Jako administratorzy i programiści spędzamy dużo czasu w terminalu. Dlatego wprowadziliśmy ClusterControl do terminala za pomocą naszego narzędzia interfejsu wiersza poleceń o nazwie s9s. s9s zapewnia łatwy interfejs do API ClusterControl RPC v2. Przekonasz się, że jest to bardzo przydatne podczas pracy z wdrożeniami na dużą skalę, ponieważ CLI pozwala na projektowanie bardziej złożonych funkcji i przepływów pracy.
Ten wpis na blogu pokazuje, jak używać s9s do automatyzacji zarządzania Galera Cluster for MySQL lub MariaDB, a także prostej konfiguracji replikacji master-slave.
Konfiguracja
Instrukcje instalacji dla konkretnego systemu operacyjnego można znaleźć w dokumentacji. Ważne jest, aby pamiętać, że jeśli zdarzy ci się użyć najnowszych narzędzi s9s z GitHub, nastąpi niewielka zmiana w sposobie tworzenia użytkownika. Następujące polecenie będzie działać poprawnie:
s9s user --create --generate-key --controller="https://localhost:9501" dbaOgólnie rzecz biorąc, wymagane są dwa kroki, jeśli chcesz skonfigurować CLI lokalnie na hoście ClusterControl. Najpierw musisz utworzyć użytkownika, a następnie wprowadzić pewne zmiany w pliku konfiguracyjnym - wszystkie kroki są zawarte w dokumentacji.
Wdrożenie
Po prawidłowym skonfigurowaniu interfejsu CLI i uzyskaniu dostępu SSH do hostów docelowych baz danych można rozpocząć proces wdrażania. W chwili pisania tego tekstu możesz użyć CLI do wdrożenia klastrów MySQL, MariaDB i PostgreSQL. Zacznijmy od przykładu wdrożenia Percona XtraDB Cluster 5.7. Aby to zrobić, wystarczy jedno polecenie.
s9s cluster --create --cluster-type=galera --nodes="10.0.0.226;10.0.0.227;10.0.0.228" --vendor=percona --provider-version=5.7 --db-admin-passwd="pass" --os-user=root --cluster-name="PXC_Cluster_57" --waitOstatnia opcja „--wait” oznacza, że polecenie będzie czekać na zakończenie zadania, pokazując jego postęp. Możesz to pominąć, jeśli chcesz - w takim przypadku polecenie s9s powróci natychmiast do powłoki po zarejestrowaniu nowego zadania w cmonie. Jest to w porządku, ponieważ cmon to proces, który sam obsługuje zadanie. Zawsze możesz sprawdzić postęp pracy osobno, używając:
example@sqldat.com:~# s9s job --list -l
--------------------------------------------------------------------------------------
Create Galera Cluster
Installing MySQL on 10.0.0.226 [██▊ ]
26.09%
Created : 2017-10-05 11:23:00 ID : 1 Status : RUNNING
Started : 2017-10-05 11:23:02 User : dba Host :
Ended : Group: users
--------------------------------------------------------------------------------------
Total: 1Rzućmy okiem na inny przykład. Tym razem stworzymy nowy klaster, replikację MySQL:prosta para master - slave. Ponownie wystarczy jedno polecenie:
example@sqldat.com:~# s9s cluster --create --nodes="10.0.0.229?master;10.0.0.230?slave" --vendor=percona --cluster-type=mysqlreplication --provider-version=5.7 --os-user=root --wait
Create MySQL Replication Cluster
/ Job 6 FINISHED [██████████] 100% Cluster createdMożemy teraz sprawdzić, czy oba klastry są uruchomione i działają:
example@sqldat.com:~# s9s cluster --list --long
ID STATE TYPE OWNER GROUP NAME COMMENT
1 STARTED galera dba users PXC_Cluster_57 All nodes are operational.
2 STARTED replication dba users cluster_2 All nodes are operational.
Total: 2Oczywiście wszystko to jest również widoczne w GUI:
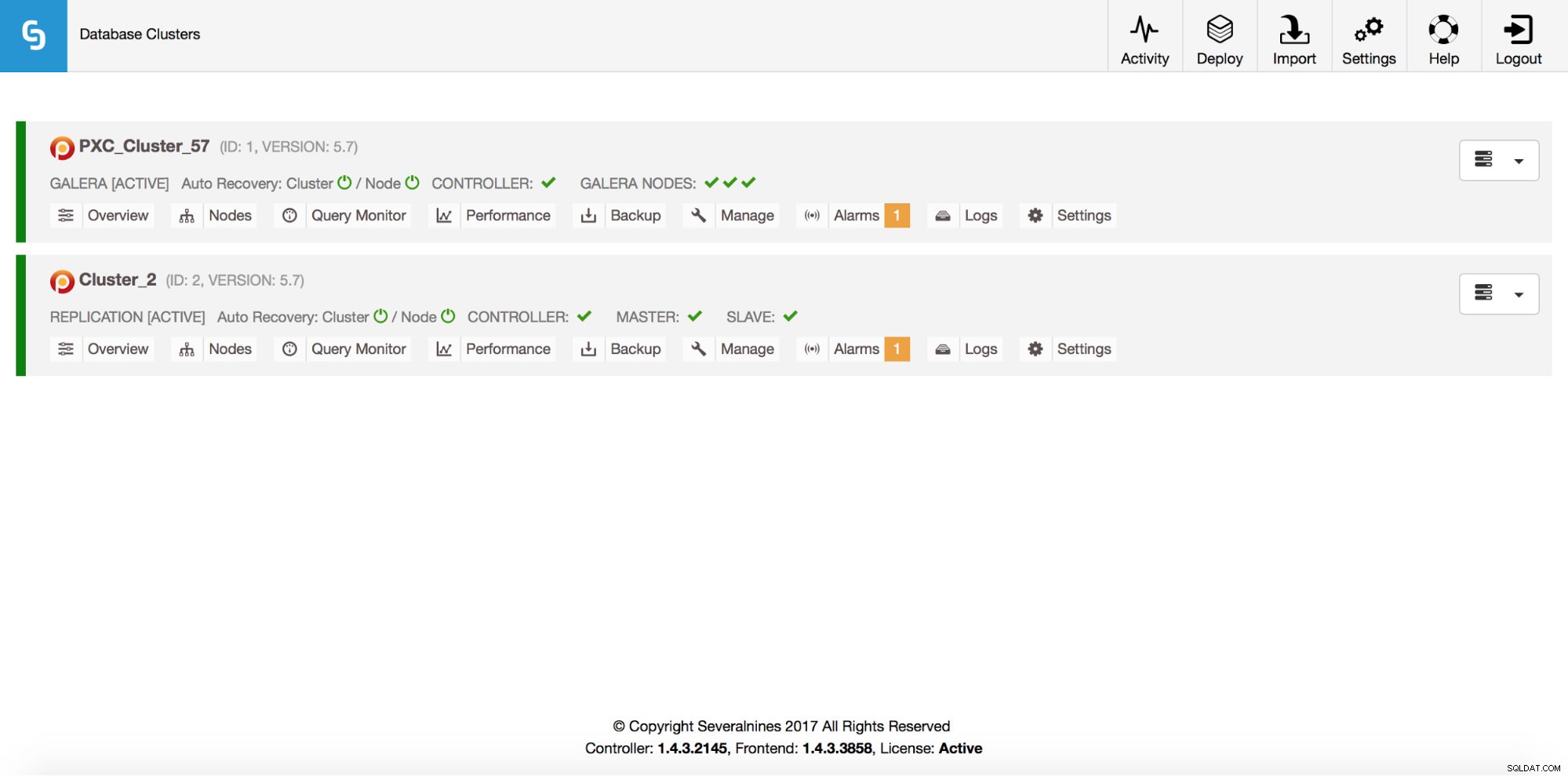
Teraz dodajmy loadbalancer ProxySQL:
example@sqldat.com:~# s9s cluster --add-node --nodes="proxysql://10.0.0.226" --cluster-id=1
WARNING: admin/admin
WARNING: proxy-monitor/proxy-monitor
Job with ID 7 registered.Tym razem nie skorzystaliśmy z opcji „--czekaj”, więc jeśli chcemy sprawdzić postęp, musimy to zrobić samodzielnie. Pamiętaj, że używamy identyfikatora pracy, który został zwrócony przez poprzednie polecenie, więc będziemy uzyskiwać informacje tylko o tym konkretnym zadaniu:
example@sqldat.com:~# s9s job --list --long --job-id=7
--------------------------------------------------------------------------------------
Add ProxySQL to Cluster
Waiting for ProxySQL [██████▋ ]
65.00%
Created : 2017-10-06 14:09:11 ID : 7 Status : RUNNING
Started : 2017-10-06 14:09:12 User : dba Host :
Ended : Group: users
--------------------------------------------------------------------------------------
Total: 7Skalowanie
Węzły można dodawać do naszego klastra Galera za pomocą jednego polecenia:
s9s cluster --add-node --nodes 10.0.0.229 --cluster-id 1
Job with ID 8 registered.
example@sqldat.com:~# s9s job --list --job-id=8
ID CID STATE OWNER GROUP CREATED RDY TITLE
8 1 FAILED dba users 14:15:52 0% Add Node to Cluster
Total: 8Coś poszło nie tak. Możemy sprawdzić, co się dokładnie stało:
example@sqldat.com:~# s9s job --log --job-id=8
addNode: Verifying job parameters.
10.0.0.229:3306: Adding host to cluster.
10.0.0.229:3306: Testing SSH to host.
10.0.0.229:3306: Installing node.
10.0.0.229:3306: Setup new node (installSoftware = true).
10.0.0.229:3306: Detected a running mysqld server. It must be uninstalled first, or you can also add it to ClusterControl.Tak, ten adres IP jest już używany przez nasz serwer replikacji. Powinniśmy użyć innego, darmowego adresu IP. Spróbujmy tego:
example@sqldat.com:~# s9s cluster --add-node --nodes 10.0.0.231 --cluster-id 1
Job with ID 9 registered.
example@sqldat.com:~# s9s job --list --job-id=9
ID CID STATE OWNER GROUP CREATED RDY TITLE
9 1 FINISHED dba users 14:20:08 100% Add Node to Cluster
Total: 9Zarządzanie
Załóżmy, że chcemy wykonać kopię zapasową naszego wzorca replikacji. Możemy to zrobić z GUI, ale czasami możemy potrzebować zintegrować go z zewnętrznymi skryptami. ClusterControl CLI doskonale sprawdzi się w takim przypadku. Sprawdźmy, jakie mamy klastry:
example@sqldat.com:~# s9s cluster --list --long
ID STATE TYPE OWNER GROUP NAME COMMENT
1 STARTED galera dba users PXC_Cluster_57 All nodes are operational.
2 STARTED replication dba users cluster_2 All nodes are operational.
Total: 2Następnie sprawdźmy hosty w naszym klastrze replikacyjnym o identyfikatorze klastra 2:
example@sqldat.com:~# s9s nodes --list --long --cluster-id=2
STAT VERSION CID CLUSTER HOST PORT COMMENT
soM- 5.7.19-17-log 2 cluster_2 10.0.0.229 3306 Up and running
soS- 5.7.19-17-log 2 cluster_2 10.0.0.230 3306 Up and running
coC- 1.4.3.2145 2 cluster_2 10.0.2.15 9500 Up and runningJak widać, są trzy hosty, o których ClusterControl wie - dwa z nich to hosty MySQL (10.0.0.229 i 10.0.0.230), trzeci to instancja ClusterControl. Wydrukujmy tylko odpowiednie hosty MySQL:
example@sqldat.com:~# s9s nodes --list --long --cluster-id=2 10.0.0.2*
STAT VERSION CID CLUSTER HOST PORT COMMENT
soM- 5.7.19-17-log 2 cluster_2 10.0.0.229 3306 Up and running
soS- 5.7.19-17-log 2 cluster_2 10.0.0.230 3306 Up and running
Total: 3W kolumnie „STAT” możesz zobaczyć tam kilka znaków. Aby uzyskać więcej informacji, sugerujemy zajrzeć na stronę podręcznika dla s9s-nodes (man s9s-nodes). Tutaj podsumujemy tylko najważniejsze fragmenty. Pierwszy znak mówi nam o typie węzła:„s” oznacza, że jest to zwykły węzeł MySQL, „c” - kontroler ClusterControl. Drugi znak opisuje stan węzła:„o” mówi nam, że jest online. Trzeci znak - rola węzła. Tutaj „M” opisuje urządzenie nadrzędne, a „S” - urządzenie podrzędne, podczas gdy „C” oznacza kontroler. Ostatni, czwarty znak mówi nam, czy węzeł jest w trybie konserwacji. „-” oznacza, że nie ma zaplanowanej konserwacji. W przeciwnym razie zobaczylibyśmy tutaj „M”. Tak więc z tych danych widzimy, że nasz master jest hostem o IP:10.0.0.229. Zróbmy jego kopię zapasową i zapiszmy na kontrolerze.
example@sqldat.com:~# s9s backup --create --nodes=10.0.0.229 --cluster-id=2 --backup-method=xtrabackupfull --wait
Create Backup
| Job 12 FINISHED [██████████] 100% Command okMożemy wtedy zweryfikować, czy rzeczywiście zakończyło się to dobrze. Zwróć uwagę na opcję „--backup-format”, która pozwala określić, które informacje mają być drukowane:
example@sqldat.com:~# s9s backup --list --full --backup-format="Started: %B Completed: %E Method: %M Stored on: %S Size: %s %F\n" --cluster-id=2
Started: 15:29:11 Completed: 15:29:19 Method: xtrabackupfull Stored on: 10.0.0.229 Size: 543382 backup-full-2017-10-06_152911.xbstream.gz
Total 1Monitorowanie
Wszystkie bazy danych muszą być monitorowane. ClusterControl używa doradców do śledzenia niektórych metryk zarówno w MySQL, jak iw systemie operacyjnym. Gdy warunek jest spełniony, wysyłane jest powiadomienie. ClusterControl zapewnia również obszerny zestaw wykresów, zarówno w czasie rzeczywistym, jak i historycznych do planowania pośmiertnego lub wydajności. Czasami byłoby wspaniale mieć dostęp do niektórych z tych wskaźników bez konieczności przechodzenia przez GUI. ClusterControl CLI umożliwia to za pomocą polecenia s9s-node. Informacje, jak to zrobić, można znaleźć na stronie podręcznika s9s-node. Pokażemy kilka przykładów tego, co możesz zrobić z CLI.
Przede wszystkim przyjrzyjmy się opcji „--node-format” polecenia „węzeł s9s”. Jak widać, istnieje wiele opcji drukowania interesujących treści.
example@sqldat.com:~# s9s node --list --node-format "%N %T %R %c cores %u%% CPU utilization %fmG of free memory, %tMB/s of net TX+RX, %M\n" "10.0.0.2*"
10.0.0.226 galera none 1 cores 13.823200% CPU utilization 0.503227G of free memory, 0.061036MB/s of net TX+RX, Up and running
10.0.0.227 galera none 1 cores 13.033900% CPU utilization 0.543209G of free memory, 0.053596MB/s of net TX+RX, Up and running
10.0.0.228 galera none 1 cores 12.929100% CPU utilization 0.541988G of free memory, 0.052066MB/s of net TX+RX, Up and running
10.0.0.226 proxysql 1 cores 13.823200% CPU utilization 0.503227G of free memory, 0.061036MB/s of net TX+RX, Process 'proxysql' is running.
10.0.0.231 galera none 1 cores 13.104700% CPU utilization 0.544048G of free memory, 0.045713MB/s of net TX+RX, Up and running
10.0.0.229 mysql master 1 cores 11.107300% CPU utilization 0.575871G of free memory, 0.035830MB/s of net TX+RX, Up and running
10.0.0.230 mysql slave 1 cores 9.861590% CPU utilization 0.580315G of free memory, 0.035451MB/s of net TX+RX, Up and runningDzięki temu, co tutaj pokazaliśmy, prawdopodobnie możesz sobie wyobrazić kilka przypadków automatyzacji. Na przykład możesz obserwować wykorzystanie procesora przez węzły, a jeśli osiągnie pewien próg, możesz wykonać kolejne zadanie s9s, aby uruchomić nowy węzeł w klastrze Galera. Możesz także na przykład monitorować wykorzystanie pamięci i wysyłać alerty, jeśli przekroczy pewien próg.
CLI potrafi więcej. Przede wszystkim możliwe jest sprawdzenie wykresów z poziomu wiersza poleceń. Oczywiście nie są one tak bogate w funkcje jak wykresy w GUI, ale czasami wystarczy zobaczyć wykres, aby znaleźć nieoczekiwany wzorzec i zdecydować, czy warto go dokładniej zbadać.
example@sqldat.com:~# s9s node --stat --cluster-id=1 --begin="00:00" --end="14:00" --graph=load 10.0.0.231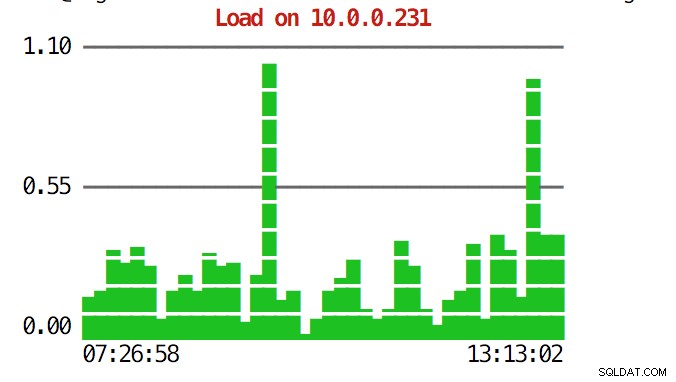
example@sqldat.com:~# s9s node --stat --cluster-id=1 --begin="00:00" --end="14:00" --graph=sqlqueries 10.0.0.231
W sytuacjach awaryjnych warto sprawdzić wykorzystanie zasobów w klastrze. Możesz utworzyć podobny wynik, który łączy dane ze wszystkich węzłów klastra:
example@sqldat.com:~# s9s process --top --cluster-id=1
PXC_Cluster_57 - 14:38:01 All nodes are operational.
4 hosts, 7 cores, 2.2 us, 3.1 sy, 94.7 id, 0.0 wa, 0.0 st,
GiB Mem : 2.9 total, 0.2 free, 0.9 used, 0.2 buffers, 1.6 cached
GiB Swap: 3 total, 0 used, 3 free,
PID USER HOST PR VIRT RES S %CPU %MEM COMMAND
8331 root 10.0.2.15 20 743748 40948 S 10.28 5.40 cmon
26479 root 10.0.0.226 20 278532 6448 S 2.49 0.85 accounts-daemon
5466 root 10.0.0.226 20 95372 7132 R 1.72 0.94 sshd
651 root 10.0.0.227 20 278416 6184 S 1.37 0.82 accounts-daemon
716 root 10.0.0.228 20 278304 6052 S 1.35 0.80 accounts-daemon
22447 n/a 10.0.0.226 20 2744444 148820 S 1.20 19.63 mysqld
975 mysql 10.0.0.228 20 2733624 115212 S 1.18 15.20 mysqld
13691 n/a 10.0.0.227 20 2734104 130568 S 1.11 17.22 mysqld
22994 root 10.0.2.15 20 30400 9312 S 0.93 1.23 s9s
9115 root 10.0.0.227 20 95368 7192 S 0.68 0.95 sshd
23768 root 10.0.0.228 20 95372 7160 S 0.67 0.94 sshd
15690 mysql 10.0.2.15 20 1102012 209056 S 0.67 27.58 mysqld
11471 root 10.0.0.226 20 95372 7392 S 0.17 0.98 sshd
22086 vagrant 10.0.2.15 20 95372 4960 S 0.17 0.65 sshd
7282 root 10.0.0.226 20 0 0 S 0.09 0.00 kworker/u4:2
9003 root 10.0.0.226 20 0 0 S 0.09 0.00 kworker/u4:1
1195 root 10.0.0.227 20 0 0 S 0.09 0.00 kworker/u4:0
27240 root 10.0.0.227 20 0 0 S 0.09 0.00 kworker/1:1
9933 root 10.0.0.227 20 0 0 S 0.09 0.00 kworker/u4:2
16181 root 10.0.0.228 20 0 0 S 0.08 0.00 kworker/u4:1
1744 root 10.0.0.228 20 0 0 S 0.08 0.00 kworker/1:1
28506 root 10.0.0.228 20 95372 7348 S 0.08 0.97 sshd
691 messagebus 10.0.0.228 20 42896 3872 S 0.08 0.51 dbus-daemon
11892 root 10.0.2.15 20 0 0 S 0.08 0.00 kworker/0:2
15609 root 10.0.2.15 20 403548 12908 S 0.08 1.70 apache2
256 root 10.0.2.15 20 0 0 S 0.08 0.00 jbd2/dm-0-8
840 root 10.0.2.15 20 316200 1308 S 0.08 0.17 VBoxService
14694 root 10.0.0.227 20 95368 7200 S 0.00 0.95 sshd
12724 n/a 10.0.0.227 20 4508 1780 S 0.00 0.23 mysqld_safe
10974 root 10.0.0.227 20 95368 7400 S 0.00 0.98 sshd
14712 root 10.0.0.227 20 95368 7384 S 0.00 0.97 sshd
16952 root 10.0.0.227 20 95368 7344 S 0.00 0.97 sshd
17025 root 10.0.0.227 20 95368 7100 S 0.00 0.94 sshd
27075 root 10.0.0.227 20 0 0 S 0.00 0.00 kworker/u4:1
27169 root 10.0.0.227 20 0 0 S 0.00 0.00 kworker/0:0
881 root 10.0.0.227 20 37976 760 S 0.00 0.10 rpc.mountd
100 root 10.0.0.227 0 0 0 S 0.00 0.00 deferwq
102 root 10.0.0.227 0 0 0 S 0.00 0.00 bioset
11876 root 10.0.0.227 20 9588 2572 S 0.00 0.34 bash
11852 root 10.0.0.227 20 95368 7352 S 0.00 0.97 sshd
104 root 10.0.0.227 0 0 0 S 0.00 0.00 kworker/1:1HGdy spojrzysz na górę, zobaczysz statystyki dotyczące procesora i pamięci zagregowane w całym klastrze.
example@sqldat.com:~# s9s process --top --cluster-id=1
PXC_Cluster_57 - 14:38:01 All nodes are operational.
4 hosts, 7 cores, 2.2 us, 3.1 sy, 94.7 id, 0.0 wa, 0.0 st,
GiB Mem : 2.9 total, 0.2 free, 0.9 used, 0.2 buffers, 1.6 cached
GiB Swap: 3 total, 0 used, 3 free,Poniżej znajdziesz listę procesów ze wszystkich węzłów w klastrze.
PID USER HOST PR VIRT RES S %CPU %MEM COMMAND
8331 root 10.0.2.15 20 743748 40948 S 10.28 5.40 cmon
26479 root 10.0.0.226 20 278532 6448 S 2.49 0.85 accounts-daemon
5466 root 10.0.0.226 20 95372 7132 R 1.72 0.94 sshd
651 root 10.0.0.227 20 278416 6184 S 1.37 0.82 accounts-daemon
716 root 10.0.0.228 20 278304 6052 S 1.35 0.80 accounts-daemon
22447 n/a 10.0.0.226 20 2744444 148820 S 1.20 19.63 mysqld
975 mysql 10.0.0.228 20 2733624 115212 S 1.18 15.20 mysqld
13691 n/a 10.0.0.227 20 2734104 130568 S 1.11 17.22 mysqldMoże to być niezwykle przydatne, jeśli chcesz dowiedzieć się, co powoduje obciążenie i który węzeł jest najbardziej dotknięty.
Mamy nadzieję, że narzędzie CLI ułatwi integrację ClusterControl z zewnętrznymi skryptami i narzędziami do aranżacji infrastruktury. Mamy nadzieję, że korzystanie z tego narzędzia przypadnie Ci do gustu i jeśli masz jakieś uwagi na temat tego, jak je ulepszyć, daj nam znać.