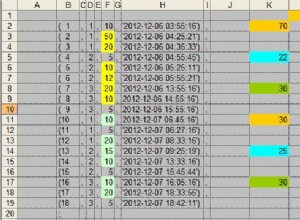
Może czegoś brakuje, ale powinieneś być w stanie przestawić dane, ale będziesz musiał zaimplementować row_number() aby pomóc w generowaniu kolumn.
Kluczem będzie użycie zapytania podobnego do:
SELECT ONE.UserID,
ONE.Episode,
ONE.Value,
TWO.Details,
'Details'
+cast(row_number() over(partition by one.userid, one.episode
order by two.details) as varchar(10)) seq
FROM TABLE1 ONE
INNER JOIN TABLE2 Two
ON ONE.UserID = TWO.UserID
AND ONE.Episode = TWO.Episode
Spowoduje to utworzenie unikalnej sekwencji dla nowych nazw kolumn, a następnie możesz zastosować PIVOT:
select userid, episode,
value,
details1,
details2
from
(
SELECT ONE.UserID,
ONE.Episode,
ONE.Value,
TWO.Details,
'Details'
+cast(row_number() over(partition by one.userid, one.episode
order by two.details) as varchar(10)) seq
FROM TABLE1 ONE
INNER JOIN TABLE2 Two
ON ONE.UserID = TWO.UserID
AND ONE.Episode = TWO.Episode
) d
pivot
(
max(details)
for seq in (Details1, Details2)
) piv;
Zobacz Skrzypce SQL z wersją demonstracyjną . Następnie możesz przekonwertować to na dynamiczny SQL:
DECLARE @cols AS NVARCHAR(MAX),
@query AS NVARCHAR(MAX)
select @cols = STUFF((SELECT ',' + QUOTENAME('Details'+cast(seq as varchar(10)))
from
(
select
row_number() over(partition by one.userid, one.episode
order by two.details) seq
FROM TABLE1 ONE
INNER JOIN TABLE2 Two
ON ONE.UserID = TWO.UserID
AND ONE.Episode = TWO.Episode
) d
group by seq
order by seq
FOR XML PATH(''), TYPE
).value('.', 'NVARCHAR(MAX)')
,1,1,'')
set @query = 'SELECT userid, episode, value, ' + @cols + '
from
(
SELECT ONE.UserID,
ONE.Episode,
ONE.Value,
TWO.Details,
''Details''
+cast(row_number() over(partition by one.userid, one.episode
order by two.details) as varchar(10)) seq
FROM TABLE1 ONE
INNER JOIN TABLE2 Two
ON ONE.UserID = TWO.UserID
AND ONE.Episode = TWO.Episode
) x
pivot
(
max(details)
for seq in (' + @cols + ')
) p '
execute sp_executesql @query;
Zobacz Skrzypce SQL z wersją demonstracyjną . Daje Ci wynik:
| USERID | EPISODE | VALUE | DETAILS1 | DETAILS2 |
|--------|---------|-----------|-----------|-----------|
| 1 | 1 | VALUE 1-1 | Details 1 | Details 2 |
| 1 | 2 | VALUE 1-2 | Details 1 | Details 2 |