Aby wydajnie obsługiwać dowolną bazę danych, musisz mieć wgląd w wydajność bazy danych. Może to nie być oczywiste, gdy wszystko idzie dobrze, ale gdy tylko coś pójdzie nie tak, dostęp do informacji może odegrać kluczową rolę w szybkim i prawidłowym zdiagnozowaniu problemu.
Wszystkie bazy danych udostępniają użytkownikom część swoich wewnętrznych danych o statusie. W MySQL możesz uzyskać te dane głównie uruchamiając 'SHOW STATUS' i 'SHOW GLOBAL STATUS', wykonując 'SHOW ENGINE INNODB STATUS', sprawdzając tabele information_schema i, w nowszych wersjach, odpytując tabele performance_schema.

Metody te nie są wygodne w codziennej pracy, stąd popularność różnych rozwiązań monitorujących i trendujących. Narzędzia takie jak Nagios/Icinga są zaprojektowane do obserwowania hostów/usług i ostrzegania, gdy usługa przekroczy dopuszczalny zakres. Inne narzędzia, takie jak Cacti i Munin, zapewniają graficzne spojrzenie na informacje o hoście/usługach i nadają historyczny kontekst wydajności i wykorzystaniu. ClusterControl łączy te dwa rodzaje monitorowania, więc przyjrzymy się prezentowanym informacjom i temu, jak powinniśmy je interpretować.
Jeśli korzystasz z Galera Cluster (MySQL Galera Cluster by Codership lub MariaDB Cluster lub Percona XtraDB Cluster), być może zauważyłeś następującą sekcję w zakładce „Przegląd” w ClusterControl:
Zobaczmy krok po kroku, jakie mamy tutaj dane.
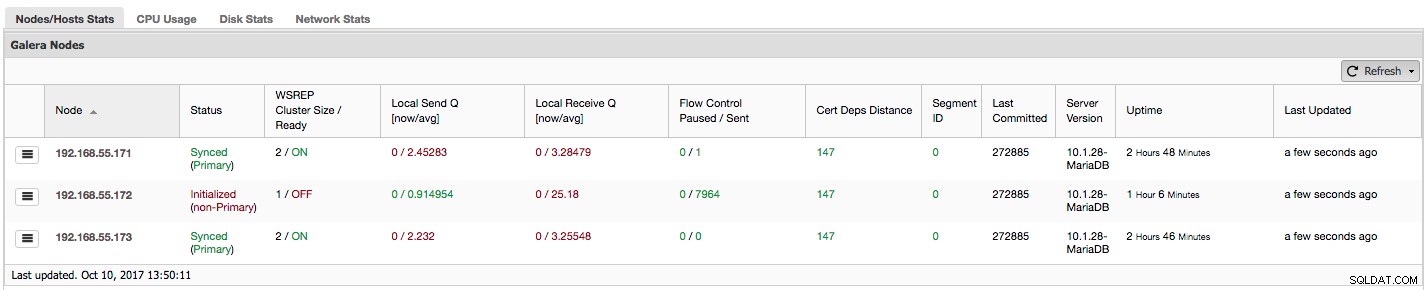
Pierwsza kolumna zawiera listę węzłów z ich adresami IP - niewiele więcej można na ten temat powiedzieć.
Druga kolumna jest bardziej interesująca - opisuje stan węzła (wsrep_local_state_comment status). Węzeł może znajdować się w różnych stanach:
- Zainicjowane — węzeł działa i nie jest częścią klastra. Może to być spowodowane na przykład problemami z siecią;
- Dołączanie — węzeł jest w trakcie dołączania do klastra i odbiera lub żąda przeniesienia stanu z jednego z innych węzłów;
- Donor/Desynced — węzeł służy jako dawca do innego węzła, który dołącza do klastra;
- Połączony — węzeł jest dołączony do klastra, ale jest zajęty nadrabianiem zadeklarowanych zestawów zapisu;
- Zsynchronizowane — węzeł działa normalnie.
W tej samej kolumnie w nawiasie znajduje się stan klastra (wsrep_cluster_status status). Może mieć trzy różne stany:
- Podstawowy — komunikacja między węzłami działa i obecne jest kworum (dostępna jest większość węzłów)
- Niepodstawowy — węzeł był częścią klastra, ale z jakiegoś powodu utracił kontakt z resztą klastra. W rezultacie ten węzeł jest uważany za nieaktywny i nie przyjmuje zapytań
- Rozłączono - węzeł nie mógł nawiązać komunikacji grupowej.
„WSREP Cluster Size / Ready” informuje nas o rozmiarze klastra widzianym przez węzeł oraz o tym, czy węzeł jest gotowy do przyjmowania zapytań. Komponenty inne niż podstawowe tworzą klaster o rozmiarze 1, a gotowość wsrep jest WYŁĄCZONA.
Rzućmy okiem na powyższy zrzut ekranu i zobaczmy, co mówi nam o Galerze. Widzimy trzy węzły. Dwa z nich (192.168.55.171 i 192.168.55.173) są w porządku, oba są „Zsynchronizowane”, a klaster jest w stanie „Podstawowy”. Obecnie klaster składa się z dwóch węzłów. Węzeł 192.168.55.172 jest „Zainicjowany” i tworzy składnik „niepodstawowy”. Oznacza to, że ten węzeł utracił połączenie z klastrem - najprawdopodobniej jakieś problemy z siecią (w rzeczywistości użyliśmy iptables do zablokowania ruchu do tego węzła z adresów 192.168.55.171 i 192.168.55.173).
W tym momencie musimy się trochę zatrzymać i opisać, jak Galera Cluster działa wewnętrznie. Nie będziemy wchodzić w zbyt wiele szczegółów, ponieważ nie jest to objęte zakresem tego wpisu na blogu, ale potrzebna jest pewna wiedza, aby zrozumieć znaczenie danych przedstawionych w następnych kolumnach.
Galera to „wirtualnie” synchroniczny klaster z wieloma wzorcami. Oznacza to, że powinieneś oczekiwać, że dane będą przesyłane „wirtualnie” w tym samym czasie (bez irytujących problemów z opóźnionymi niewolnikami) i że możesz pisać do dowolnego węzła w klastrze (bez irytujących problemów z awansowaniem slave do master ). Aby to osiągnąć, Galera używa writesets — atomowego zestawu zmian, które są replikowane w klastrze. Zbiór zapisów może zawierać kilka zmian wierszy i dodatkowe potrzebne informacje, takie jak dane dotyczące blokowania.
Gdy klient wyda polecenie COMMIT, ale zanim MySQL faktycznie cokolwiek zatwierdzi, tworzony jest zestaw zapisów i wysyłany do wszystkich węzłów w klastrze w celu certyfikacji. Wszystkie węzły sprawdzają, czy można zatwierdzić zmiany, czy nie (ponieważ zmiany mogą kolidować z innymi zapisami wykonywanymi w międzyczasie bezpośrednio na innym węźle). Jeśli tak, dane są faktycznie zatwierdzane przez MySQL, jeśli nie, następuje wycofanie.
Należy pamiętać, że węzły, podobne do slave'ów w normalnej replikacji, mogą działać inaczej - niektóre mogą mieć lepszy sprzęt niż inne, niektóre mogą być bardziej obciążone niż inne. Jednak Galera wymaga od nich przetwarzania zapisów w krótki i szybki sposób, aby zachować „wirtualną” synchronizację. Musi istnieć mechanizm, który może ograniczyć replikację i umożliwić wolniejszym węzłom nadążyć za resztą klastra.
Przyjrzyjmy się kolumnom „Lokalne wysyłanie Q [teraz/śr.]” i „Lokalne odbieranie Q [teraz/śr.]”. Każdy węzeł ma lokalną kolejkę do wysyłania i odbierania zestawów zapisu. Pozwala to na zrównoleglenie niektórych zapisów i kolejkowania danych, które nie mogą być przetworzone na raz, jeśli węzeł nie nadąża za ruchem. W SHOW GLOBAL STATUS możemy znaleźć osiem liczników opisujących obie kolejki, cztery liczniki na kolejkę:
- wsrep_local_send_queue - aktualny stan kolejki wysyłania
- wsrep_local_send_queue_min - minimum od STATUSU PŁUKANIA
- wsrep_local_send_queue_max - maksymalna od STATUSU PŁUKANIA
- wsrep_local_send_queue_avg - średnia od STATUSU FLUSH
- wsrep_local_recv_queue - aktualny stan kolejki odbiorczej
- wsrep_local_recv_queue_min - minimum od STATUSU PŁUKANIA
- wsrep_local_recv_queue_max - maksymalna od STATUSU PŁUKANIA
- wsrep_local_recv_queue_avg - średnia od STATUSU FLUSH
Powyższe metryki są ujednolicone we wszystkich węzłach w ClusterControl -> Wydajność -> Stan bazy danych:
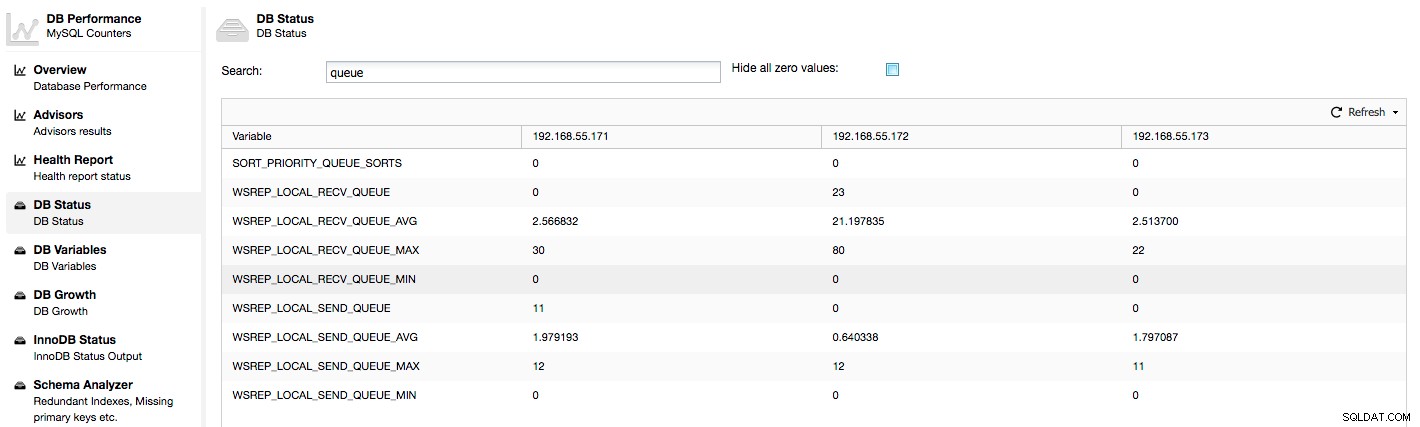
ClusterControl wyświetla liczniki „teraz” i „średnie”, ponieważ mają one największe znaczenie jako pojedyncza liczba (możesz również tworzyć niestandardowe wykresy na podstawie zmiennych opisujących bieżący stan kolejek) . Kiedy widzimy, że jedna z kolejek rośnie, oznacza to, że węzeł nie może nadążyć za replikacją, a inne węzły będą musiały zwolnić, aby umożliwić mu nadrobienie zaległości. Zalecamy zbadanie obciążenia danego węzła - sprawdź listę procesów dla niektórych długo działających zapytań, sprawdź statystyki systemu operacyjnego, takie jak wykorzystanie procesora i obciążenie we/wy. Być może możliwe jest również redystrybucja części ruchu z tego węzła do reszty klastra.
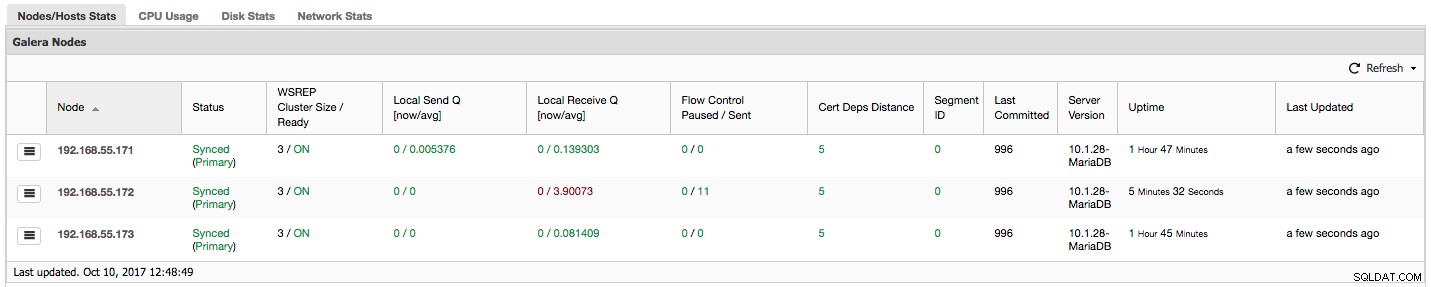
„Kontrola przepływu wstrzymana” pokazuje informacje o procentowym czasie, przez jaki dany węzeł musiał wstrzymać replikację z powodu zbyt dużego obciążenia. Gdy węzeł nie może nadążyć z obciążeniem, wysyła pakiety kontroli przepływu do innych węzłów, informując je, że powinny ograniczyć wysyłanie zestawów zapisu. Na naszym zrzucie ekranu mamy wartość „0,30” dla węzła 192.168.55.172. Oznacza to, że prawie przez 30% czasu ten węzeł musiał wstrzymać replikację, ponieważ nie był w stanie nadążyć za wskaźnikiem certyfikacji zestawu zapisów wymaganym przez inne węzły (lub prościej, trafiło go zbyt wiele zapisów!). Jak widzimy, to „Lokalny odbiór Q [śr.]” wskazuje nam również na ten fakt.
Kolejna kolumna „Flow Control Sent” zawiera informacje o tym, ile pakietów Flow Control dany węzeł wysłał do klastra. Ponownie widzimy, że jest to węzeł 192.168.55.172, który spowalnia klaster.
Co możemy zrobić z tymi informacjami? Przede wszystkim powinniśmy zbadać, co się dzieje w wolnym węźle. Sprawdź wykorzystanie procesora, sprawdź wydajność I/O i statystyki sieci. Ten pierwszy krok pomaga ocenić, z jakim problemem mamy do czynienia.
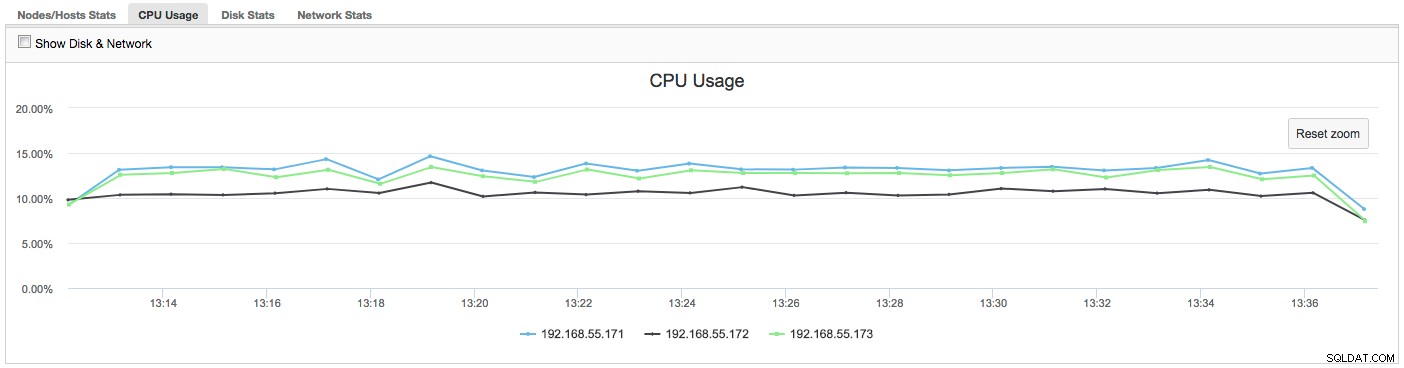
W tym przypadku, po przejściu na kartę Użycie procesora, staje się jasne, że przyczyną naszych problemów jest nadmierne wykorzystanie procesora. Następnym krokiem byłoby zidentyfikowanie winowajcy poprzez zajrzenie do PROCESSLIST (Monitor zapytań -> Uruchamianie zapytań -> filtruj według 192.168.55.172) w celu sprawdzenia obraźliwych zapytań:
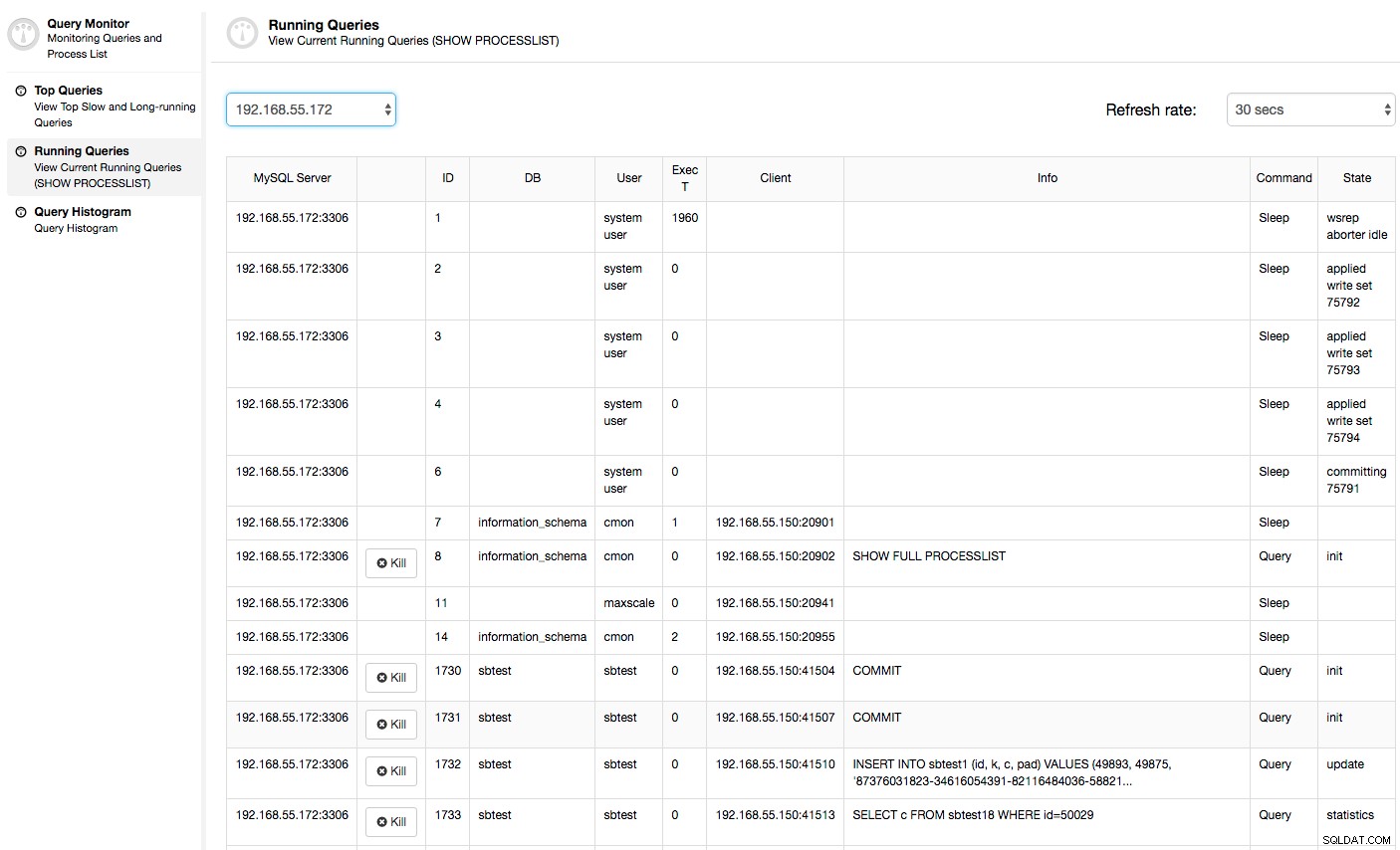
Lub sprawdź procesy w węźle od strony systemu operacyjnego (Węzły -> 192.168.55.172 -> Góra), aby sprawdzić, czy obciążenie nie jest spowodowane przez coś spoza Galera/MySQL.
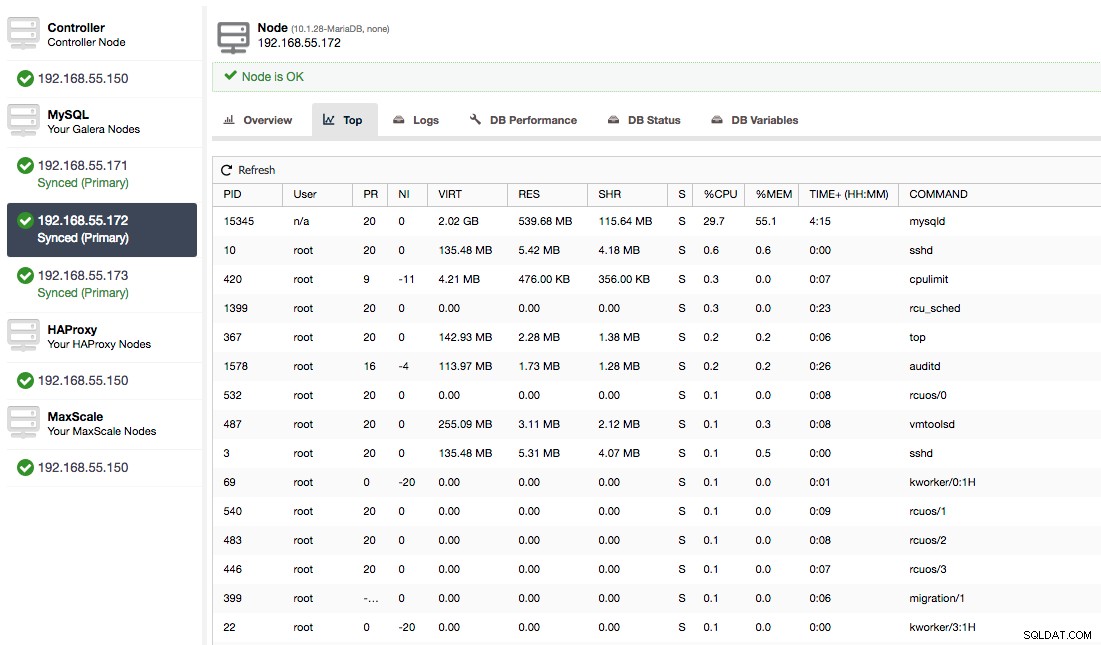
W tym przypadku wykonaliśmy polecenie mysqld przez cpulimit, aby zasymulować wolne użycie procesora specjalnie dla procesu mysqld, ograniczając go do 30% z 400% dostępnego procesora (serwer ma 4 rdzenie).
Kolumna „Cert Deps Distance” podaje nam informację o tym, ile średnio zapisów można zastosować równolegle. Czasami zestawy zapisu mogą być wykonywane w tym samym czasie — Galera wykorzystuje to, używając wielu wsrep_slave_threads stosować zapisy. Ta kolumna daje pewne wyobrażenie, ile wątków podrzędnych możesz użyć w swoim obciążeniu. Warto zauważyć, że nie ma sensu konfigurować wsrep_slave_threads zmienna na wartości wyższe niż widoczne w tej kolumnie lub w wsrep_cert_deps_distance zmienna statusu, na której opiera się kolumna „Cert Deps Distance”. Kolejna ważna uwaga - nie ma sensu ustawiać wsrep_slave_threads zmienna na więcej niż liczbę rdzeni procesora.
„Identyfikator segmentu” — ta kolumna będzie wymagała dodatkowego wyjaśnienia. Segmenty to nowa funkcja dodana w Galera 3.0. Przed tą wersją zestawy zapisu były wymieniane między wszystkimi węzłami. Załóżmy, że mamy dwa centra danych:
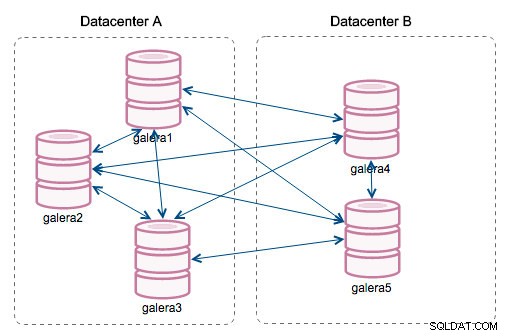
Ten rodzaj gadania działa dobrze w sieciach lokalnych, ale WAN to inna historia - certyfikacja spowalnia ze względu na zwiększone opóźnienia, dodatkowe koszty są generowane z powodu przepustowości sieci używanej do przesyłania zestawów zapisu między każdym członkiem klastra.
Wraz z wprowadzeniem „Segmentów” sytuacja się zmieniła. Możesz przypisać węzeł do segmentu, modyfikując wsrep_provider_options zmienną i dodanie do niej "gmcast.segment=x" (0, 1, 2). Węzły o tym samym numerze segmentu są traktowane tak, jakby znajdowały się w tym samym centrum danych, połączonym siecią lokalną. Nasz wykres staje się wtedy inny:
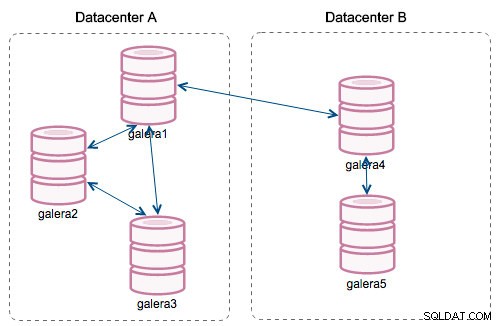
Główna różnica polega na tym, że komunikacja nie dotyczy już wszystkich. W ramach każdego segmentu tak - to wciąż ten sam mechanizm, ale oba segmenty komunikują się tylko za pomocą jednego połączenia między dwoma wybranymi węzłami. W przypadku przestoju połączenie to zostanie automatycznie przełączone w tryb awaryjny. W rezultacie otrzymujemy mniej rozmów w sieci i mniejsze zużycie przepustowości między zdalnymi centrami danych. Tak więc w zasadzie kolumna „Identyfikator segmentu” mówi nam, do którego segmentu przypisany jest węzeł.
Kolumna „Last Committed” dostarcza nam informacji o numerze sekwencyjnym zbioru zapisów, który został ostatnio wykonany na danym węźle. Może to być przydatne przy określaniu, który węzeł jest najbardziej aktualny, jeśli istnieje potrzeba uruchomienia klastra.
Pozostałe kolumny są oczywiste:wersja serwera, czas pracy węzła i data aktualizacji stanu.
Jak widać, sekcja „Galera Nodes” w „Nodes/Hosts Stats” w zakładce „Przegląd” daje całkiem dobre zrozumienie kondycji klastra – czy tworzy on składnik „Podstawowy”, ile węzłów jest sprawnych , czy są jakieś problemy z wydajnością niektórych węzłów, a jeśli tak, który węzeł spowalnia klaster.
Ten zestaw danych jest bardzo przydatny podczas obsługi klastra Galera, więc miejmy nadzieję, że koniec z lataniem na ślepo :-)