W poprzednim poście omówiliśmy, w jaki sposób można przejąć kontrolę nad procesem przełączania awaryjnego w ClusterControl, korzystając z białych i czarnych list. W tym poście omówimy podobną koncepcję. Ale tym razem skupimy się na integracjach z zewnętrznymi skryptami i aplikacjami za pośrednictwem licznych podpięć udostępnianych przez ClusterControl.
Środowiska infrastrukturalne można budować na różne sposoby, ponieważ często istnieje wiele opcji do wyboru dla danego elementu układanki. Jak zdefiniować węzeł bazy danych, do którego należy pisać? Czy korzystasz z wirtualnego adresu IP? Czy korzystasz z funkcji wykrywania usług? Może idziesz z wpisami DNS i zmieniasz rekordy A w razie potrzeby? A co z warstwą proxy? Czy polegasz na wartości „tylko do odczytu”, aby serwery proxy decydowały o pisarzu, czy może wprowadzasz wymagane zmiany bezpośrednio w konfiguracji serwera proxy? Jak Twoje środowisko radzi sobie z przełączaniem? Czy możesz po prostu iść dalej i go wykonać, a może musisz wcześniej podjąć wstępne działania? Na przykład, czy zatrzymać niektóre inne procesy, zanim będziesz mógł dokonać przełączenia?
Nie jest możliwe, aby oprogramowanie do przełączania awaryjnego było wstępnie skonfigurowane tak, aby obejmowało wszystkie różne konfiguracje, które mogą tworzyć ludzie. Jest to główny powód, aby zapewnić różne sposoby podłączania się do procesu przełączania awaryjnego. W ten sposób możesz go dostosować i umożliwić obsługę wszystkich subtelności swojej konfiguracji. W tym poście na blogu przyjrzymy się, w jaki sposób można dostosować proces przełączania awaryjnego ClusterControl za pomocą różnych skryptów przed i po awarii. Omówimy również kilka przykładów tego, co można osiągnąć dzięki takiej personalizacji.
Integracja ClusterControl
ClusterControl udostępnia kilka punktów zaczepienia, których można użyć do podłączenia zewnętrznych skryptów. Poniżej znajdziesz listę tych z pewnym wyjaśnieniem.
- Replication_onfail_failover_script — ten skrypt jest wykonywany, gdy tylko zostanie wykryte, że konieczne jest przełączenie awaryjne. Jeśli skrypt zwróci wartość niezerową, wymusi przerwanie pracy awaryjnej. Jeśli skrypt zostanie zdefiniowany, ale nie zostanie znaleziony, przełączanie awaryjne zostanie przerwane. Do skryptu dostarczane są cztery argumenty:arg1='wszystkie serwery' arg2='starymaster' arg3='kandydat', arg4='niewolnicy starego mistrza' i przekazywane w następujący sposób:'nazwa_skryptu arg1 arg2 arg3 arg4'. Skrypt musi być dostępny na kontrolerze i wykonywalny.
- Replication_pre_failover_script — ten skrypt jest wykonywany przed przejściem awaryjnym, ale po wybraniu kandydata i możliwe jest kontynuowanie procesu przełączania awaryjnego. Jeśli skrypt zwróci wartość niezerową, spowoduje to przerwanie pracy awaryjnej. Jeśli skrypt zostanie zdefiniowany, ale nie zostanie znaleziony, przełączanie awaryjne zostanie przerwane. Skrypt musi być dostępny na kontrolerze i wykonywalny.
- Replication_post_failover_script — ten skrypt jest wykonywany po przełączeniu awaryjnym. Jeśli skrypt zwróci wartość niezerową, w protokole zadania zostanie zapisane Ostrzeżenie. Skrypt musi być dostępny na kontrolerze i wykonywalny.
- Replication_post_unsuccessful_failover_script — ten skrypt jest wykonywany po nieudanej próbie przełączenia awaryjnego. Jeśli skrypt zwróci wartość niezerową, w protokole zadania zostanie zapisane Ostrzeżenie. Skrypt musi być dostępny na kontrolerze i wykonywalny.
- Replication_failed_reslave_failover_script — ten skrypt jest wykonywany po wypromowaniu nowego mastera i jeśli ponowne podporządkowanie slave'owi nowego mastera nie powiedzie się. Jeśli skrypt zwróci wartość niezerową, w protokole zadania zostanie zapisane Ostrzeżenie. Skrypt musi być dostępny na kontrolerze i wykonywalny.
- Replication_pre_switchover_script — ten skrypt jest wykonywany przed przełączeniem. Jeśli skrypt zwróci wartość niezerową, wymusi to niepowodzenie przełączenia. Jeśli skrypt zostanie zdefiniowany, ale nie zostanie znaleziony, przełączenie zostanie przerwane. Skrypt musi być dostępny na kontrolerze i wykonywalny.
- Replication_post_switchover_script — ten skrypt jest wykonywany po przełączeniu. Jeśli skrypt zwróci wartość niezerową, w protokole zadania zostanie zapisane Ostrzeżenie. Skrypt musi być dostępny na kontrolerze i wykonywalny.
Jak widać, podpięcia obejmują większość przypadków, w których możesz chcieć podjąć pewne działania - przed i po przełączeniu, przed i po przełączeniu awaryjnym, gdy nie powiodło się przejęcie lub przełączenie awaryjne. Wszystkie skrypty są wywoływane z czterema argumentami (które mogą, ale nie muszą być obsługiwane w skrypcie, nie jest wymagane, aby skrypt wykorzystywał je wszystkie):wszystkie serwery, nazwa hosta (lub adres IP - tak jak jest zdefiniowany w ClusterControl) starego mastera, nazwę hosta (lub IP - jak zdefiniowano w ClusterControl) kandydata na mastera i czwartego, wszystkie repliki starego mastera. Te opcje powinny umożliwić obsługę większości przypadków.
Wszystkie te podpięcia powinny być zdefiniowane w pliku konfiguracyjnym dla danego klastra (/etc/cmon.d/cmon_X.cnf gdzie X jest identyfikatorem klastra). Przykład może wyglądać tak:
replication_pre_failover_script=/usr/bin/stonith.py
replication_post_failover_script=/usr/bin/vipmove.shOczywiście wywoływane skrypty muszą być wykonywalne, inaczej cmon nie będzie w stanie ich wykonać. Poświęćmy teraz chwilę i przejdźmy przez proces przełączania awaryjnego w ClusterControl i zobaczmy, kiedy zewnętrzne skrypty są wykonywane.
Proces przełączania awaryjnego w ClusterControl
Zdefiniowaliśmy wszystkie dostępne haki:
replication_onfail_failover_script=/tmp/1.sh
replication_pre_failover_script=/tmp/2.sh
replication_post_failover_script=/tmp/3.sh
replication_post_unsuccessful_failover_script=/tmp/4.sh
replication_failed_reslave_failover_script=/tmp/5.sh
replication_pre_switchover_script=/tmp/6.sh
replication_post_switchover_script=/tmp/7.shNastępnie musisz ponownie uruchomić proces cmon. Po zakończeniu jesteśmy gotowi do przetestowania przełączania awaryjnego. Oryginalna topologia wygląda tak:
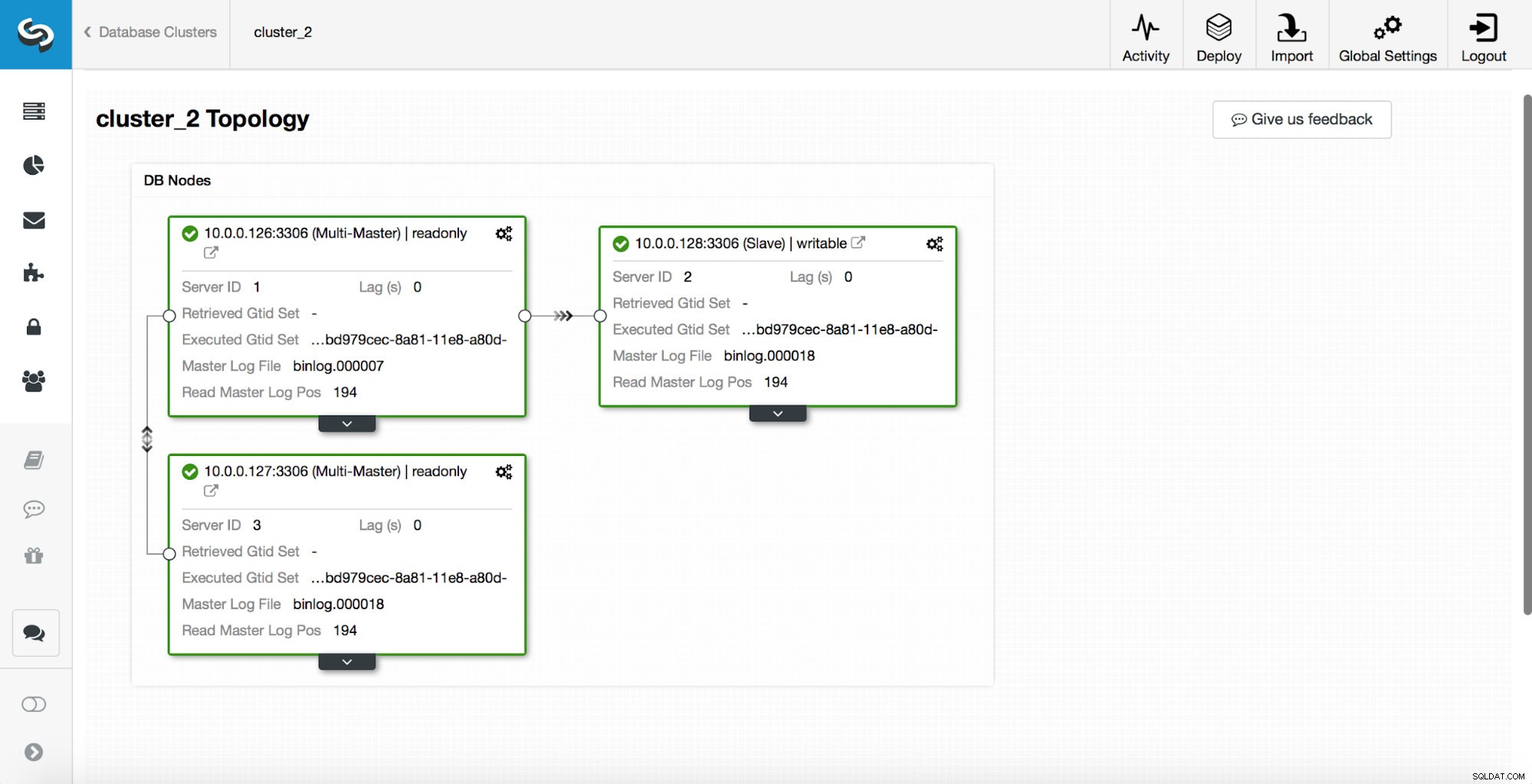
Master został zabity i rozpoczął się proces przełączania awaryjnego. Pamiętaj, że nowsze wpisy w dzienniku znajdują się na górze, więc chcesz śledzić przełączanie awaryjne od dołu do góry.
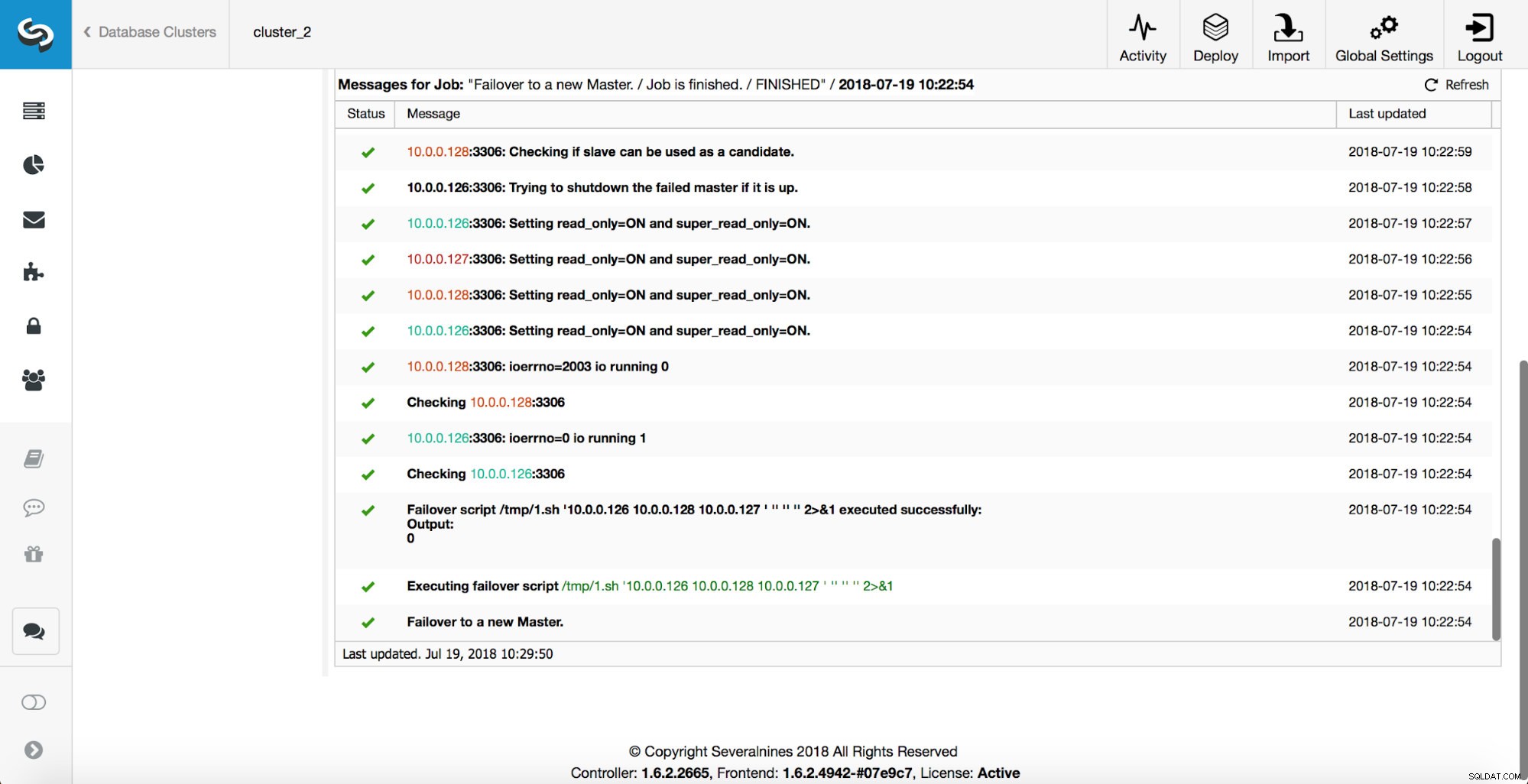
Jak widać, natychmiast po uruchomieniu zadania przełączania awaryjnego wyzwala przechwycenie „replication_onfail_failover_script”. Następnie wszystkie osiągalne hosty są oznaczane jako tylko do odczytu, a ClusterControl próbuje uniemożliwić uruchomienie starego systemu głównego.
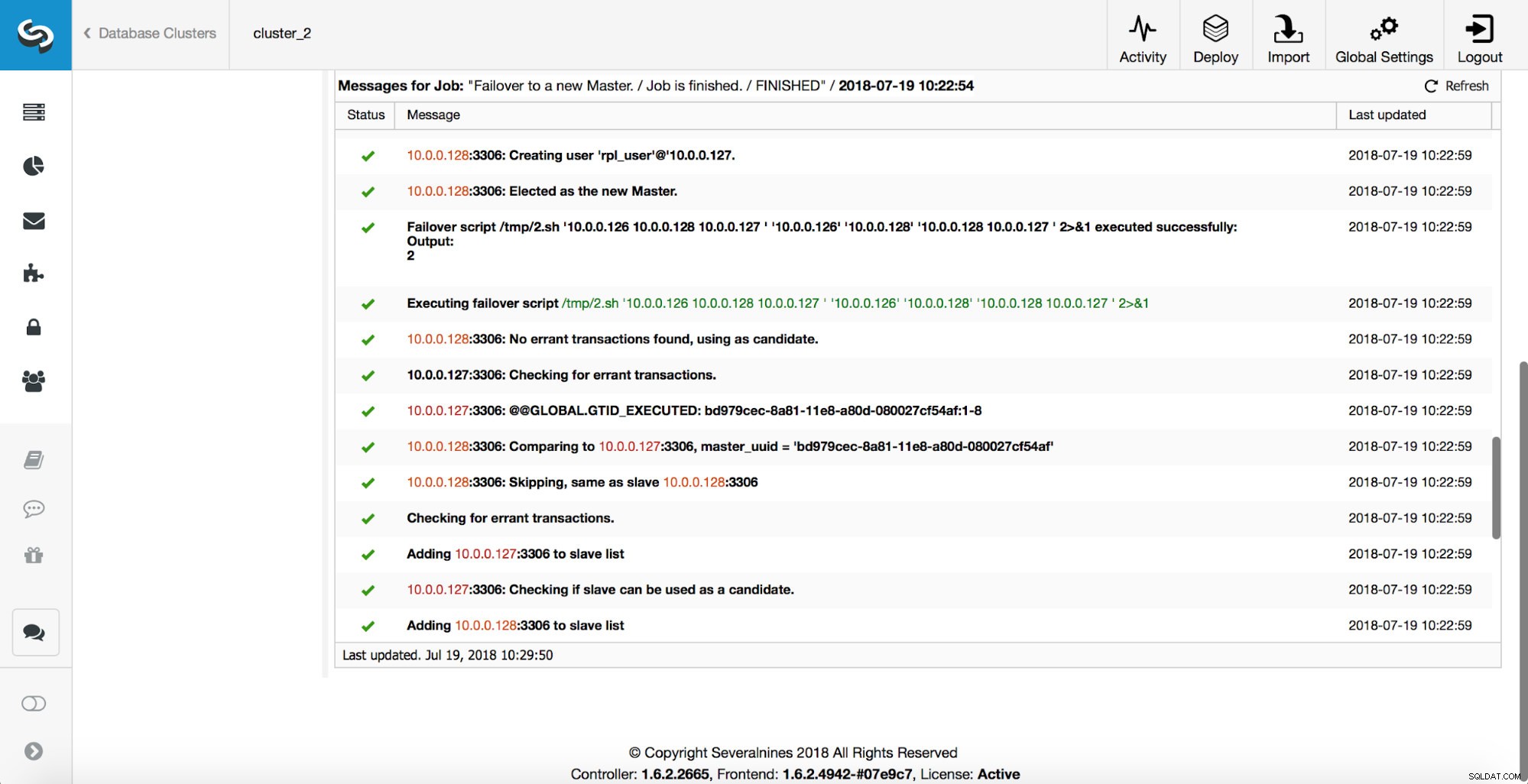
Następnie wybierany jest kandydat na mistrza, wykonywane są kontrole sprawności. Po potwierdzeniu, że kandydat na mastera może być używany jako nowy master, wykonywany jest „replication_pre_failover_script”.
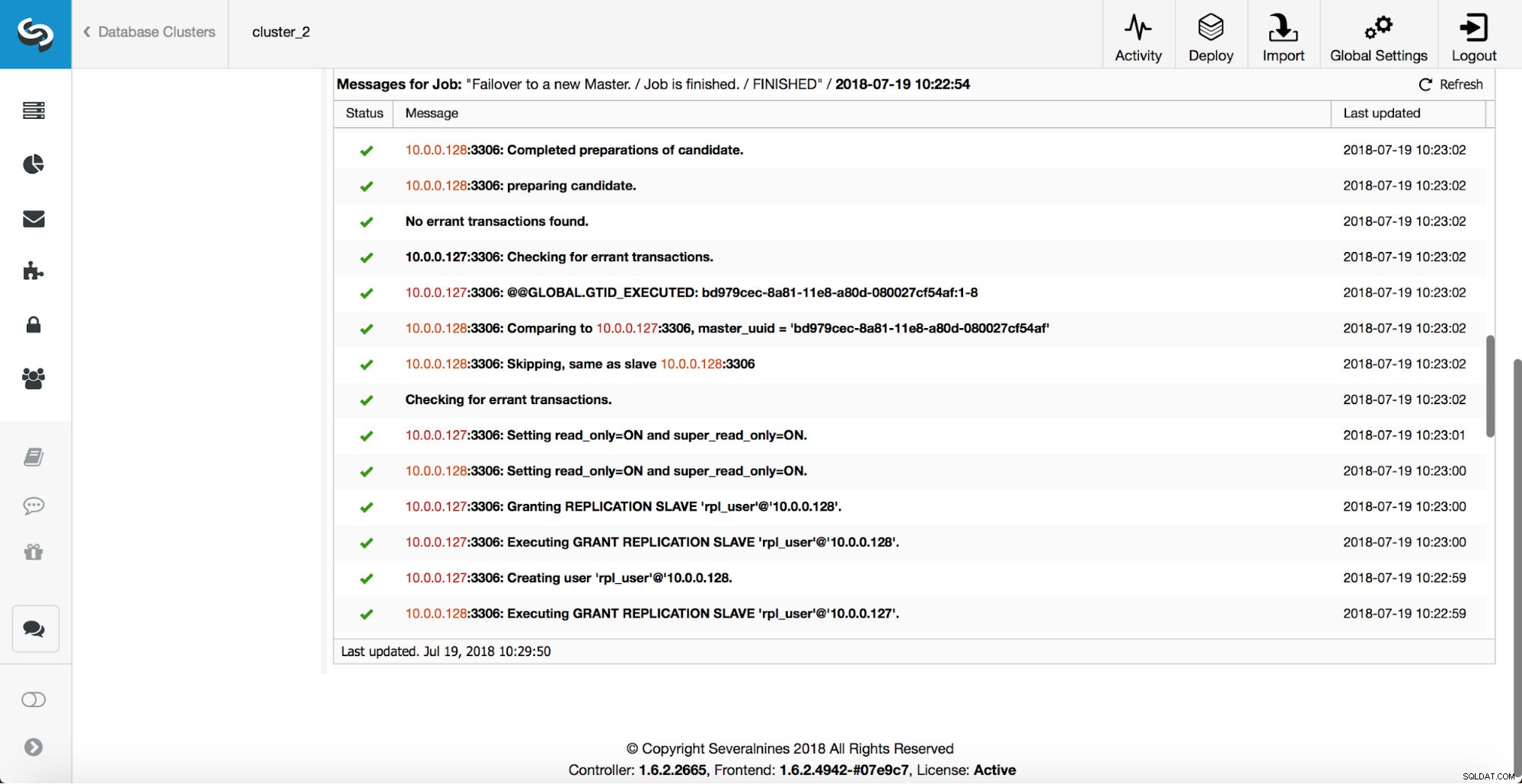
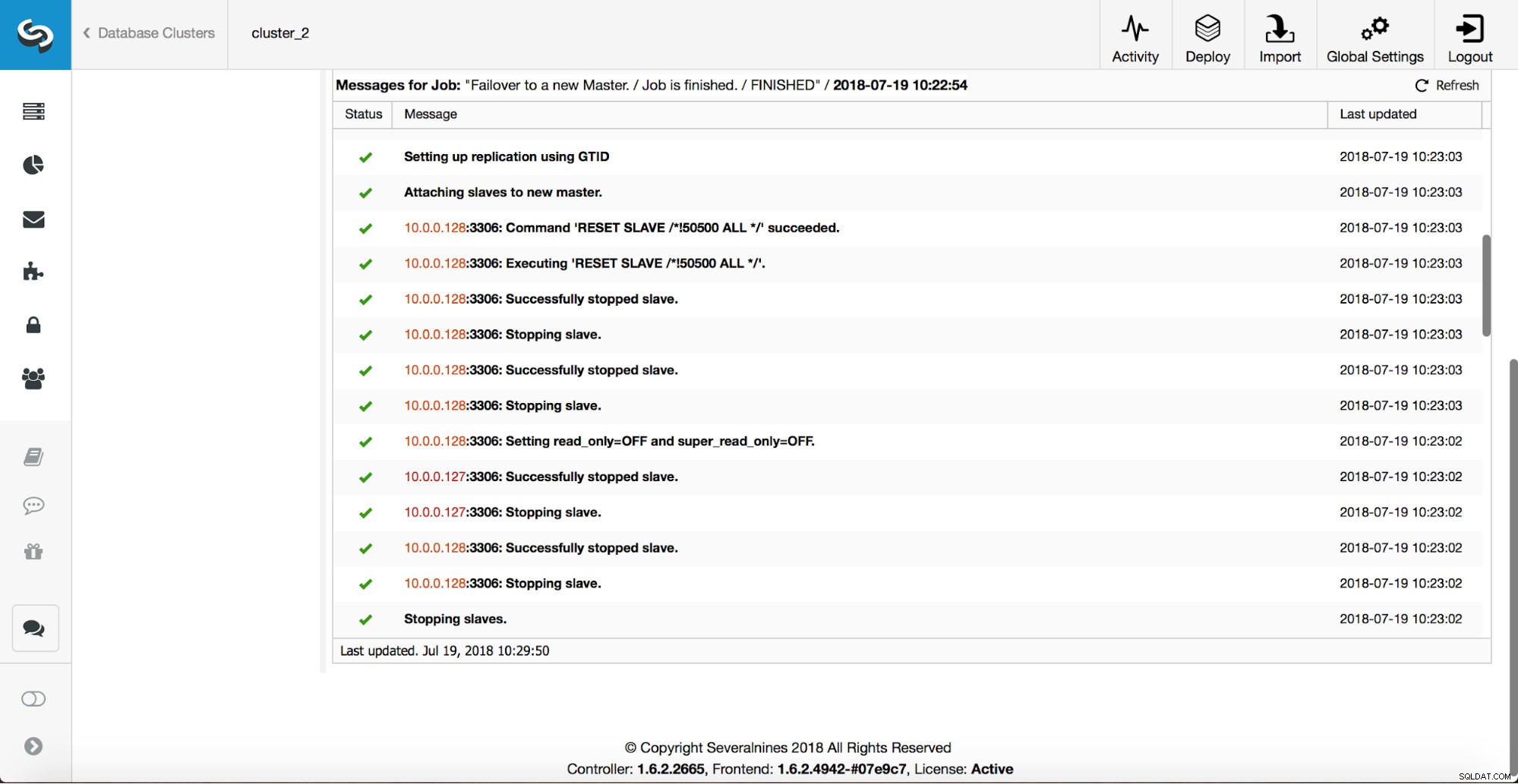
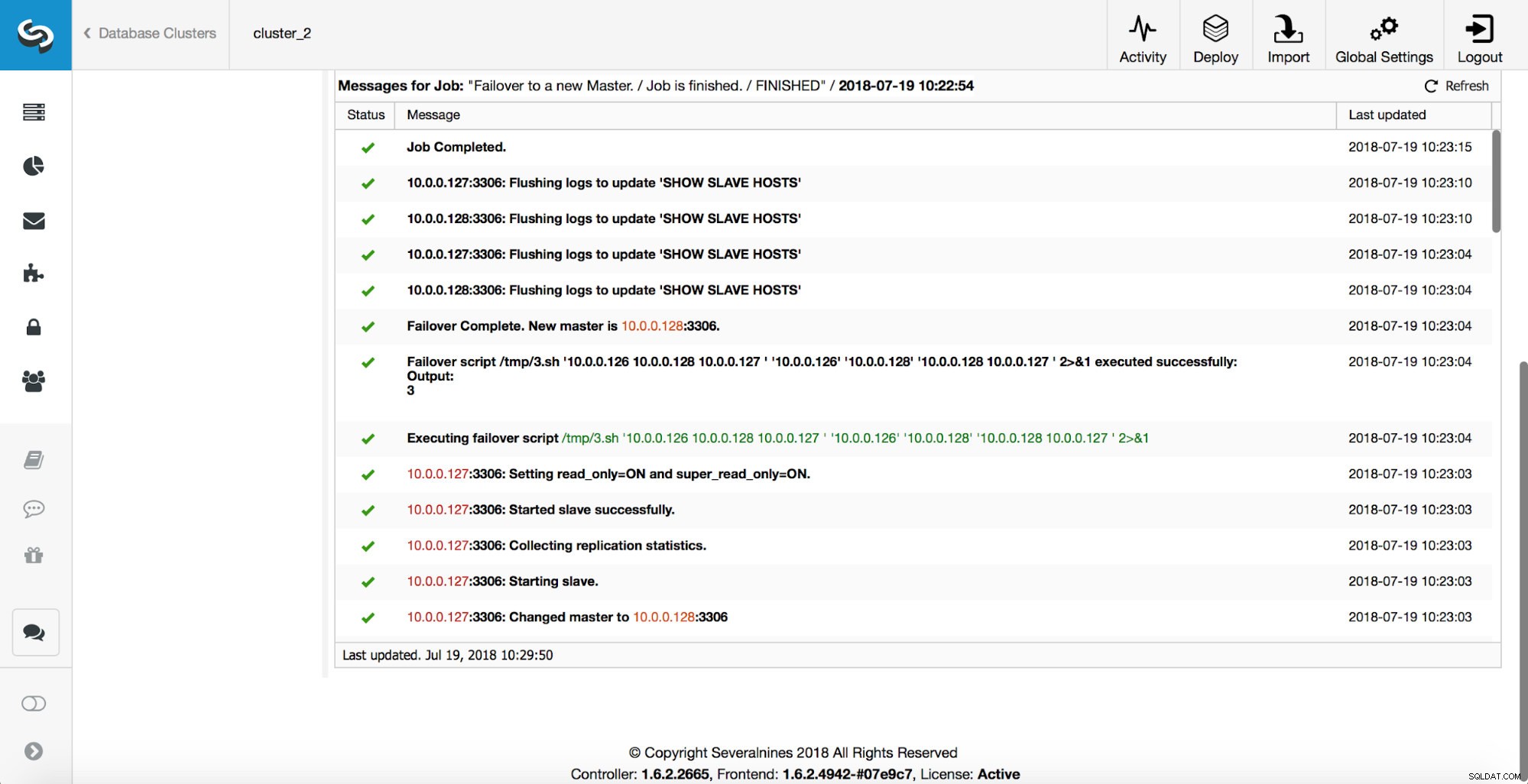
Przeprowadzanych jest więcej kontroli, repliki są zatrzymywane i podporządkowane nowemu masterowi. Na koniec, po zakończeniu przełączania awaryjnego, uruchamiane jest ostatnie przechwycenie „replication_post_failover_script”.
Kiedy hooki mogą być przydatne?
W tej sekcji omówimy kilka przykładowych przypadków, w których dobrym pomysłem może być zaimplementowanie zewnętrznych skryptów. Nie będziemy wchodzić w szczegóły, ponieważ są one zbyt ściśle związane z konkretnym środowiskiem. Będzie to bardziej lista sugestii, które mogą być przydatne do wdrożenia.
Skrypt STONITH
Shoot The Other Node In The Head (STONITH) to proces mający na celu upewnienie się, że stary mistrz, który nie żyje, pozostanie martwy (i tak… nie lubimy zombie włóczących się po naszej infrastrukturze). Ostatnią rzeczą, której prawdopodobnie chcesz, jest posiadanie niereagującego starego wzorca, który następnie wraca do trybu online i w rezultacie otrzymujesz dwa wzorce do zapisu. Istnieją środki ostrożności, które możesz podjąć, aby upewnić się, że stary wzorzec nie zostanie użyty, nawet jeśli pojawi się ponownie, i bezpieczniej jest pozostać offline. Sposoby, w jaki sposób zapewnić, że będzie się różnić w zależności od środowiska. Dlatego najprawdopodobniej nie będzie wbudowanej obsługi STONITH w narzędziu do przełączania awaryjnego. W zależności od środowiska możesz chcieć wykonać polecenie CLI, które zatrzyma (a nawet usunie) maszynę wirtualną, na której działa stary master. Jeśli masz konfigurację lokalną, możesz mieć większą kontrolę nad sprzętem. Możliwe jest skorzystanie z pewnego rodzaju zdalnego zarządzania (zintegrowanego Lights-out lub innego zdalnego dostępu do serwera). Możesz mieć również dostęp do zarządzalnych gniazdek i wyłączyć zasilanie w jednym z nich, aby upewnić się, że serwer nigdy nie uruchomi się ponownie bez interwencji człowieka.
Wykrywanie usług
Wspomnieliśmy już trochę o wykrywaniu usług. Istnieje wiele sposobów przechowywania informacji o topologii replikacji i wykrywania hosta nadrzędnego. Zdecydowanie jedną z bardziej popularnych opcji jest użycie etc.d lub Consul do przechowywania danych o aktualnej topologii. Dzięki niemu aplikacja lub serwer proxy może polegać na tych danych w celu wysłania ruchu do właściwego węzła. ClusterControl (podobnie jak większość narzędzi obsługujących obsługę awaryjną) nie ma bezpośredniej integracji z etc.d lub Consul. Zadanie aktualizacji danych topologicznych spoczywa na użytkowniku. Może użyć haków, takich jak replication_post_failover_script lub replication_post_switchover_script, aby wywołać niektóre skrypty i wprowadzić wymagane zmiany. Innym dość powszechnym rozwiązaniem jest użycie DNS do kierowania ruchu do właściwych instancji. Jeśli utrzymasz niski czas życia rekordu DNS, powinieneś być w stanie zdefiniować domenę, która będzie wskazywać na twój master (tj. writes.cluster1.example.com). Wymaga to zmiany rekordów DNS i ponownie, podpięcia, takie jak replication_post_failover_script lub replication_post_switchover_script, mogą być naprawdę pomocne przy wprowadzaniu wymaganych modyfikacji po awarii.
Ponowna konfiguracja proxy
Każdy używany serwer proxy musi kierować ruch do właściwych instancji. W zależności od samego serwera proxy, sposób wykonywania wykrywania głównego może być (częściowo) zakodowany na stałe lub może należeć do użytkownika, który określi, co chce. Mechanizm przełączania awaryjnego ClusterControl został zaprojektowany w taki sposób, aby dobrze integrował się z wdrożonymi i skonfigurowanymi serwerami proxy. Nadal może się zdarzyć, że istnieją serwery proxy, które nie zostały zainstalowane przez ClusterControl i wymagają wykonania pewnych ręcznych działań podczas wykonywania przełączenia awaryjnego. Takie serwery proxy można również zintegrować z procesem przełączania awaryjnego ClusterControl za pomocą zewnętrznych skryptów i punktów zaczepienia, takich jak replication_post_failover_script lub replication_post_switchover_script.
Dodatkowe rejestrowanie
Może się zdarzyć, że zechcesz zebrać dane z procesu przełączania awaryjnego do celów debugowania. ClusterControl ma obszerne wydruki, aby upewnić się, że można śledzić proces i dowiedzieć się, co się stało i dlaczego. Nadal może się zdarzyć, że będziesz chciał zebrać dodatkowe, niestandardowe informacje. Zasadniczo można tu wykorzystać wszystkie hooki — możesz zebrać stan początkowy, przed przełączeniem awaryjnym możesz śledzić stan środowiska na wszystkich etapach przełączania awaryjnego.