail];
Go CREATE NONCLUSTERED INDEX IX_SalesOrderDetail_Unitprice ON [AdventureWorks].[Sales].[SalesOrderDetail](UnitPrice DESC, SalesOrderID ASC);
Go
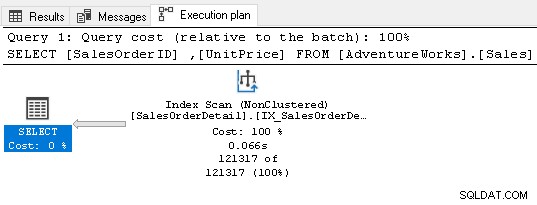
Nie wymaga teraz żadnego operatora sortowania, ponieważ indeks spełnia wymagania zapytania.
7. Użyj kluczy obcych dla indeksu SQL Server
Powinieneś utworzyć indeks na kolumnach kluczy obcych. Zaleca się utworzenie indeksu klastrowego na kluczu obcym, aby poprawić wydajność zapytania.
8. Pamiętaj o kwestiach dotyczących przechowywania indeksów SQL Server
Przydatnym aspektem do rozważenia jest również przechowywanie indeksów. SQL Server tworzy wszystkie indeksy w tej samej grupie plików tabeli. Można rozważyć oddzielną grupę plików dla indeksów i oddzielić plik fizyczny na osobnym dysku. Zwiększy to wydajność i przepustowość we/wy.
Podobnie można użyć partycjonowania tabeli do segregowania danych na wielu dyskach i grupach plików. Możesz zaprojektować indeksy partycjonowane dla tych partycji tabeli, aby poprawić współbieżny dostęp do danych.
Inną opcją jest zdefiniowanie FILLFACTOR podczas tworzenia lub przebudowy indeksu. FILLFACTOR definiuje wolną przestrzeń na stronach danych węzła liścia. Przydaje się do dalszego wprowadzania danych. Jeśli Twoje dane są statyczne i nie zmieniają się często, możesz wziąć pod uwagę wysoką wartość FILLFACTOR. Z drugiej strony, w przypadku często zmieniających się danych, możesz zostawić wystarczająco dużo miejsca na nowe wstawianie danych.
9. Znajdź brakujące indeksy
Czasami otrzymujesz informacje o brakującym indeksie SQL Server w planie wykonania zapytania. Możesz również uruchomić dynamiczne widoki zarządzania, aby znaleźć brakujące indeksy. Nie powinieneś tworzyć tych indeksów na ślepo. Jest to jedynie sugestia optymalizatora zapytań, ale nie uwzględnia istniejącego indeksu ani wymagań dotyczących obciążenia. Może również zawierać wiele kolumn w definicji indeksu, więc przejrzyj te sugestie przed jego wdrożeniem.
10. Zawsze twórz indeks klastrowy przed indeksem nieklastrowym
Jako ogólną wskazówkę należy utworzyć indeks klastrowy przed budowaniem indeksów nieklastrowanych. Jeśli tabela nie ma indeksu, indeks nieklastrowany składa się z identyfikatorów wierszy. Po utworzeniu indeksu klastrowego SQL Server musi odbudować te indeksy nieklastrowane, aby mogły wskazywać klucz indeksu klastrowego zamiast identyfikatorów wierszy.
11. Monitoruj konserwację indeksu i statystyki aktualizacji
Poniżej znajduje się kilka obszarów konserwacji, które należy monitorować, jeśli chodzi o indeksy SQL Server.
- Usuń fragmentację indeksu :należy regularnie sprawdzać fragmenty wewnętrzne i zewnętrzne, zwłaszcza w przypadku tabel z wysokimi transakcjami. Twoje zapytania mogą odpowiadać powoli, nawet jeśli masz odpowiednie indeksy dla swoich obciążeń. Silnie pofragmentowany indeks może obniżyć wydajność, ponieważ wymaga dodatkowych operacji we/wy. Możesz przeprowadzić reorg lub odbudować indeks na podstawie jego wartości fragmentacji. Zwykle należy odbudować indeks, jeśli ma fragmentację większą niż 30% i zreorganizować, jeśli ma fragmentację mniejszą niż 30%.
- Usuń nieużywane indeksy: Należy zawsze przeglądać nieużywane (bezczynne) indeksy w bazie danych, ponieważ optymalizator zapytań musi je uwzględnić dla każdego zapytania. Nieużywany indeks również zużywa pamięć i zwiększa koszty utrzymania.
- Aktualizuj statystyki: Statystyki należy okresowo aktualizować, nawet jeśli w konfiguracji bazy danych ustawiono statystyki automatycznej aktualizacji. Optymalizator zapytań może przygotować zły plan wykonania, jeśli statystyki indeksu nie zostaną zaktualizowane. Możesz zaplanować zadanie agenta, aby zaktualizować statystyki SQL Server z pełnym skanowaniem po godzinach pracy.
Więcej informacji na ten temat znajdziesz w sekcji Konserwacja indeksu SQL.
Stosowanie najlepszych praktyk dotyczących indeksowania SQL Server
Chociaż nie zawsze istnieje prosty sposób na zaprojektowanie optymalnego indeksu SQL Server, zastosowanie się do zaleceń przedstawionych w tym poście pomoże Ci poruszać się po różnych wymaganiach dotyczących indeksowania, które napotkasz w przypadku każdego typu bazy danych i jej obciążeń. Te sprawdzone metody pomogą zoptymalizować indeksy, aby poprawić wydajność bazy danych i zapewnić płynniejszy proces dostrajania wydajności.