Całkowicie zgadzam się z @PaulStock, że agregaty najlepiej pozostawić systemom źródłowym. Agregat w SSIS jest w pełni blokującym komponentem, podobnie jak sort i mam już przedstawiłem swoją argumentację w tej kwestii .
Ale są chwile, kiedy wykonywanie tych operacji w systemie źródłowym po prostu nie zadziała. Najlepsze, co udało mi się wymyślić, to w zasadzie podwójne przetwarzanie danych. Tak, ick, ale nigdy nie udało mi się znaleźć sposobu, aby przejść przez kolumnę bez zmian. W przypadku scenariuszy Min/Max chciałbym to zrobić jako opcję, ale oczywiście coś takiego jak Suma utrudniłoby komponentowi zorientowanie się, z którym wierszem „źródłowym” jest powiązany.
2005
Wdrożenie z 2005 roku wyglądałoby tak. Twoja wydajność nie będzie dobra, w rzeczywistości kilka rzędów wielkości od dobrej, ponieważ będziesz mieć wszystkie te transformacje blokujące, oprócz konieczności ponownego przetworzenia danych źródłowych.
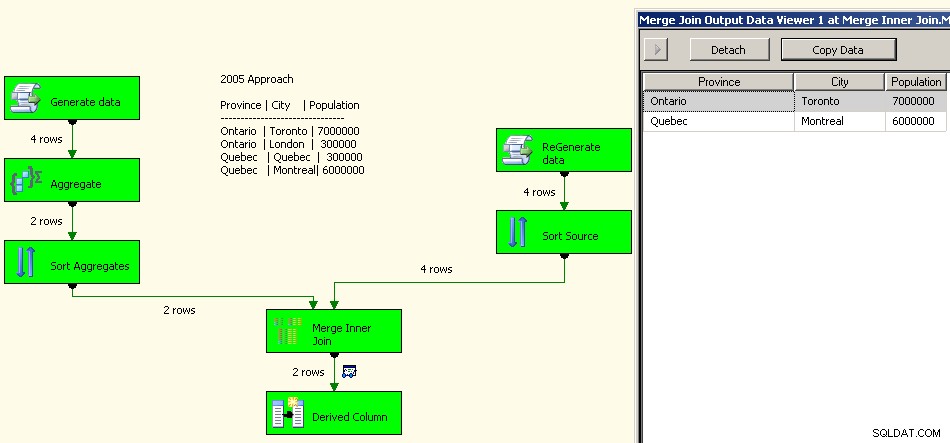
Scal dołączenie 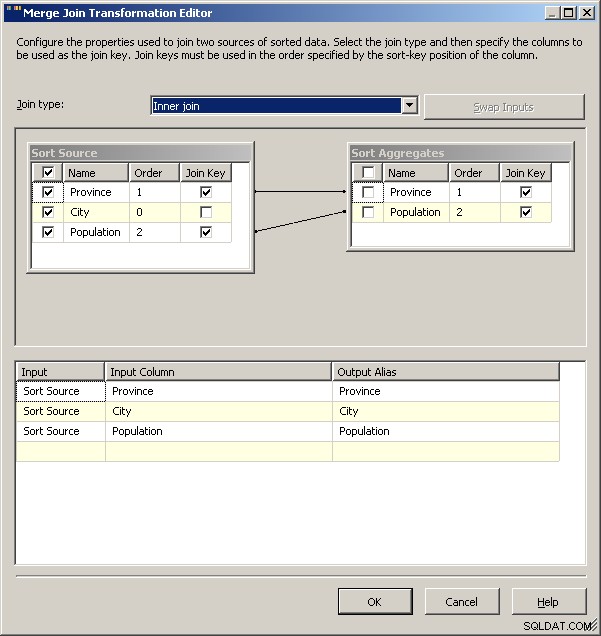
2008
W 2008 r. masz możliwość korzystania z Menedżera połączeń pamięci podręcznej co pomogłoby wyeliminować przekształcenia blokujące, przynajmniej tam, gdzie ma to znaczenie, ale nadal będziesz musiał ponieść koszty podwójnego przetwarzania danych źródłowych.
Przeciągnij dwa przepływy danych na kanwę. Pierwszy zapełni menedżera połączeń pamięci podręcznej i powinien znajdować się w miejscu, w którym odbywa się agregacja.
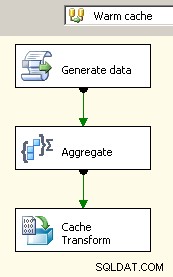
Teraz, gdy pamięć podręczna zawiera zagregowane dane, upuść zadanie wyszukiwania w głównym przepływie danych i przeprowadź wyszukiwanie w pamięci podręcznej.
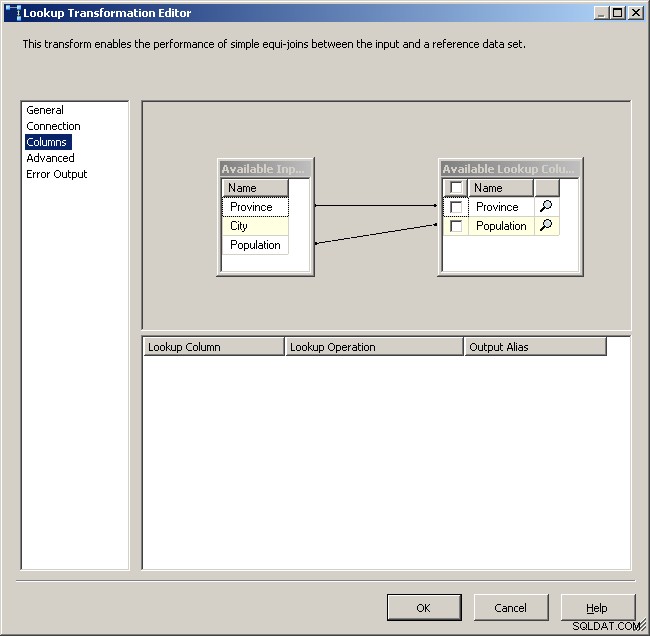
Ogólna karta wyszukiwania
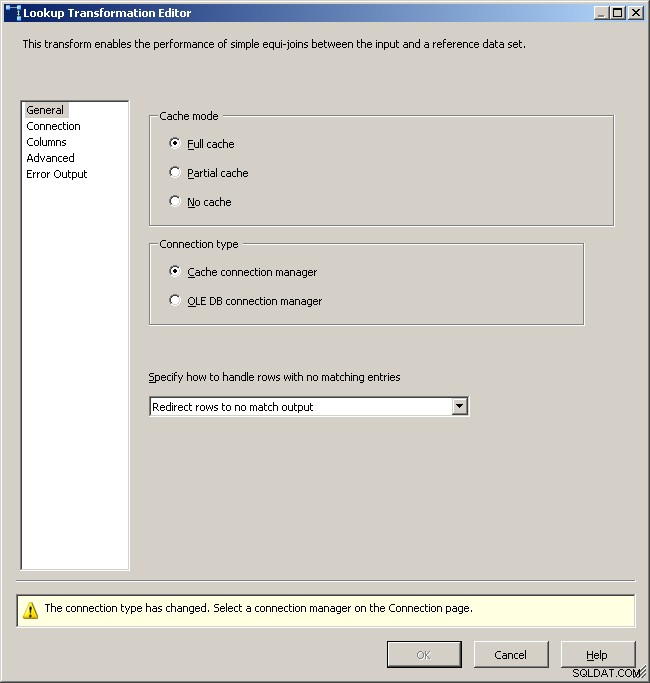
Wybierz menedżera połączeń pamięci podręcznej
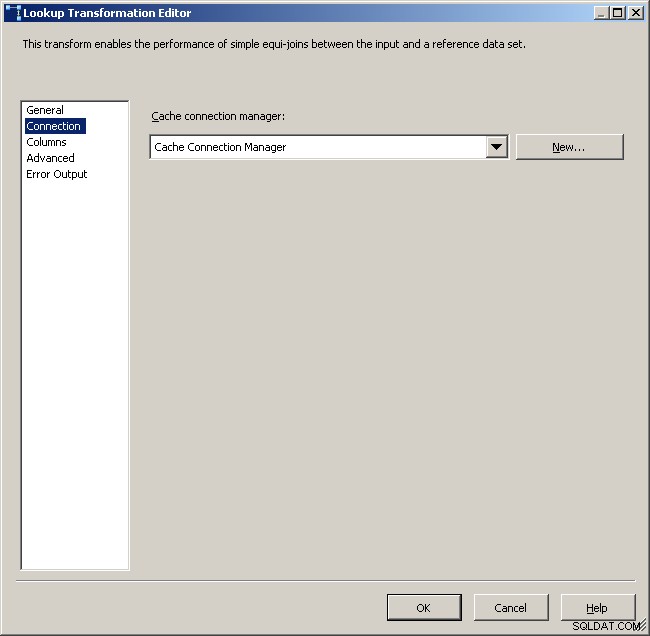
Mapuj odpowiednie kolumny
Wielki sukces 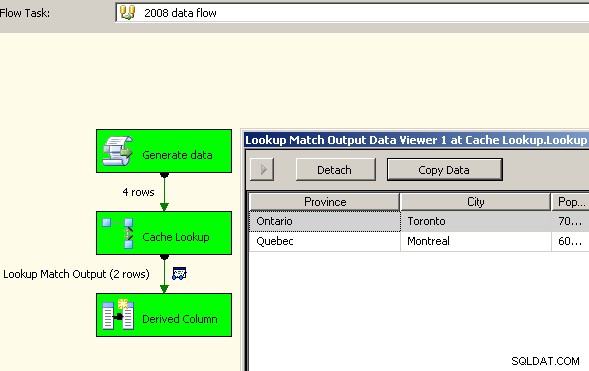
Zadanie skryptu
Trzecie podejście, jakie przychodzi mi do głowy, 2005 lub 2008, to napisanie tego samemu. Z reguły staram się unikać zadań skryptowych, ale jest to przypadek, w którym prawdopodobnie ma to sens. Musisz ustawić go jako asynchroniczna transformacja skryptu ale po prostu obsługuj tam swoje agregacje. Więcej kodu do utrzymania, ale możesz zaoszczędzić sobie kłopotów z ponownym przetwarzaniem danych źródłowych.
Na koniec, jako ogólne zastrzeżenie, zbadam, jaki wpływ na twoje rozwiązanie wpłynie powiązanie. W przypadku tego zestawu danych spodziewałbym się, że coś takiego jak Guelph nagle puchnie i wiąże Toronto, ale jeśli tak, to co powinien zrobić pakiet? W tej chwili obie dadzą 2 rzędy dla Ontario, ale czy to jest zamierzone zachowanie? Skrypt oczywiście pozwala określić, co dzieje się w przypadku remisów. Prawdopodobnie mógłbyś postawić rozwiązanie 2008 na głowie, buforując „normalne” dane i używając ich jako warunku wyszukiwania i używając agregatów do wycofania tylko jednego z powiązań. 2005 prawdopodobnie może zrobić to samo, umieszczając agregację jako lewe źródło połączenia scalającego
Edycje
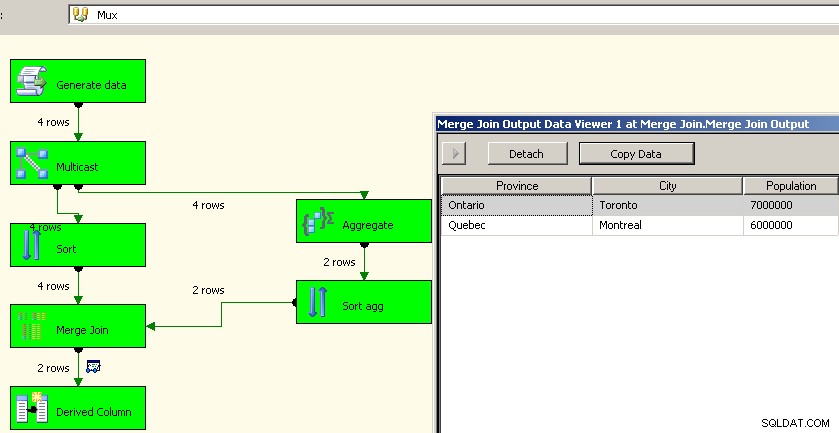
Jason Horner w swoim komentarzu miał dobry pomysł. Innym podejściem byłoby użycie transformacji multiemisji i wykonanie agregacji w jednym strumieniu i ponowne połączenie. Nie mogłem wymyślić, jak sprawić, by wszystko działało z unią, ale moglibyśmy użyć sortowania i łączenia łączenia, podobnie jak powyżej. Jest to prawdopodobnie lepsze podejście, ponieważ oszczędza nam kłopotów z ponownym przetwarzaniem danych źródłowych.