Otrzymujemy kilka miłych opinii na temat naszego produktu ClusterControl, a zwłaszcza jego łatwości instalacji i uruchomienia. Instalowanie nowego oprogramowania to jedno, ale prawidłowe używanie to drugie.
Nie jest niczym niezwykłym niecierpliwość do testowania nowego oprogramowania i wolimy bawić się nową ekscytującą aplikacją niż czytać dokumentację przed rozpoczęciem. To trochę niefortunne, ponieważ możesz przegapić ważne funkcje lub nie zrozumieć, jak z nich korzystać.
Ta seria blogów obejmuje wszystkie podstawowe operacje ClusterControl for MySQL, MongoDB i PostgreSQL wraz z przykładami, jak najlepiej wykorzystać konfigurację. Zapewnia głębokie zagłębienie się w różne tematy, aby zaoszczędzić czas.
Oto tematy poruszane w tej serii:
- Wdrażanie pierwszych klastrów
- Dodawanie istniejącej infrastruktury
- Monitorowanie wydajności i kondycji
- Tworzenie komponentów HA
- Zarządzanie przepływem pracy
- Ochrona Twoich danych
- Ochrona Twoich danych
- Dogłębny przypadek użycia
W dzisiejszym poście omówimy instalowanie ClusterControl i wdrażanie pierwszych klastrów.
Przygotowania
W tej serii wykorzystamy zestaw pudełek Vagrant, ale jeśli chcesz, możesz skorzystać z własnej infrastruktury. Jeśli chcesz przetestować go z Vagrantem, udostępniliśmy przykładową konfigurację z następującego repozytorium Github:https://github.com/severalnines/vagrant
Sklonuj repozytorium na własną maszynę:
$ git clone example@sqldat.com:severalnines/vagrant.gitTopologia wędrujących węzłów jest następująca:
- vm1:kontrola klastra
- vm2:węzeł bazy danych1
- vm3:węzeł bazy danych 2
- vm4:węzeł bazy danych 3
Możesz łatwo dodać dodatkowe węzły, jeśli chcesz, zmieniając następujący wiersz:
4.times do |n|Plik Vagrant jest skonfigurowany do automatycznego instalowania ClusterControl na pierwszym węźle i przekazywania interfejsu użytkownika ClusterControl do portu 8080 na hoście, na którym działa Vagrant. Jeśli więc adres IP twojego hosta to 192.168.1.10, interfejs ClusterControl znajdziesz tutaj:https://192.168.1.10:8080/clustercontrol/
Instalowanie ClusterControl
Możesz to pominąć, jeśli zdecydujesz się użyć pliku Vagrant i uzyskać automatyczną instalację. Ale instalacja ClusterControl jest prosta i zajmie mniej niż pięć minut.
Podczas instalacji pakietu wystarczy wydać następujące trzy polecenia w węźle ClusterControl, aby go zainstalować:
$ wget https://www.severalnines.com/downloads/cmon/install-cc
$ chmod +x install-cc
$ ./install-cc # as root or sudo userTo wszystko:nie może być prostsze. Jeśli skrypt instalacyjny nie napotkał żadnych problemów, ClusterControl powinien być zainstalowany i uruchomiony. Możesz teraz zalogować się do ClusterControl pod następującym adresem URL:https://192.168.1.210/clustercontrol
Po utworzeniu konta administratora i zalogowaniu się zostaniesz poproszony o dodanie pierwszego klastra.
Wdróż klaster Galera
Zostaniesz poproszony o utworzenie nowego serwera/klastra bazy danych lub zaimportowanie istniejącego (tj. już wdrożonego) serwera lub klastra:
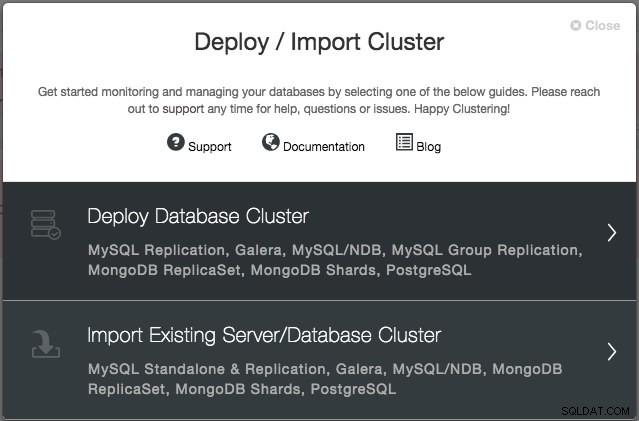
Zamierzamy wdrożyć klaster Galera. Należy wypełnić dwie sekcje. Pierwsza zakładka dotyczy SSH i ustawień ogólnych:
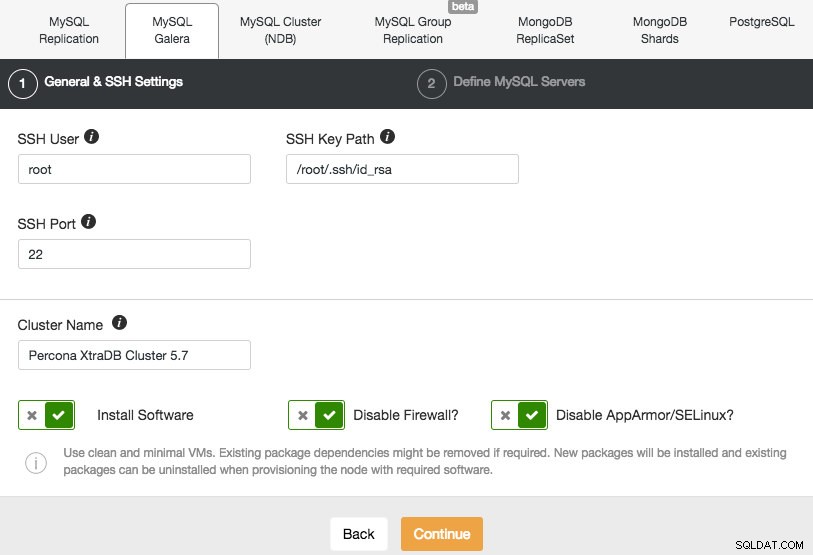
Aby umożliwić ClusterControl instalowanie węzłów Galera, używamy użytkownika root, któremu przyznano dostęp SSH przez skrypty ładowania początkowego Vagrant. Jeśli zdecydujesz się na użycie własnej infrastruktury, musisz wprowadzić tutaj użytkownika, który może wykonywać bezhasłowe SSH do węzłów, które będzie kontrolować ClusterControl. Pamiętaj tylko, że musisz wcześniej samodzielnie skonfigurować bezhasłowe SSH z ClusterControl do wszystkich węzłów bazy danych.
Upewnij się również, że wyłączyłeś AppArmor/SELinux. Zobacz, dlaczego.
Następnie przejdź do drugiego etapu i określ informacje związane z bazą danych oraz hosty docelowe:
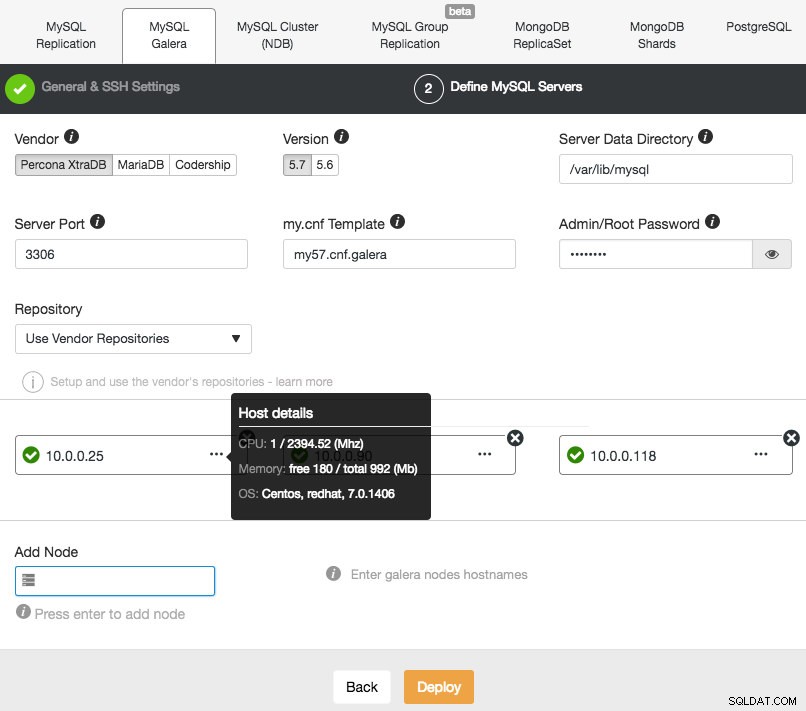
ClusterControl natychmiast wykona pewne testy poprawności za każdym razem, gdy naciśniesz klawisz Enter podczas dodawania węzła. Możesz zobaczyć podsumowanie hosta, najeżdżając kursorem na każdy zdefiniowany węzeł. Gdy wszystko jest zielone, oznacza to, że ClusterControl ma łączność ze wszystkimi węzłami, możesz kliknąć Wdróż. Zostanie utworzone zadanie do zbudowania nowego klastra. Fajną rzeczą jest to, że możesz śledzić postęp tego zadania, klikając Aktywność -> Zadania -> Utwórz klaster -> Pełne szczegóły zadania :
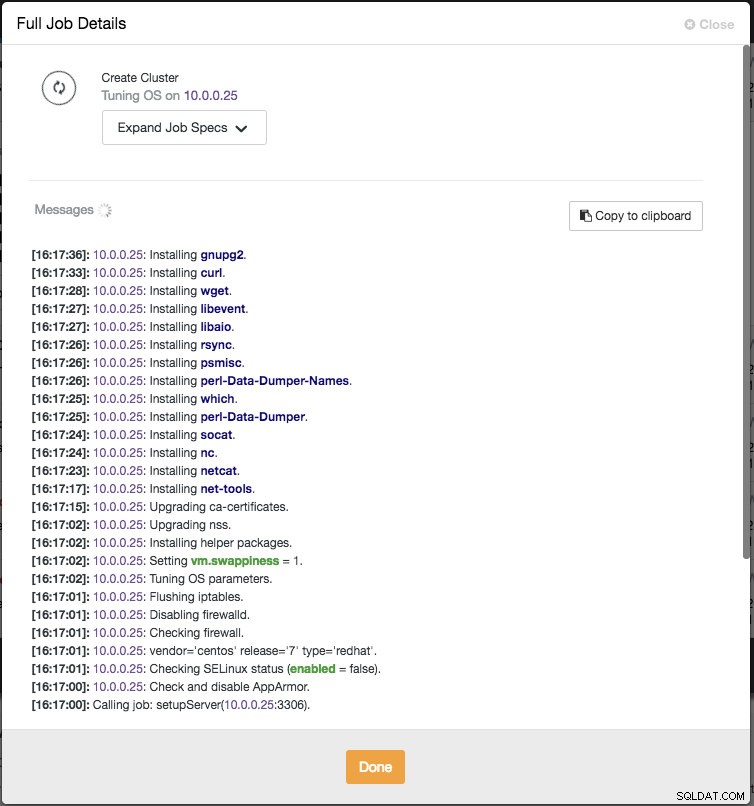
Po zakończeniu zadania właśnie utworzyłeś swój pierwszy klaster. Przegląd klastra powinien wyglądać tak:
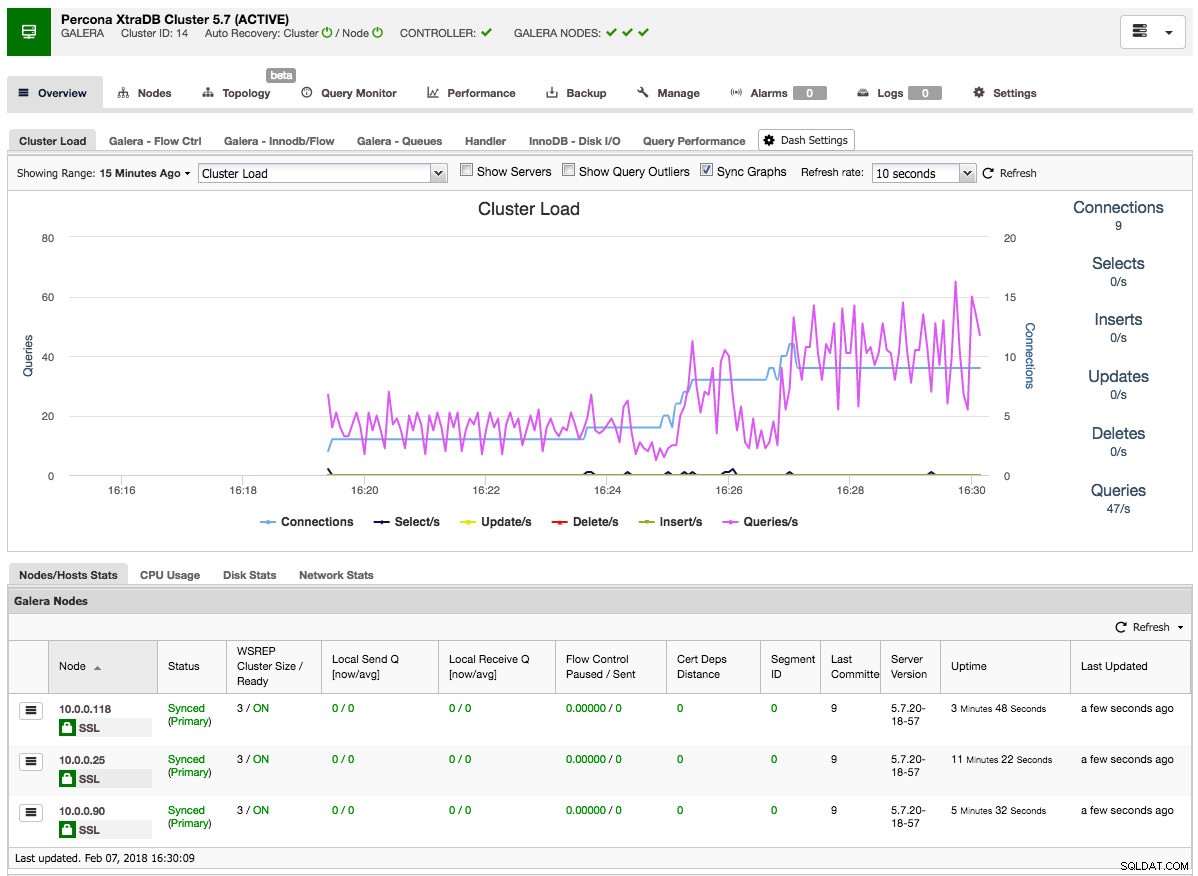
Na karcie węzły możesz wykonać dowolną operację, którą normalnie wykonasz na klastrze. Monitor zapytań zapewnia dobry przegląd zarówno uruchomionych, jak i najczęstszych zapytań. Karta wydajności pomoże Ci uważnie obserwować wydajność klastra, a także zawiera doradców, którzy pomogą Ci aktywnie reagować na trendy w danych. Karta kopii zapasowej umożliwia łatwe planowanie tworzenia kopii zapasowych i przechowywanie ich w pamięci lokalnej lub w chmurze. Karta zarządzania umożliwia rozszerzenie klastra lub uczynienie go wysoce dostępnym dla aplikacji za pomocą systemu równoważenia obciążenia.
Cała ta funkcjonalność zostanie omówiona w późniejszych wpisach na blogu z tej serii.
Wdróż klaster replikacji MySQL
Wdrażanie konfiguracji MySQL Replication jest podobne do wdrażania bazy danych Galera, z tą różnicą, że w oknie dialogowym wdrażania znajduje się dodatkowa zakładka, w której można zdefiniować topologię replikacji:
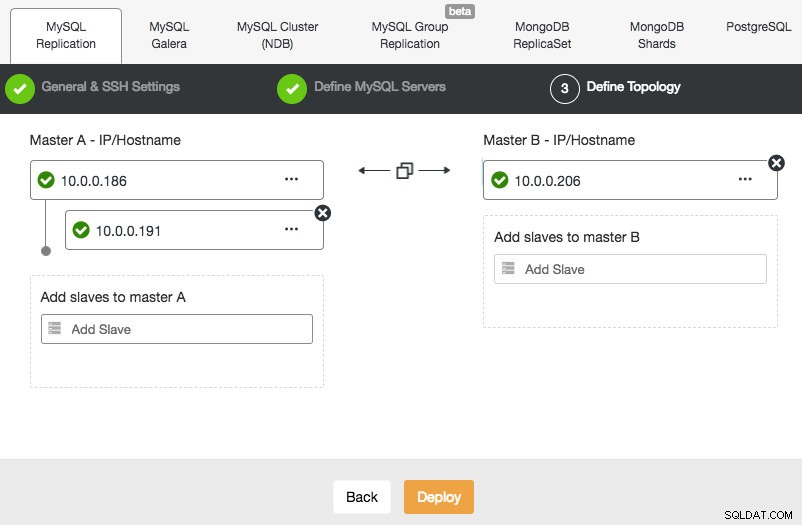
Możesz skonfigurować standardową replikację master-slave, a także replikację master-master. W przypadku tego ostatniego, tylko jeden master będzie zapisywalny w danym momencie. Należy pamiętać, że replikacja master-master nie zapewnia rozwiązywania konfliktów i gwarantowanej spójności danych, jak w przypadku Galery. Używaj tej konfiguracji ostrożnie lub zajrzyj do klastra Galera. Gdy wszystko stanie się zielone i klikniesz Wdróż, zostanie utworzone zadanie do zbudowania nowego klastra.
Ponownie, postęp wdrażania jest dostępny w Aktywność -> Zadania.
Aby skalować urządzenie podrzędne (odczyt kopii), po prostu użyj opcji „Dodaj węzeł” na liście klastrów:
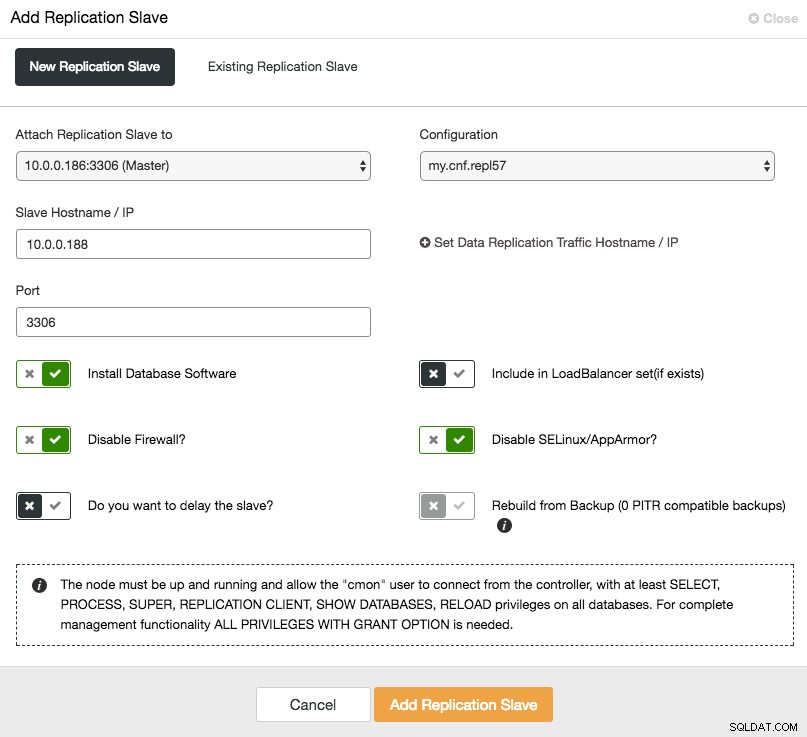
Po dodaniu węzła podrzędnego, ClusterControl dostarczy do urządzenia podrzędnego kopię danych z jego urządzenia nadrzędnego za pomocą Xtrabackup lub z dowolnych istniejących kopii zapasowych zgodnych z PITR dla tego klastra.
Wdróż replikację PostgreSQL
ClusterControl obsługuje wdrażanie PostgreSQL w wersji 9.x i nowszych. Kroki są podobne w przypadku wdrażania MySQL Replication, gdzie na końcu etapu wdrażania można zdefiniować topologię bazy danych podczas dodawania węzłów:
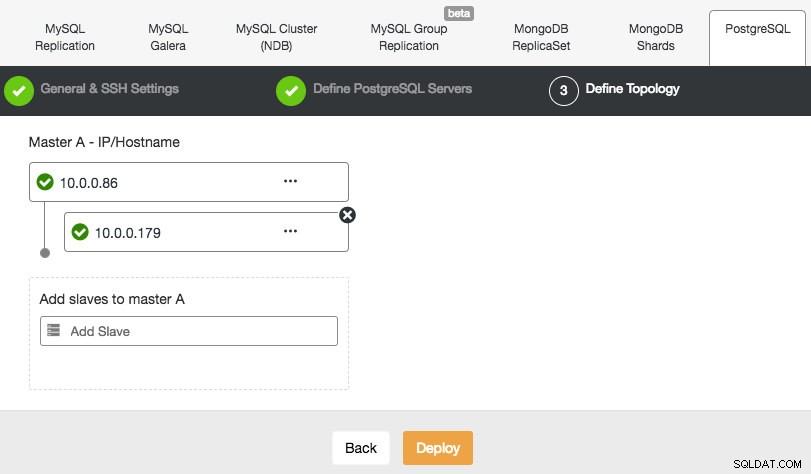
Podobnie jak w przypadku replikacji MySQL, po zakończeniu wdrażania można skalować w poziomie, dodając do klastra replikację podrzędną. Krok jest tak prosty, jak wybranie urządzenia nadrzędnego i wypełnienie FQDN dla nowego urządzenia podrzędnego:
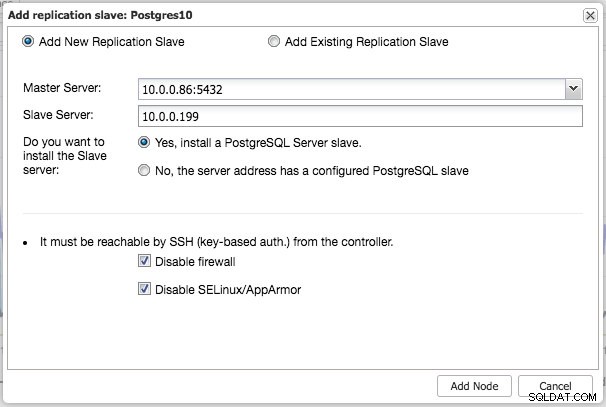
ClusterControl wykona następnie niezbędne dane z wybranego urządzenia głównego za pomocą pg_basebackup, skonfiguruje użytkownika replikacji i włączy replikację strumieniową. Przegląd klastra PostgreSQL daje pewien wgląd w konfigurację:
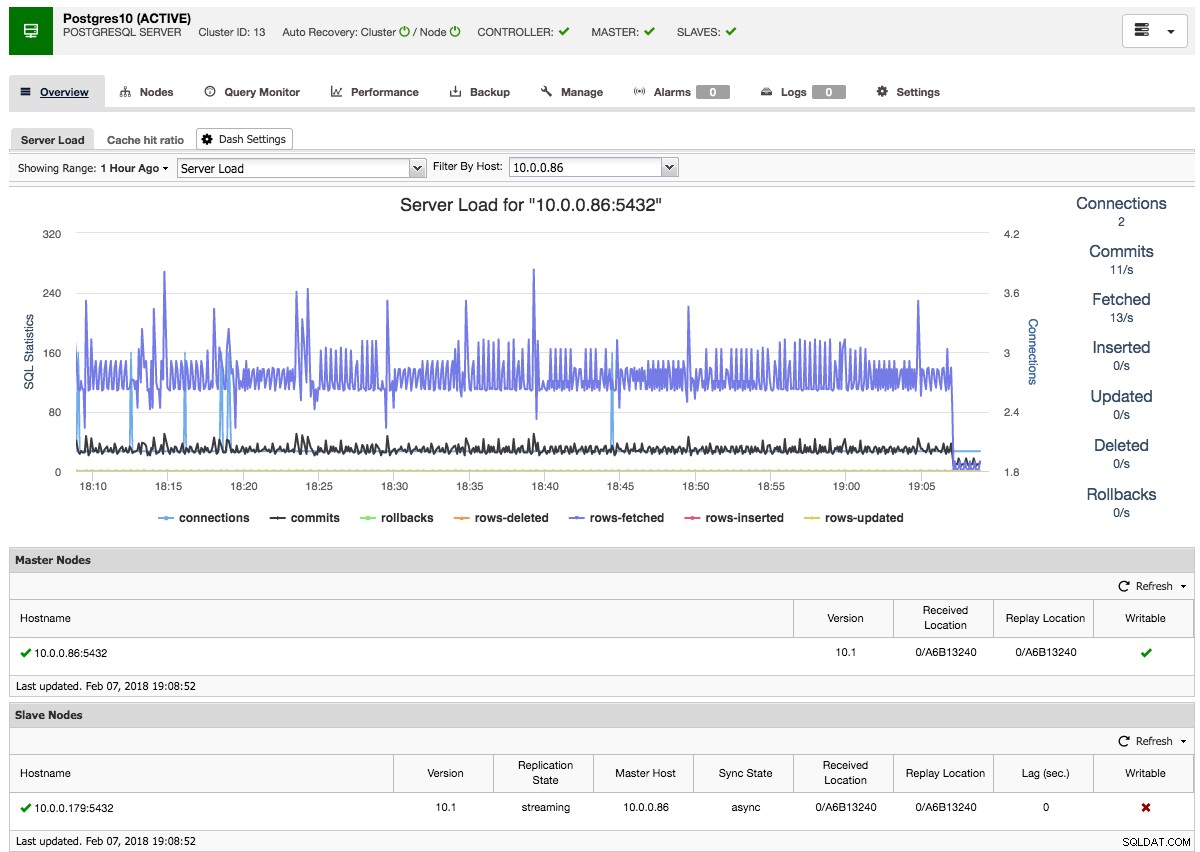
Podobnie jak w przypadku przeglądów klastrów Galera i MySQL, tutaj znajdziesz wszystkie niezbędne zakładki i funkcje:monitor zapytań, wydajność, zakładki kopii zapasowych, które umożliwiają wykonanie niezbędnych operacji.
Wdróż zestaw replik MongoDB
Wdrażanie nowego zestawu replik MongoDB jest podobne do innych klastrów. W oknie dialogowym Deploy Database Cluster wybierz MongoDB ReplicatSet, zdefiniuj preferowane opcje bazy danych i dodaj węzły bazy danych:
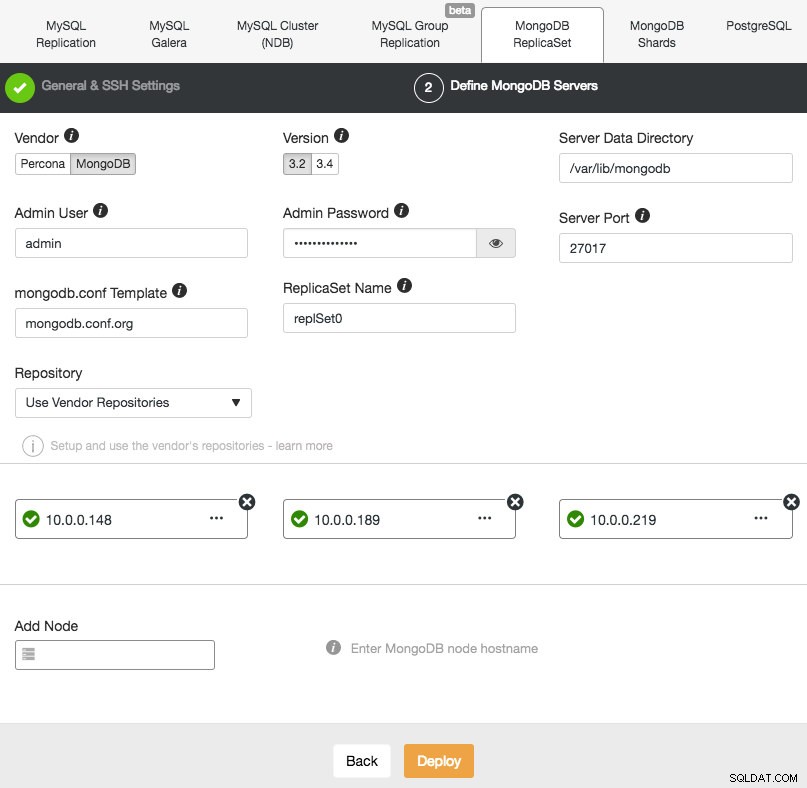
Możesz wybrać instalację Percona Server for MongoDB firmy Percona lub MongoDB Server firmy MongoDB, Inc (wcześniej 10gen). Musisz również określić użytkownika i hasło administratora MongoDB, ponieważ ClusterControl domyślnie wdroży klaster MongoDB z włączonym uwierzytelnianiem.
Po zainstalowaniu klastra możesz dodać dodatkowy węzeł podrzędny lub węzeł arbitra do zestawu replik za pomocą menu „Dodaj węzeł” w tym samym menu rozwijanym z przeglądu klastra:
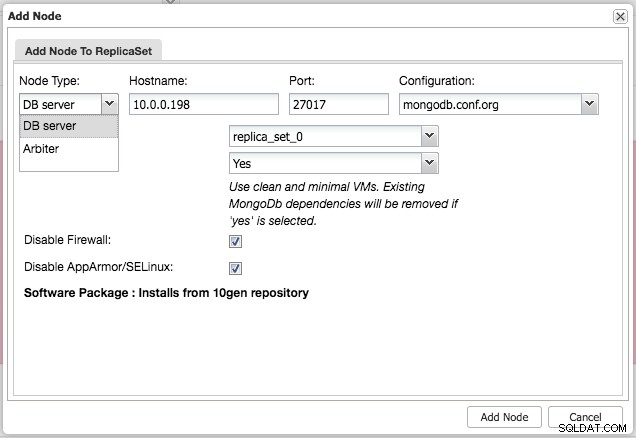
Po dodaniu niewolnika lub arbitra do zestawu replik, zostanie uruchomione zadanie. Po zakończeniu tego zadania minie trochę czasu, zanim MongoDB doda je do klastra i stanie się widoczne w przeglądzie klastra:
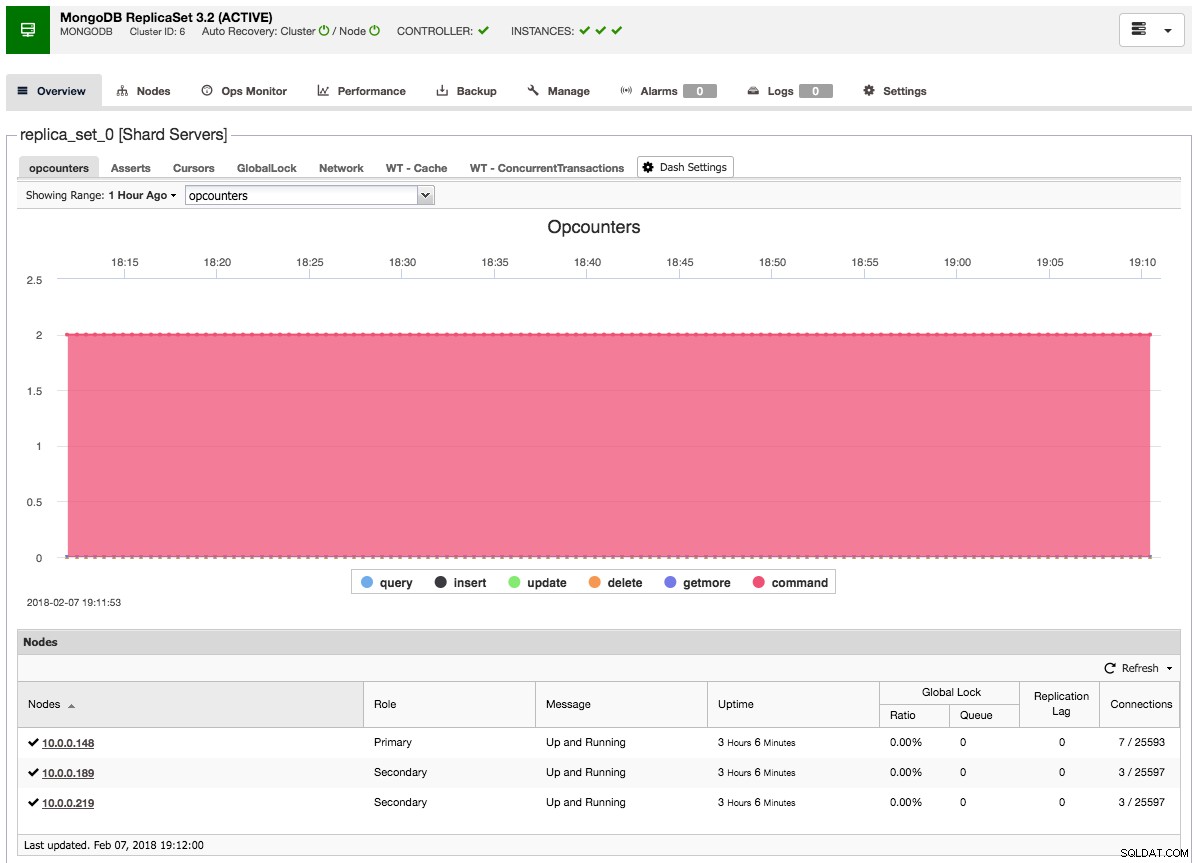
Ostateczne myśli
Dzięki tym trzem przykładom pokazaliśmy, jak łatwo jest skonfigurować różne klastry od podstaw w zaledwie kilka minut. Piękno korzystania z tej konfiguracji Włóczęgów polega na tym, że równie łatwe jak odrodzenie tego środowiska, można je również zdjąć, a następnie odrodzić. Zaskocz swoich kolegów, pokazując, jak szybko możesz skonfigurować środowisko pracy.
Oczywiście równie interesujące byłoby dodanie istniejących hostów i już wdrożonych klastrów do ClusterControl, i to omówimy następnym razem.