Indeksy programu SQL Server służą do szybszego pobierania danych i ograniczania wąskich gardeł wpływających na krytyczne zasoby. Indeksy w tabeli bazy danych służą jako technika optymalizacji wydajności. Możesz się zastanawiać – w jaki sposób indeksy zwiększają wydajność zapytań? Czy są takie rzeczy jak dobre i złe indeksy? Załóżmy, że masz tabelę z 50 kolumnami, czy dobrym pomysłem jest tworzenie indeksów dla każdej z kolumn? Jeśli tworzymy wiele indeksów, czy pomaga to w szybszym wykonywaniu zapytań SQL?
Wszystkie świetne pytania, ale zanim zagłębimy się w nie, ważne jest, aby wiedzieć, dlaczego indeksy mogą być wymagane w pierwszej kolejności.
Wyobraź sobie, że odwiedzasz bibliotekę miejską, która ma kolekcję tysięcy książek. Szukasz konkretnej książki, ale jak ją znajdziesz? Jeśli przejrzałeś każdą książkę, w każdym stojaku, znalezienie jej może zająć kilka dni. To samo dotyczy bazy danych, gdy szukasz rekordu spośród milionów wierszy przechowywanych w tabeli.
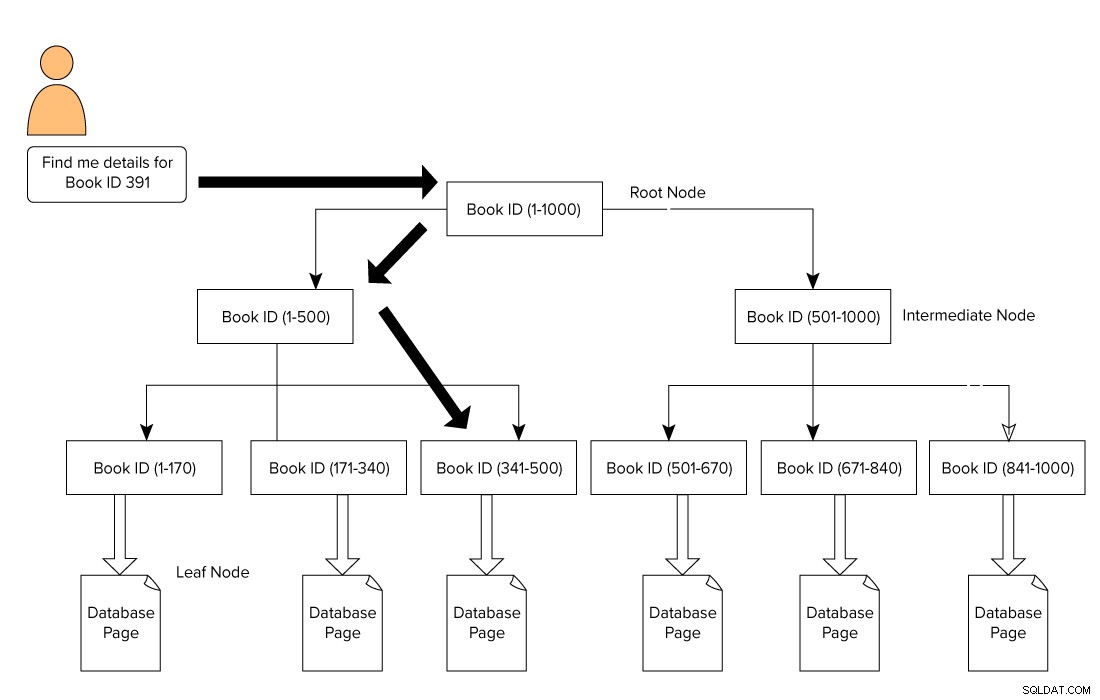
Indeks SQL Server ma kształt B-drzewa, który składa się z węzła głównego u góry i węzła liścia u dołu. W naszym przykładzie książek bibliotecznych użytkownik wysyła zapytanie w celu wyszukania książki o identyfikatorze 391. W tym przypadku aparat zapytań rozpoczyna przechodzenie od węzła głównego do węzła liścia.
Węzeł główny –> Węzeł pośredni –> Węzeł liścia.
Mechanizm zapytań szuka strony referencyjnej na poziomie pośrednim. W tym przykładzie pierwszy węzeł pośredni składa się z identyfikatorów książek od 1-500, a drugi węzeł pośredni składa się z 501-1000.
Na podstawie węzła pośredniego aparat zapytań przechodzi przez drzewo B w poszukiwaniu odpowiedniego węzła pośredniego i węzła liścia. Ten węzeł liścia może składać się z rzeczywistych danych lub wskazywać na rzeczywistą stronę danych na podstawie typu indeksu. Na poniższym obrazku widzimy, jak przeszukiwać indeks w celu wyszukania danych za pomocą indeksów SQL Server. W takim przypadku SQL Server nie musi przechodzić przez każdą stronę, czytać jej i szukać zawartości określonego identyfikatora książki.
Wpływ indeksów na wydajność SQL Server
W poprzednim przykładzie biblioteki zbadaliśmy potencjalny wpływ na wydajność indeksu. Przyjrzyjmy się wydajności zapytania z indeksem i bez niego.
Załóżmy, że potrzebujemy danych dla [SalesOrderID] 56958 z tabeli [SalesOrderDetail_Demo].
WYBIERZ *
Z [AdventureWorks].[Sprzedaż].[SzczegółyZamówieniaSprzedaży_Demo]
gdzie IDZamówieniaSprzedaży=56958
Ta tabela nie zawiera żadnych indeksów. Tabela bez żadnych indeksów nazywana jest tabelą sterty w SQL Server.
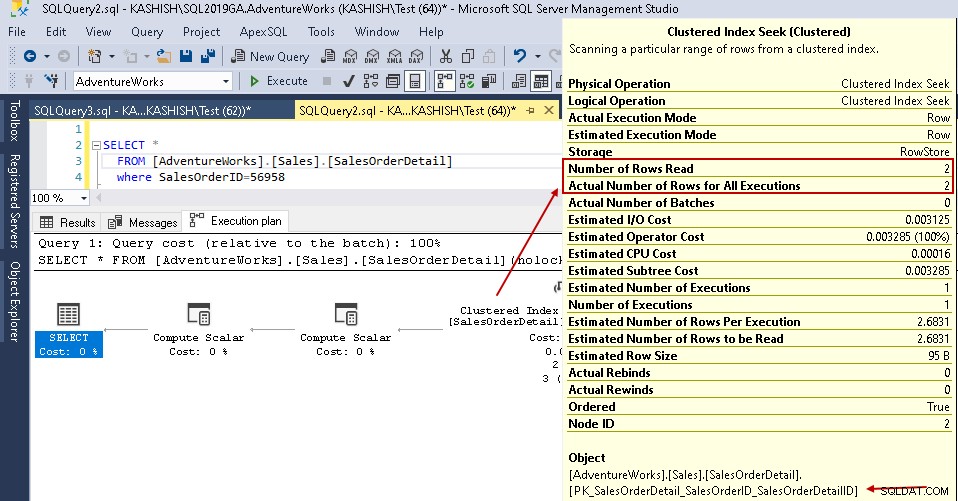
W tym miejscu możesz uruchomić powyższe oświadczenie Select i wyświetlić rzeczywisty plan wykonania. Ta tabela zawiera 121317 rekordów. Wykonuje skanowanie tabeli, co oznacza, że odczytuje wszystkie wiersze w tabeli, aby znaleźć określony [SalesOrderID].
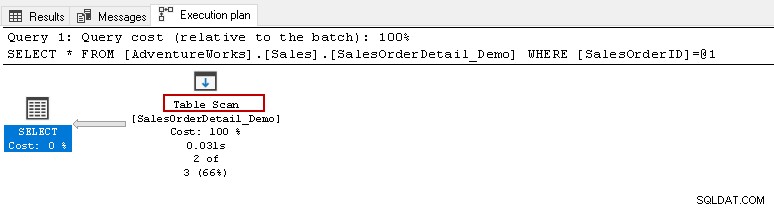
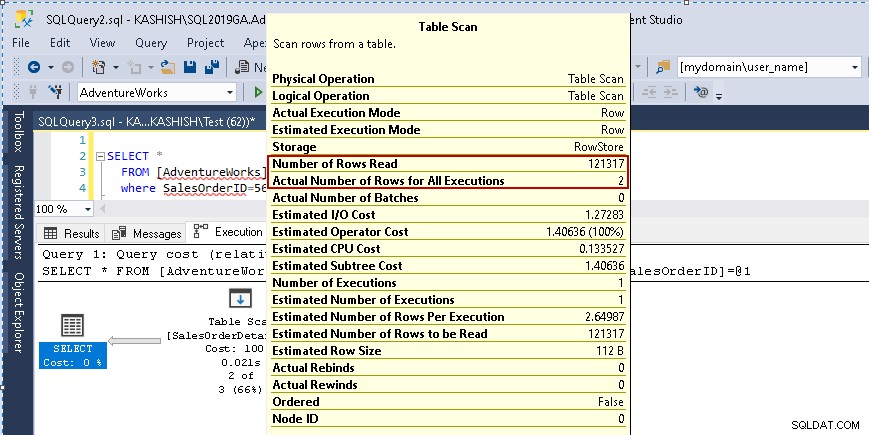
Po najechaniu kursorem na ikonę skanowania tabeli pokazuje, że rzeczywisty zestaw wyników zawiera 2 wiersze, ale w tym celu odczytuje wszystkie wiersze w tej tabeli.
- Liczba odczytanych wierszy:121317
- Rzeczywista liczba wierszy do wykonania:2
A teraz pomyśl o tabeli z milionami lub miliardami wierszy. Przechodzenie przez wszystkie rekordy w tabeli w celu filtrowania kilku wierszy nie jest dobrą praktyką. W rozbudowanym systemie baz danych przetwarzania transakcji online (OLTP) nie wykorzystuje efektywnie zasobów serwera (procesora, IO, pamięci), dlatego użytkownik może napotkać problemy z wydajnością.
Teraz uruchommy powyższą instrukcję select z tabelą zawierającą indeksy. Ta tabela zawiera indeks klastrowy klucza podstawowego i dwa indeksy nieklastrowane w kolumnach [ProductID] i [rowguid]. Porozmawiamy później o różnych typach indeksów w SQL Server.
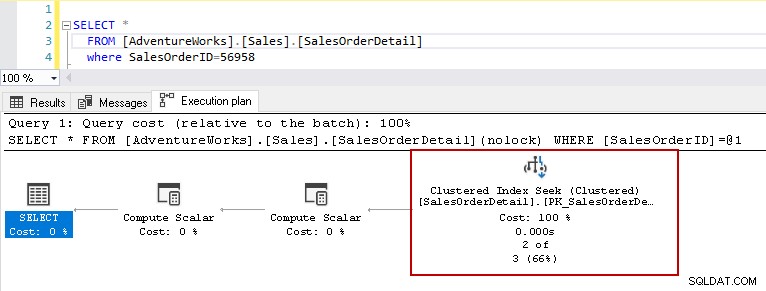
Teraz, jeśli ponownie uruchomisz instrukcję select z tym samym predykatem, plan wykonania pokaże problem z wydajnością. Optymalizator zapytań decyduje się użyć wyszukiwania indeksu klastrowego zamiast skanowania indeksu klastrowego.
W szczegółach wyszukiwania indeksu klastrowego pokazuje, że optymalizator zapytań dokładnie odczytuje wiersze, które podał w wyniku.
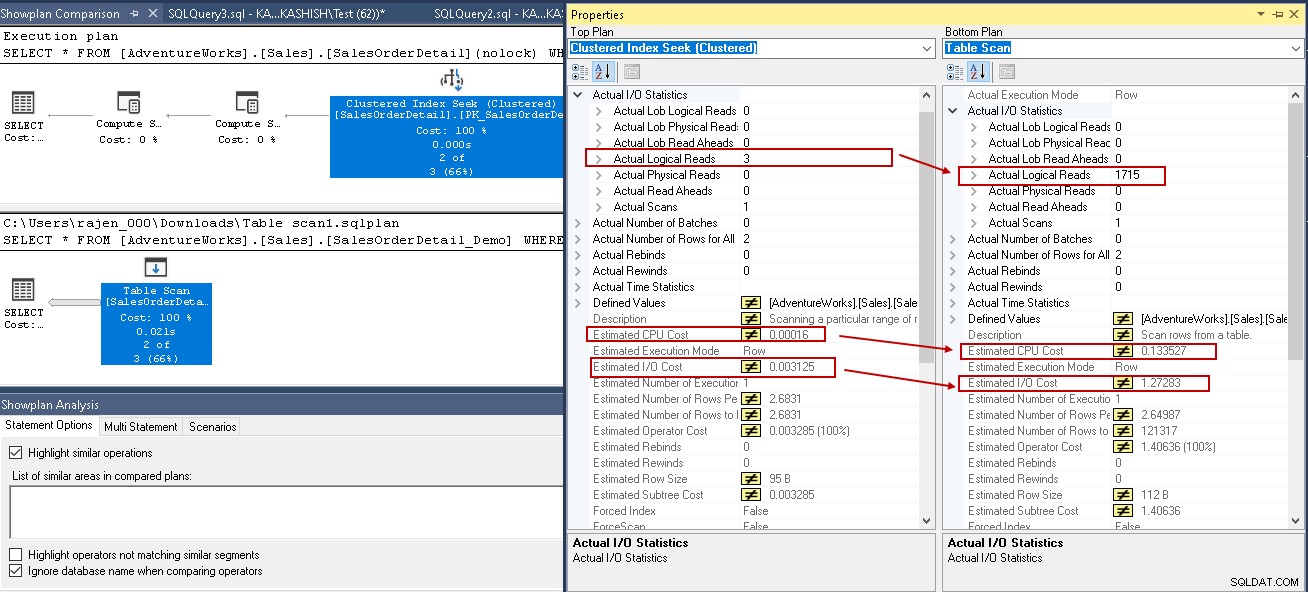
Aby zapewnić Ci analizę porównawczą, porównajmy plan wykonania z indeksem SQL Server i bez niego. Więcej informacji znajdziesz w artykule SQL Shack Jak porównywać plany wykonywania zapytań w SQL Server 2016.
W tym przykładzie spójrz na podświetlone wartości w wyszukiwaniu indeksu klastrowego i skanowaniu tabeli:
- Odczyty logiczne:silnik bazy danych SQL Server odczytuje stronę z bufora pamięci podręcznej i powoduje odczyt logiczny. Poniżej widzimy, że odczyty logiczne są zmniejszane z 1715 do 3 po utworzeniu indeksu.
- Szacowany koszt procesora również spada z 0,133527 do 0,00016
- Szacowany koszt IO spada z 1,27283 do 0,003125
Poniższy obraz pokazuje różnicę między skanowaniem tabeli a wyszukiwaniem indeksu.
Dobre (przydatne) indeksy i złe indeksy w SQL Server
Jak sama nazwa wskazuje, dobry indeks poprawia wydajność zapytań i minimalizuje wykorzystanie zasobów. Czy indeks może zmniejszyć wydajność zapytań w SQL Server? Czasami tworzymy indeks na określonej kolumnie, ale nigdy nie jest on używany. Załóżmy, że masz indeks w kolumnie i wykonujesz wiele operacji wstawiania i aktualizacji dla tej kolumny. Dla każdej aktualizacji wymagana jest również odpowiednia aktualizacja indeksu. Jeśli Twoje obciążenie ma większą aktywność zapisu i masz wiele indeksów w kolumnie, spowolniłoby to ogólną wydajność zapytań. Nieużywany indeks może również spowolnić działanie instrukcji select. Optymalizator zapytań wykorzystuje statystyki do tworzenia planu wykonania. Odczytuje wszystkie indeksy oraz próbkowanie ich danych i na tej podstawie buduje zoptymalizowany plan wykonania zapytań. Możesz śledzić wykorzystanie indeksu za pomocą dynamicznego widoku zarządzania sys.dm_db_index_usage_stats i monitorować zasoby, takie jak skanowanie użytkowników, wyszukiwanie użytkowników i wyszukiwania użytkowników.
Typy indeksów SQL Server i uwagi
SQL Server ma dwa główne indeksy — klastrowane i nieklastrowane. Indeks klastrowy przechowuje rzeczywiste dane w węźle liścia indeksu. Fizycznie sortuje dane na stronach danych na podstawie klucza indeksu klastrowego. SQL Server zezwala na jeden indeks klastrowy na tabelę. Możesz połączyć wiele kolumn, aby zbudować klastrowy klucz indeksu. Indeks nieklastrowy jest indeksem logicznym i zawiera kolumnę klucza indeksu, która wskazuje na klucz indeksu klastrowego.
Możemy mieć inne indeksy w SQL Server, takie jak indeks XML, indeks magazynu kolumn, indeks przestrzenny, indeks pełnotekstowy, indeks skrótu itp.
Przed zbudowaniem indeksu w SQL Server należy wziąć pod uwagę następujące punkty:
- Obciążenie pracą
- Kolumna, w której wymagany jest indeks
- Rozmiar stołu
- Rosnąca lub malejąca kolejność danych w kolumnie
- Kolejność kolumn
- Typ indeksu
- Współczynnik wypełnienia, indeks wypełnienia i kolejność sortowania TempDB
Korzyści, implikacje i zalecenia dotyczące indeksu SQL Server
Indeksy w bazie danych mogą być mieczem obosiecznym. Przydatny indeks SQL Server zwiększa wydajność zapytań i systemu bez wpływu na inne zapytania. Z drugiej strony, jeśli utworzysz indeks bez żadnego przygotowania lub rozważenia, może to spowodować spadek wydajności, powolne pobieranie danych i może zużywać bardziej krytyczne zasoby, takie jak procesor, we/wy i pamięć. Indeksy zwiększają również liczbę zadań związanych z konserwacją bazy danych. Mając na uwadze te czynniki, zawsze najlepiej jest przetestować odpowiedni indeks w środowisku przedprodukcyjnym przy obciążeniu równoważnym z produkcją, a następnie przeanalizować wydajność i zdecydować, czy najlepiej wdrożyć go w produkcyjnej bazie danych. Istnieje wiele innych zaleceń, które należy wziąć pod uwagę, sprawdź moje 11 najlepszych praktyk dotyczących indeksu, aby uzyskać więcej informacji.