Jednym z bardziej kłopotliwych problemów do rozwiązania w programie SQL Server mogą być problemy związane z przyznawaniem pamięci. Niektóre zapytania wymagają do wykonania więcej pamięci niż inne, w zależności od tego, jakie operacje należy wykonać (np. sortowanie, mieszanie). Optymalizator SQL Server szacuje, ile pamięci jest potrzebne, a zapytanie musi uzyskać przyznanie pamięci, aby rozpocząć wykonywanie. Przechowuje to przydział na czas wykonywania zapytania — co oznacza, że jeśli optymalizator przeszacowuje pamięć, możesz napotkać problemy ze współbieżnością. Jeśli nie docenia pamięci, możesz zobaczyć wycieki w tempdb. Żadna z tych opcji nie jest idealna, a gdy po prostu masz zbyt wiele zapytań proszących o więcej pamięci, niż jest dostępne do przyznania, zobaczysz, że czeka RESOURCE_SEMAPHORE. Istnieje wiele sposobów na zaatakowanie tego problemu, a jedną z moich nowych ulubionych metod jest użycie Query Store.
Konfiguracja
Wykorzystamy kopię WideWorldImporters, którą wypełniłem za pomocą procedury składowanej DataLoadSimulation.DailyProcessToCreateHistory. Tabela Sales.Orders ma około 4,6 miliona wierszy, a tabela Sales.OrderLines ma około 9,2 miliona wierszy. Przywrócimy kopię zapasową i włączymy Query Store, a także usuniemy wszelkie stare dane Query Store, aby nie zmieniać żadnych danych w tej wersji demonstracyjnej.
Przypomnienie:Nie uruchamiaj ALTER DATABASE
USE [master]; GO RESTORE DATABASE [WideWorldImporters] FROM DISK = N'C:\Backups\WideWorldImporters.bak' WITH FILE = 1, MOVE N'WWI_Primary' TO N'C:\Databases\WideWorldImporters\WideWorldImporters.mdf', MOVE N'WWI_UserData' TO N'C:\Databases\WideWorldImporters\WideWorldImporters_UserData.ndf', MOVE N'WWI_Log' TO N'C:\Databases\WideWorldImporters\WideWorldImporters.ldf', NOUNLOAD, REPLACE, STATS = 5 GO ALTER DATABASE [WideWorldImporters] SET QUERY_STORE = ON; GO ALTER DATABASE [WideWorldImporters] SET QUERY_STORE ( OPERATION_MODE = READ_WRITE, INTERVAL_LENGTH_MINUTES = 10 ); GO ALTER DATABASE [WideWorldImporters] SET QUERY_STORE CLEAR; GO
Procedura składowana, której użyjemy do testowania zapytań do wyżej wymienionych tabel Orders i OrderLines na podstawie zakresu dat:
USE [WideWorldImporters]; GO DROP PROCEDURE IF EXISTS [Sales].[usp_OrderInfo_OrderDate]; GO CREATE PROCEDURE [Sales].[usp_OrderInfo_OrderDate] @StartDate DATETIME, @EndDate DATETIME AS SELECT [o].[CustomerID], [o].[OrderDate], [o].[ContactPersonID], [ol].[Quantity] FROM [Sales].[Orders] [o] JOIN [Sales].[OrderLines] [ol] ON [o].[OrderID] = [ol].[OrderID] WHERE [OrderDate] BETWEEN @StartDate AND @EndDate ORDER BY [OrderDate]; GO
Testowanie
Wykonamy procedurę składowaną z trzema różnymi zestawami parametrów wejściowych:
EXEC [Sales].[usp_OrderInfo_OrderDate] '2016-01-01', '2016-01-08'; GO EXEC [Sales].[usp_OrderInfo_OrderDate] '2016-01-01', '2016-06-30'; GO EXEC [Sales].[usp_OrderInfo_OrderDate] '2016-01-01', '2016-12-31'; GO
Pierwsze wykonanie zwraca 1958 wierszy, drugie 267 268 wierszy, a ostatnie ponad 2,2 miliona wierszy. Jeśli spojrzysz na zakresy dat, nie jest to zaskakujące – im większy zakres dat, tym więcej danych jest zwracanych.
Ponieważ jest to procedura składowana, parametry wejściowe użyte początkowo określają plan, a także ilość pamięci, która ma zostać przyznana. Jeśli spojrzymy na rzeczywisty plan wykonania pierwszego wykonania, zobaczymy zagnieżdżone pętle i przyznanie pamięci 2656 KB.
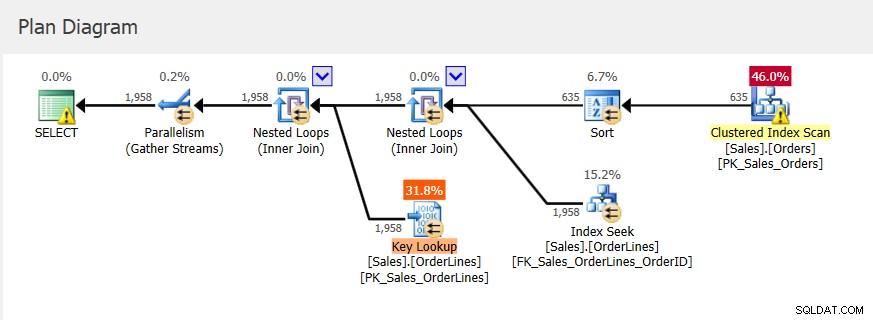
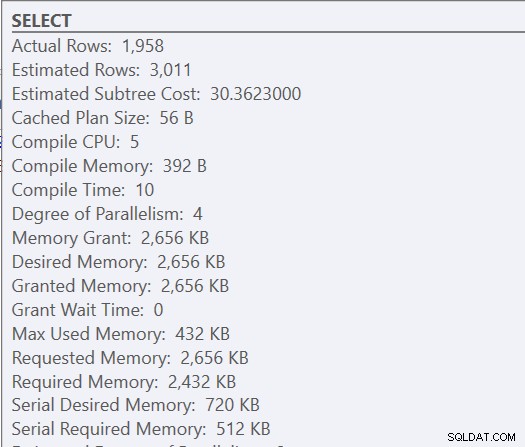
Kolejne egzekucje mają ten sam plan (bo to właśnie zostało zapisane w pamięci podręcznej) i taką samą przydział pamięci, ale mamy wskazówkę, że to nie wystarczy, ponieważ jest ostrzeżenie o sortowaniu.
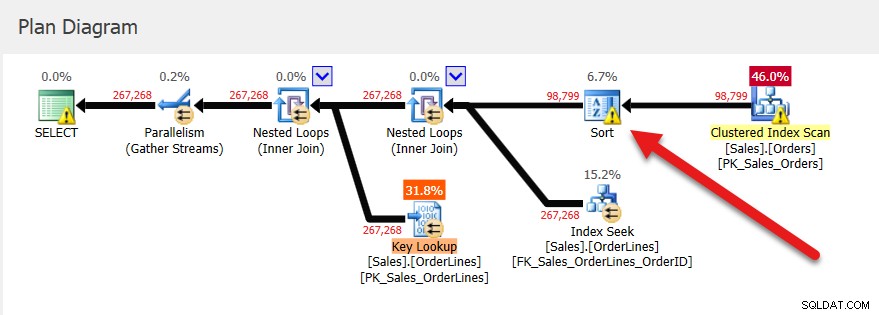
Jeśli wyszukamy tę procedurę składowaną w magazynie zapytań, zobaczymy trzy wykonania i te same wartości dla pamięci UsedKB, niezależnie od tego, czy patrzymy na średnią, minimalną, maksymalną, ostatnią czy odchylenie standardowe. Uwaga:informacje o przydzieleniu pamięci w Query Store są raportowane jako liczba stron 8 KB.
SELECT [qst].[query_sql_text], [qsq].[query_id], [qsp].[plan_id], [qsq].[object_id], [rs].[count_executions], [rs].[last_execution_time], [rs].[avg_duration], [rs].[avg_logical_io_reads], [rs].[avg_query_max_used_memory] * 8 AS [AvgUsedKB], [rs].[min_query_max_used_memory] * 8 AS [MinUsedKB], --memory grant (reported as the number of 8 KB pages) for the query plan within the aggregation interval [rs].[max_query_max_used_memory] * 8 AS [MaxUsedKB], [rs].[last_query_max_used_memory] * 8 AS [LastUsedKB], [rs].[stdev_query_max_used_memory] * 8 AS [StDevUsedKB], TRY_CONVERT(XML, [qsp].[query_plan]) AS [QueryPlan_XML] FROM [sys].[query_store_query] [qsq] JOIN [sys].[query_store_query_text] [qst] ON [qsq].[query_text_id] = [qst].[query_text_id] JOIN [sys].[query_store_plan] [qsp] ON [qsq].[query_id] = [qsp].[query_id] JOIN [sys].[query_store_runtime_stats] [rs] ON [qsp].[plan_id] = [rs].[plan_id] WHERE [qsq].[object_id] = OBJECT_ID(N'Sales.usp_OrderInfo_OrderDate');

Jeśli szukamy problemów z przyznawaniem pamięci w tym scenariuszu — gdy plan jest buforowany i ponownie używany — Query Store nie pomoże nam.
Ale co, jeśli konkretne zapytanie zostanie skompilowane podczas wykonywania, albo z powodu podpowiedzi RECOMPILE, albo dlatego, że jest wykonywane ad hoc?
Możemy zmienić procedurę, aby dodać wskazówkę RECOMPILE do instrukcji (co jest zalecane zamiast dodawania RECOMPILE na poziomie procedury lub uruchamiania procedury WITH RECOMIPLE):
ALTER PROCEDURE [Sales].[usp_OrderInfo_OrderDate] @StartDate DATETIME, @EndDate DATETIME AS SELECT [o].[CustomerID], [o].[OrderDate], [o].[ContactPersonID], [ol].[Quantity] FROM [Sales].[Orders] [o] JOIN [Sales].[OrderLines] [ol] ON [o].[OrderID] = [ol].[OrderID] WHERE [OrderDate] BETWEEN @StartDate AND @EndDate ORDER BY [OrderDate] OPTION (RECOMPILE); GO
Teraz ponownie uruchomimy naszą procedurę z tymi samymi parametrami wejściowymi co poprzednio i sprawdzimy dane wyjściowe:

Zwróć uwagę, że mamy nowy query_id — tekst zapytania zmienił się, ponieważ dodaliśmy do niego OPTION (RECOMPILE) — a także mamy dwie nowe wartości plan_id i mamy różne numery przydziałów pamięci dla jednego z naszych planów. Dla planu_id 5 istnieje tylko jedno wykonanie, a numery przyznania pamięci odpowiadają początkowemu wykonaniu – tak więc plan dotyczy małego zakresu dat. Dwa większe zakresy dat wygenerowały ten sam plan, ale istnieje znaczna zmienność przyznanych pamięci – 94 528 dla minimum i 573 568 dla maksimum.
Jeśli przyjrzymy się informacjom o przydzieleniu pamięci za pomocą raportów Query Store, ta zmienność przedstawia się nieco inaczej. Po otwarciu raportu Top Resource Consumers z bazy danych, a następnie zmianie metryki na Zużycie pamięci (KB) i Avg, nasze zapytanie z RECOMPILE trafia na górę listy.
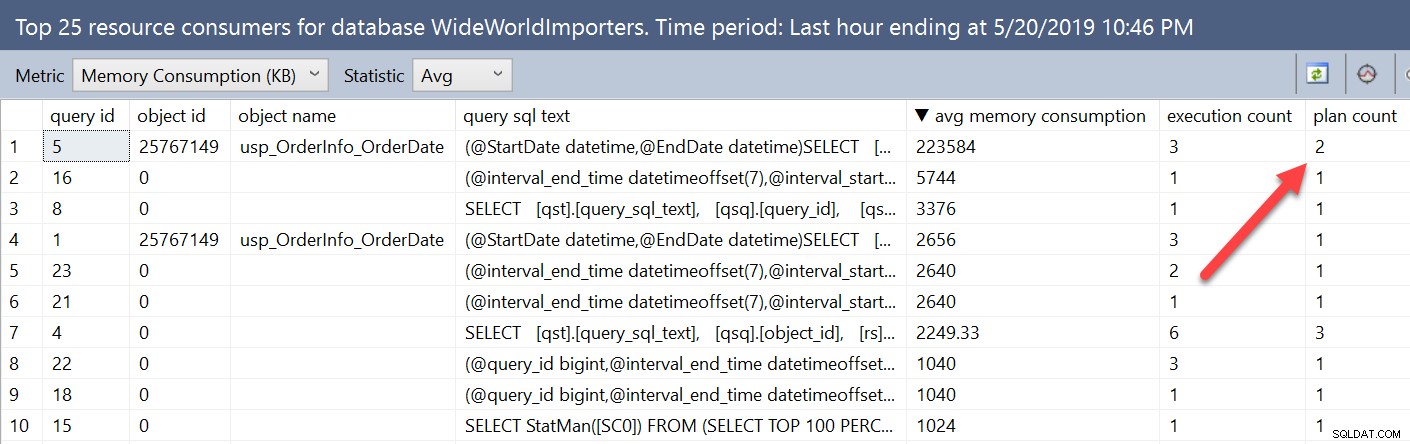
W tym oknie metryki są agregowane według zapytania, a nie planu. Zapytanie, które wykonaliśmy bezpośrednio w widokach magazynu zapytań, zawiera nie tylko identyfikator zapytania, ale także identyfikator planu. Tutaj możemy zobaczyć, że zapytanie ma dwa plany i możemy je wyświetlić w oknie podsumowania planu, ale metryki są połączone dla wszystkich planów w tym widoku.
Zmienność przyznawania pamięci jest oczywista, gdy patrzymy bezpośrednio na widoki. Możemy znaleźć zapytania ze zmiennością za pomocą interfejsu użytkownika, zmieniając statystykę ze średniej na StDev:
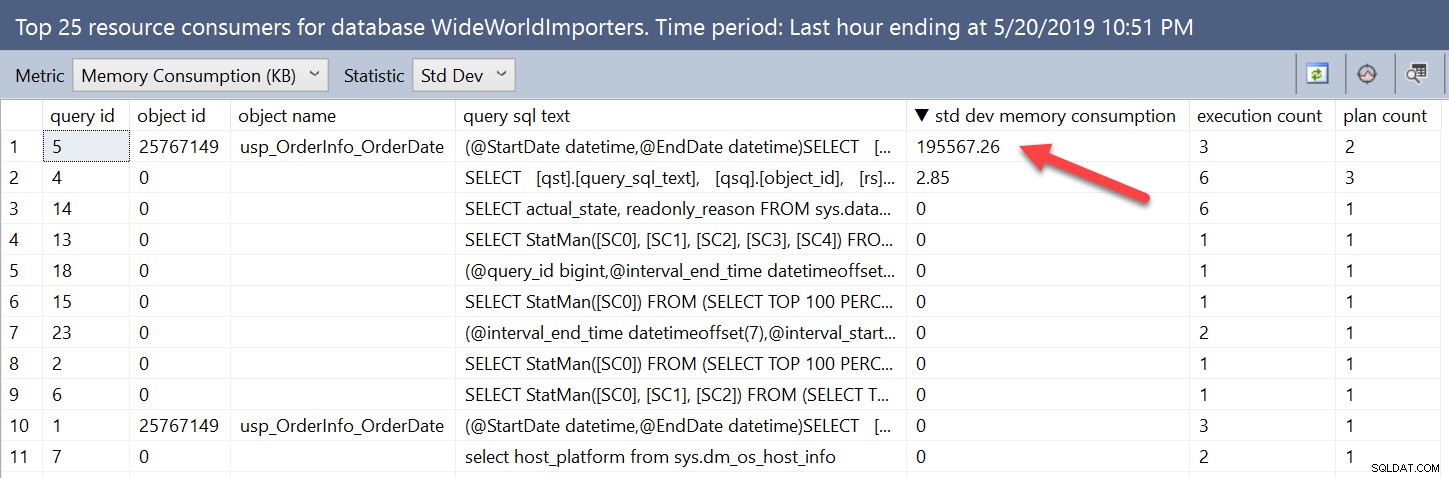
Te same informacje możemy znaleźć, wysyłając zapytania do widoków magazynu zapytań i porządkując je według stdev_query_max_used_memory malejąco. Ale możemy również wyszukiwać na podstawie różnicy między minimalnym i maksymalnym przydziałem pamięci lub procentem różnicy. Na przykład, jeśli obawialiśmy się przypadków, w których różnica w przydziałach była większa niż 512 MB, moglibyśmy uruchomić:
SELECT [qst].[query_sql_text], [qsq].[query_id], [qsp].[plan_id], [qsq].[object_id], [rs].[count_executions], [rs].[last_execution_time], [rs].[avg_duration], [rs].[avg_logical_io_reads], [rs].[avg_query_max_used_memory] * 8 AS [AvgUsedKB], [rs].[min_query_max_used_memory] * 8 AS [MinUsedKB], [rs].[max_query_max_used_memory] * 8 AS [MaxUsedKB], [rs].[last_query_max_used_memory] * 8 AS [LastUsedKB], [rs].[stdev_query_max_used_memory] * 8 AS [StDevUsedKB], TRY_CONVERT(XML, [qsp].[query_plan]) AS [QueryPlan_XML] FROM [sys].[query_store_query] [qsq] JOIN [sys].[query_store_query_text] [qst] ON [qsq].[query_text_id] = [qst].[query_text_id] JOIN [sys].[query_store_plan] [qsp] ON [qsq].[query_id] = [qsp].[query_id] JOIN [sys].[query_store_runtime_stats] [rs] ON [qsp].[plan_id] = [rs].[plan_id] WHERE ([rs].[max_query_max_used_memory]*8) - ([rs].[min_query_max_used_memory]*8) > 524288;
Osoby korzystające z programu SQL Server 2017 z indeksami magazynu kolumn, które mają przewagę w postaci opinii o przyznaniu pamięci, mogą również korzystać z tych informacji w magazynie zapytań. Najpierw zmienimy naszą tabelę Orders, aby dodać klastrowany indeks Columnstore:
ALTER TABLE [Sales].[Invoices] DROP CONSTRAINT [FK_Sales_Invoices_OrderID_Sales_Orders]; GO ALTER TABLE [Sales].[Orders] DROP CONSTRAINT [FK_Sales_Orders_BackorderOrderID_Sales_Orders]; GO ALTER TABLE [Sales].[OrderLines] DROP CONSTRAINT [FK_Sales_OrderLines_OrderID_Sales_Orders]; GO ALTER TABLE [Sales].[Orders] DROP CONSTRAINT [PK_Sales_Orders] WITH ( ONLINE = OFF ); GO CREATE CLUSTERED COLUMNSTORE INDEX CCI_Orders ON [Sales].[Orders];
Następnie ustawimy tryb rozczesywania bazy danych na 140, abyśmy mogli wykorzystać informację zwrotną o przyznaniu pamięci:
ALTER DATABASE [WideWorldImporters] SET COMPATIBILITY_LEVEL = 140; GO
Na koniec zmienimy naszą procedurę składowaną, aby usunąć OPTION (RECOMPILE) z naszego zapytania, a następnie uruchomimy ją kilka razy z różnymi wartościami wejściowymi:
ALTER PROCEDURE [Sales].[usp_OrderInfo_OrderDate] @StartDate DATETIME, @EndDate DATETIME AS SELECT [o].[CustomerID], [o].[OrderDate], [o].[ContactPersonID], [ol].[Quantity] FROM [Sales].[Orders] [o] JOIN [Sales].[OrderLines] [ol] ON [o].[OrderID] = [ol].[OrderID] WHERE [OrderDate] BETWEEN @StartDate AND @EndDate ORDER BY [OrderDate]; GO EXEC [Sales].[usp_OrderInfo_OrderDate] '2016-01-01', '2016-01-08'; GO EXEC [Sales].[usp_OrderInfo_OrderDate] '2016-01-01', '2016-06-30'; GO EXEC [Sales].[usp_OrderInfo_OrderDate] '2016-01-01', '2016-12-31'; GO EXEC [Sales].[usp_OrderInfo_OrderDate] '2016-01-01', '2016-06-30'; GO EXEC [Sales].[usp_OrderInfo_OrderDate] '2016-01-01', '2016-01-08'; GO EXEC [Sales].[usp_OrderInfo_OrderDate] '2016-01-01', '2016-12-31'; GO
W Query Store widzimy następujące elementy:

Mamy nowy plan dla query_id =1, który ma inne wartości dla metryk przydziału pamięci i nieco niższy StDev niż w przypadku plan_id 6. Jeśli spojrzymy na plan w Query Store, zobaczymy, że uzyskuje on dostęp do klastrowanego indeksu Columnstore :
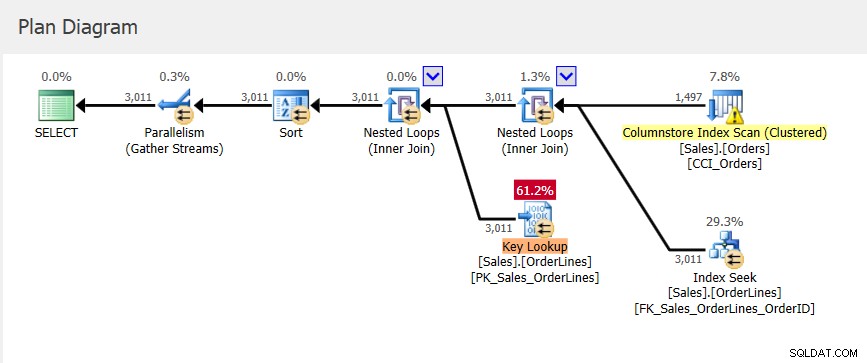
Pamiętaj, że plan w magazynie zapytań jest tym, który został wykonany, ale zawiera tylko szacunki. Chociaż plan w pamięci podręcznej planu ma zaktualizowane informacje o przyznaniu pamięci, gdy pojawia się informacja zwrotna o pamięci, informacje te nie są stosowane do istniejącego planu w magazynie zapytań.
Podsumowanie
Oto, co lubię w używaniu Query Store do przeglądania zapytań ze zmiennymi przydziałami pamięci:dane są gromadzone automatycznie. Jeśli ten problem pojawi się nieoczekiwanie, nie musimy niczego wprowadzać, aby spróbować zebrać informacje, już mamy je przechwycone w Query Store. W przypadku sparametryzowania zapytania może być trudniej znaleźć zmienność przyznania pamięci ze względu na potencjał wartości statycznych z powodu buforowania planu. Jednak możemy również odkryć, że z powodu ponownej kompilacji zapytanie ma wiele planów z bardzo różnymi wartościami przyznania pamięci, których możemy użyć do wyśledzenia problemu. Istnieje wiele sposobów na zbadanie problemu przy użyciu danych przechwyconych w Query Store, które pozwalają przyjrzeć się problemom zarówno proaktywnie, jak i reaktywnie.