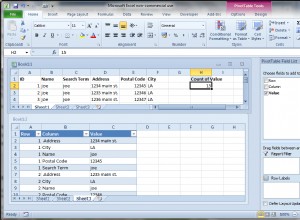
Nazwy można wyodrębnić za pomocą rekurencyjnego CTE i parsowania ciągów. Reszta to tylko agregacja:
with cte as (
select (case when names like '%,%'
then left(names, charindex(',', names) - 1)
else names
end) as name,
(case when names like '%,%'
then substring(names, charindex(',', names) + 1, len(names))
end) as names
from names
union all
select (case when names like '%,%'
then left(names, charindex(',', names) - 1)
else names
end) as name,
(case when names like '%,%'
then substring(names, charindex(',', names) + 1, len(names))
end)
from cte
where names is not null
)
select name, count(*)
from cte
group by name;
Jak zapewne się zorientowałeś, przechowywanie list rozdzielanych przecinkami w SQL Server to zły pomysł. Powinieneś mieć tabelę skojarzeń/połączeń z jednym wierszem na nazwę (i innymi kolumnami opisującymi listę, w której się znajduje).