Wykazanie możliwego wyjaśnienia.
Utwórz skrypt tabeli
SELECT *
INTO #T
FROM master.dbo.spt_values
CREATE NONCLUSTERED INDEX [IX_T] ON #T ([name] DESC,[number] DESC);
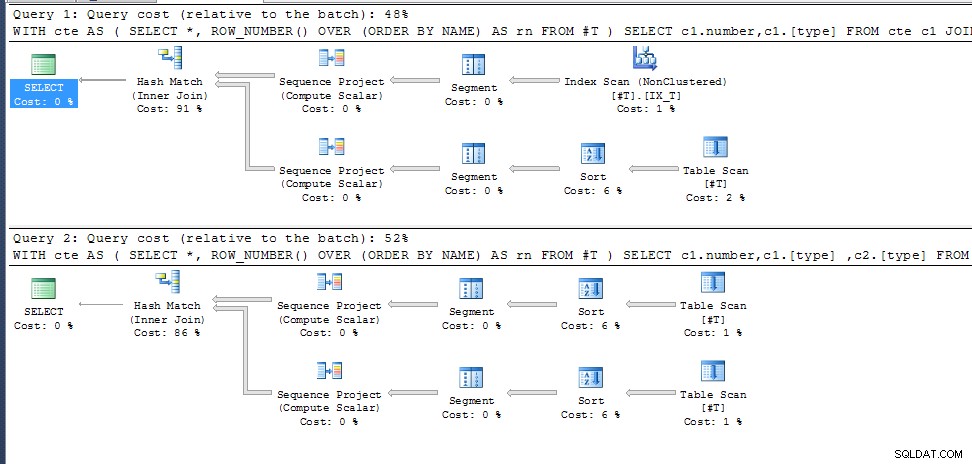
Zapytanie pierwsze (zwraca 35 wyników)
WITH cte AS
(
SELECT *, ROW_NUMBER() OVER (ORDER BY NAME) AS rn
FROM #T
)
SELECT c1.number,c1.[type]
FROM cte c1
JOIN cte c2 ON c1.rn=c2.rn AND c1.number <> c2.number
Zapytanie drugie (tak samo jak poprzednio, ale dodanie c2.[typ] do listy wyboru powoduje zwrócenie 0 wyników);
WITH cte AS
(
SELECT *, ROW_NUMBER() OVER (ORDER BY NAME) AS rn
FROM #T
)
SELECT c1.number,c1.[type] ,c2.[type]
FROM cte c1
JOIN cte c2 ON c1.rn=c2.rn AND c1.number <> c2.number
Dlaczego?
row_number() dla zduplikowanych nazw nie jest określony, więc po prostu wybiera ten, który pasuje do najlepszego planu wykonania dla wymaganych kolumn wyjściowych. W drugim zapytaniu jest tak samo dla obu wywołań cte, w pierwszym wybiera inną ścieżkę dostępu z wynikającą z tego inną numeracją wierszy.
Sugerowane rozwiązanie
Sam dołączasz do CTE w dniu ROW_NUMBER() over (order by t.[Date])
Wbrew oczekiwaniom CTE prawdopodobnie nie urzeczywistniać się
co zapewniłoby spójność dla self join, a zatem zakładasz korelację między ROW_NUMBER() po obu stronach, które mogą nie istnieć dla rekordów, w których duplikat [Date] istnieje w danych.
Co się stanie, jeśli spróbujesz użyć ROW_NUMBER() over (order by t.[Date], t.[id]) aby upewnić się, że w przypadku wiązanych dat numeracja wierszy jest w gwarantowanej spójnej kolejności. (Lub jakaś inna kolumna/kombinacja kolumn, która może rozróżniać rekordy, jeśli tego nie zrobię)