MariaDB oferuje wbudowane możliwości shardingu na wielu hostach z aparatem pamięci masowej Spider. Spider obsługuje partycjonowanie i transakcje XA oraz umożliwia obsługę zdalnych tabel różnych instancji MariaDB tak, jakby znajdowały się w tej samej instancji. Zdalna tabela może być dowolnym silnikiem magazynu. Łączenie tabel jest osiągane przez ustanowienie połączenia z lokalnego serwera MariaDB ze zdalnym serwerem MariaDB, a łącze jest współdzielone dla wszystkich tabel, które są częścią tej samej transakcji.
W tym poście na blogu omówimy wdrażanie klastra dwóch fragmentów MariaDB przy użyciu ClusterControl. Zamierzamy wdrożyć kilka serwerów MariaDB (w celu zapewnienia nadmiarowości i dostępności), aby hostować tabelę partycjonowaną w oparciu o zakres wybranego klucza fragmentu. Wybrany klucz fragmentu to w zasadzie kolumna, która przechowuje wartości z dolnym i górnym limitem, tak jak w tym przypadku wartości całkowite z zakresu od 0 do 1 000 000, co czyni go najlepszym kluczem kandydującym do równoważenia dystrybucji danych między dwoma fragmentami. Dlatego podzielimy zakresy na dwie partycje:
-
0 - 499999:Fragment 1
-
500000 - 1000000:Fragment 2
Poniższy diagram ilustruje naszą wysokopoziomową architekturę tego, co zamierzamy wdrożyć:
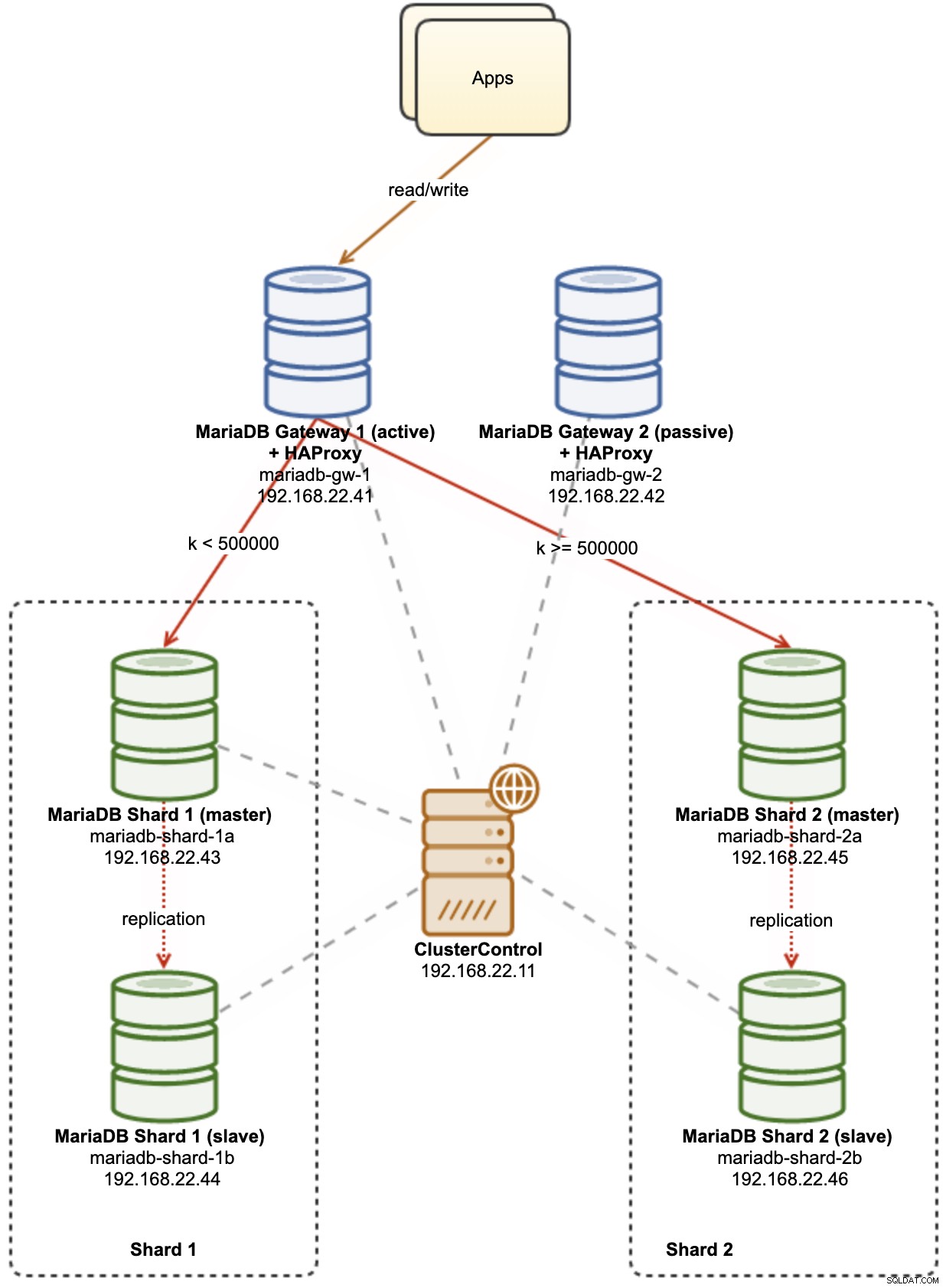
Kilka objaśnień diagramu:
-
mariadb-gw-1:instancja MariaDB z silnikiem pamięci masowej Spider działa jak router shard. Nadajemy temu hostowi nazwę MariaDB Gateway 1 i będzie to podstawowy (aktywny) serwer MariaDB, który ma dotrzeć do fragmentów. Aplikacja połączy się z tym hostem jak standardowe połączenie MariaDB. Ten węzeł łączy się z fragmentami przez nasłuchiwanie HAProxy na portach 127.0.0.1 3307 (shard1) i 3308 (shard2).
-
mariadb-gw-2:instancja MariaDB z silnikiem pamięci masowej Spider działa jak router shard. Nadajemy temu hostowi nazwę MariaDB Gateway 2 i będzie to drugorzędny (pasywny) serwer MariaDB, aby uzyskać dostęp do fragmentów. Będzie miał taką samą konfigurację jak mariadb-gw-1. Aplikacja połączy się z tym hostem tylko wtedy, gdy podstawowa baza danych MariaDB nie będzie działać. Ten węzeł łączy się z fragmentami przez nasłuchiwanie HAProxy na portach 127.0.0.1 3307 (shard1) i 3308 (shard2).
-
mariadb-shard-1a:główny węzeł MariaDB, który służy jako podstawowy węzeł danych dla pierwszej partycji. Serwery bramy MariaDB powinny zapisywać tylko do głównego fragmentu.
-
mariadb-shard-1b:replika MariaDB, która służy jako pomocniczy węzeł danych dla pierwszej partycji. Powinien przejąć rolę mastera w przypadku awarii mastera sharda (automatyczne przełączanie awaryjne jest zarządzane przez ClusterControl).
-
mariadb-shard-2a:główny węzeł MariaDB, który służy jako główny węzeł danych dla drugiej partycji. Serwery bramy MariaDB zapisują tylko do głównego fragmentu.
-
mariadb-shard-2b:replika MariaDB, która służy jako pomocniczy węzeł danych dla drugiej partycji. Powinien przejąć rolę mastera w przypadku awarii mastera sharda (automatyczne przełączanie awaryjne jest zarządzane przez ClusterControl).
-
ClusterControl:scentralizowane narzędzie do wdrażania, zarządzania i monitorowania naszych fragmentów/klastrów MariaDB.
Wdrażanie klastrów baz danych za pomocą ClusterControl
ClusterControl to narzędzie do automatyzacji służące do zarządzania cyklem życia systemu zarządzania bazą danych typu open source. Zamierzamy używać ClusterControl jako scentralizowanego narzędzia do wdrażania klastrów, zarządzania topologią i monitorowania na potrzeby tego wpisu na blogu.
1) Zainstaluj ClusterControl.
2) Skonfiguruj bezhasłowe SSH z serwera ClusterControl do wszystkich węzłów bazy danych. W węźle ClusterControl:
(clustercontrol)$ whoami
root
$ ssh-keygen -t rsa
$ ssh-copy-id example@sqldat.com
$ ssh-copy-id example@sqldat.com
$ ssh-copy-id example@sqldat.com
$ ssh-copy-id example@sqldat.com
$ ssh-copy-id example@sqldat.com
$ ssh-copy-id example@sqldat.com3) Ponieważ zamierzamy wdrożyć 4 zestawy klastrów, dobrym pomysłem jest użycie narzędzia ClusterControl CLI do tego konkretnego zadania, aby przyspieszyć i uprościć proces wdrażania. Najpierw sprawdźmy, czy możemy połączyć się z domyślnymi danymi uwierzytelniającymi, uruchamiając następujące polecenie (domyślne dane uwierzytelniające są automatycznie konfigurowane w /etc/s9s.conf):
(clustercontrol)$ s9s cluster --list --long
Total: 0Jeśli nie otrzymamy żadnych błędów i zobaczymy podobny wynik jak powyżej, dobrze jest iść.
4) Należy zauważyć, że kroki 4,5,6 i 7 można wykonać jednocześnie, ponieważ ClusterControl obsługuje wdrażanie równoległe. Zaczniemy od wdrożenia pierwszego serwera MariaDB Gateway przy użyciu ClusterControl CLI:
(clustercontrol)$ s9s cluster --create \
--cluster-type=mysqlreplication \
--nodes="192.168.22.101?master" \
--vendor=mariadb \
--provider-version=10.5 \
--os-user=root \
--os-key-file=/root/.ssh/id_rsa \
--db-admin="root" \
--db-admin-passwd="SuperS3cr3tPassw0rd" \
--cluster-name="MariaDB Gateway 1"5) Wdróż drugi serwer MariaDB Gateway:
(clustercontrol)$ s9s cluster --create \
--cluster-type=mysqlreplication \
--nodes="192.168.22.102?master" \
--vendor=mariadb \
--provider-version=10.5 \
--os-user=root \
--os-key-file=/root/.ssh/id_rsa \
--db-admin="root" \
--db-admin-passwd="SuperS3cr3tPassw0rd" \
--cluster-name="MariaDB Gateway 2"6) Wdróż 2-węzłową replikację MariaDB dla pierwszego fragmentu:
(clustercontrol)$ s9s cluster --create \
--cluster-type=mysqlreplication \
--nodes="192.168.22.111?master;192.168.22.112?slave" \
--vendor=mariadb \
--provider-version=10.5 \
--os-user=root \
--os-key-file=/root/.ssh/id_rsa \
--db-admin="root" \
--db-admin-passwd="SuperS3cr3tPassw0rd" \
--cluster-name="MariaDB - Shard 1"7) Wdróż 2-węzłową replikację MariaDB dla drugiego fragmentu:
(clustercontrol)$ s9s cluster --create \
--cluster-type=mysqlreplication \
--nodes="192.168.22.121?master;192.168.22.122?slave" \
--vendor=mariadb \
--provider-version=10.5 \
--os-user=root \
--os-key-file=/root/.ssh/id_rsa \
--db-admin="root" \
--db-admin-passwd="SuperS3cr3tPassw0rd" \
--cluster-name="MariaDB - Shard 2"Podczas wdrażania, możemy monitorować wyniki zadania z CLI:
(clustercontrol)$ s9s job --list --show-running
ID CID STATE OWNER GROUP CREATED RDY TITLE
25 0 RUNNING admin admins 07:19:28 45% Create MySQL Replication Cluster
26 0 RUNNING admin admins 07:19:38 45% Create MySQL Replication Cluster
27 0 RUNNING admin admins 07:20:06 30% Create MySQL Replication Cluster
28 0 RUNNING admin admins 07:20:14 30% Create MySQL Replication ClusterA także z interfejsu użytkownika ClusterControl:
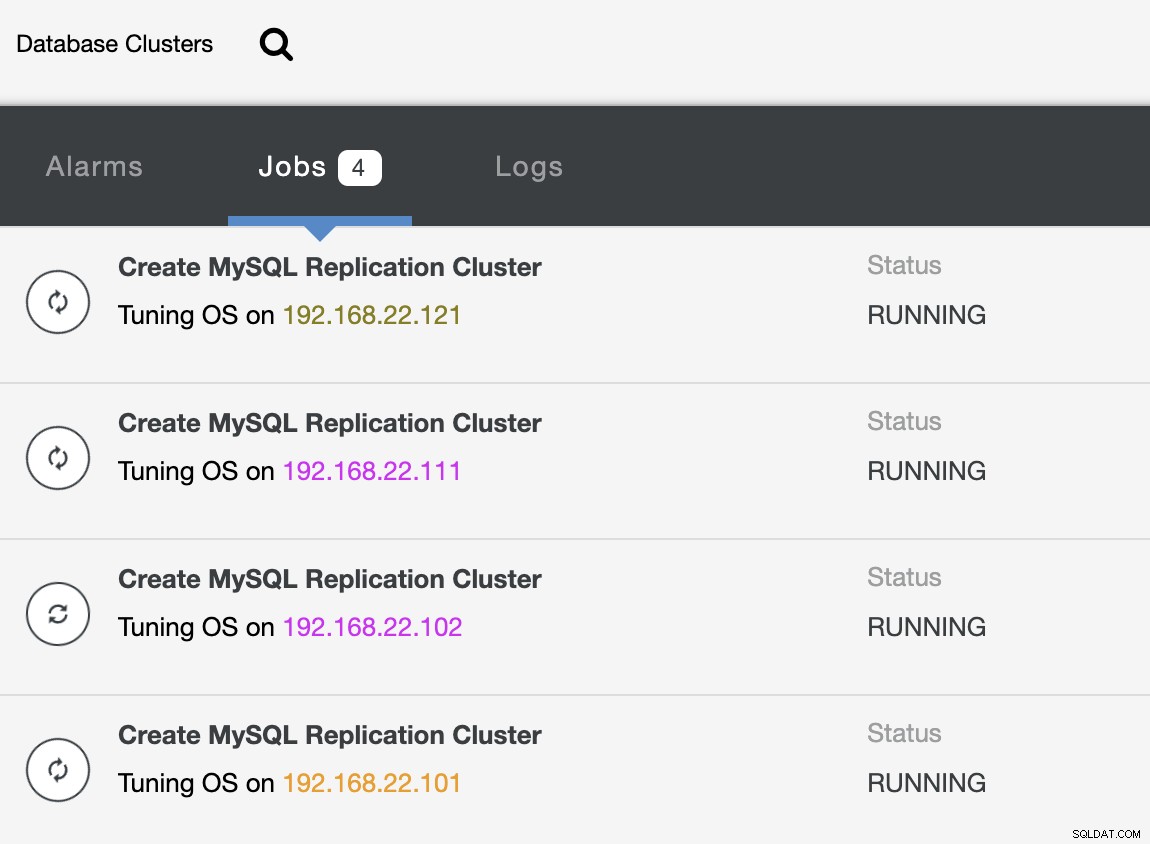
Po zakończeniu wdrażania powinieneś zobaczyć coś, co znajduje się na liście klastrów bazy danych tak w panelu ClusterControl:
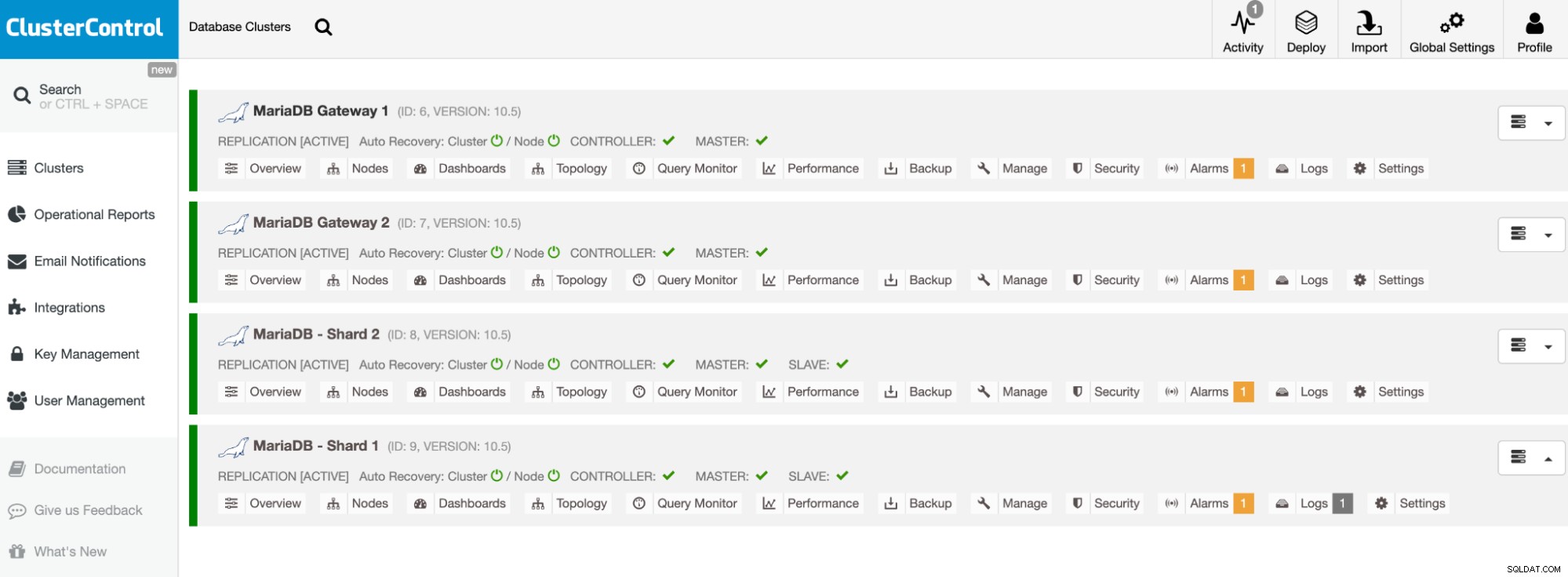
Nasze klastry są już wdrożone i korzystają z najnowszej wersji MariaDB 10.5. Następnie musimy skonfigurować HAProxy, aby udostępniał pojedynczy punkt końcowy fragmentom MariaDB.
Skonfiguruj HAProxy
HAProxy jest niezbędny jako pojedynczy punkt końcowy replikacji typu master-slave fragmentu. W przeciwnym razie w przypadku awarii mastera należy zaktualizować listę serwerów Spidera za pomocą instrukcji CREATE OR REPLACE SERVER w serwerach bramy, a następnie wykonać ALTER TABLE i przekazać nowy parametr połączenia. Dzięki HAProxy możemy skonfigurować go tak, aby nasłuchiwał na lokalnym hoście serwera bramy i monitorował różne fragmenty MariaDB z różnymi portami. Skonfigurujemy HAProxy na obu serwerach bramy w następujący sposób:
-
127.0.0.1:3307 -> Shard1 (serwery zaplecza to mariadb-shard-1a i mariadb-shard- 1b)
-
127.0.0.1:3308 -> Shard2 (serwery zaplecza to mariadb-shard-2a i mariadb-shard- 2b)
W przypadku awarii mastera sharda, ClusterControl przełączy awaryjnie slave sharda jako nowy master, a HAProxy odpowiednio przekieruje połączenia do nowego mastera. Zamierzamy zainstalować HAProxy na serwerach bramy (mariadb-gw-1 i mariadb-gw-2) za pomocą ClusterControl, ponieważ automatycznie skonfiguruje on serwery zaplecza (konfiguracja mysqlchk, dotacje użytkowników, instalacja xinetd) z kilkoma sztuczkami, jak pokazano poniżej.
Przede wszystkim w interfejsie użytkownika ClusterControl wybierz pierwszy fragment, MariaDB - Shard 1 -> Manage -> Load Balancers -> HAProxy -> Wdróż HAProxy i określ adres serwera jako 192.168.22.101 ( mariadb-gw-1), podobnie jak na poniższym zrzucie ekranu:
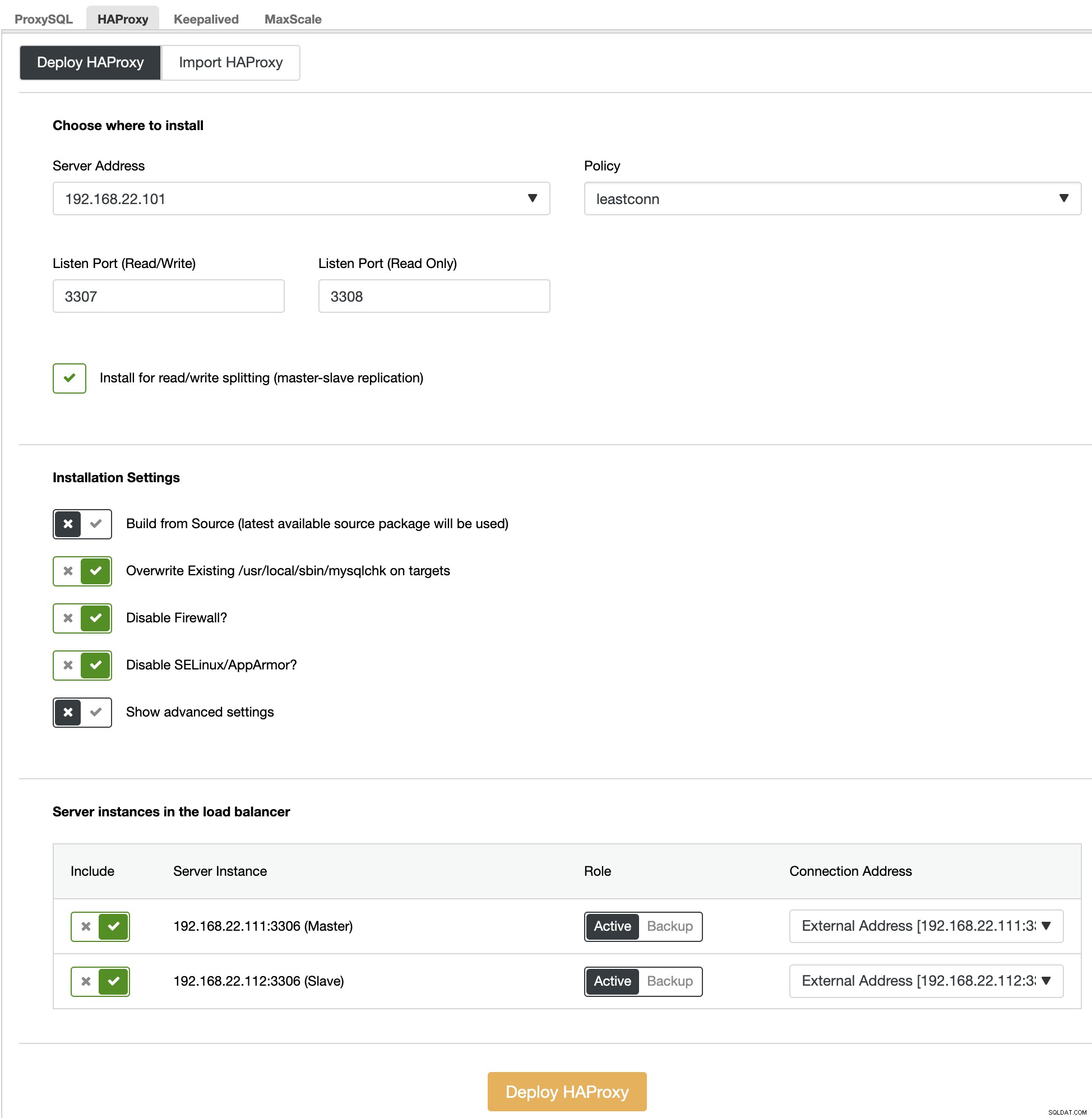
Podobnie, ale ten dla sharda 2, przejdź do MariaDB - Shard 2 -> Zarządzaj -> Load Balancers -> HAProxy -> Wdróż HAProxy i określ adres serwera jako 192.168.22.102 (mariadb-gw-2). Poczekaj, aż wdrożenie zakończy się dla obu węzłów HAProxy.
Teraz musimy skonfigurować usługę HAProxy na mariadb-gw-1 i mariadb-gw-2, aby równoważyć obciążenie wszystkich fragmentów jednocześnie. Używając edytora tekstu (lub ClusterControl UI -> Manage -> Configurations), edytuj 2 ostatnie dyrektywy „listen” pliku /etc/haproxy/haproxy.cfg, aby wyglądały tak:
listen haproxy_3307_shard1
bind *:3307
mode tcp
timeout client 10800s
timeout server 10800s
tcp-check connect port 9200
tcp-check expect string master\ is\ running
balance leastconn
option tcp-check
default-server port 9200 inter 2s downinter 5s rise 3 fall 2 slowstart 60s maxconn 64 maxqueue 128 weight 100
server 192.168.22.111 192.168.22.111:3306 check # mariadb-shard-1a-master
server 192.168.22.112 192.168.22.112:3306 check # mariadb-shard-1b-slave
listen haproxy_3308_shard2
bind *:3308
mode tcp
timeout client 10800s
timeout server 10800s
tcp-check connect port 9200
tcp-check expect string master\ is\ running
balance leastconn
option tcp-check
default-server port 9200 inter 2s downinter 5s rise 3 fall 2 slowstart 60s maxconn 64 maxqueue 128 weight 100
server 192.168.22.121 192.168.22.121:3306 check # mariadb-shard-2a-master
server 192.168.22.122 192.168.22.122:3306 check # mariadb-shard-2b-slaveUruchom ponownie usługę HAProxy, aby załadować zmiany (lub użyj ClusterControl -> Nodes -> HAProxy -> Restart Node):
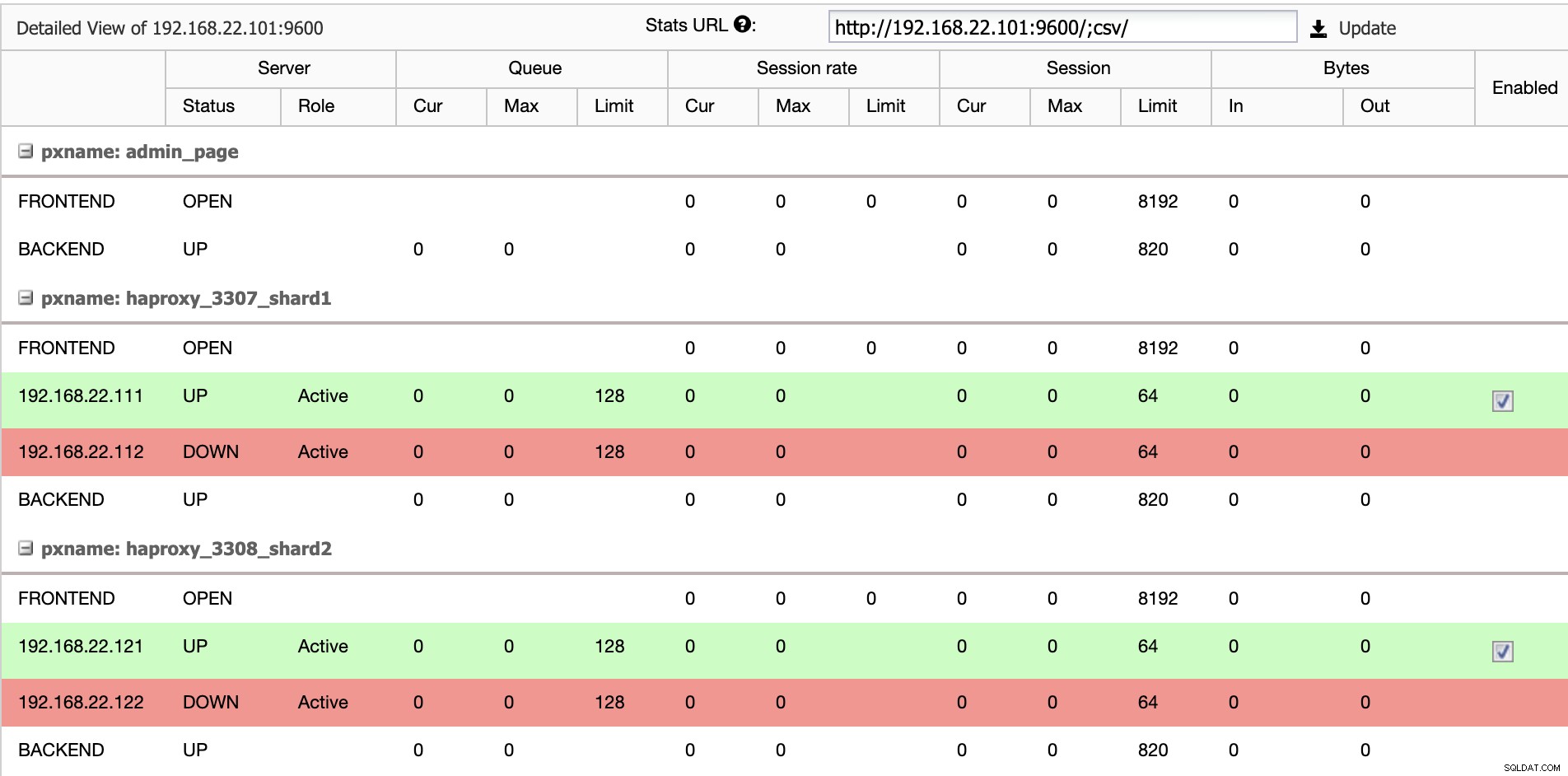
$ systemctl restart haproxyW interfejsie użytkownika ClusterControl możemy sprawdzić, czy tylko jeden serwer zaplecza jest aktywny na fragment (wskazywany przez zielone linie), jak pokazano poniżej:
Na tym etapie wdrażanie naszego klastra bazy danych jest już zakończone. Możemy przystąpić do konfiguracji fragmentowania MariaDB za pomocą silnika pamięci masowej Spider.
Przygotowywanie serwerów bram MariaDB
Na obu serwerach MariaDB Gateway (mariadb-gw-1 i mariadb-gw-2) wykonaj następujące zadania:
Zainstaluj wtyczkę Spider:
MariaDB> INSTALL PLUGIN spider SONAME 'ha_spider.so';Sprawdź, czy silnik pamięci masowej jest obsługiwany:
MariaDB> SELECT engine,support FROM information_schema.engines WHERE engine = 'spider';
+--------+---------+
| engine | support |
+--------+---------+
| SPIDER | YES |
+--------+---------+Opcjonalnie możemy również zweryfikować, czy wtyczka jest poprawnie załadowana z bazy danych information_schema:
MariaDB> SELECT PLUGIN_NAME,PLUGIN_VERSION,PLUGIN_STATUS,PLUGIN_TYPE FROM information_schema.plugins WHERE plugin_name LIKE 'SPIDER%';
+--------------------------+----------------+---------------+--------------------+
| PLUGIN_NAME | PLUGIN_VERSION | PLUGIN_STATUS | PLUGIN_TYPE |
+--------------------------+----------------+---------------+--------------------+
| SPIDER | 3.3 | ACTIVE | STORAGE ENGINE |
| SPIDER_ALLOC_MEM | 1.0 | ACTIVE | INFORMATION SCHEMA |
| SPIDER_WRAPPER_PROTOCOLS | 1.0 | ACTIVE | INFORMATION SCHEMA |
+--------------------------+----------------+---------------+--------------------+Dodaj następujący wiersz w sekcji [mysqld] w pliku konfiguracyjnym MariaDB:
plugin-load-add = ha_spiderUtwórz pierwszy "węzeł danych" dla pierwszego fragmentu, który powinien być dostępny przez HAProxy 127.0.0.1 na porcie 3307:
MariaDB> CREATE OR REPLACE SERVER Shard1
FOREIGN DATA WRAPPER mysql
OPTIONS (
HOST '127.0.0.1',
DATABASE 'sbtest',
USER 'spider',
PASSWORD 'SpiderP455',
PORT 3307);Utwórz drugi „węzeł danych” dla drugiego fragmentu, który powinien być dostępny przez HAProxy 127.0.0.1 na porcie 3308:
CREATE OR REPLACE SERVER Shard2
FOREIGN DATA WRAPPER mysql
OPTIONS (
HOST '127.0.0.1',
DATABASE 'sbtest',
USER 'spider',
PASSWORD 'SpiderP455',
PORT 3308);Teraz możemy utworzyć tabelę Spider, która wymaga partycjonowania. W tym przykładzie utworzymy tabelę o nazwie sbtest1 wewnątrz bazy danych sbtest, podzieloną według wartości całkowitej w kolumnie 'k':
MariaDB> CREATE SCHEMA sbtest;
MariaDB> CREATE TABLE sbtest.sbtest1 (
`id` int(11) NOT NULL AUTO_INCREMENT,
`k` int(11) NOT NULL DEFAULT '0',
`c` char(120) NOT NULL DEFAULT '',
`pad` char(60) NOT NULL DEFAULT '',
PRIMARY KEY (`id`, `k`)
)
ENGINE=Spider
COMMENT 'wrapper "mysql", table "sbtest1"'
PARTITION BY RANGE (k) (
PARTITION shard1 VALUES LESS THAN (499999) COMMENT = 'srv "Shard1"',
PARTITION shard2 VALUES LESS THAN MAXVALUE COMMENT = 'srv "Shard2"'
);Zauważ, że klauzule COMMENT ='srv "ShardX"' instrukcji CREATE TABLE są krytyczne, gdy przekazujemy informacje o połączeniu ze zdalnym serwerem. Wartość musi być identyczna z nazwą serwera, jak w instrukcji CREATE SERVER. Zamierzamy wypełnić tę tabelę za pomocą generatora obciążenia Sysbench, jak pokazano poniżej.
Utwórz użytkownika bazy danych aplikacji, aby uzyskać dostęp do bazy danych i zezwól na to z serwerów aplikacji:
MariaDB> CREATE USER example@sqldat.com'192.168.22.%' IDENTIFIED BY 'passw0rd';
MariaDB> GRANT ALL PRIVILEGES ON sbtest.* TO example@sqldat.com'192.168.22.%';W tym przykładzie, ponieważ jest to zaufana sieć wewnętrzna, po prostu używamy symbolu wieloznacznego w instrukcji, aby zezwolić na dowolny adres IP z tego samego zakresu, 192.168.22.0/24.
Jesteśmy teraz gotowi do skonfigurowania naszych węzłów danych.
Przygotowywanie serwerów fragmentów MariaDB
Na obu serwerach głównych MariaDB Shard (mariadb-shard-1a i mariadb-shard-2a) wykonaj następujące zadania:
1) Utwórz docelową bazę danych:
MariaDB> CREATE SCHEMA sbtest;2) Utwórz użytkownika „pająk” i zezwól na połączenia z serwerów bramy (mariadb-gw-1 i mariadb-gw2). Ten użytkownik musi mieć wszystkie uprawnienia do tabeli podzielonej na fragmenty, a także do bazy danych systemu MySQL :
MariaDB> CREATE USER 'spider'@'192.168.22.%' IDENTIFIED BY 'SpiderP455';
MariaDB> GRANT ALL PRIVILEGES ON sbtest.* TO example@sqldat.com'192.168.22.%';
MariaDB> GRANT ALL ON mysql.* TO example@sqldat.com'192.168.22.%';W tym przykładzie, ponieważ jest to zaufana sieć wewnętrzna, po prostu używamy symbolu wieloznacznego w instrukcji, aby zezwolić na dowolny adres IP z tego samego zakresu, 192.168.22.0/24.
3) Utwórz tabelę, która będzie otrzymywać dane z naszych serwerów bramy za pośrednictwem silnika pamięci masowej Spider. Ta tabela „odbiorców” może znajdować się w dowolnym aparacie pamięci masowej obsługiwanym przez MariaDB. W tym przykładzie używamy silnika pamięci masowej InnoDB:
MariaDB> CREATE TABLE sbtest.sbtest1 (
`id` int(11) NOT NULL AUTO_INCREMENT,
`k` int(11) NOT NULL DEFAULT '0',
`c` char(120) NOT NULL DEFAULT '',
`pad` char(60) NOT NULL DEFAULT '',
PRIMARY KEY (`id`, `k`)
) ENGINE = INNODB;To wszystko. Nie zapomnij powtórzyć kroków na drugim fragmencie.
Testowanie
Aby przetestować za pomocą Sysbench do generowania niektórych obciążeń bazy danych na serwerze aplikacji, musimy wcześniej zainstalować Sysbench:
$ yum install -y https://repo.percona.com/yum/percona-release-latest.noarch.rpm
$ yum install -y sysbenchWygeneruj kilka testowych obciążeń i wyślij je do pierwszego serwera bramy, mariadb-gw-1 (192.168.11.101):
$ sysbench \
/usr/share/sysbench/oltp_insert.lua \
--report-interval=2 \
--threads=4 \
--rate=20 \
--time=9999 \
--db-driver=mysql \
--mysql-host=192.168.11.101 \
--mysql-port=3306 \
--mysql-user=sbtest \
--mysql-db=sbtest \
--mysql-password=passw0rd \
--tables=1 \
--table-size=1000000 \
runMożesz powtórzyć powyższy test na mariadb-gw-2 (192.168.11.102), a połączenia z bazą danych powinny być odpowiednio kierowane do właściwego fragmentu.
Patrząc na pierwszy fragment (mariadb-shard-1a lub mariadb-shard-1b), możemy stwierdzić, że ta partycja zawiera tylko wiersze, w których klucz fragmentu (kolumna k) jest mniejszy niż 500000:
MariaDB [sbtest]> SELECT MIN(k),MAX(k) FROM sbtest1;
+--------+--------+
| min(k) | max(k) |
+--------+--------+
| 200175 | 499963 |
+--------+--------+W innym fragmencie (mariadb-shard-2a lub mariadb-shard-2b) przechowuje dane od 500000 do 999999 zgodnie z oczekiwaniami:
MariaDB [sbtest]> SELECT MIN(k),MAX(k) FROM sbtest1;
+--------+--------+
| min(k) | max(k) |
+--------+--------+
| 500067 | 999948 |
+--------+--------+Podczas gdy w przypadku serwera MariaDB Gateway (mariadb-gw-1 lub mariadb-gw-2), możemy zobaczyć wszystkie wiersze podobne do sytuacji, gdy tabela istnieje w tej instancji MariaDB:
MariaDB [sbtest]> SELECT MIN(k),MAX(k) FROM sbtest1;
+--------+--------+
| min(k) | max(k) |
+--------+--------+
| 200175 | 999948 |
+--------+--------+Aby przetestować aspekt wysokiej dostępności, gdy główny fragmentu nie jest dostępny, na przykład gdy główny (mariadb-shard-2a) fragmentu 2 ulegnie awarii, ClusterControl automatycznie przeprowadzi promocję urządzenia podrzędnego na niewolnik (mariadb-shard-2b), aby był panem. W tym okresie prawdopodobnie można było zobaczyć ten błąd:
ERROR 1429 (HY000) at line 1: Unable to connect to foreign data source: Shard2I podczas jego niedostępności otrzymasz następujący błąd:
ERROR 1158 (08S01) at line 1: Got an error reading communication packetsW naszych pomiarach przełączanie awaryjne trwało około 23 sekund po rozpoczęciu przełączania awaryjnego, a po wypromowaniu nowego mastera powinno być możliwe zapisywanie do tabeli z serwera bramy jak zwykle.
Wnioski
Powyższa konfiguracja jest dowodem zasady, w jaki sposób ClusterControl może być używany do wdrażania konfiguracji podzielonej na fragmenty MariaDB. Może również poprawić dostępność usługi konfiguracji fragmentowania MariaDB dzięki funkcji automatycznego odzyskiwania węzłów i klastrów, a także wszystkim standardowym funkcjom zarządzania i monitorowania w celu obsługi ogólnej infrastruktury bazy danych.