@rob_farley Twoje ostatnie rozwiązanie przepełnienia stosu do zamawiania według wartości, a następnie pole jest geniusz! Chciałem osobiście podziękować.
— Joel Sacco (@Jsac90) 11 sierpnia 2016
Widziałem ten tweet…
I skłoniło mnie to do spojrzenia na to, do czego się odnosi, ponieważ nie napisałem nic „ostatnio” na StackOverflow o zamawianiu danych. Okazuje się, że to była ta odpowiedź, którą napisałem , który choć nie był akceptowaną odpowiedzią, zebrał ponad sto głosów.
Osoba zadająca pytanie miała bardzo prosty problem – chęć, aby określone wiersze pojawiły się jako pierwsze. A moje rozwiązanie było proste:
ORDER BY CASE WHEN city = 'New York' THEN 1 ELSE 2 END, City;
Wydaje się, że była to popularna odpowiedź, w tym dla Joela Sacco (zgodnie z powyższym tweetem).
Chodzi o to, by stworzyć wyraz, a przez to uporządkować. ORDER BY nie dba o to, czy jest to rzeczywista kolumna, czy nie. Możesz zrobić to samo, używając APPLY, jeśli naprawdę wolisz używać „kolumny” w klauzuli ORDER BY.
SELECT Users.* FROM Users CROSS APPLY ( SELECT CASE WHEN City = 'New York' THEN 1 ELSE 2 END AS OrderingCol ) o ORDER BY o.OrderingCol, City;
Jeśli użyję kilku zapytań przeciwko WideWorldImporters, mogę pokazać, dlaczego te dwa zapytania naprawdę są dokładnie takie same. Zamierzam przeszukać tabelę Sales.Orders, prosząc, aby jako pierwsze pojawiła się pozycja Orders for Salesperson 7. Zamierzam również stworzyć odpowiedni indeks pokrycia:
CREATE INDEX rf_Orders_SalesPeople_OrderDate ON Sales.Orders(SalespersonPersonID) INCLUDE (OrderDate);
Plany dla tych dwóch zapytań wyglądają identycznie. Wykonują identycznie – te same odczyty, te same wyrażenia, to tak naprawdę to samo zapytanie. Jeśli istnieje niewielka różnica w rzeczywistym procesorze lub czasie trwania, to jest to przypadek z powodu innych czynników.
SELECT OrderID, SalespersonPersonID, OrderDate FROM Sales.Orders ORDER BY CASE WHEN SalespersonPersonID = 7 THEN 1 ELSE 2 END, SalespersonPersonID; SELECT OrderID, SalespersonPersonID, OrderDate FROM Sales.Orders CROSS APPLY ( SELECT CASE WHEN SalespersonPersonID = 7 THEN 1 ELSE 2 END AS OrderingCol ) o ORDER BY o.OrderingCol, SalespersonPersonID;
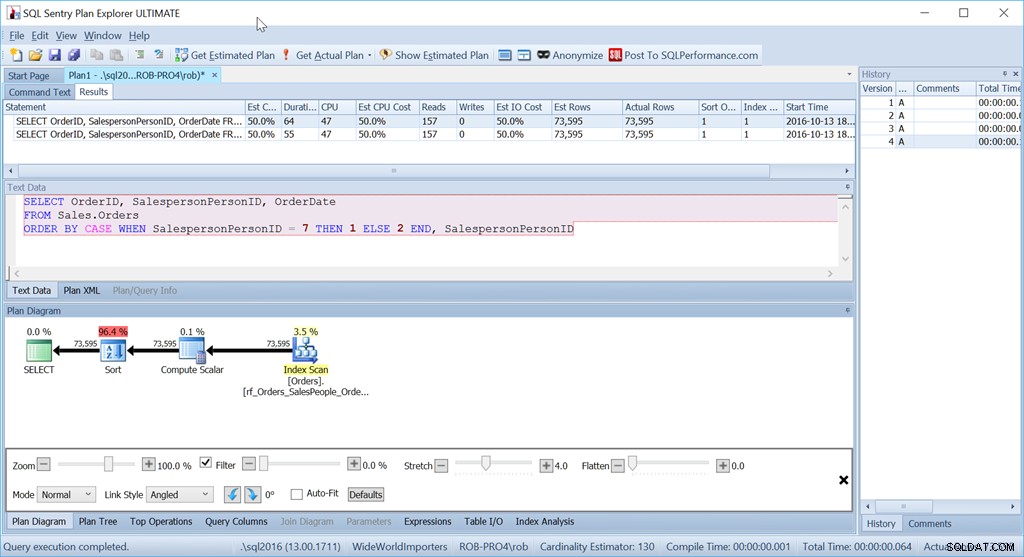
A jednak nie jest to zapytanie, którego użyłbym w tej sytuacji. Nie, jeśli wydajność była dla mnie ważna. (Zazwyczaj tak jest, ale nie zawsze warto pisać zapytanie na dłuższą metę, jeśli ilość danych jest niewielka).
Martwi mnie ten operator sortowania. To 96,4% kosztów!
Zastanów się, czy chcemy po prostu zamówić przez SalespersonPersonID:
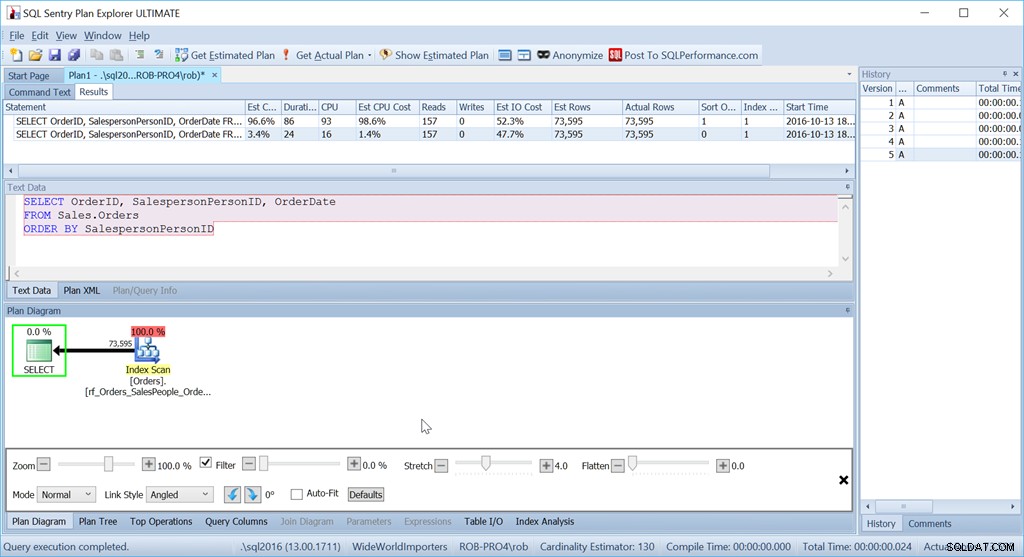
Widzimy, że szacowany koszt procesora w tym prostszym zapytaniu wynosi 1,4% partii, podczas gdy w przypadku wersji posortowanej na zamówienie wynosi 98,6%. To SIEDEMDZIEŚCIE RAZY gorsze. Odczyty są jednak takie same – to dobrze. Czas trwania jest znacznie gorszy, podobnie jak procesor.
Nie przepadam za sortowaniem. Mogą być paskudne.
Jedną z opcji, którą mam tutaj, jest dodanie kolumny obliczeniowej do mojej tabeli i jej zindeksowanie, ale będzie to miało wpływ na wszystko, co szuka wszystkich kolumn w tabeli, takie jak ORM, Power BI lub wszystko, co powoduje SELECT * . Więc to nie jest takie wspaniałe (chociaż jeśli kiedykolwiek dodamy ukryte kolumny obliczeniowe, będzie to naprawdę fajna opcja tutaj).
Inną opcją, która jest bardziej rozwlekła (niektórzy mogą zasugerować, że mi to odpowiada – a jeśli myślisz, że:Oi! Nie bądź taki niegrzeczny!) i używa więcej czytań, jest rozważenie, co byśmy zrobili w prawdziwym życiu, gdyby musieliśmy to zrobić.
Gdybym miał stos 73 595 zamówień posortowanych według zamówienia Sprzedawcy i musiałbym je najpierw zwrócić z określonym Sprzedawcą, nie zlekceważyłbym kolejności, w jakiej się znajdowały i po prostu posortowałby je wszystkie, zacząłbym od zagłębienia się i znajdowanie tych dla Sprzedawcy 7 – utrzymywanie ich w kolejności, w jakiej się znajdowały. Następnie znajdowałem te, które nie były tymi, które nie były Sprzedawcą 7 – umieszczanie ich dalej i znowu utrzymywanie ich w kolejności, w jakiej już były w.
W T-SQL robi się to tak:
SELECT OrderID, SalespersonPersonID, OrderDate
FROM
(
SELECT OrderID, SalespersonPersonID, OrderDate,
1 AS OrderingCol
FROM Sales.Orders
WHERE SalespersonPersonID = 7
UNION ALL
SELECT OrderID, SalespersonPersonID, OrderDate,
2 AS OrderingCol
FROM Sales.Orders
WHERE SalespersonPersonID != 7
) o
ORDER BY o.OrderingCol, o.SalespersonPersonID; To pobiera dwa zestawy danych i łączy je. Jednak Optymalizator zapytań widzi, że musi zachować kolejność SalespersonPersonID po połączeniu tych dwóch zestawów, więc wykonuje specjalny rodzaj łączenia, który utrzymuje tę kolejność. Jest to połączenie scalające (konkatenacja), a plan wygląda tak:
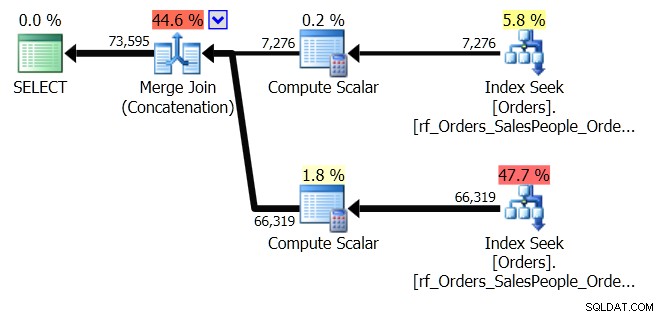
Widać, że to dużo bardziej skomplikowane. Ale miejmy nadzieję, że zauważysz również, że nie ma operatora sortowania. Połączenie scalające (konkatenacja) pobiera dane z każdej gałęzi i tworzy zestaw danych we właściwej kolejności. W tym przypadku najpierw pobierze wszystkie 7276 wierszy dla Sprzedawcy 7, a następnie pozostałych 66 319, ponieważ jest to wymagane zamówienie. W każdym zestawie dane znajdują się w kolejności SalespersonPersonID, która jest utrzymywana w miarę przepływu danych.
Wspomniałem wcześniej, że używa więcej odczytów i tak się dzieje. Jeśli pokazuję wyjście SET STATISTICS IO, porównując oba zapytania, widzę to:
Stół „Stół roboczy”. Liczba skanów 0, odczyty logiczne 0, odczyty fizyczne 0, odczyty z wyprzedzeniem 0, odczyty logiczne lobu 0, odczyty fizyczne lobu 0, odczyty loba z wyprzedzeniem 0.Tabela „Zamówienia”. Liczba skanów 1, odczyty logiczne 157, odczyty fizyczne 0, odczyty z wyprzedzeniem 0, odczyty logiczne lobu 0, odczyty fizyczne lobu 0, odczyty z wyprzedzeniem lobu 0.
Tabela 'Zamówienia „. Liczba skanów 3, odczyty logiczne 163, odczyty fizyczne 0, odczyty z wyprzedzeniem 0, odczyty logiczne LOB 0, odczyty fizyczne LOB 0, odczyty LOB z wyprzedzeniem 0.
Korzystając z wersji „Sortowanie niestandardowe”, to tylko jeden skan indeksu, wykorzystujący 157 odczytów. Używając metody „Union All”, to trzy skany – jeden dla SalespersonPersonID =7, jeden dla SalespersonPersonID <7 i jeden dla SalespersonPersonID> 7. Te dwa ostatnie możemy zobaczyć, patrząc na właściwości drugiego wyszukiwania indeksu:
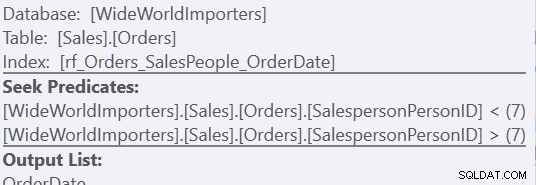
Dla mnie jednak korzyść wynika z braku stołu roboczego.
Spójrz na szacunkowy koszt procesora:

Nie jest tak mały jak nasze 1,4%, gdy całkowicie unikamy sortowania, ale nadal jest to ogromna poprawa w stosunku do naszej metody sortowania niestandardowego.
Ale słowo ostrzeżenia…
Załóżmy, że utworzyłem ten indeks w inny sposób i miałem OrderDate jako kolumnę kluczową, a nie jako kolumnę dołączoną.
CREATE INDEX rf_Orders_SalesPeople_OrderDate ON Sales.Orders(SalespersonPersonID, OrderDate);
Teraz moja metoda „Union All” w ogóle nie działa zgodnie z przeznaczeniem.
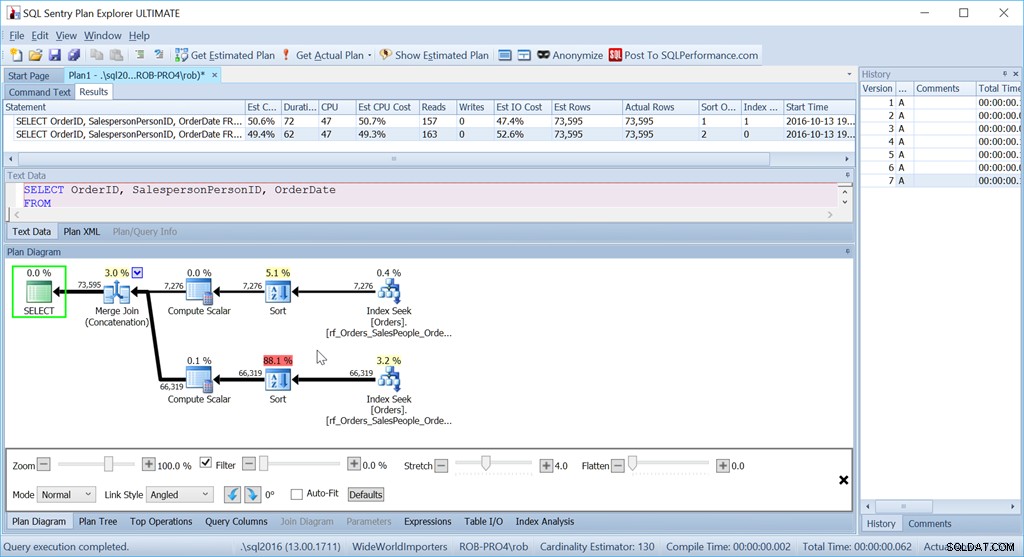
Pomimo używania dokładnie tych samych zapytań co wcześniej, mój fajny plan ma teraz dwa operatory sortowania i działa prawie tak samo źle, jak moja oryginalna wersja Skanuj + Sortuj.
Powodem tego jest dziwactwo operatora łączenia łączenia (konkatenacji), a wskazówka znajduje się w operatorze sortowania.

Jest uporządkowany według SalespersonPersonID, a następnie OrderID — który jest kluczem indeksu klastrowego tabeli. Wybiera to, ponieważ wiadomo, że jest to unikatowe i jest to mniejszy zestaw kolumn do sortowania niż SalespersonPersonID, po którym następuje OrderDate, po którym następuje OrderID, który jest kolejnością zestawu danych utworzoną przez trzy skanowania zakresów indeksów. Jeden z tych przypadków, w których Optymalizator zapytań nie zauważa lepszej opcji, która jest właśnie tam.
W przypadku tego indeksu potrzebowalibyśmy również naszego zestawu danych uporządkowanego według daty zamówienia, aby stworzyć nasz preferowany plan.
SELECT OrderID, SalespersonPersonID, OrderDate
FROM
(
SELECT OrderID, SalespersonPersonID, OrderDate,
1 AS OrderingCol
FROM Sales.Orders
WHERE SalespersonPersonID = 7
UNION ALL
SELECT OrderID, SalespersonPersonID, OrderDate,
2 AS OrderingCol
FROM Sales.Orders
WHERE SalespersonPersonID != 7
) o
ORDER BY o.OrderingCol, o.SalespersonPersonID, OrderDate;
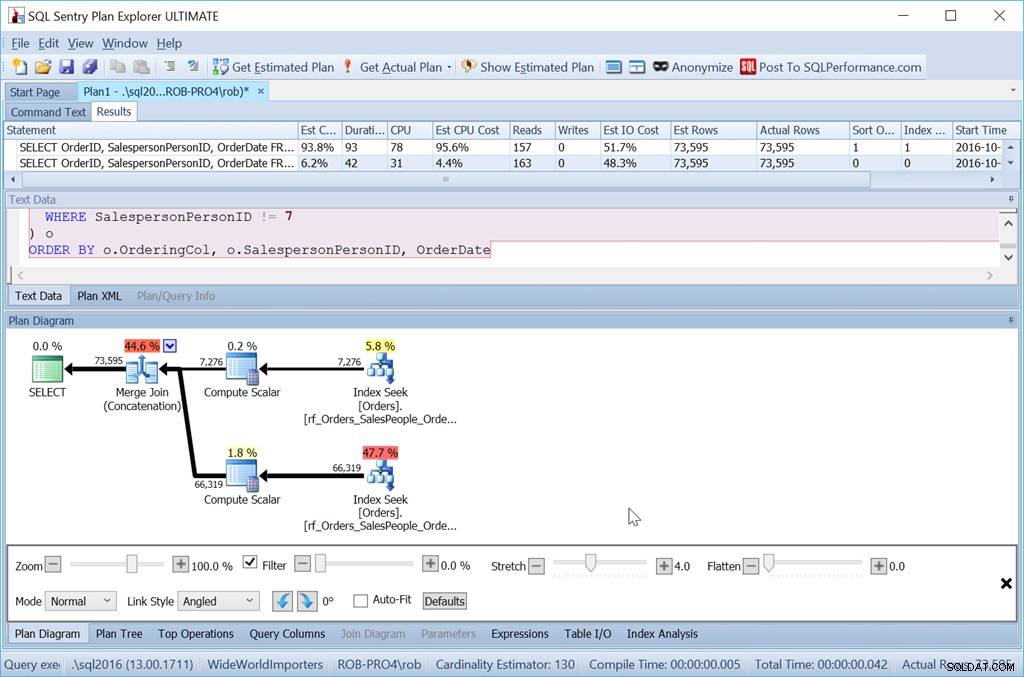
Więc to zdecydowanie więcej wysiłku. Zapytanie jest dla mnie dłuższe, jest więcej odczytów i muszę mieć indeks bez dodatkowych kolumn kluczowych. Ale na pewno szybciej. Przy jeszcze większej liczbie wierszy wpływ jest jeszcze większy i nie muszę też ryzykować, że Sort rozleje się do tempdb.
W przypadku małych zestawów moja odpowiedź na StackOverflow jest nadal dobra. Ale kiedy ten operator sortowania kosztuje mnie wydajność, używam metody Union All / Merge Join (Concatenation).