Najlepszym sposobem, jaki znalazłem, aby to osiągnąć, jest:
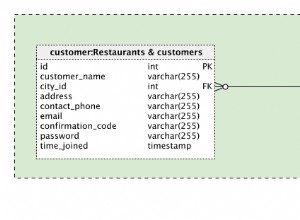
- Tworzę plik danych wyjściowych testowych. Wypełniam plik .txt zestawem wyników z zapytania SQL, które zostanie użyte w pakiecie. Upewnij się, że pierwszy wiersz pliku .txt zawiera nazwy nagłówków kolumn.
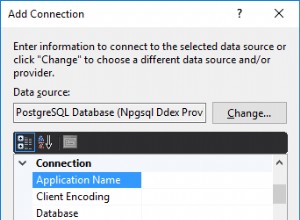
- Utwórz płaskie połączenie plików. Wskaż go na tekstowy plik tekstowy. Zaznacz pole „Nazwy kolumn w pierwszym wierszu danych”. Zapewni to, że zostaną użyte/pokazane rzeczywiste nazwy nagłówków kolumn, zamiast „Kolumna 0”, „Kolumna 1” itd. Kliknij „OK”, aby zamknąć Menedżera połączeń plików płaskich.
- Edytuj element docelowy pliku prostego, aby upewnić się, że są pobrane rzeczywiste nazwy nagłówków kolumn i że pola są prawidłowo mapowane między zapytaniem a kolumnami wyjściowymi połączenia pliku prostego. Kliknij „OK”.
- Podświetl Flat File Connection i naciśnij "F4", aby otworzyć okno "Properties". Tam zmień „ColumnNamesInFirstDataRow” na „False”.
Teraz twój wyjściowy plik płaski będzie zawierał tylko dane ... bez wiersza nagłówka kolumny. Jednak nadal możesz przejść do elementu docelowego pliku płaskiego i zobaczyć rzeczywiste nazwy nagłówków kolumn, które są tam używane.