Jednym ze świetnych sposobów poznania błędów w programie SQL Server jest zapoznanie się z uwagami do wydania dla aktualizacji zbiorczych i dodatków Service Pack, gdy się pojawią. Jednak czasami jest to również świetny sposób na zapoznanie się z ulepszeniami programu SQL Server.
Zbiorcza aktualizacja 6 dla dodatku Service Pack 1 dla programu SQL Server 2014 wprowadzono nową flagę śledzenia 7471, która zmienia zachowanie blokowania zadań UPDATE STATISTICS w programie SQL Server (zobacz KB #3156157). W tym poście przyjrzymy się różnicy w zachowaniu blokowania i tym, gdzie ta flaga śledzenia może być przydatna.
Aby skonfigurować odpowiednie środowisko demo dla tego posta, skorzystałem z bazy danych AdventureWorks2014 i stworzyłem powiększoną wersję tabeli SalesOrderDetail na podstawie skryptu dostępnego na moim blogu. Tabela SalesOrderDetailEnlarged została powiększona do rozmiaru 2 GB, aby umożliwić jednoczesne wykonywanie operacji UPDATE STATISTICS WITH FULLSCAN względem różnych statystyk w tabeli. Następnie użyłem sp_whoisactive do zbadania blokad utrzymywanych przez obie sesje.
Zachowanie bez TF 7471
Domyślne zachowanie programu SQL Server wymaga blokady na wyłączność (X) na zasobie OBJECT.UPDSTATS dla tabeli za każdym razem, gdy polecenie UPDATE STATISTICS jest wykonywane względem tabeli. Można to zobaczyć w danych wyjściowych sp_whoisactive dla dwóch współbieżnych wykonań UPDATE STATISTICS WITH FULLSCAN względem tabeli Sales.SalesOrderDetailEnlarged przy użyciu różnych nazw indeksów do aktualizacji statystyk. Powoduje to zablokowanie drugiego wykonania AKTUALIZACJI STATYSTYK aż do zakończenia pierwszego wykonania.
UPDATE STATISTICS [Sales].[SalesOrderDetailEnlarged]
([PK_SalesOrderDetailEnlarged_SalesOrderID_SalesOrderDetailID]) WITH FULLSCAN; <Object name="SalesOrderDetailEnlarged" schema_name="Sales">
<Locks>
<Lock resource_type="METADATA.INDEXSTATS"
index_name="PK_SalesOrderDetailEnlarged_SalesOrderID_SalesOrderDetailID"
request_mode="Sch-S" request_status="GRANT" request_count="2" />
<Lock resource_type="METADATA.STATS" request_mode="Sch-S" request_status="GRANT" request_count="1" />
<Lock resource_type="OBJECT" request_mode="Sch-S" request_status="GRANT" request_count="2" />
<Lock resource_type="OBJECT.UPDSTATS" request_mode="X" request_status="GRANT" request_count="1" />
</Locks>
</Object> UPDATE STATISTICS [Sales].[SalesOrderDetailEnlarged]
([IX_SalesOrderDetailEnlarged_ProductID]) WITH FULLSCAN; <Object name="SalesOrderDetailEnlarged" schema_name="Sales">
<Locks>
<Lock resource_type="METADATA.INDEXSTATS"
index_name="PK_SalesOrderDetailEnlarged_SalesOrderID_SalesOrderDetailID"
request_mode="Sch-S" request_status="GRANT" request_count="1" />
<Lock resource_type="OBJECT" request_mode="Sch-S" request_status="GRANT" request_count="1" />
<Lock resource_type="OBJECT.UPDSTATS" request_mode="X" request_status="WAIT" request_count="1" />
</Locks>
</Object> Szczegółowość zasobu blokady znajdującego się w OBJECT.UPDSTATS zapobiega równoczesnym aktualizacjom wielu statystyk w tej samej tabeli. Udoskonalenia sprzętowe w ostatnich latach naprawdę zmieniły potencjalne wąskie gardła, które są wspólne dla implementacji SQL Server i podobnie jak wprowadzono zmiany w DBCC CHECKDB, aby przyspieszyć działanie, zmieniając zachowanie blokowania UPDATE STATISTICS, aby umożliwić jednoczesne aktualizowanie statystyk na ta sama tabela może znacznie skrócić okresy konserwacji dla VLDB, zwłaszcza tam, gdzie jest wystarczająca moc procesora i podsystemu we/wy, aby umożliwić jednoczesne aktualizacje bez wpływu na wrażenia użytkownika końcowego.
Zachowanie z TF 7471
Zachowanie blokowania z flagą śledzenia 7471 umożliwiało zmiany z wymagania wyłącznej blokady (X) na zasobie OBJECT.UPDSTATS na wymaganie blokady aktualizacji (U) na zasobie METADATA.STATS dla określonej statystyki, która jest aktualizowana, co umożliwia jednoczesne wykonywanie UPDATE STATISTICS w tej samej tabeli. Dane wyjściowe sp_whoisactive dla tych samych poleceń UPDATE STATISTICS WITH FULLCAN z włączoną flagą śledzenia pokazano poniżej:
UPDATE STATISTICS [Sales].[SalesOrderDetailEnlarged]
([PK_SalesOrderDetailEnlarged_SalesOrderID_SalesOrderDetailID]) WITH FULLSCAN; <Object name="SalesOrderDetailEnlarged" schema_name="Sales">
<Locks>
<Lock resource_type="METADATA.INDEXSTATS"
index_name="PK_SalesOrderDetailEnlarged_SalesOrderID_SalesOrderDetailID"
request_mode="Sch-S" request_status="GRANT" request_count="2" />
<Lock resource_type="METADATA.STATS" request_mode="U" request_status="GRANT" request_count="1" />
<Lock resource_type="OBJECT" request_mode="Sch-S" request_status="GRANT" request_count="2" />
</Locks>
</Object> UPDATE STATISTICS [Sales].[SalesOrderDetailEnlarged]
([IX_SalesOrderDetailEnlarged_ProductID]) WITH FULLSCAN; <Objects>
<Object name="SalesOrderDetailEnlarged" schema_name="Sales">
<Locks>
<Lock resource_type="METADATA.INDEXSTATS"
index_name="IX_SalesOrderDetailEnlarged_ProductID"
request_mode="Sch-S" request_status="GRANT" request_count="2" />
<Lock resource_type="METADATA.INDEXSTATS"
index_name="PK_SalesOrderDetailEnlarged_SalesOrderID_SalesOrderDetailID"
request_mode="Sch-S" request_status="GRANT" request_count="2" />
<Lock resource_type="METADATA.STATS" request_mode="U" request_status="GRANT" request_count="1" />
<Lock resource_type="OBJECT" request_mode="Sch-S" request_status="GRANT" request_count="2" />
</Locks>
</Object> W przypadku VLDB, które stają się coraz bardziej powszechne, może to mieć duży wpływ na czas potrzebny na wykonanie aktualizacji statystyk na serwerze.
Niedawno pisałem na blogu o równoległym rozwiązaniu do konserwacji SQL Server przy użyciu skryptów konserwacyjnych Service Broker i Ola Hallengren jako sposobu na optymalizację nocnych zadań konserwacyjnych i skrócenie czasu wymaganego do przebudowy indeksów i aktualizacji statystyk na serwerach, które mają dużą moc procesora i we/wy dostępny. W ramach tego rozwiązania wymusiłem kolejność zadań w kolejce do Service Broker, aby spróbować uniknąć równoczesnych wykonań względem tej samej tabeli zarówno dla zadań odbudowy/reorganizacji indeksu, jak i UPDATE STATISTICS. Celem tego było utrzymanie jak największej liczby pracowników aż do zakończenia zadań konserwacyjnych, podczas których wykonywana byłaby serializacja w oparciu o blokowanie współbieżnych zadań.
Zrobiłem kilka modyfikacji w przetwarzaniu w tym poście, aby po prostu przetestować efekty tej flagi śledzenia tylko z równoczesnymi aktualizacjami statystyk, a wyniki są poniżej.
Testowanie wydajności jednoczesnej aktualizacji statystyk
Aby przetestować wydajność tylko równoległego aktualizowania statystyk przy użyciu konfiguracji Service Broker, zacząłem od utworzenia statystyki kolumn dla każdej kolumny w bazie danych AdventureWorks2014, używając poniższego skryptu do generowania poleceń DDL do wykonania.
USE [AdventureWorks2014]
GO
SELECT *, 'DROP STATISTICS ' + QUOTENAME(c.TABLE_SCHEMA) + '.'
+ QUOTENAME(c.TABLE_NAME) + '.' + QUOTENAME(c.TABLE_NAME
+ '_' + c.COLUMN_NAME) + ';
GO
CREATE STATISTICS ' +QUOTENAME(c.TABLE_NAME + '_' + c.COLUMN_NAME)
+ ' ON ' + QUOTENAME(c.TABLE_SCHEMA) + '.' + QUOTENAME(c.TABLE_NAME)
+ ' (' +QUOTENAME(c.COLUMN_NAME) + ');' + '
GO'
FROM INFORMATION_SCHEMA.COLUMNS AS c
INNER JOIN INFORMATION_SCHEMA.TABLES AS t
ON c.TABLE_CATALOG = t.TABLE_CATALOG AND
c.TABLE_SCHEMA = t.TABLE_SCHEMA AND
c.TABLE_NAME = t.TABLE_NAME
WHERE t.TABLE_TYPE = 'BASE TABLE'
AND c.DATA_TYPE <> N'xml'; To nie jest coś, co zwykle chciałbyś zrobić, ale daje mi mnóstwo statystyk do równoległego testowania wpływu flagi śledzenia na współbieżne aktualizowanie statystyk. Zamiast losować kolejność, w jakiej ustawiam zadania w kolejce do Service Broker, zamiast tego po prostu umieszczam zadania w kolejce tak, jak istnieją w tabeli CommandLog na podstawie identyfikatora tabeli, po prostu zwiększając identyfikator o jeden, aż wszystkie polecenia zostaną umieszczone w kolejce do przetworzenia.
USE [master]; -- Clear the Command Log TRUNCATE TABLE [master].[dbo].[CommandLog]; DECLARE @MaxID INT; SELECT @MaxID = MAX(ID) FROM master.dbo.CommandLog; SELECT @MaxID = ISNULL(@MaxID, 1) ---- Load new tasks into the Command Log EXEC master.dbo.IndexOptimize @Databases = N'AdventureWorks2014', @FragmentationLow = NULL, @FragmentationMedium = NULL, @FragmentationHigh = NULL, @UpdateStatistics = 'ALL', @StatisticsSample = 100, @LogToTable = 'Y', @Execute = 'N'; DECLARE @NewMaxID INT SELECT @NewMaxID = MAX(ID) FROM master.dbo.CommandLog; USE msdb; DECLARE @CurrentID INT = @MaxID WHILE (@CurrentID <= @NewMaxID) BEGIN -- Begin a conversation and send a request message DECLARE @conversation_handle UNIQUEIDENTIFIER; DECLARE @message_body XML; BEGIN TRANSACTION; BEGIN DIALOG @conversation_handle FROM SERVICE [OlaHallengrenMaintenanceTaskService] TO SERVICE N'OlaHallengrenMaintenanceTaskService' ON CONTRACT [OlaHallengrenMaintenanceTaskContract] WITH ENCRYPTION = OFF; SELECT @message_body = N'<CommandLogID>'+CAST(@CurrentID AS NVARCHAR)+N'</CommandLogID>'; SEND ON CONVERSATION @conversation_handle MESSAGE TYPE [OlaHallengrenMaintenanceTaskMessage] (@message_body); COMMIT TRANSACTION; SET @CurrentID = @CurrentID + 1; END WHILE EXISTS (SELECT 1 FROM OlaHallengrenMaintenanceTaskQueue WITH(NOLOCK)) BEGIN WAITFOR DELAY '00:00:01.000' END WAITFOR DELAY '00:00:06.000' SELECT DATEDIFF(ms, MIN(StartTime), MAX(EndTime)) FROM master.dbo.CommandLog; GO 10
Następnie czekałem na zakończenie wszystkich zadań, zmierzyłem różnicę w czasie rozpoczęcia i zakończenia wykonywania zadań i wziąłem średnią z dziesięciu testów, aby określić ulepszenia tylko w celu jednoczesnej aktualizacji statystyk przy użyciu domyślnego próbkowania i aktualizacji pełnego skanowania.
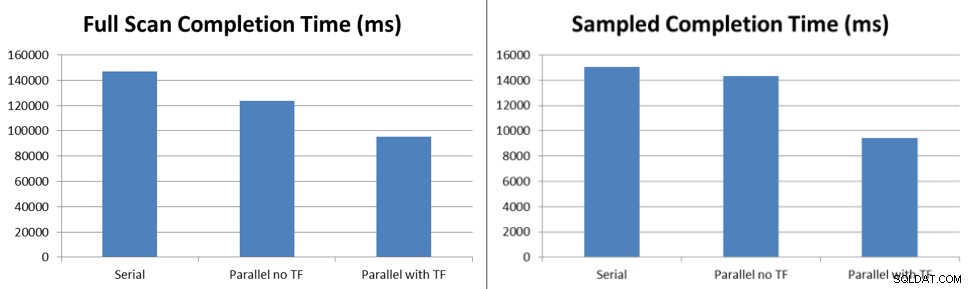
Wyniki testu pokazują, że nawet w przypadku blokowania, które występuje w ramach domyślnego zachowania bez flagi śledzenia, próbkowane aktualizacje statystyk są uruchamiane o 6% szybciej, a aktualizacje pełnego skanowania są uruchamiane o 16% szybciej z pięcioma wątkami przetwarzającymi zadania w kolejce do usługi Service Broker. Po włączeniu flagi śledzenia 7471 te same próbkowane aktualizacje statystyk działają o 38% szybciej, a aktualizacje pełnego skanowania działają o 45% szybciej z pięcioma wątkami przetwarzającymi zadania umieszczone w kolejce do usługi Service Broker.
Potencjalne wyzwania z TF 7471
Jakkolwiek przekonujące są wyniki testów, nic na tym świecie nie jest darmowe, a podczas moich wstępnych testów napotkałem pewne problemy z rozmiarem maszyny wirtualnej, której używałem na moim laptopie, co powodowało problemy z obciążeniem.
Początkowo testowałem równoległą konserwację przy użyciu maszyny wirtualnej 4vCPU z 4 GB pamięci RAM, którą skonfigurowałem specjalnie do tego celu. Gdy zacząłem zwiększać liczbę MAX_QUEUE_READERS dla procedury aktywacji w Service Broker, zacząłem napotykać problemy z RESOURCE_SEMAPHORE czekami po włączeniu flagi śledzenia, co pozwala na równoległe aktualizowanie statystyk w powiększonych tabelach w mojej bazie danych AdventureWorks2014 ze względu na wymagania dotyczące przyznawania pamięci dla każdej z uruchomionych komend UPDATE STATISTICS. Zostało to złagodzone przez zmianę konfiguracji maszyny wirtualnej na 16 GB pamięci RAM, ale jest to coś, co należy monitorować i obserwować podczas wykonywania równoległych zadań na większych tabelach, w tym konserwacji indeksu, ponieważ głód przyznawania pamięci wpłynie również na żądania użytkowników końcowych, które mogą próbować wykonać i Potrzebujesz również większego przydziału pamięci.
Zespół produktu również napisał na blogu o tej fladze śledzenia i ostrzegał w swoim poście, że scenariusze impasu mogą wystąpić podczas jednoczesnej aktualizacji statystyk podczas tworzenia statystyk. To nie jest coś, na co jeszcze natknąłem się podczas moich testów, ale zdecydowanie jest to coś, o czym należy pamiętać (Kendra Little też przed tym ostrzega). W związku z tym ich zaleceniem jest, aby ta flaga śledzenia była włączona tylko podczas równoległego wykonywania zadania konserwacji, a następnie powinna być wyłączona w normalnych okresach obciążenia.
Miłej zabawy!