Sysbench to doskonałe narzędzie do generowania danych testowych i wykonywania testów porównawczych MySQL OLTP. Zwykle podczas wykonywania testu porównawczego za pomocą Sysbench wykonuje się cykl przygotowania, uruchomienia i czyszczenia. Domyślnie tabela generowana przez Sysbench jest standardową tabelą podstawową bez partycji. To zachowanie można oczywiście rozszerzyć, ale musisz wiedzieć, jak napisać je w skrypcie LUA.
W tym wpisie na blogu pokażemy, jak generować dane testowe dla partycjonowanej tabeli w MySQL za pomocą Sysbench. Może to służyć jako plac zabaw do dalszego zagłębiania się w przyczynowo-skutkowy skutek partycjonowania tabel, dystrybucji danych i routingu zapytań.
Partycjonowanie tabeli na jednym serwerze
Partycjonowanie na jednym serwerze oznacza po prostu, że wszystkie partycje tabeli znajdują się na tym samym serwerze/instancji MySQL. Tworząc strukturę tabeli, zdefiniujemy wszystkie partycje jednocześnie. Ten rodzaj partycjonowania jest dobry, jeśli masz dane, które z czasem tracą swoją użyteczność i można je łatwo usunąć z partycjonowanej tabeli przez upuszczenie partycji (lub partycji) zawierającej tylko te dane.
Utwórz schemat Sysbench:
mysql> CREATE SCHEMA sbtest;Utwórz użytkownika bazy danych sysbench:
mysql> CREATE USER 'sbtest'@'%' IDENTIFIED BY 'passw0rd';
mysql> GRANT ALL PRIVILEGES ON sbtest.* TO 'sbtest'@'%';W Sysbench można użyć polecenia --prepare, aby przygotować serwer MySQL ze strukturami schematu i wygenerować wiersze danych. Musimy pominąć tę część i ręcznie zdefiniować strukturę tabeli.
Utwórz tabelę podzieloną na partycje. W tym przykładzie utworzymy tylko jedną tabelę o nazwie sbtest1 i zostanie ona podzielona przez kolumnę o nazwie „k”, która jest zasadniczo liczbą całkowitą z przedziału od 0 do 1 000 000 (w oparciu o opcję --table-size, którą jesteśmy będzie później używany w operacji tylko wstawiania):
mysql> CREATE TABLE `sbtest1` (
`id` int(11) NOT NULL AUTO_INCREMENT,
`k` int(11) NOT NULL DEFAULT '0',
`c` char(120) NOT NULL DEFAULT '',
`pad` char(60) NOT NULL DEFAULT '',
PRIMARY KEY (`id`,`k`)
)
PARTITION BY RANGE (k) (
PARTITION p1 VALUES LESS THAN (499999),
PARTITION p2 VALUES LESS THAN MAXVALUE
);Będziemy mieć 2 partycje - Pierwsza partycja nazywa się p1 i będzie przechowywać dane, w których wartość w kolumnie "k" jest mniejsza niż 499 999, a druga partycja, p2, będzie przechowywać pozostałe wartości . Tworzymy również klucz podstawowy, który zawiera obie ważne kolumny — „id” to identyfikator wiersza, a „k” to klucz partycji. Podczas partycjonowania klucz podstawowy musi zawierać wszystkie kolumny w funkcji partycjonowania tabeli (gdzie używamy „k” w funkcji partycjonowania zakresu).
Sprawdź, czy są tam partycje:
mysql> SELECT TABLE_SCHEMA, TABLE_NAME, PARTITION_NAME, TABLE_ROWS
FROM INFORMATION_SCHEMA.PARTITIONS
WHERE TABLE_SCHEMA='sbtest2'
AND TABLE_NAME='sbtest1';
+--------------+------------+----------------+------------+
| TABLE_SCHEMA | TABLE_NAME | PARTITION_NAME | TABLE_ROWS |
+--------------+------------+----------------+------------+
| sbtest | sbtest1 | p1 | 0 |
| sbtest | sbtest1 | p2 | 0 |
+--------------+------------+----------------+------------+Następnie możemy rozpocząć operację tylko wstawiania Sysbench, jak poniżej:
$ sysbench \
/usr/share/sysbench/oltp_insert.lua \
--report-interval=2 \
--threads=4 \
--rate=20 \
--time=9999 \
--db-driver=mysql \
--mysql-host=192.168.11.131 \
--mysql-port=3306 \
--mysql-user=sbtest \
--mysql-db=sbtest \
--mysql-password=passw0rd \
--tables=1 \
--table-size=1000000 \
runObserwuj, jak partycje tabel rosną w miarę uruchamiania Sysbench:
mysql> SELECT TABLE_SCHEMA, TABLE_NAME, PARTITION_NAME, TABLE_ROWS
FROM INFORMATION_SCHEMA.PARTITIONS
WHERE TABLE_SCHEMA='sbtest2'
AND TABLE_NAME='sbtest1';
+--------------+------------+----------------+------------+
| TABLE_SCHEMA | TABLE_NAME | PARTITION_NAME | TABLE_ROWS |
+--------------+------------+----------------+------------+
| sbtest | sbtest1 | p1 | 1021 |
| sbtest | sbtest1 | p2 | 1644 |
+--------------+------------+----------------+------------+Jeśli policzymy całkowitą liczbę wierszy za pomocą funkcji ILE.LICZB, będzie to odpowiadać całkowitej liczbie wierszy zgłaszanych przez partycje:
mysql> SELECT COUNT(id) FROM sbtest1;
+-----------+
| count(id) |
+-----------+
| 2665 |
+-----------+To wszystko. Mamy gotowe partycjonowanie tabeli na jednym serwerze, z którym możemy się pobawić.
Partycjonowanie tabel na wielu serwerach
W partycjonowaniu wieloserwerowym będziemy używać wielu serwerów MySQL do fizycznego przechowywania podzbioru danych określonej tabeli (sbtest1), jak pokazano na poniższym diagramie:
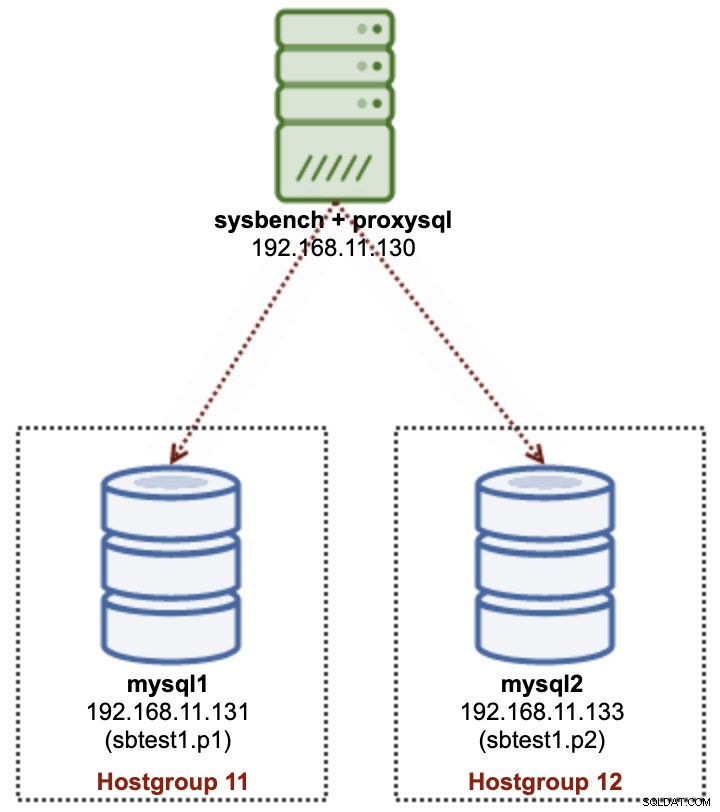
Zamierzamy wdrożyć 2 niezależne węzły MySQL - mysql1 i mysql2. Tabela sbtest1 zostanie podzielona na te dwa węzły i tę kombinację partycja + host nazwiemy fragmentem. Sysbench działa zdalnie na trzecim serwerze, naśladując warstwę aplikacji. Ponieważ Sysbench nie rozpoznaje partycji, musimy mieć sterownik bazy danych lub router, aby kierować zapytania bazy danych do właściwego fragmentu. W tym celu użyjemy ProxySQL.
Stwórzmy w tym celu kolejną nową bazę danych o nazwie sbtest3:
mysql> CREATE SCHEMA sbtest3;
mysql> USE sbtest3;Przyznaj odpowiednie uprawnienia użytkownikowi bazy danych sbtest:
mysql> CREATE USER 'sbtest'@'%' IDENTIFIED BY 'passw0rd';
mysql> GRANT ALL PRIVILEGES ON sbtest3.* TO 'sbtest'@'%';W mysql1 utwórz pierwszą partycję tabeli:
mysql> CREATE TABLE `sbtest1` (
`id` int(11) NOT NULL AUTO_INCREMENT,
`k` int(11) NOT NULL DEFAULT '0',
`c` char(120) NOT NULL DEFAULT '',
`pad` char(60) NOT NULL DEFAULT '',
PRIMARY KEY (`id`,`k`)
)
PARTITION BY RANGE (k) (
PARTITION p1 VALUES LESS THAN (499999)
);W przeciwieństwie do samodzielnego partycjonowania, definiujemy tylko warunek dla partycji p1 w tabeli, aby przechowywać wszystkie wiersze z wartościami kolumny „k” z zakresu od 0 do 499 999.
W mysql2 utwórz kolejną partycjonowaną tabelę:
mysql> CREATE TABLE `sbtest1` (
`id` int(11) NOT NULL AUTO_INCREMENT,
`k` int(11) NOT NULL DEFAULT '0',
`c` char(120) NOT NULL DEFAULT '',
`pad` char(60) NOT NULL DEFAULT '',
PRIMARY KEY (`id`,`k`)
)
PARTITION BY RANGE (k) (
PARTITION p2 VALUES LESS THAN MAXVALUE
);Na drugim serwerze powinien przechowywać dane drugiej partycji, przechowując pozostałe przewidywane wartości kolumny "k".
Nasza struktura tabeli jest teraz gotowa do wypełnienia danymi testowymi.
Zanim będziemy mogli uruchomić operację tylko wstawiania Sysbench, musimy zainstalować serwer ProxySQL jako router zapytań i działać jako brama dla naszych fragmentów MySQL. Fragmentacja na wielu serwerach wymaga, aby połączenia bazy danych pochodzące z aplikacji były kierowane do właściwego fragmentu. W przeciwnym razie zobaczysz następujący błąd:
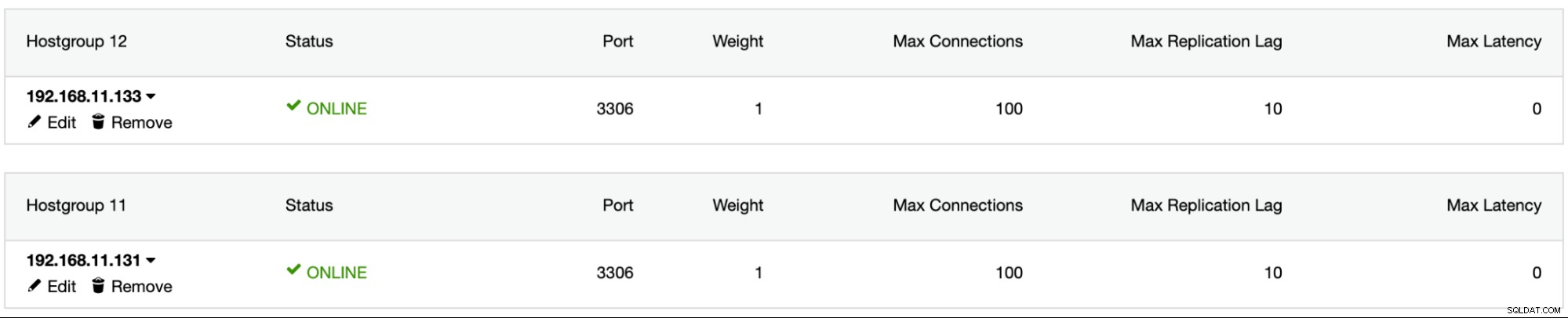
1526 (Table has no partition for value 503599)Zainstaluj ProxySQL za pomocą ClusterControl, dodaj użytkownika bazy danych sbtest do ProxySQL, dodaj oba serwery MySQL do ProxySQL i skonfiguruj mysql1 jako grupę hostów 11 i mysql2 jako grupę hostów 12:
Następnie musimy popracować nad sposobem kierowania zapytania. Przykładowe zapytanie INSERT, które zostanie wykonane przez Sysbench, będzie wyglądać mniej więcej tak:
INSERT INTO sbtest1 (id, k, c, pad)
VALUES (0, 503502, '88816935247-23939908973-66486617366-05744537902-39238746973-63226063145-55370375476-52424898049-93208870738-99260097520', '36669559817-75903498871-26800752374-15613997245-76119597989')Dlatego użyjemy następującego wyrażenia regularnego do filtrowania zapytania INSERT dla "k" => 500000, aby spełnić warunek partycjonowania:
^INSERT INTO sbtest1 \(id, k, c, pad\) VALUES \([0-9]\d*, ([5-9]{1,}[0-9]{5}|[1-9]{1,}[0-9]{6,}).*Powyższe wyrażenie po prostu próbuje filtrować następujące elementy:
-
[0-9]\d* - Spodziewamy się tutaj liczby całkowitej auto-inkrementacji, dlatego dopasowujemy dowolną liczbę całkowitą.
-
[5-9]{1,}[0-9]{5} - Wartość pasuje do dowolnej liczby całkowitej od 5 jako pierwszej cyfry i od 0 do 9 na ostatnich 5 cyfrach, aby dopasować wartość z zakresu od 500 000 do 999 999.
-
[1-9]{1,}[0-9]{6,} - Wartość pasuje do dowolnej liczby całkowitej od 1-9 jako pierwszej cyfry i 0-9 na ostatnich 6 lub większych cyfrach, aby dopasować wartość od 1 000 000 i większą.
Stworzymy dwie podobne reguły zapytań. Pierwsza reguła zapytania to negacja powyższego wyrażenia regularnego. Podajemy ten identyfikator reguły 51, a docelową grupą hostów powinna być grupa hostów 11, aby dopasować kolumnę „k” <500 000 i przekazać zapytania do pierwszej partycji. Powinno to wyglądać tak:
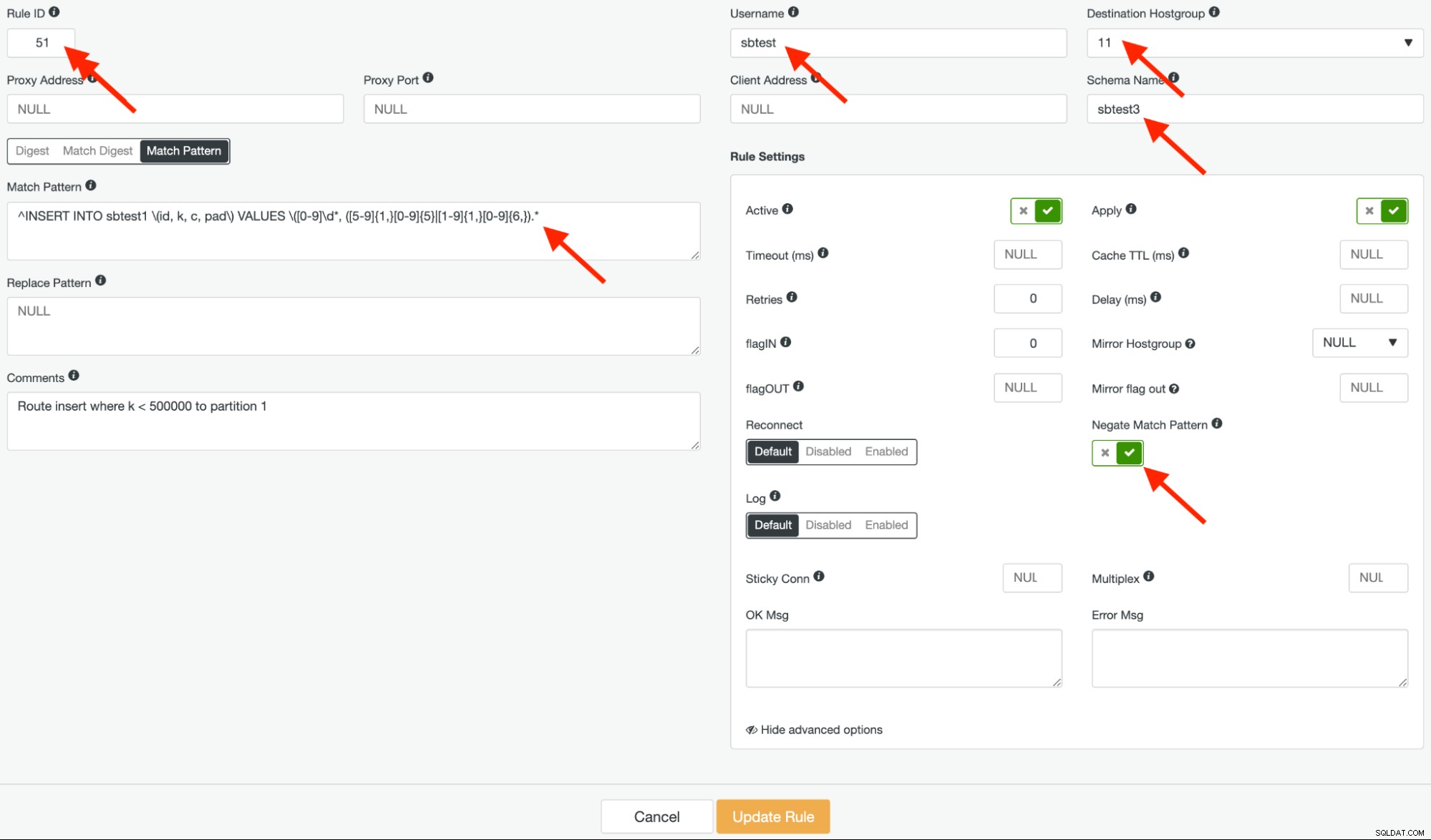
Zwróć uwagę na „Negate Match Pattern” na powyższym zrzucie ekranu. Ta opcja ma kluczowe znaczenie dla prawidłowego routingu tej reguły zapytania.
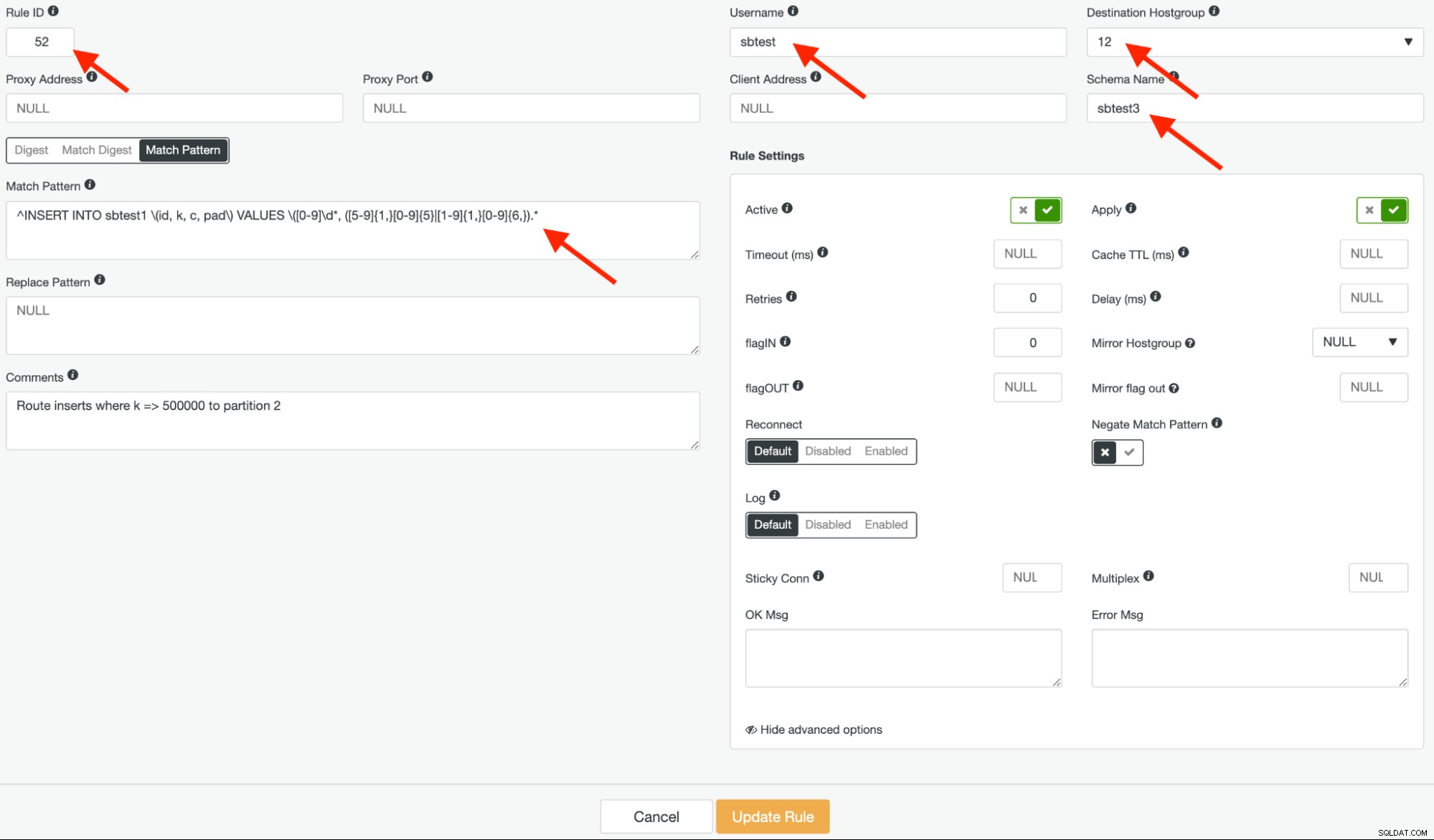
Następnie utwórz kolejną regułę zapytania z identyfikatorem reguły 52, używając tego samego wyrażenia regularnego, a docelowa grupa hostów powinna mieć wartość 12, ale tym razem pozostaw „Wzorzec zanegowania dopasowania” jako fałsz, jak pokazano poniżej:
Możemy wtedy rozpocząć operację tylko wstawiania za pomocą Sysbench do wygenerowania danych testowych . Informacje związane z dostępem do MySQL powinny dotyczyć hosta ProxySQL (192.168.11.130 na porcie 6033):
$ sysbench \
/usr/share/sysbench/oltp_insert.lua \
--report-interval=2 \
--threads=4 \
--rate=20 \
--time=9999 \
--db-driver=mysql \
--mysql-host=192.168.11.130 \
--mysql-port=6033 \
--mysql-user=sbtest \
--mysql-db=sbtest3 \
--mysql-password=passw0rd \
--tables=1 \
--table-size=1000000 \
runJeśli nie widzisz żadnego błędu, oznacza to, że ProxySQL skierował nasze zapytania do właściwego fragmentu/partycji. Powinieneś zobaczyć, że liczba trafień reguł zapytania wzrasta, gdy proces Sysbench jest uruchomiony:
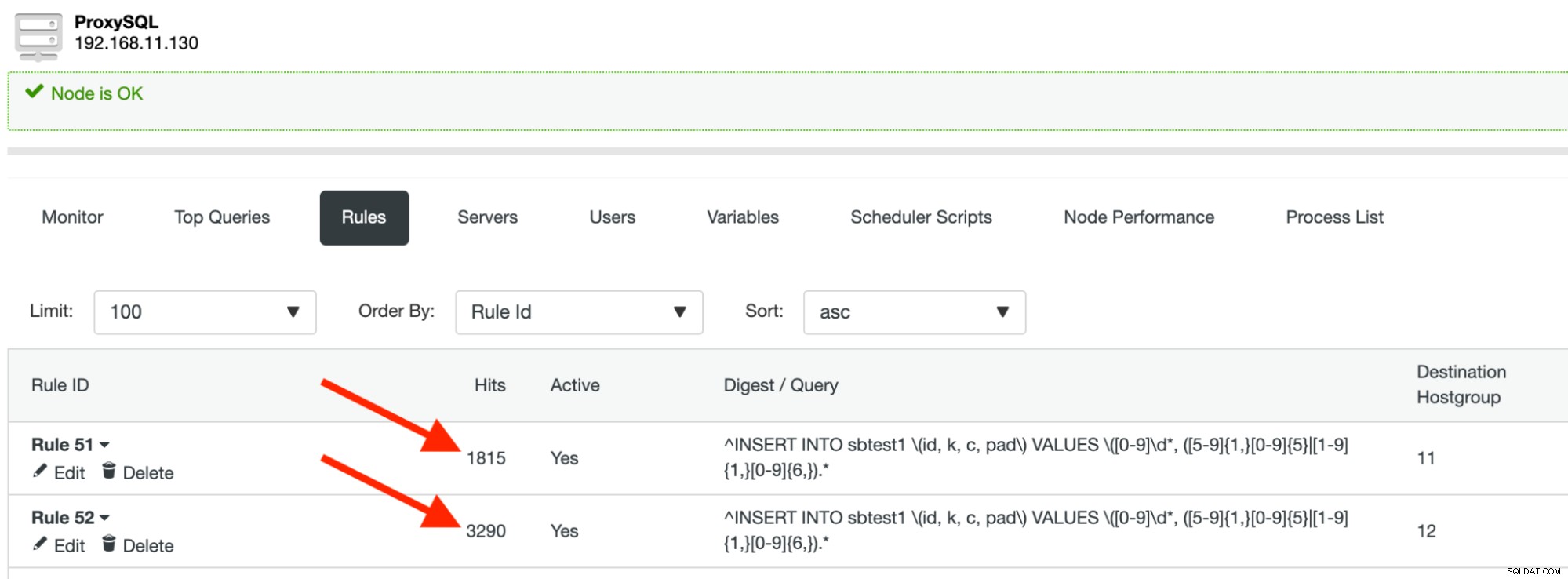
W sekcji Najpopularniejsze zapytania możemy zobaczyć podsumowanie routingu zapytań:
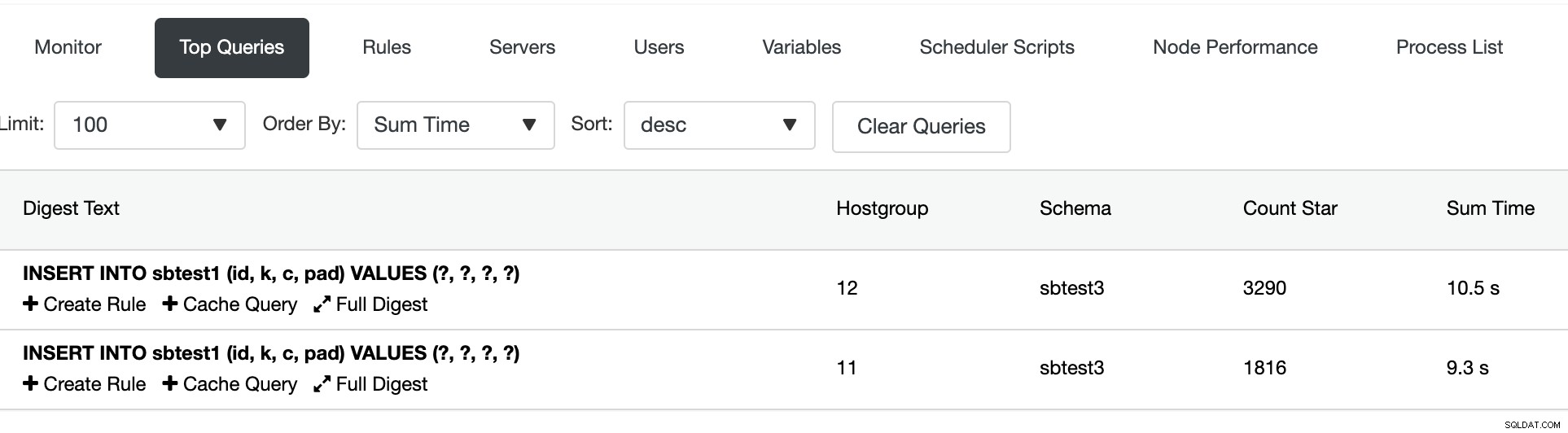
Aby to sprawdzić, zaloguj się do mysql1, aby wyszukać pierwszą partycję i sprawdź minimalną i maksymalną wartość kolumny 'k' w tabeli sbtest1:
mysql> USE sbtest3;
mysql> SELECT min(k), max(k) FROM sbtest1;
+--------+--------+
| min(k) | max(k) |
+--------+--------+
| 232185 | 499998 |
+--------+--------+Wygląda świetnie. Maksymalna wartość kolumny „k” nie przekracza limitu 499 999. Sprawdźmy liczbę wierszy przechowywanych dla tej partycji:
mysql> SELECT TABLE_SCHEMA, TABLE_NAME, PARTITION_NAME, TABLE_ROWS
FROM INFORMATION_SCHEMA.PARTITIONS
WHERE TABLE_SCHEMA='sbtest3'
AND TABLE_NAME='sbtest1';
+--------------+------------+----------------+------------+
| TABLE_SCHEMA | TABLE_NAME | PARTITION_NAME | TABLE_ROWS |
+--------------+------------+----------------+------------+
| sbtest3 | sbtest1 | p1 | 1815 |
+--------------+------------+----------------+------------+Teraz sprawdźmy inny serwer MySQL (mysql2):
mysql> USE sbtest3;
mysql> SELECT min(k), max(k) FROM sbtest1;
+--------+--------+
| min(k) | max(k) |
+--------+--------+
| 500003 | 794952 |
+--------+--------+Sprawdźmy liczbę wierszy przechowywanych dla tej partycji:
mysql> SELECT TABLE_SCHEMA, TABLE_NAME, PARTITION_NAME, TABLE_ROWS
FROM INFORMATION_SCHEMA.PARTITIONS
WHERE TABLE_SCHEMA='sbtest3'
AND TABLE_NAME='sbtest1';
+--------------+------------+----------------+------------+
| TABLE_SCHEMA | TABLE_NAME | PARTITION_NAME | TABLE_ROWS |
+--------------+------------+----------------+------------+
| sbtest3 | sbtest1 | p2 | 3247 |
+--------------+------------+----------------+------------+Wspaniały! Mamy sharded konfiguracji testowej MySQL z odpowiednim partycjonowaniem danych za pomocą Sysbench, z którą możemy się pobawić. Miłego testowania!



