Obie funkcje OVER i PARTITION BY służą do podziału zestawu wyników zgodnie z określonymi kryteriami.
W tym artykule wyjaśniono, w jaki sposób te dwie funkcje mogą być używane w połączeniu do pobierania danych podzielonych na partycje w bardzo specyficzny sposób.
Przygotowywanie niektórych przykładowych danych
Aby wykonać nasze przykładowe zapytania, najpierw utwórzmy bazę danych o nazwie „studentdb”.
Uruchom następujące polecenie w oknie zapytania:
CREATE DATABASE schooldb;
Następnie musimy utworzyć tabelę „student” w bazie danych „studentdb”. Tabela uczniów będzie miała pięć kolumn:id, imię i nazwisko, wiek, płeć i całkowity_wynik.
Jak zawsze, upewnij się, że masz odpowiednią kopię zapasową, zanim zaczniesz eksperymentować z nowym kodem. Zobacz ten artykuł na temat tworzenia kopii zapasowych baz danych SQL Server, jeśli nie masz pewności.
Wykonaj następujące zapytanie, aby utworzyć tabelę uczniów.
USE schooldb
CREATE TABLE student
(
id INT PRIMARY KEY IDENTITY,
name VARCHAR(50) NOT NULL,
gender VARCHAR(50) NOT NULL,
age INT NOT NULL,
total_score INT NOT NULL,
) Na koniec musimy wstawić do bazy danych pewne fikcyjne dane, z którymi będziemy pracować.
USE schooldb
INSERT INTO student
VALUES ('Jolly', 'Female', 20, 500),
('Jon', 'Male', 22, 545),
('Sara', 'Female', 25, 600),
('Laura', 'Female', 18, 400),
('Alan', 'Male', 20, 500),
('Kate', 'Female', 22, 500),
('Joseph', 'Male', 18, 643),
('Mice', 'Male', 23, 543),
('Wise', 'Male', 21, 499),
('Elis', 'Female', 27, 400); Teraz jesteśmy gotowi do pracy nad problemem i zobaczenia, kogo możemy użyć do jego rozwiązania za pomocą funkcji Over i Partition By.
Problem
Mamy 10 rekordów w tabeli uczniów i chcemy wyświetlić imię i nazwisko, identyfikator i płeć dla wszystkich uczniów, a dodatkowo chcemy również wyświetlić całkowitą liczbę uczniów należących do każdej płci, średni wiek uczniów uczniowie każdej płci i suma wartości w kolumnie total_score dla każdej płci.
Zestaw wyników, którego szukamy, jest następujący:
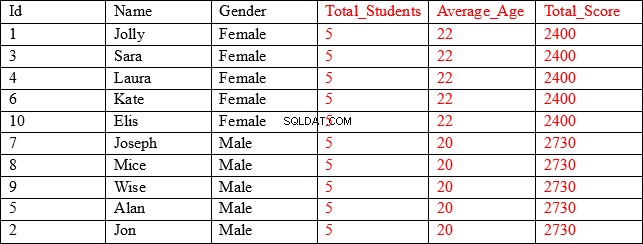
Jak widać, pierwsze trzy kolumny (pokazane na czarno) zawierają indywidualne wartości dla każdego rekordu, podczas gdy ostatnie trzy kolumny (pokazane na czerwono) zawierają zagregowane wartości pogrupowane według kolumny płci. Na przykład w kolumnie Average_Age w pierwszych pięciu wierszach wyświetlany jest średni wiek i łączny wynik wszystkich rekordów, w których płeć to Kobieta.
Nasz zestaw wyników zawiera zagregowane wyniki połączone z niezagregowanymi kolumnami.
Aby pobrać zagregowane wyniki, pogrupowane według określonej kolumny, możemy jak zwykle użyć klauzuli GROUP BY.
USE schooldb SELECT gender, count(gender) AS Total_Students, AVG(age) as Average_Age, SUM(total_score) as Total_Score FROM student GROUP BY gender
Zobaczmy, jak możemy pobrać Total_Students, Average_Age i Total_Score uczniów pogrupowanych według płci.
Zobaczysz następujące wyniki:

Teraz rozszerzmy to i dodajmy „id” i „name” (niezagregowane kolumny w instrukcji SELECT) i zobaczmy, czy możemy uzyskać pożądany wynik.
USE schooldb SELECT id, name, gender, count(gender) AS total_students, AVG(age) as Average_Age, SUM(total_score) as Total_Score FROM student GROUP BY gender
Po uruchomieniu powyższego zapytania zobaczysz błąd:

Błąd mówi, że kolumna id tabeli uczniów jest nieprawidłowa w instrukcji SELECT, ponieważ używamy klauzuli GROUP BY w zapytaniu.
Oznacza to, że będziemy musieli zastosować funkcję agregującą w kolumnie id lub będziemy musieli użyć jej w klauzuli GROUP BY. Krótko mówiąc, ten schemat nie rozwiązuje naszego problemu.
Rozwiązanie wykorzystujące instrukcję JOIN
Jednym z rozwiązań tego problemu byłoby użycie instrukcji JOIN, aby połączyć kolumny z zagregowanymi wynikami z kolumnami zawierającymi niezagregowane wyniki.
Aby to zrobić, potrzebujesz podzapytania, które pobiera płeć, Total_Students, Average_Age i Total_Score uczniów pogrupowanych według płci. Wyniki te można następnie połączyć z wynikami uzyskanymi z podzapytania za pomocą zewnętrznej instrukcji SELECT. Zostanie to zastosowane do kolumny płci w podzapytaniu zawierającym zagregowany wynik oraz do kolumny płci w tabeli uczniów. Zewnętrzna instrukcja SELECT zawierałaby kolumny niezagregowane, tj. „id” i „nazwa”, jak poniżej.
USE schooldb SELECT id, name, Aggregation.gender, Aggregation.Total_students, Aggregation.Average_Age, Aggregation.Total_Score FROM student INNER JOIN (SELECT gender, count(gender) AS Total_students, AVG(age) AS Average_Age, SUM(total_score) AS Total_Score FROM student GROUP BY gender) AS Aggregation on Aggregation.gender = student.gender
Powyższe zapytanie da pożądany rezultat, ale nie jest optymalnym rozwiązaniem. Musieliśmy użyć instrukcji JOIN i podzapytania, co zwiększa złożoność skryptu. To nie jest eleganckie ani wydajne rozwiązanie.
Lepszym podejściem jest użycie klauzul OVER i PARTITION BY w połączeniu.
Rozwiązanie wykorzystujące OVER i PARTITION BY
Aby użyć klauzul OVER i PARTITION BY, wystarczy określić kolumnę, według której chcesz podzielić zagregowane wyniki. Najlepiej to wyjaśnić na przykładzie.
Przyjrzyjmy się, jak osiągnąć nasz wynik za pomocą funkcji OVER i PARTITION BY.
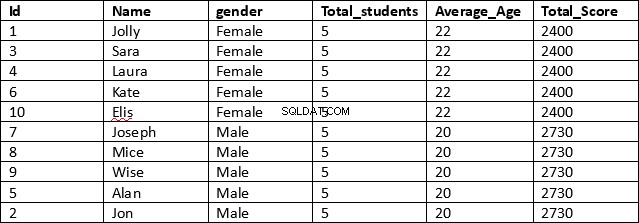
USE schooldb SELECT id, name, gender, COUNT(gender) OVER (PARTITION BY gender) AS Total_students, AVG(age) OVER (PARTITION BY gender) AS Average_Age, SUM(total_score) OVER (PARTITION BY gender) AS Total_Score FROM student
To znacznie bardziej wydajny wynik. W pierwszym wierszu skryptu pobierane są kolumny id, name i gender. Te kolumny nie zawierają żadnych zagregowanych wyników.
Następnie dla kolumn, które zawierają zagregowane wyniki, po prostu określamy zagregowaną funkcję, po której następuje klauzula OVER, a następnie w nawiasie podajemy klauzulę PARTITION BY, po której następuje nazwa kolumny, w której chcemy podzielić nasze wyniki, jak pokazano poniżej.
Referencje
- Microsoft — zrozumienie klauzuli OVER
- Midnight DBA – wprowadzenie do OVER i PARTITION BY
- StackOverflow – różnica między PARTITION BY i GROUP BY