Uruchamianie baz danych w infrastrukturze chmurowej staje się w dzisiejszych czasach coraz bardziej popularne. Chociaż maszyna wirtualna w chmurze może nie być tak niezawodna jak serwer klasy korporacyjnej, główni dostawcy usług w chmurze oferują różnorodne narzędzia zwiększające dostępność usług. W tym poście na blogu pokażemy, jak zaprojektować bazę danych MySQL lub MariaDB pod kątem wysokiej dostępności w chmurze. Przyjrzymy się konkretnie Amazon Web Services i Google Cloud Platform, ale większość wskazówek można również wykorzystać w przypadku innych dostawców chmury.
Zarówno AWS, jak i Google oferują usługi baz danych w swoich chmurach, a usługi te można skonfigurować pod kątem wysokiej dostępności. Możliwe jest posiadanie kopii w różnych strefach dostępności (lub strefach w GCP), aby zwiększyć swoje szanse na przetrwanie częściowej awarii usług w regionie. Chociaż usługa hostowana jest bardzo wygodnym sposobem prowadzenia bazy danych, należy pamiętać, że usługa jest zaprojektowana tak, aby zachowywać się w określony sposób i może, ale nie musi, odpowiadać Twoim wymaganiom. Na przykład AWS RDS dla MySQL ma dość ograniczoną listę opcji, jeśli chodzi o obsługę przełączania awaryjnego. Wdrożenia Multi-AZ mają 60-120 sekund czasu przełączania awaryjnego zgodnie z dokumentacją. W rzeczywistości, biorąc pod uwagę, że „cieniowa” instancja MySQL musi zaczynać się od „uszkodzonego” zestawu danych, może to potrwać jeszcze dłużej, ponieważ może być wymagane więcej pracy przy stosowaniu lub wycofywaniu transakcji z dzienników przeróbek InnoDB. Istnieje możliwość wypromowania niewolnika na mistrza, ale nie jest to wykonalne, ponieważ nie można zniewolić istniejących niewolników od nowego pana. W przypadku usługi zarządzanej jest ona również z natury bardziej złożona i trudniej jest śledzić problemy z wydajnością. Więcej informacji na temat RDS dla MySQL i jego ograniczeń znajdziesz w tym poście na blogu.
Z drugiej strony, jeśli zdecydujesz się zarządzać bazami danych, znajdziesz się w innym świecie możliwości. W instancjach EC2 lub Compute Engine jest również możliwe wiele rzeczy, które można zrobić na gołym metalu. Nie masz narzutu związanego z zarządzaniem podstawowym sprzętem, a jednocześnie zachowujesz kontrolę nad architekturą systemu. Podczas projektowania pod kątem dostępności MySQL istnieją dwie główne opcje — replikacja MySQL i klaster Galera. Porozmawiajmy o nich.
Replikacja MySQL
Replikacja MySQL to powszechny sposób skalowania MySQL z wieloma kopiami danych. Asynchroniczny lub półsynchroniczny, pozwala na propagację zmian dokonanych na pojedynczym programie piszącym, masterze, do replik/slave - z których każda zawierałaby pełny zestaw danych i mogłaby zostać awansowana na nowego mastera. Replikacji można również użyć do skalowania odczytów, kierując ruch odczytu do replik i odciążając w ten sposób master. Główną zaletą replikacji jest łatwość użytkowania - jest tak powszechnie znana i popularna (jest również łatwa w konfiguracji), że istnieje wiele zasobów i narzędzi, które pomogą Ci nią zarządzać i konfigurować. Jednym z nich jest nasz własny ClusterControl — możesz go użyć do łatwego wdrożenia konfiguracji replikacji MySQL ze zintegrowanymi modułami równoważenia obciążenia, zarządzania zmianami topologii, przełączania awaryjnego/odzyskiwania i tak dalej.
Jednym z głównych problemów związanych z replikacją MySQL jest to, że nie jest ona zaprojektowana do obsługi podziałów sieci lub awarii mastera. Jeśli mistrz upadnie, musisz wypromować jedną z replik. Jest to proces ręczny, choć można go zautomatyzować za pomocą narzędzi zewnętrznych (np. ClusterControl). Nie ma również mechanizmu kworum i nie ma obsługi odgradzania nieudanych instancji głównych w replikacji MySQL. Niestety, może to prowadzić do poważnych problemów w środowiskach rozproszonych - jeśli promujesz nowego mastera, podczas gdy stary wraca do trybu online, możesz skończyć na zapisie do dwóch węzłów, powodując dryf danych i powodując poważne problemy ze spójnością danych.
W dalszej części tego postu przyjrzymy się kilku przykładom, które pokazują, jak wykrywać podziały sieci i wdrażać STONITH lub inny mechanizm ogrodzeniowy do konfiguracji replikacji MySQL.
Klaster Galera
W poprzedniej sekcji widzieliśmy, że replikacja MySQL nie ma wsparcia dla ogrodzeń i kworum — to miejsce, w którym błyszczy Galera Cluster. Ma wbudowaną obsługę kworum, ma również mechanizm ogrodzenia, który uniemożliwia partycjonowanym węzłom przyjmowanie zapisów. To sprawia, że Galera Cluster jest bardziej odpowiedni niż replikacja w konfiguracjach z wieloma centrami danych. Galera Cluster obsługuje również wiele nagrywarek i jest w stanie rozwiązywać konflikty zapisu. Dlatego nie jesteś ograniczony do jednego programu piszącego w konfiguracji z wieloma centrami danych, możliwe jest posiadanie programu piszącego w każdym centrum danych, co zmniejsza opóźnienie między aplikacją a warstwą bazy danych. Nie przyspiesza to zapisu, ponieważ każdy zapis nadal musi być wysłany do każdego węzła Galera w celu certyfikacji, ale nadal jest to łatwiejsze niż wysyłanie zapisów ze wszystkich serwerów aplikacji przez sieć WAN do jednego zdalnego mastera.
Choć Galera jest dobra, nie zawsze jest najlepszym wyborem dla wszystkich obciążeń. Galera nie jest zamiennikiem typu drop-in dla MySQL/InnoDB. Ma wspólne funkcje z „normalnym” MySQL – wykorzystuje InnoDB jako silnik pamięci, zawiera cały zestaw danych w każdym węźle, co umożliwia JOIN. Mimo to niektóre cechy wydajności Galera (takie jak wydajność zapisów, na które ma wpływ opóźnienie sieci) różnią się od tego, czego można oczekiwać od konfiguracji replikacji. Utrzymanie też wygląda inaczej:obsługa zmian schematu działa nieco inaczej. Niektóre projekty schematów nie są optymalne:jeśli w tabelach znajdują się punkty aktywne, takie jak często aktualizowane liczniki, może to prowadzić do problemów z wydajnością. Istnieje również różnica w najlepszych praktykach związanych z przetwarzaniem wsadowym — zamiast wykonywać zapytania w dużych transakcjach, chcesz, aby Twoje transakcje były małe.
Poziom proxy
Zbudowanie wysoce dostępnej konfiguracji bez serwerów proxy jest bardzo trudne i kłopotliwe. Oczywiście, możesz napisać kod w swojej aplikacji, aby śledzić instancje bazy danych, umieszczać na czarnej liście te niezdrowe, śledzić zapisywalne wzorce i tak dalej. Ale jest to o wiele bardziej złożone niż wysyłanie ruchu do pojedynczego punktu końcowego — czyli tam, gdzie wkracza serwer proxy. ClusterControl umożliwia wdrożenie ProxySQL, HAProxy i MaxScale. Podamy kilka przykładów użycia ProxySQL, ponieważ daje nam to dużą elastyczność w kontrolowaniu ruchu w bazie danych.
ProxySQL można wdrożyć na kilka sposobów. Na początek można go wdrożyć na osobnych hostach, a Keepalived może służyć do zapewnienia wirtualnego adresu IP. Wirtualny adres IP zostanie przeniesiony w przypadku awarii jednej z instancji ProxySQL. W chmurze taka konfiguracja może być problematyczna, ponieważ dodanie adresu IP do interfejsu zwykle nie wystarcza. Będziesz musiał zmodyfikować konfigurację Keepalived i skrypty, aby działały z elastycznym adresem IP (lub statycznym - jednak może to być wywołane przez dostawcę chmury). Następnie można użyć Cloud API lub CLI, aby przenieść ten adres IP na inny host. Z tego powodu sugerujemy kolokację ProxySQL z aplikacją. Każdy serwer aplikacji byłby skonfigurowany do łączenia się z lokalnym serwerem ProxySQL za pomocą gniazd Unix. Ponieważ ProxySQL wykorzystuje proces anioła, awarie ProxySQL można wykryć/zrestartować w ciągu sekundy. W przypadku awarii sprzętu, ten konkretny serwer aplikacji ulegnie awarii wraz z ProxySQL. Pozostałe serwery aplikacji mogą nadal uzyskiwać dostęp do swoich odpowiednich lokalnych instancji ProxySQL. Ta konkretna konfiguracja ma dodatkowe funkcje. Bezpieczeństwo — ProxySQL od wersji 1.4.8 nie obsługuje SSL po stronie klienta. Może tylko skonfigurować połączenie SSL między ProxySQL a backendem. Kolokacja ProxySQL na hoście aplikacji i używanie gniazd Unix jest dobrym obejściem. ProxySQL ma również możliwość buforowania zapytań i jeśli zamierzasz korzystać z tej funkcji, warto trzymać go jak najbliżej aplikacji, aby zmniejszyć opóźnienia. Sugerujemy użycie tego wzorca do wdrożenia ProxySQL.
Typowe konfiguracje
Rzućmy okiem na przykłady wysoce dostępnych konfiguracji.
Pojedyncze centrum danych, replikacja MySQL
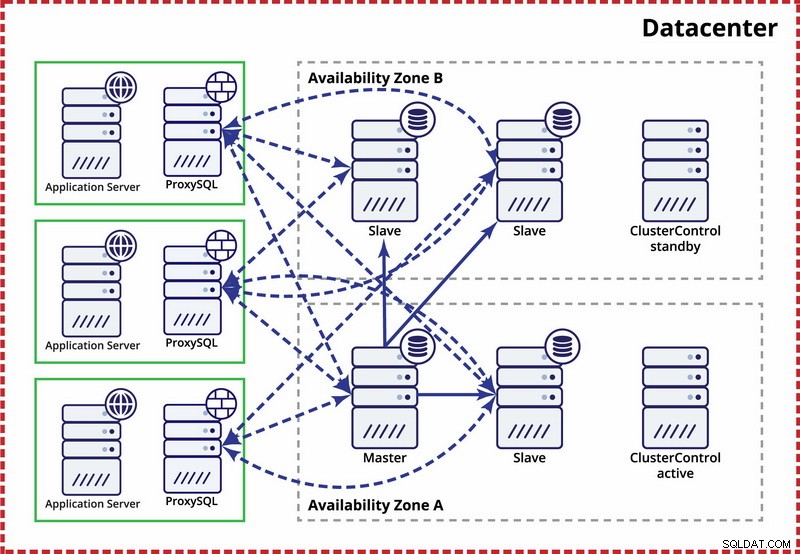
Zakłada się tutaj, że w centrum danych istnieją dwie oddzielne strefy. Każda strefa ma nadmiarowe i oddzielne zasilanie, sieć i łączność, aby zmniejszyć prawdopodobieństwo jednoczesnej awarii dwóch stref. Możliwe jest ustawienie topologii replikacji obejmującej obie strefy.
Tutaj używamy ClusterControl do zarządzania przełączaniem awaryjnym. Aby rozwiązać scenariusz podziału mózgu między strefami dostępności, łączymy aktywny ClusterControl z masterem. Umieszczamy również na czarnej liście urządzenia podrzędne w drugiej strefie dostępności, aby upewnić się, że automatyczne przełączanie awaryjne nie spowoduje udostępnienia dwóch urządzeń głównych.
Wiele centrów danych, replikacja MySQL
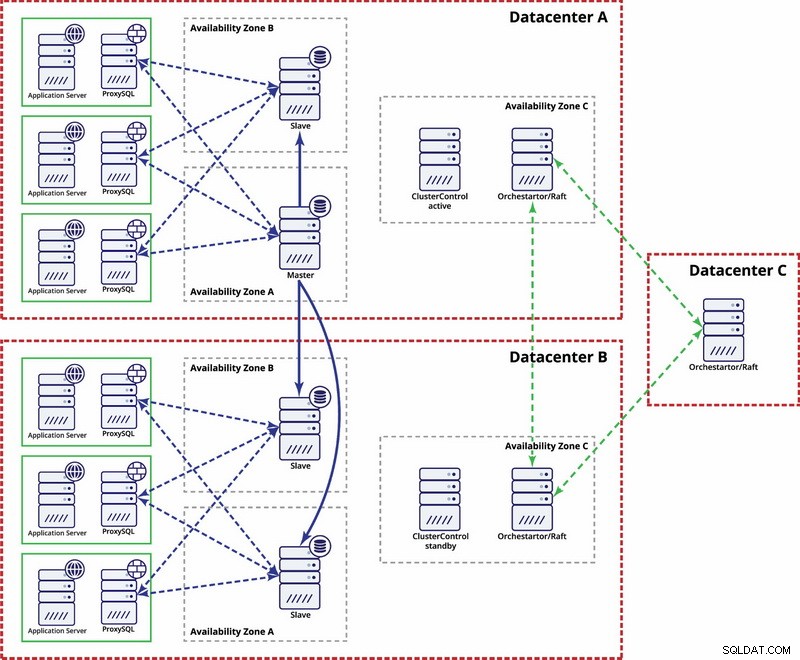
W tym przykładzie do obliczenia kworum używamy trzech centrów danych i programu Orchestrator/Raft. Może być konieczne napisanie własnych skryptów implementujących STONITH, jeśli master znajduje się w podzielonym na partycje segmencie infrastruktury. ClusterControl służy do odzyskiwania i zarządzania węzłami.
Wiele centrów danych, klaster Galera
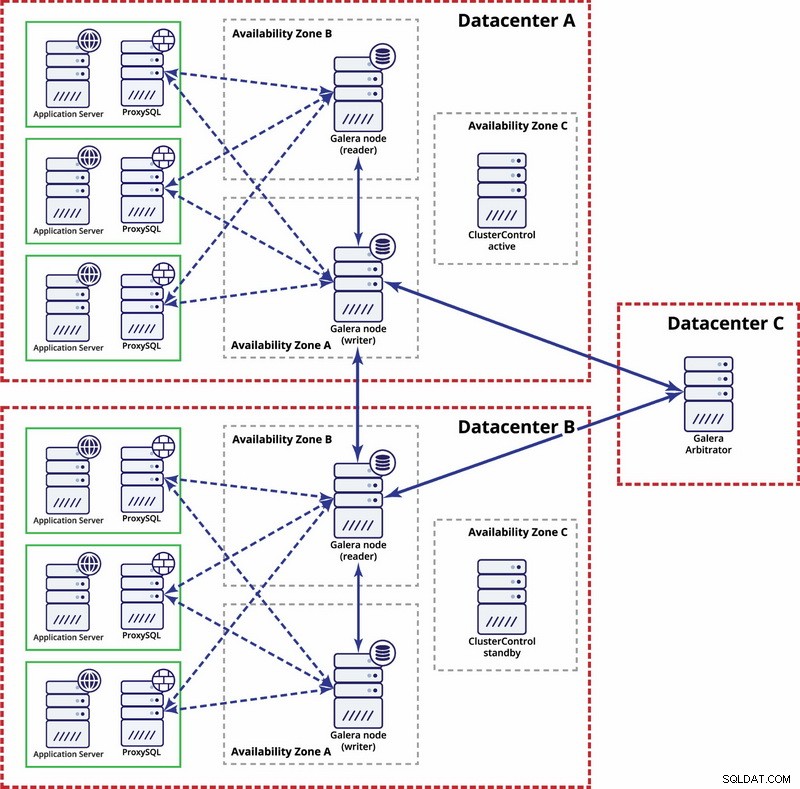
W tym przypadku używamy trzech centrów danych z arbitrem Galera w trzecim - umożliwia to obsługę awarii całego centrum danych i zmniejsza ryzyko partycjonowania sieci, ponieważ trzecie centrum danych może być używane jako przekaźnik.
Aby dowiedzieć się więcej, zapoznaj się z dokumentem „Jak projektować wysoce dostępne środowiska baz danych typu open source” i obejrzyj powtórkę z seminarium internetowego „Projektowanie baz danych typu open source pod kątem wysokiej dostępności”.