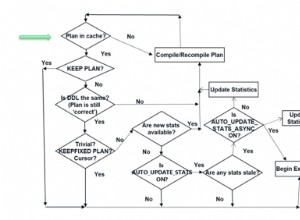
SELECT TOP 1000
*
FROM (
SELECT patientId, labId, result,
DENSE_RANK() OVER (PARTITION BY patientId, labId ORDER BY labDate DESC) dr
FROM labs
) q
PIVOT (
MIN(result)
FOR
labId IN ([1],[2],[3],[4],[5],[7],[8],[9],[10],[11],[12],[13],[14],[15],[16],[17])
) p
WHERE dr = 1
ORDER BY
patientId
Możesz również spróbować utworzyć widok indeksowany w ten sposób:
CREATE VIEW
v_labs_patient_lab
WITH SCHEMABINDING
AS
SELECT patientId, labId, COUNT_BIG(*) AS cnt
FROM dbo.labs
GROUP BY
patientId, labId
CREATE UNIQUE CLUSTERED INDEX
ux_labs_patient_lab
ON v_labs_patient_lab (patientId, labId)
i użyj go w zapytaniu:
SELECT TOP 1000
*
FROM (
SELECT lr.patientId, lr.labId, lr.result
FROM v_labs_patient_lab vl
CROSS APPLY
(
SELECT TOP 1 WITH TIES
result
FROM labs l
WHERE l.patientId = vl.patientId
AND l.labId = vl.labId
ORDER BY
l.labDate DESC
) lr
) q
PIVOT (
MIN(result)
FOR
labId IN ([1],[2],[3],[4],[5],[7],[8],[9],[10],[11],[12],[13],[14],[15],[16],[17])
) p
ORDER BY
patientId