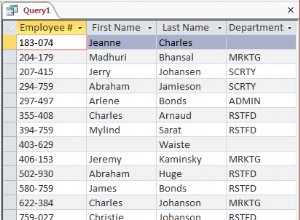
Zakładając, że masz pola w tym formacie:
00Data0007
000000Data0011
0000Data0015
, możesz wykonać następujące czynności:
-
Utwórz kolumnę wyliczaną:
ndata AS RIGHT(REVERSE(data), LEN(data) - 4)Spowoduje to przekształcenie Twoich kolumn w następujące:
ataD00 ataD000000 ataD0000 -
Utwórz indeks w tej kolumnie
-
Wydaj to zapytanie, aby wyszukać ciąg
Data:SELECT * FROM mytable WHERE ndata LIKE N'ataD%' AND SUBSTRING(ndata, LEN(N'ataD') + 1, LEN(ndata)) = REPLICATE('0', LEN(ndata) - LEN('ataD'))Pierwszy warunek użyje indeksu do filtrowania zgrubnego.
Drugi upewni się, że wszystkie wiodące znaki (które stały się końcowymi znakami w wyliczonej kolumnie) są tylko zerami.
Zobacz ten wpis na moim blogu, aby uzyskać szczegółowe informacje na temat wydajności:
Aktualizacja
Jeśli potrzebujesz tylko indeksu SUBSTRING bez zmiany schematu, tworzenie widoku jest opcją.
CREATE VIEW v_substring75
WITH SCHEMABINDING
AS
SELECT s.id, s.data, SUBSTRING(data, 7, 5) AS substring75
FROM mytable
CREATE UNIQUE CLUSTERED INDEX UX_substring75_substring_id ON (substring75, id)
SELECT id, data
FROM v_substring75
WHERE substring75 = '12345'